RLHF已过时?新一代免参考模型方法Reinforce-Lite,让语言模型获得自主推理能力
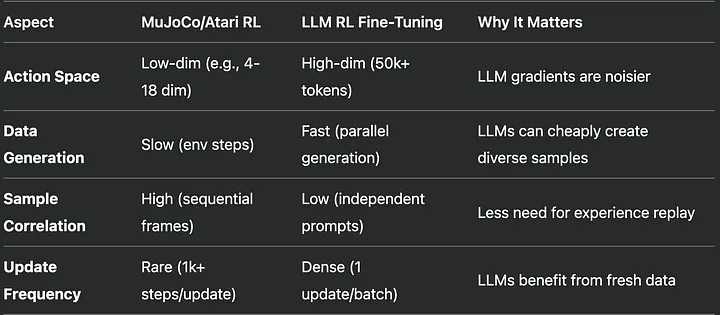
强化学习 (Reinforcement Learning, RL) 作为最强大的学习算法之一,已经屡次带来突破性成果,例如 DeepMind 的 AlphaGo、OpenAI 的 DOTA5、Mujoco 和 Atari 实验,以及用于大语言模型 (LLM) 对齐的 RLHF (Reinforcement Learning from Human Feedback)。对于优势估计,采用基于组的相对策
RLHF已过时?新一代免参考模型方法Reinforce-Lite,让语言模型获得自主推理能力
原创 NLP轻松谈 NLP轻松谈 2025年03月26日 10:23 北京
我们能否在计算资源有限(约 48GB RTX6000 和 10 美元预算)的条件下,让一个 3B 规模的模型具备推理能力,例如回溯 (Backtracking)、自我反思 (Self Reflection)、逻辑推理 (Logical Reasoning) 等?
强化学习 (Reinforcement Learning, RL) 作为最强大的学习算法之一,已经屡次带来突破性成果,例如 DeepMind 的 AlphaGo、OpenAI 的 DOTA5、Mujoco 和 Atari 实验,以及用于大语言模型 (LLM) 对齐的 RLHF (Reinforcement Learning from Human Feedback)。最近,DeepSeek 也在 RL 领域投入大量研究。然而,由于 RL 涉及众多复杂组件,其应用仍面临诸多挑战。RL 需要精细调整多个关键要素,例如合理的信用分配 (Credit Assignment)、适当的 Actor/Critic 超参数优化、RL 算法选择(基于模型 Model-Based 或无模型 Model-Free)等,因此在更广泛的应用场景中受限。
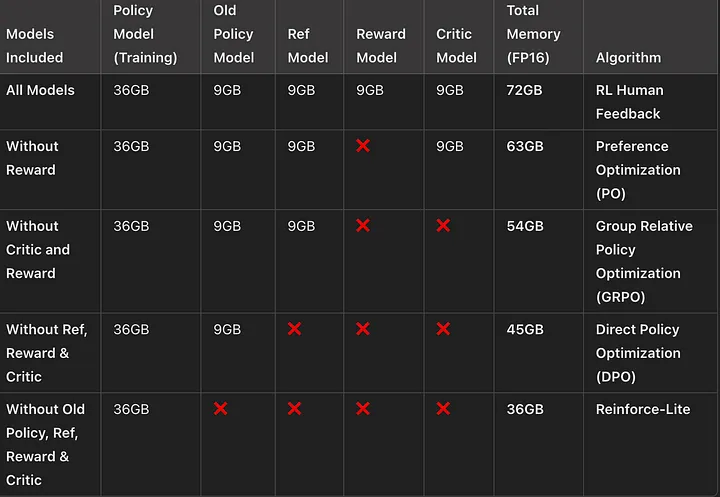
在 LLM 训练中引入 RL 可能涉及多达 5 个模型:
-
策略模型 (Policy Model) —— 训练中的核心模型
-
旧策略模型 (Old Policy Model) —— 用于计算替代比率 (Surrogate)
-
参考模型 (Reference Model) —— 用于计算 KL 散度 (KL Divergence)
-
奖励模型 (Reward Model) —— 用于学习奖励函数
-
评论者模型 (Critic Model) —— 用于计算价值函数 (Value Function)
Reinforce-Lite: 一种更简单、更稳定、更高效的 LLM 微调替代方案
引言
RL 训练涉及多个复杂的组成部分,不仅带来了计算负担,还增加了训练稳定性的挑战。因此,从零开始重新思考整个算法,回归 第一性原理 (First Principles),并提出一种更简单的替代方案:Reinforce-Lite。该方法避免了替代比率 (Surrogate Ratio) 的复杂性,无需旧策略模型 (Old Policy Model),仅依靠单一策略网络 (Single Policy Network) 即可实现稳定训练,同时赋予模型推理能力。
为什么 PPO/GRPO 中的替代比率对 LLM 来说是过度设计?
PPO 在传统强化学习环境(如 Mujoco、Atari 和 Dota)中,每个训练批次会进行多次更新,这是因为数据收集成本较高,重复利用样本能够提高数据使用效率。然而,在大语言模型 (LLM) 训练中,这种方法既不必要,也会带来高昂的计算成本。LLM 可以并行生成多样化的响应,从而自然地形成丰富的数据集,无需重复更新。所有响应都可以由同一策略网络生成,并在序列生成结束后,根据奖励进行一次性梯度反向传播。此外,在文本生成这种高维动作空间中,每个批次进行多次更新可能导致过拟合,而不是策略的有效改进。采用单次更新,并结合分组归一化等方法,既能保证训练稳定性,又能大幅降低计算成本。考虑到 LLM 训练本身已经非常消耗资源,简化优化过程,同时保持性能不下降,是更优的选择。从技术角度来看,这种方法无需旧策略模型即可计算替代比率 (Surrogate Ratio)。
Reinforce-Lite算法——
-
❌ 移除 KL 散度,不需要参考模型 —— 采用梯度裁剪代替,尽管不是自适应的,但能完成任务。
-
❌ 移除替代比率,不需要旧策略模型。
-
❌ 采用基于组的相对奖励 (DeepSeek 的 GRPO 风格) 进行优势估计算法,不再需要评估模型 (Critic)。
这样得到了一个轻量级的强化学习算法。在这一过程中,优化问题被简化为经典的 Reinforce 方法——
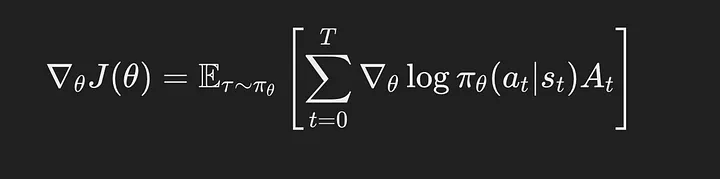
对于优势估计,采用基于组的相对策略优化 (GRPO) 的归一化技术,每个问题使用 10 个响应的组大小,并利用归一化来减少梯度更新的方差。
PyTorch 实现
def reinforce_lite(batch, policy_model, tokenizer, device, step, save_dir):
policy_model.train()
prompts, targets = zip(*batch)
batch_size = len(prompts)
evaluated_group = 0
all_logprobs = []
all_rewards = []
all_responses = []
all_lengths = []
for group_idx in range(config.GROUP_SIZE):
formatted_prompts = [format_prompt(p, tokenizer) for p in prompts]
inputs = tokenizer(
formatted_prompts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=config.MAX_SEQ_LENGTH
).to(device)
generate_kwargs = {
**inputs,
"max_new_tokens": config.MAX_NEW_TOKENS,
"do_sample": True,
"temperature": Temprature_val,
"top_p":top_p,
"pad_token_id": tokenizer.pad_token_id,
"return_dict_in_generate": True,
}
if group_idx == evaluated_group:
generated = policy_model.generate(**generate_kwargs)
generated_ids = generated.sequences
outputs = policy_model(
generated_ids,
attention_mask=(generated_ids != tokenizer.pad_token_id).long()
)
prompt_length = inputs.input_ids.shape[1]
response_length = generated_ids.shape[1] - prompt_length
if response_length > 0:
logits = outputs.logits[:, prompt_length-1:-1, :]
response_tokens = generated_ids[:, prompt_length:]
log_probs = torch.log_softmax(logits, dim=-1)
token_log_probs = torch.gather(log_probs, -1, response_tokens.unsqueeze(-1)).squeeze(-1)
sequence_log_probs = token_log_probs.sum(dim=1)
else:
sequence_log_probs = torch.zeros(batch_size, device=device)
else:
with torch.no_grad():
generated = policy_model.generate(**generate_kwargs)
sequence_log_probs = torch.zeros(batch_size, device=device)
responses = tokenizer.batch_decode(
generated.sequences[:, inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
rewards = torch.tensor([get_reward(resp, tgt) for resp, tgt in zip(responses, targets)], device=device)
all_responses.extend(responses)
all_rewards.append(rewards)
all_logprobs.append(sequence_log_probs)
all_lengths.extend([len(r.split()) for r in responses])
rewards_tensor = torch.stack(all_rewards)
logprobs_tensor = torch.stack(all_logprobs)
evaluated_rewards = rewards_tensor[evaluated_group]
others_rewards = torch.cat([
rewards_tensor[:evaluated_group],
rewards_tensor[evaluated_group+1:]
], dim=0)
baseline = others_rewards.mean(dim=0)
advantages = (evaluated_rewards - baseline) / (others_rewards.std(dim=0) + 1e-8)
advantages = torch.clamp(advantages, -adv_clip_val, adv_clip_val)
policy_loss = -(logprobs_tensor[evaluated_group] * advantages.detach()).mean()
return policy_loss, rewards_tensor.mean().item(), policy_loss.item(), 0.0, all_responses[0], all_lengths
-
初始化一个经过指令微调 (Instruction-tuned) 的 LLM,并通过适当的提示词让其在
<think></think>标签内包含推理步骤。 -
为模型输出定义一个奖励函数 (例如,在 GSM8K 数学推理任务中评估正确性)。使用正则表达式从标签中提取数值,并与数据集中的实际答案进行比较。
-
直接计算梯度来优化策略,与奖励相关,而不需要替代损失 (Surrogate Loss)。
-
通过基于组的相对归一化进行优势估计,消除评估模型的需求。使用 10 个响应的组大小。
-
使用标准的对数概率梯度技巧 (Log-Probability Gradient Trick) 更新模型。
GSM8K 数据集
选择了GSM8K 数据集,即小学数学 (Grade School Math) 数据集,其中包含数学题目及其答案,格式如下:
Question : Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Answer : Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May. #### 72
虽然答案中包含详细的推理步骤,但仅需关注的是 ### 之后的最终答案。因此,指示策略模型直接输出最终答案,并使用 <answer></answer> 进行封装,以便验证其计算结果是否正确。这种方式类似于蒙特卡罗 (Monte Carlo) 问题,模型在整个推理过程结束后才能获得奖励。
def format_prompt(question: str) -> str:
return f"""<|begin_of_text|><|start_header_id|>user<|end_header_id|>
Solve this math problem: {question}
Show your reasoning first in <think tags>, then put the final answer in \\boxed{{}}.
奖励建模
奖励机制非常简单:
-
如果答案错误,策略模型将获得 -1 的负奖励。
-
如果答案正确,策略模型将获得 +1 的正奖励。
def get_reward(completion: str, target: str) -> float:
reward = -1.0
try:
completion = completion.strip()
start_tag = "<answer>"
end_tag = "</answer>"
start_idx = completion.rfind(start_tag)
if start_idx != -1:
substring_after_start = completion[start_idx + len(start_tag):]
end_idx = substring_after_start.find(end_tag)
if end_idx != -1:
answer = substring_after_start[:end_idx].strip()
if not answer and end_idx > 0:
answer = substring_after_start[:end_idx].strip()
numbers = ''.join(char for char in answer if char.isdigit() or char == '.')
if numbers:
generated_num = float(numbers)
target_num = float(str(target).strip())
if abs(generated_num - target_num) < 1e-6:
reward = 1.0
except Exception as e:
pass
return reward
训练设置
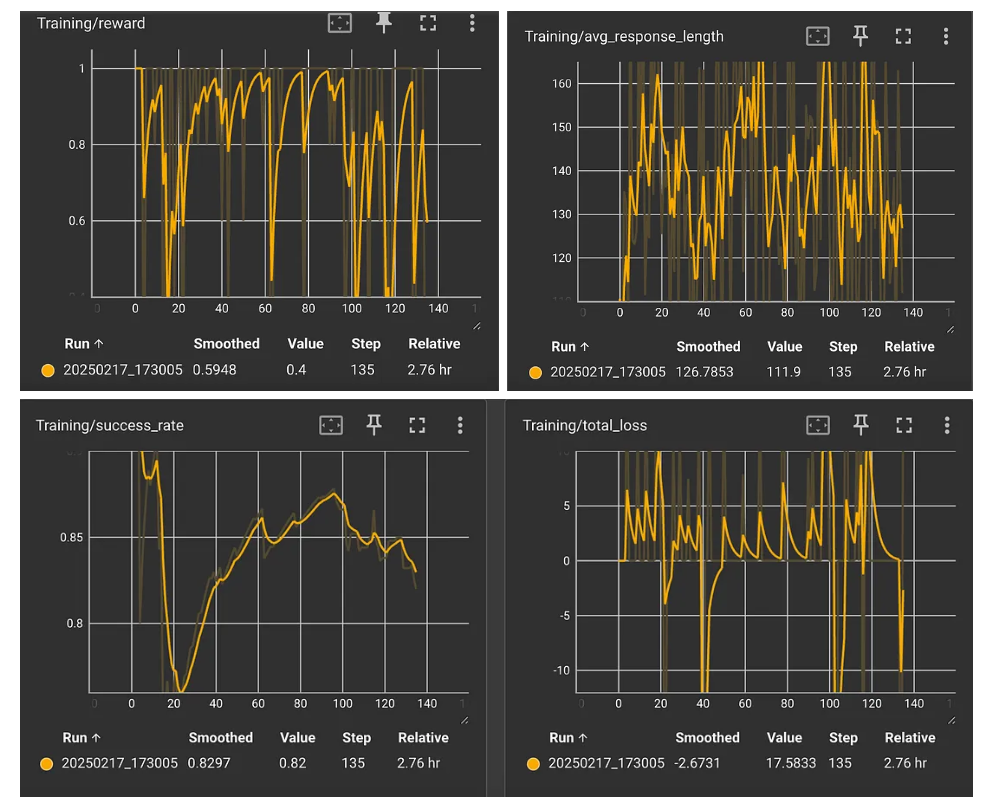
作者使用 Reinforce-Lite 算法在 RTX A6000 上训练 3B 规模的模型,并运行 12 小时。训练时,采用 10 个样本为一组,以适应计算资源的限制。在训练初期,观察到模型不断尝试增加推理步长 (即输出 Token 长度),但频繁的 OOM (内存溢出) 限制了模型的长步推理能力,从而影响了学习效果。
奖励图展示了组内所有响应的平均得分。理论上,平均得分越接近 1,说明模型的回答在大多数情况下越准确。尽管只训练了几百个迭代,但仍然可以观察到一定的奖励波动,这是因为策略网络在尝试不同的策略。作者计划利用熵正则化 (Entropy Regularisation) 进行控制,从而在探索 (Exploration) 与利用 (Exploitation) 之间取得平衡。
Reinforce-Lite 与 Instruct 模型在 GSM8K 上的基准测试
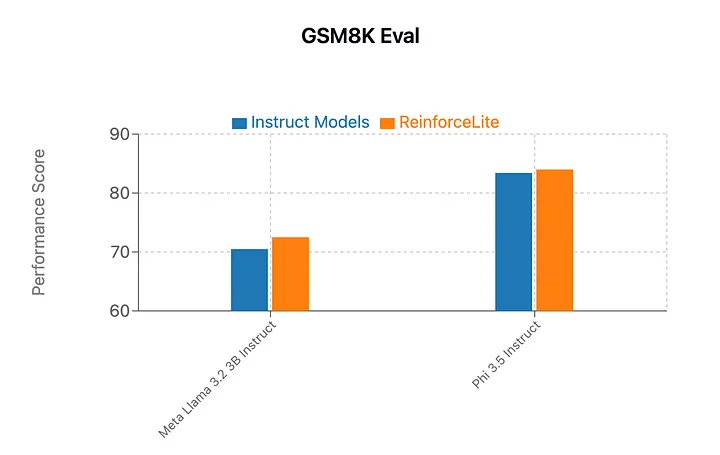
在 GSM8K 数据集上评估了 Reinforce-Lite,并发现该方法在有限的训练条件下,相比 Instruct 模型表现出轻微提升。具体来说,它在 Meta Llama 3.2 上的评估分数提高了 2.0%(70.5 → 72.5),在 Phi3.5 Instruct 上提高了 0.6%(83.4 → 84.0),均运行于 FP16。
推理轨迹
在这些示例中,Reinforce-Lite 调优后的模型展现出更强的逻辑推理能力,包括搜索、验证、创建表格进行辅助计算、试错等。而这些能力并未在 Instruct 模型中体现。
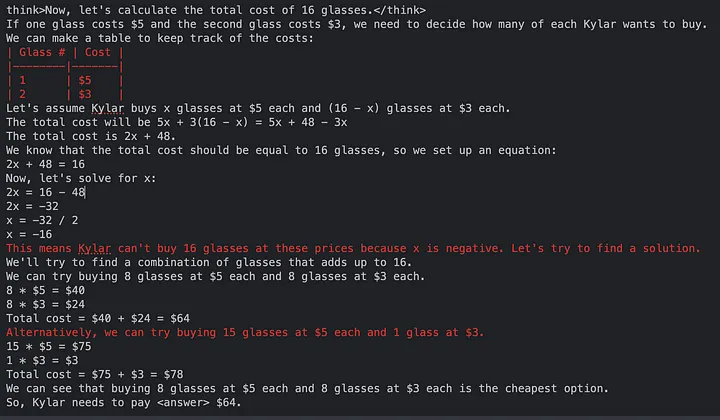
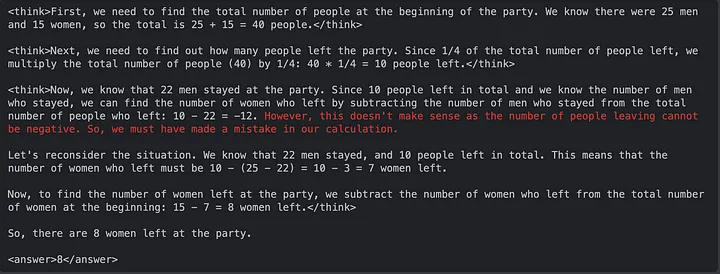
关键结论
-
Reinforce-Lite 增强了结构化推理能力 —— 从模型生成的序列可以看出,经过 RL 微调后,评估分数略有提升。
-
无须引入 PPO 的复杂结构 —— 仅使用单一策略网络即可完成 LLM 微调。
-
计算效率更高 —— Reinforce-Lite 是一种计算资源友好的算法,能够实现端到端的强化学习 (RL) 训练,同时减少训练复杂度。
-
赋予 LLM 更强的自主性 —— 该算法使 LLM 能够自主尝试不同的策略以获取奖励。
-
推理步长增加会带来更高的内存需求 —— 随着训练的进行,模型尝试延长推理过程 (rollout),但在 48GB GPU 上训练 3GB 模型时,超过 1024 个 Token 便频繁遇到 OOM 问题。
-
梯度裁剪确保稳定性,无需计算 KL 散度 —— 通过简单的梯度裁剪,能够有效防止策略发散,而无需计算 KL 散度。这是一种低成本的替代方案。在整个训练过程中,未观察到策略出现突发性或剧烈变化。
代码链接:https://github.com/Raj-08/Q-Flow/tree/main
往期内容
超越Deepseek的GRPO,字节跳动&清华港大提出DAPO:四项核心技术提高LLM推理性能
无需复杂奖励!SEARCH-R1用强化学习教会LLM自主搜索
仅54GB训练20K上下文!Unsloth GRPO算法暴降90%显存

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献391条内容
已为社区贡献391条内容

所有评论(0)