多例上下文学习
多例上下文的越多越好?两个设计的提示词策略
Many-Shot In-Context Learning
NeurIPS 2024
核心思想:
这篇论文主要探讨了“多样本上下文学习 (Many-Shot In-Context Learning, ICL)”。简单来说,就是在模型推理时,直接在大型语言模型 (LLM) 的提示 (prompt) 中提供大量(成百上千个)的输入-输出样例(称为“shots”),而无需更新模型的权重。这是对“少样本上下文学习 (few-shot ICL)”(只用少量样例)的扩展,得益于像 Gemini 1.5 Pro 这样拥有更大上下文窗口的新模型。
解决的关键问题:
- 少样本ICL的局限性: 虽然少样本ICL有效,但对于复杂任务或者让LLM完全理解期望的行为,它可能无法提供足够的信息。
- 人工生成数据的瓶颈: 为多样本ICL创建成百上千个高质量的人工样例既昂贵又耗时。
针对数据瓶颈提出的解决方案:
为了减轻对大量人工生成数据的依赖,作者探索了两种设置:
- “强化ICL (Reinforced ICL)”: 使用模型生成的“思维链 (chain-of-thought)”推理过程来替代人工编写的推理过程。具体步骤为:首先通过零样本或少样本提示生成多个推理链,然后筛选出能得出正确答案的推理链用于上下文学习。实验结果表明,在 MATH 和 GPQA 等任务中,该方案的表现优于使用人类标注推理链的少样本 ICL。
- “无监督ICL (Unsupervised ICL)”: 完全移除推理过程甚至输出样例。模型仅被提示大量特定领域的输入(例如,一堆数学问题,没有答案),然后在末尾附上一个零样本或少样本的指令来说明期望的输出格式。其理念是,看到大量目标领域的输入有助于模型“定位”其在预训练期间学到的相关技能。
主要发现和贡献:
-
显著的性能提升: 从少样本ICL转向多样本ICL,在多种生成和判别任务上都带来了显著的性能提升,包括:
- 翻译(尤其是低资源语言翻译)
- 摘要生成
- 问题解决(如MATH, GSM8K数学题)
- 问答(如GPQA)
- 算法推理(如Big-Bench Hard)
- 代码验证(作为奖励模型)
- 规划
- 情感分析
(图1 生动地展示了这些提升)。
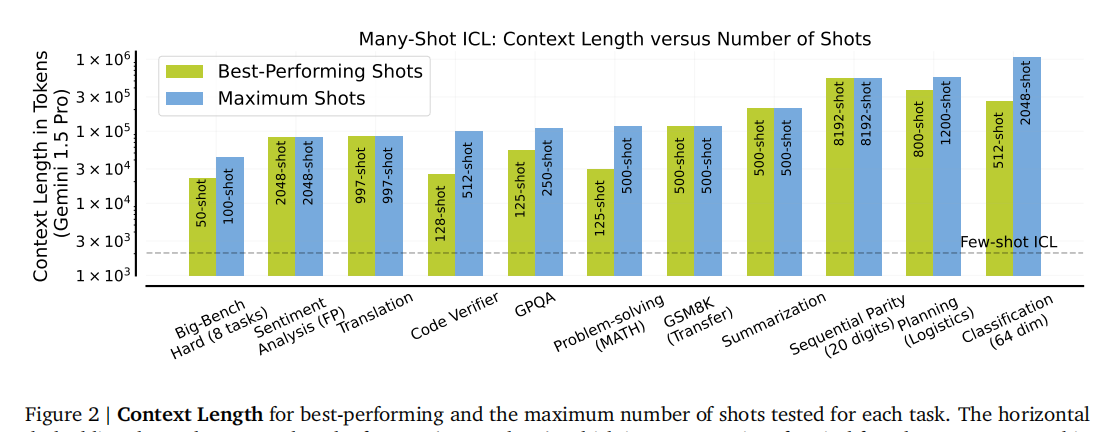
(图2 展示了不同任务在最佳表现和最大测试样本数下的上下文长度,强调了许多任务在达到数万甚至数十万tokens的上下文长度时才能达到最佳或最大测试性能)。![![[image-70.png]]](https://i-blog.csdnimg.cn/direct/2dd920dc3c514724beb168f2ac686b83.png)
-
强化ICL和无监督ICL的有效性:
- 这两种方法在多样本场景下都很有效,尤其是在复杂的推理任务上(例如MATH, GPQA, Big-Bench Hard)。(图7 展示了在MATH和GSM8K任务上,强化ICL和无监督ICL通常优于使用真实MATH解的ICL; 图8 展示了在GPQA任务上强化ICL和无监督ICL的表现; 图9 展示了在Big-Bench Hard任务上强化ICL优于无监督ICL和人类编写的思维链提示)。
- 在某些情况下,强化ICL的表现甚至优于无监督ICL,有时甚至优于使用真实人工标注推理过程的ICL,特别是在泛化能力方面(例如,用MATH的提示在GSM8K上进行迁移)。
- 无监督ICL也能超越使用人工演示的少样本ICL,表明即使仅仅看到大量相关输入也是有帮助的。
![![[image-72.png]]](https://i-blog.csdnimg.cn/direct/d9a1198d504f45a9a799868aa084e80f.png)
![![[image-73.png]]](https://i-blog.csdnimg.cn/direct/3ff8080080744a0aa4a3c095bdcc033c.png)
![![[image-74.png]]](https://i-blog.csdnimg.cn/direct/6c575427c5f043eb82cceb915d961fb1.png)
- 多样本ICL解锁新能力:
-
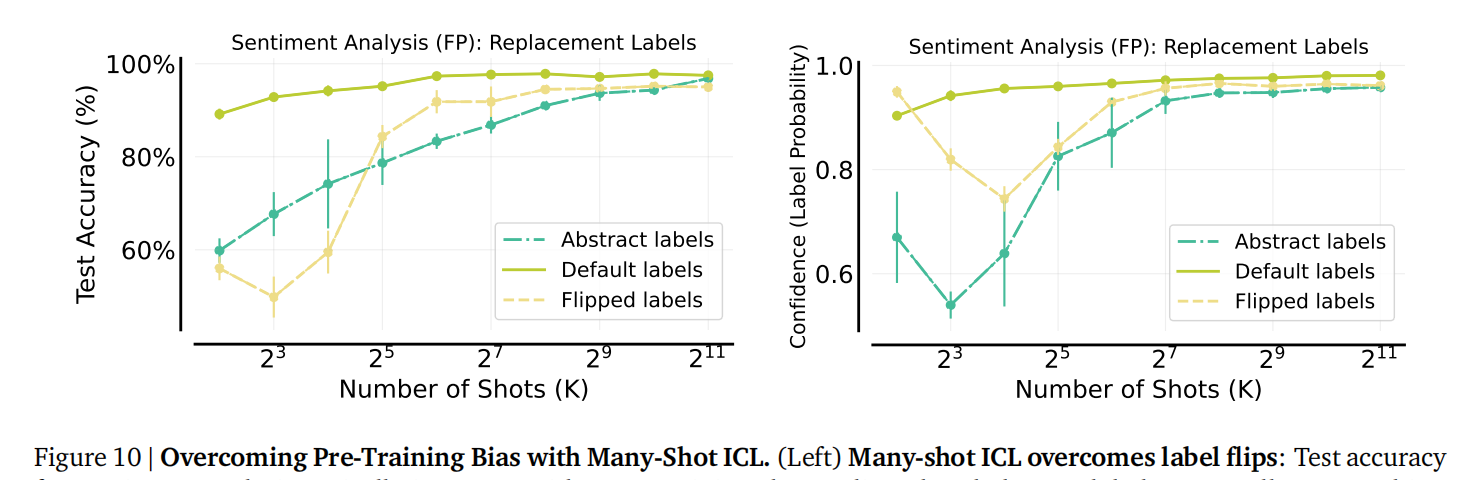
克服预训练偏见: 有了足够多的样例,多样本ICL可以克服模型在预训练数据中习得的偏见(例如,在情感分析中学习翻转标签或抽象标签)。(图10 展示了在情感分析任务中,多样本ICL如何克服标签翻转带来的偏见,以及模型置信度的变化)。
-
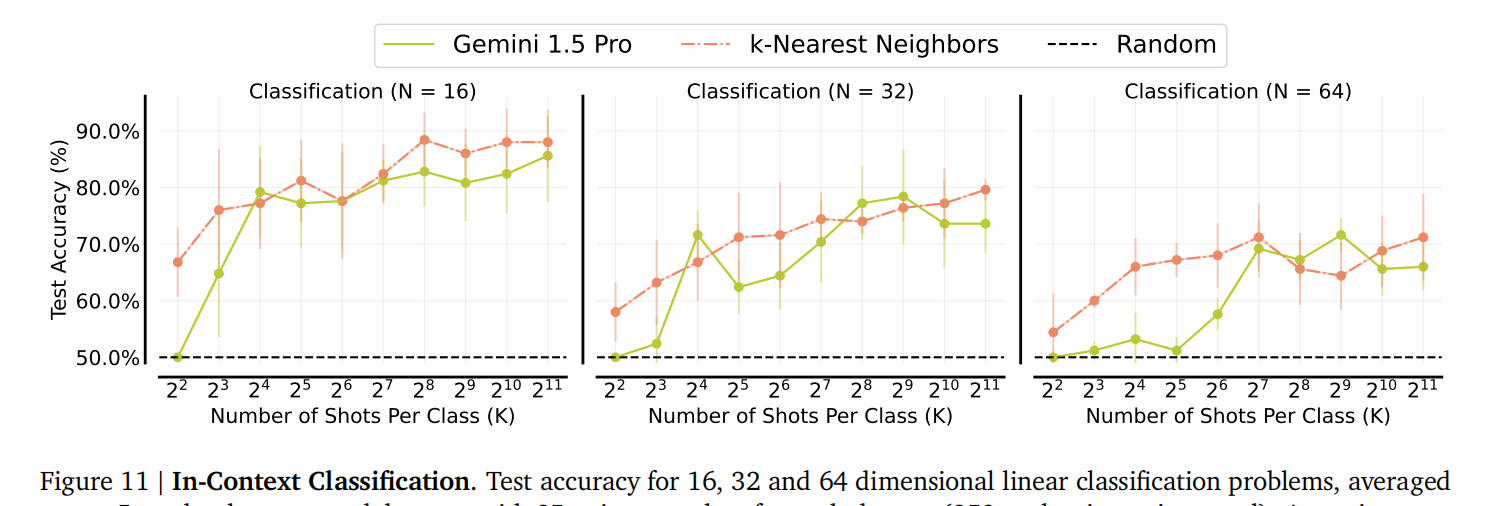
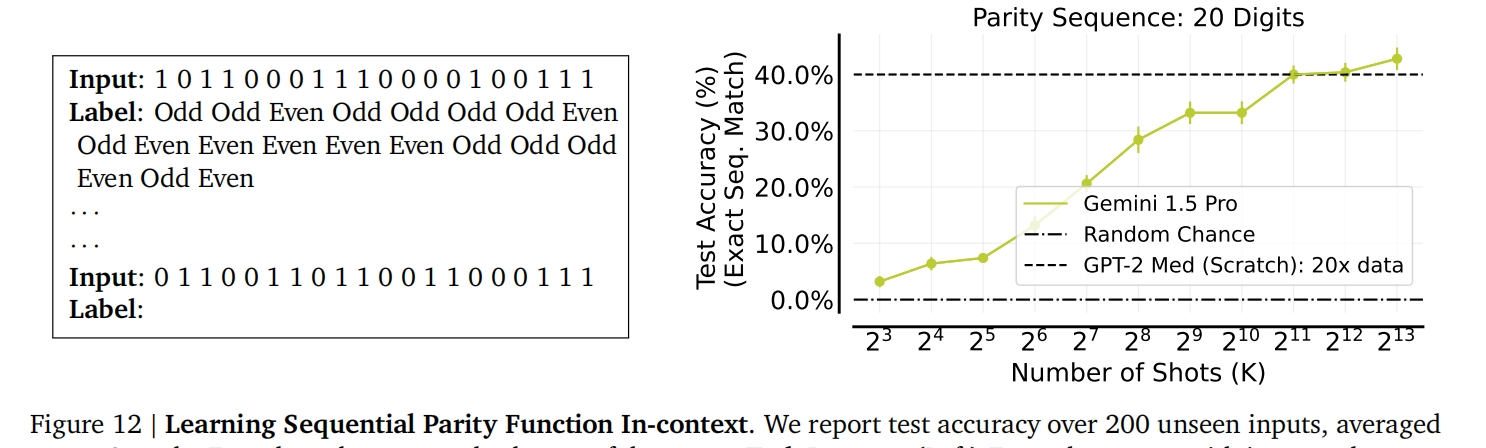
学习高维/非自然语言函数: 它可以学习带有数值输入的任务,如高维线性分类和序列奇偶校验,这些是少样本ICL难以处理的。(图11 展示了在高维线性分类任务上的表现; 图12 展示了在序列奇偶校验任务上的表现,并给出了一个任务提示示例)。
-
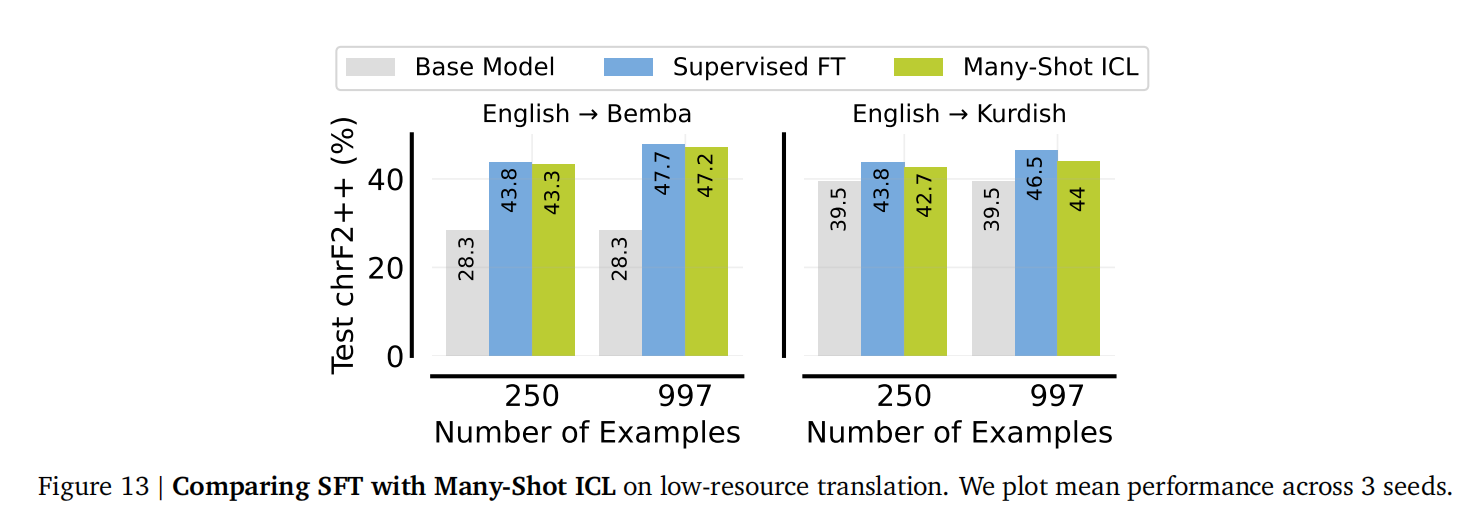
* **媲美微调:** 在某些任务上(如低资源机器翻译),多样本ICL的性能与监督微调 (SFT) 相当,而无需任何权重更新。(**图13** 对比了在低资源翻译任务上,SFT与多样本ICL的性能)。
-
多样本ICL的分析:
-
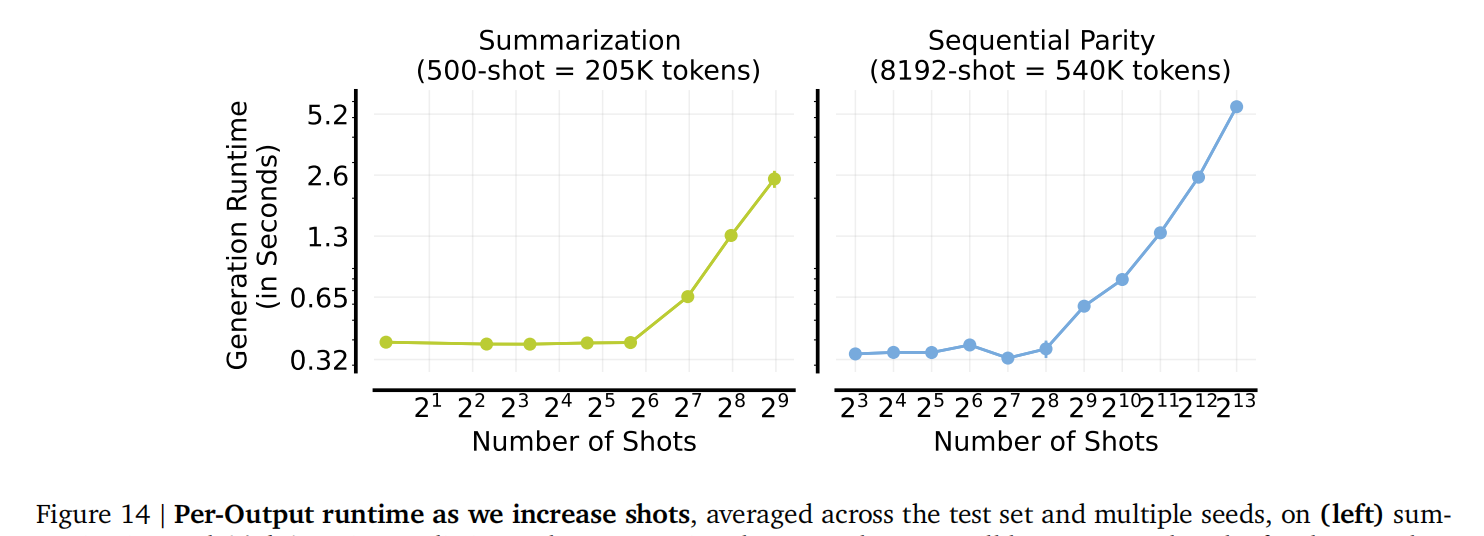
推理成本: 虽然增加样本数量会增加推理时间,但键值缓存 (KV caching) 使其能够线性扩展(而非二次方),因此是可控的。(图14 展示了在摘要和奇偶校验任务上,随着样本数量增加,每个输出的生成运行时间的变化)。
-
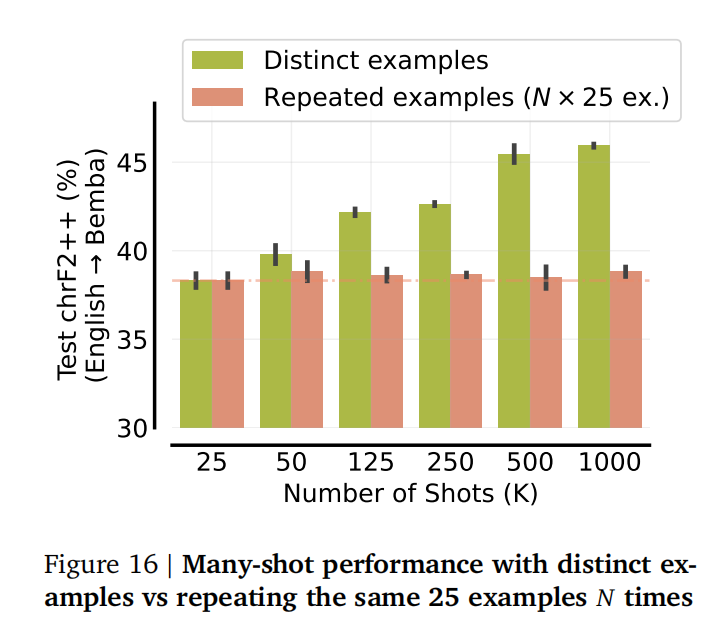
增益来源: 收益主要来自于增加新的、不同的信息,而不是仅仅通过重复样例来增加上下文长度。(图16 对比了使用不同样例和重复相同样例在低资源机器翻译任务上的性能)。
-
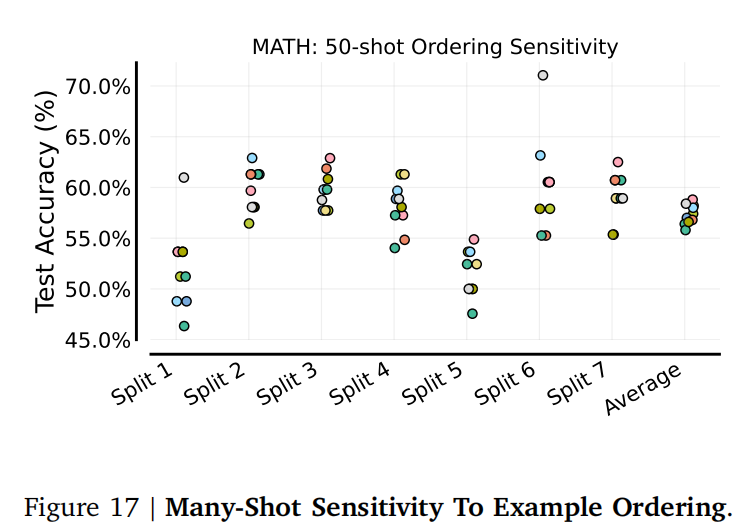
样例顺序敏感性: 与少样本ICL类似,多样本提示中样例的顺序仍然对模型性能有显著影响。(图17 展示了在MATH任务中,50个样本的不同排序对性能的显著影响,7个随机序列)。
-
下一词元预测损失并非完美指标: 尽管负对数似然 (NLL) 通常随着上下文长度的增加而降低,但其趋势并不总是与实际的下游任务性能良好相关(例如,任务性能可能在NLL持续改善的情况下下降)。(图18 展示了在GPQA, MATH, GSM8K任务上,NLL随样本数量的变化趋势)。
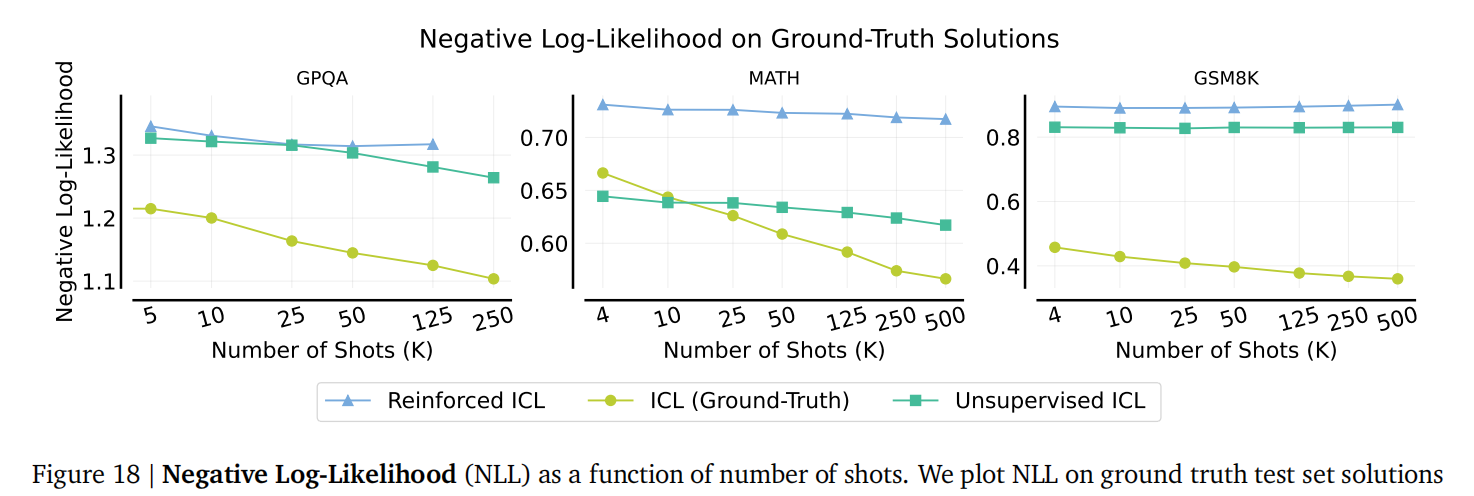
-
-
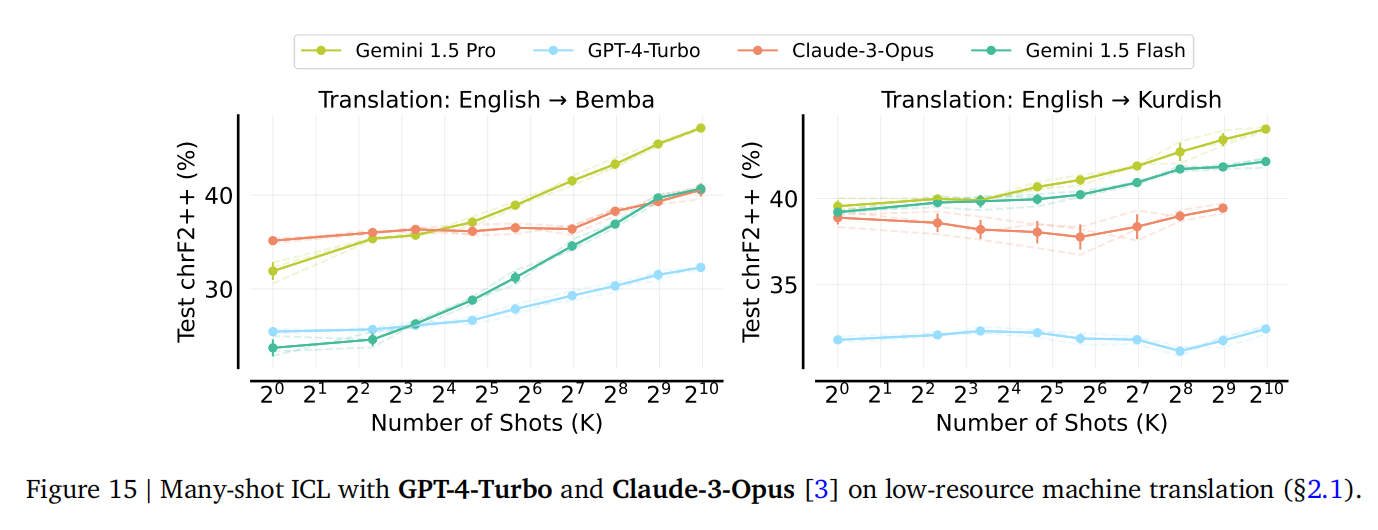
与其他前沿LLM的比较: 论文表明,其他长上下文LLM(如GPT-4-Turbo, Claude-3-Opus)也能从多样本ICL中受益,尽管提升程度不同。即使是较小的长上下文模型(如Gemini 1.5 Flash)也能获得显著益处。(图15 对比了不同前沿LLM在低资源机器翻译任务上的多样本ICL表现)。
意义:
- 多样本ICL使LLM在无需昂贵微调的情况下更加通用和适应性更强。
- 减少了对任务专业化微调的依赖。
- 强化ICL和无监督ICL为在人工标注数据稀缺时扩展ICL提供了途径。
- 推动了LLM从上下文中“即时”学习能力的边界。
提及的局限性:
- 研究主要使用的是Gemini 1.5 Pro。
- 对于某些任务(如MATH),当提示中的样例过多时性能反而下降的原因尚未完全明了。
- NLL(一种常用的损失函数,NLL越低,意味着模型对于预测正确的下一个词元更有信心)的趋势不足以解释这些性能下降。
总而言之,这篇论文表明,对于上下文学习来说,多多益善通常是成立的,而且即使高质量的人工数据有限,巧妙的提示策略(如强化ICL和无监督ICL)也能从具有大上下文窗口的LLM中释放出令人印象深刻的性能。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)