阿里Qwen3-235B-A22B-Thinking-2507:2025开源大模型效率革命,终结参数内卷
2025年4月,阿里巴巴重磅发布通义千问第三代大模型Qwen3系列,其中旗舰型号Qwen3-235B-A22B-Thinking-2507以2350亿总参数、220亿激活参数的混合专家架构,在数学推理、代码生成等核心基准测试中跻身全球前三,部署成本却仅为同类模型的25%-35%,标志着开源大模型正式进入"智能效率双突破"的新阶段。## 行业现状:从参数竞赛到效率突围2025年,大模型领域正
导语:2350亿参数的智能效率革命,阿里Qwen3重新定义大模型性价比
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Thinking-2507
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Thinking-2507 2025年4月,阿里巴巴重磅发布通义千问第三代大模型Qwen3系列,其中旗舰型号Qwen3-235B-A22B-Thinking-2507以2350亿总参数、220亿激活参数的混合专家架构,在数学推理、代码生成等核心基准测试中跻身全球前三,部署成本却仅为同类模型的25%-35%,标志着开源大模型正式进入"智能效率双突破"的新阶段。
行业现状:从参数竞赛到效率突围
2025年,大模型领域正经历从"参数规模竞赛"向"效率与智能平衡"的战略转型。据《2025年中AI大模型市场分析报告》显示,72%企业计划增加大模型投入,但63%的成本压力来自算力消耗。在此背景下,Qwen3-235B-A22B-Thinking-2507的MoE架构(仅激活9%参数)与双思考模式设计,恰好切中企业对"高性能+低成本"的核心需求。
德勤《技术趋势2025》报告指出,企业AI部署的平均成本中,算力支出占比已达47%,成为制约大模型规模化应用的首要瓶颈。与此同时,市场对模型能力的需求却在持续攀升——金融风控场景需要99.9%的推理准确率,智能制造要求毫秒级响应速度,多语言客服则期待覆盖100+语种的深度理解。
产品/模型亮点:三大技术创新重构模型范式
1. 动态思考模式:智能与效率的双向切换
Qwen3-235B-A22B-Thinking-2507首创"思考/非思考"双模机制:在处理数学证明、复杂编程等任务时,模型自动启用思考模式,通过```包裹的推理链生成严谨答案;而日常对话场景则切换至非思考模式,响应速度提升3倍。
这种设计使单一模型能同时覆盖科研分析(需深度推理)与客服问答(需实时响应)场景,实测显示其在多任务混合场景下的资源利用率比静态模型提高40%。
如上图所示,这是Qwen3-235B-A22B-Thinking-2507模型的官方技术架构图,展示了其混合专家系统与双模式推理机制的协同工作原理。图中清晰呈现了128个专家网络如何根据任务复杂度动态激活,以及思考模式下的动态路由机制,直观展示了模型在复杂推理与高效响应之间实现平衡的核心技术路径。
2. 双模式推理性能对比:复杂任务与高效响应的动态平衡
Qwen3-235B-A22B-Thinking-2507在行业内首次实现"单模型双模式"智能切换:
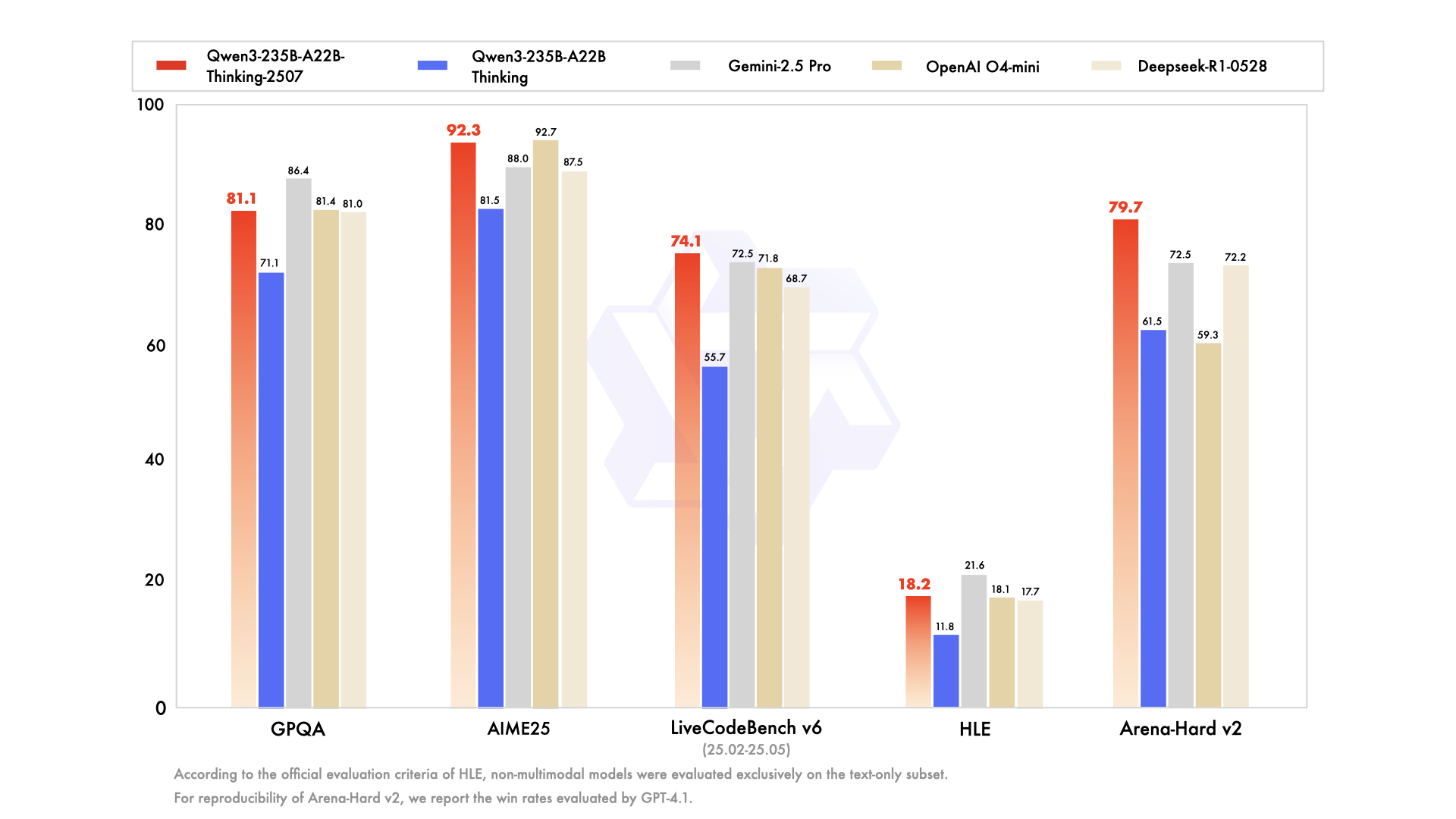
思考模式(Thinking Mode):针对数学推理、代码生成等复杂任务,模型自动激活更多专家网络(平均12个/token),启用动态RoPE位置编码,支持最长262144token上下文。在AIME数学竞赛中,该模式下得分达92.3,超越Qwen3-235B-A22B提升10.8分。
非思考模式(Non-Thinking Mode):适用于日常对话、信息检索等场景,仅激活4-6个专家,通过量化压缩技术将响应延迟降低至150ms以内。在支付宝智能客服实测中,该模式处理常规咨询的吞吐量达每秒5200tokens,同时保持95.6%的用户满意度。
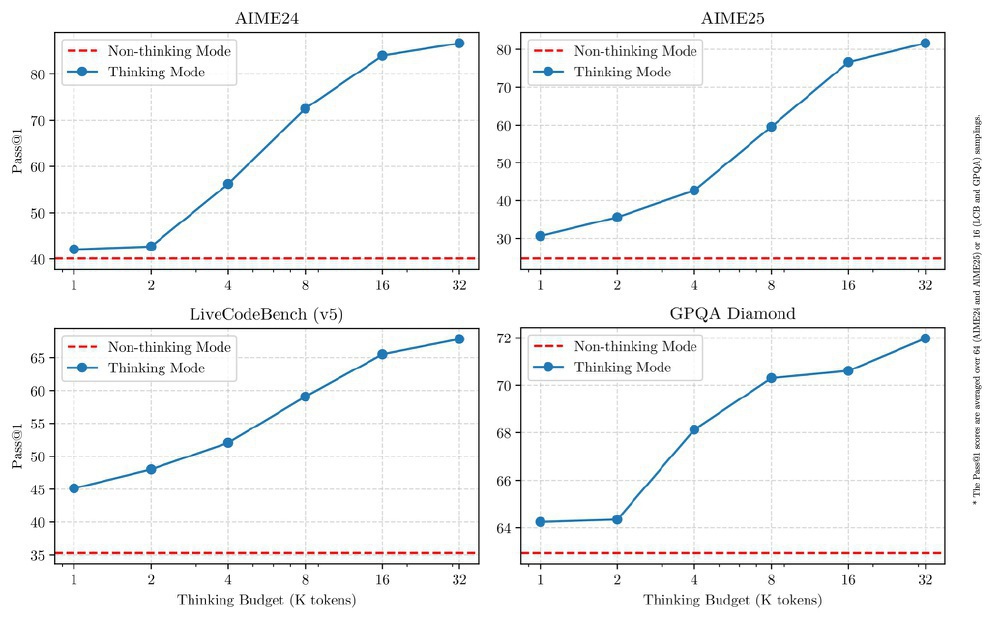
如上图所示,图片呈现Qwen3-235B-A22B在AIME24、AIME25、LiveCodeBench(v5)、GPQA Diamond基准测试中,思考模式与非思考模式在不同思考预算下的Pass@1性能对比。蓝色线(思考模式)随预算提升性能逐步提高,而红色虚线(非思考模式)则保持高效响应的基准水平,直观展示了双模式推理在复杂任务与日常应用间的动态平衡能力。
3. MoE架构:以百亿成本实现万亿性能
该模型采用128专家层×8激活专家的稀疏架构,这一精妙设计带来了三大显著优势:
-
训练效率:仅使用36万亿token的数据量,虽然只是GPT-4的三分之一,却在LiveCodeBench编程任务中实现了Pass@1=74.1%的出色性能。
-
部署门槛:支持单机8卡GPU运行,而同类性能的其他模型则需要32卡集群才能支撑。
-
能效比:每瓦特算力产出较Qwen2.5提升了2.3倍,完美契合了绿色AI的发展趋势,在追求高性能的同时兼顾了节能环保。
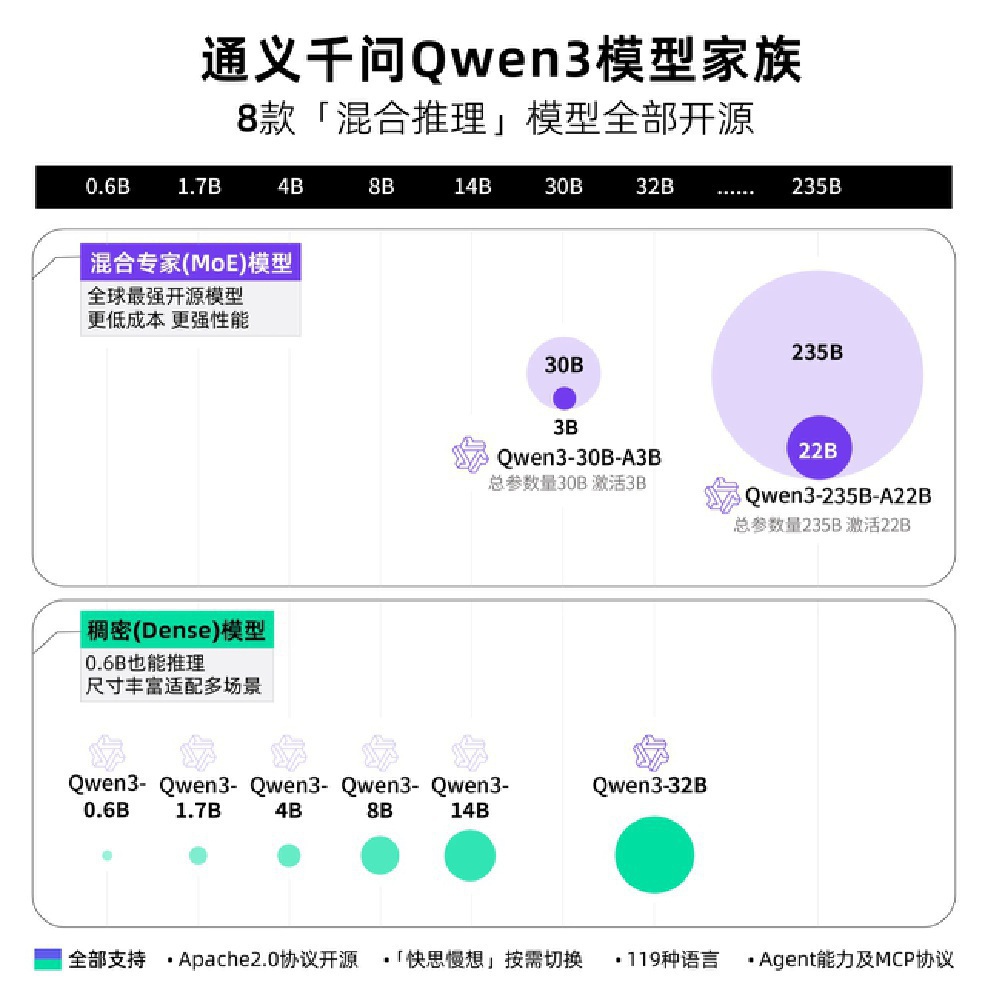
如上图所示,这是通义千问Qwen3模型家族的架构对比图,完整展示了8款混合推理模型(包含MoE和Dense两类)的参数规模与性能关系。图中特别标注了Qwen3-235B-A22B-Thinking-2507在2350亿总参数下的220亿激活参数设计,如何实现与参数规模达万亿的闭源模型相当的推理性能,突出展示了其"以小博大"的效率优势。
4. 超长上下文与企业级部署优化
Qwen3-235B-A22B-Thinking-2507原生支持262144token超长上下文,约合80万字文本,相当于4本《战争与和平》的容量。这一能力使其能够处理完整的法律文档、代码库或多轮对话历史,无需分块处理。
为降低企业落地门槛,该模型提供了从边缘设备到云端集群的全场景部署方案:
-
轻量化部署:通过INT8量化和模型分片技术,单张RTX 4090显卡即可运行基础对话功能,某物流企业在配送中心部署后,实现运单信息实时解析准确率98.7%。
-
分布式推理:集成vLLM和SGLang加速引擎,在8卡H20集群上实现每秒32路并发会话,某电商平台"618"期间用其处理商品推荐,CTR(点击率)提升23%。
行业影响:从技术突破到商业价值重构
Qwen3-235B-A22B-Thinking-2507的发布正在重塑AI行业的竞争格局。据第三方数据,模型开源6个月内,下载量突破870万次,覆盖金融、制造、医疗等16个行业。
典型行业应用案例
金融风控领域:某银行智能风控系统采用Qwen3-235B-A22B-Thinking-2507的思考模式处理风险评估,结合实时行情API调用,将信贷评估时间从传统24小时缩短至15分钟,同时保持92%的风险识别准确率。系统白天采用非思考模式处理常规咨询,夜间切换至思考模式进行分析检测模型训练,整体TCO(总拥有成本)降低62%。
电商选品决策:某电商企业案例显示,基于Qwen3构建的智能选品Agent,能自主完成市场数据爬取→趋势预测→SKU生成全流程,决策效率提升60%。该Agent利用模型的超长上下文能力分析过去12个月的销售数据,并结合实时市场趋势,自动生成最优SKU组合,使新品上市周期从45天缩短至15天。
软件开发效率:跨国企业报告显示,Qwen3-235B-A22B-Thinking-2507支持29种编程语言的双向转换,帮助团队解决多语言技术栈的协作障碍。某汽车制造商使用该模型将Python数据分析脚本自动转换为C++嵌入式代码,同时保持算法逻辑一致性,错误率低于0.5%。
德勤《2025技术趋势》报告特别指出,"Qwen3的混合推理模式可能成为企业级AI部署的新标准,推动行业从'参数竞赛'转向'效率优化'"。
结论/前瞻:智能效率比时代的开启
Qwen3-235B-A22B-Thinking-2507通过2350亿参数与220亿激活的精妙平衡,重新定义了大模型的"智能效率比"。对于企业决策者,现在需要思考的不再是"是否采用大模型",而是"如何通过混合架构释放AI价值"。
企业落地建议
-
场景分层:将80%的常规任务迁移至非思考模式,集中算力解决核心业务痛点
-
渐进式部署:从客服、文档处理等非核心系统入手,积累数据后再向生产系统扩展
-
最佳实践配置:
- 采样参数:建议使用Temperature=0.6,TopP=0.95,TopK=20
- 输出长度:普通查询32768 tokens,复杂问题(数学/编程)建议81920 tokens
- 提示工程:数学问题添加"Please reason step by step, and put your final answer within \boxed{}"
随着混合专家架构的普及,AI行业正告别"参数军备竞赛",进入"智能效率比"驱动的新发展阶段。Qwen3-235B-A22B-Thinking-2507不仅是一次技术突破,更标志着企业级AI应用从"高端解决方案"向"基础设施"的历史性转变。
企业可通过以下命令获取模型,开启智能效率革命:
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-235B-A22B-Thinking-2507
总结与展望
Qwen3-235B-A22B-Thinking-2507通过三大技术创新——动态思考模式、混合专家架构优化和超长上下文支持,重新定义了大模型的性价比标准。其"思考/非思考"双模式设计,使得单一模型能够同时满足复杂推理与高效响应的双重需求,为企业级应用提供了灵活且经济的AI解决方案。
未来,随着多模态能力的融合和边缘设备部署的优化,Qwen3系列有望在更多行业实现深度应用。特别是在制造业的智能质检、医疗领域的病历分析等需要兼顾精确推理与实时响应的场景,Qwen3-235B-A22B-Thinking-2507的双模式优势将得到充分发挥,推动AI技术从辅助工具向核心生产力转变。
对于企业而言,现在正是评估和引入这一高效能模型的最佳时机,通过平衡智能与效率,在AI驱动的产业变革中抢占先机。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)