GRAPE:通过偏好对齐来泛化机器人策略
25年2月来自 UNC、西雅图的华盛顿大学和芝加哥大学的论文“GRAPE: Generalizing Robot Policy via Preference Alignment”。尽管视觉-语言-动作 (VLA) 模型最近在各种机器人任务上取得了进展,但它们仍存在一些关键问题,例如对未见过任务的泛化能力差,因为它们完全依赖于从成功案例中克隆行为。此外,它们通常经过微调以复制专家在不同环境下收集的演
25年2月来自 UNC、西雅图的华盛顿大学和芝加哥大学的论文“GRAPE: Generalizing Robot Policy via Preference Alignment”。
尽管视觉-语言-动作 (VLA) 模型最近在各种机器人任务上取得了进展,但它们仍存在一些关键问题,例如对未见过任务的泛化能力差,因为它们完全依赖于从成功案例中克隆行为。此外,它们通常经过微调以复制专家在不同环境下收集的演示,从而引入分布偏差并限制其对不同操作目标(如效率、安全性和任务完成)的适应性。为了弥补这一差距,本文推出 GRAPE:通过偏好对齐泛化机器人策略。具体而言,GRAPE 在轨迹级别对齐 VLA,并隐式地模拟来自成功和失败试验的奖励,以提高对不同任务的泛化能力。此外,GRAPE 将复杂的操作任务分解为独立的阶段,并通过使用大型视觉-语言模型提出的关键点通过定制的时-空约束自动引导偏好建模。值得注意的是,这些约束非常灵活,可以根据不同的目标进行定制,例如安全性、效率或任务成功率。在现实世界和模拟环境中的一系列任务中评估 GRAPE。实验结果表明,GRAPE 提升最先进 VLA 模型的性能,使域内操作任务和未见过操作任务的成功率分别提高 51.79% 和 58.20%。此外,GRAPE 还可以与各种目标保持一致,例如安全性和效率,分别将碰撞率降低 37.44%,并将滚动步长降低 11.15%。
GRAPE概述如图所示:
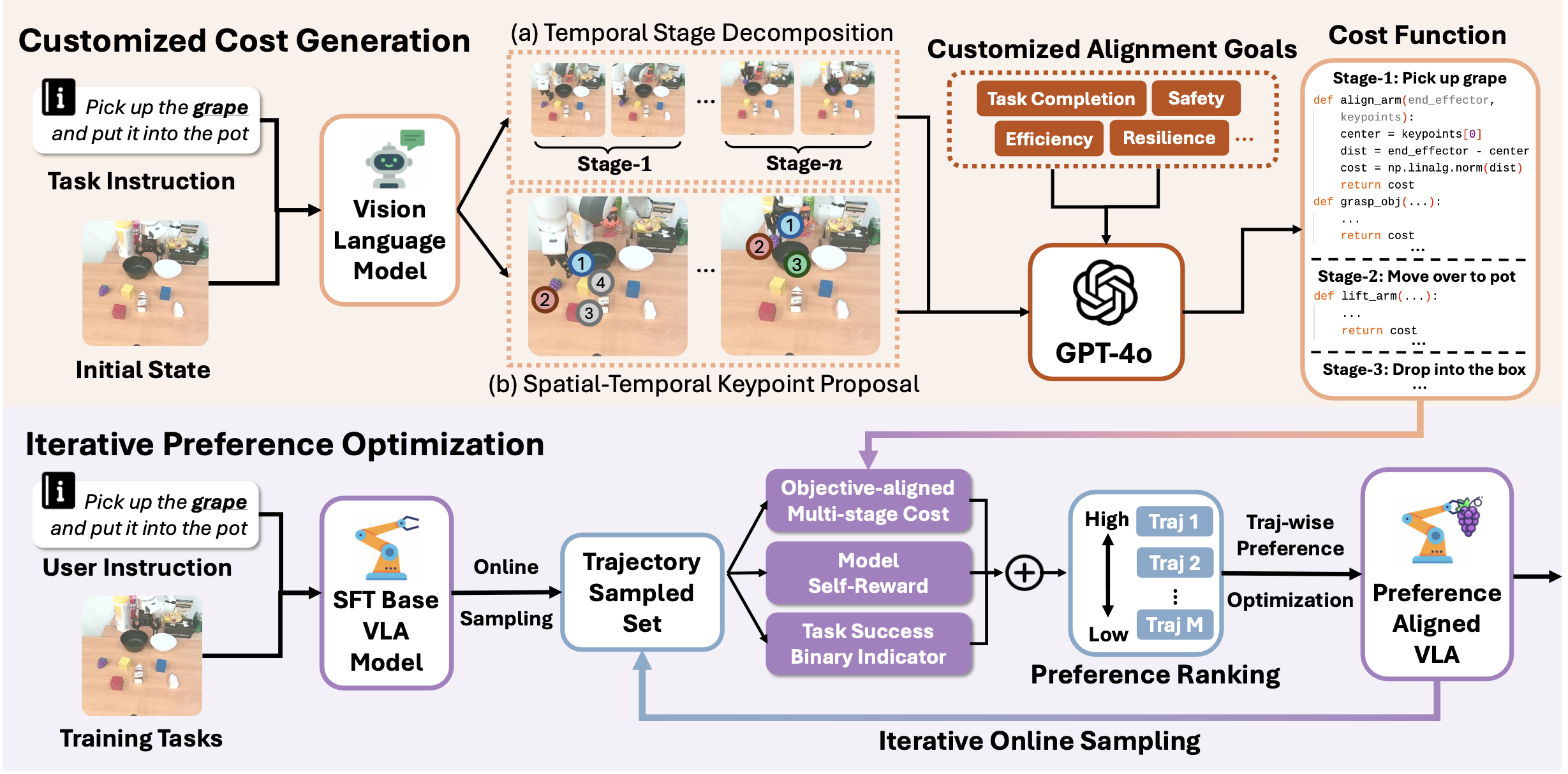
在推理过程中,VLA 通常使用任务指令 q 进行初始化,并且在每个时间步 t,它获取环境观察 o_t(通常是图像)并输出动作 a_t,其中我们可以将 π_θ(a_i|(o_i, q)) 表示为由 θ 参数化的 VLA 的动作策略。为了完成任务,VLA 会迭代地与环境交互并获得长度为 T 的轨迹 ζ = {o_1, a_1, · · · , o_T , a_T |q}。通常,VLA 会通过 SFT 进行微调以模仿专家行为。
轨迹偏好优化(TPO)
为了提升泛化能力,遵循 Schulman (2017) 和 Bai (2022) 的研究,进一步通过强化学习目标微调 VLA 策略。令 r_φ 表示以 φ 为参数的奖励函数,则有
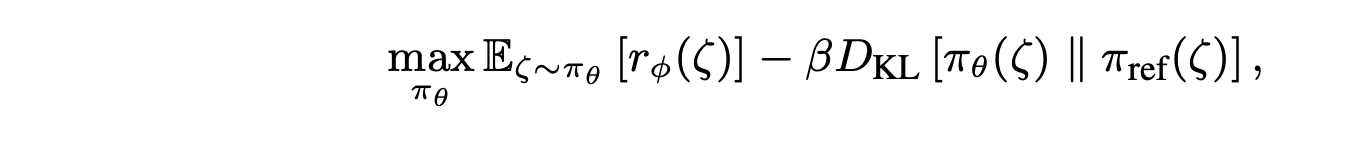
遵循 Rafailov (2024) 的研究,推导出轨迹奖励 r(ζ) 的解析重参数化公式,如下所示:
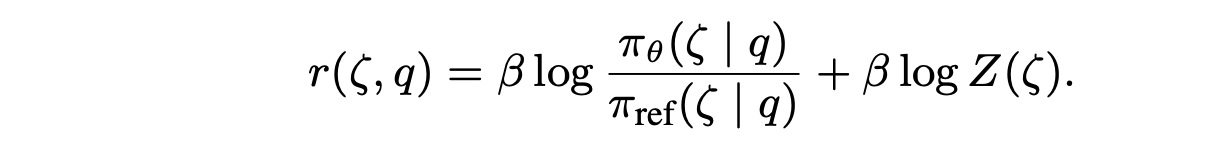
具体来说,令 ζ_w 和 ζ_l 分别表示从相同初始状态开始的选择轨迹和拒绝轨迹,可以将轨迹奖励建模目标表述为:
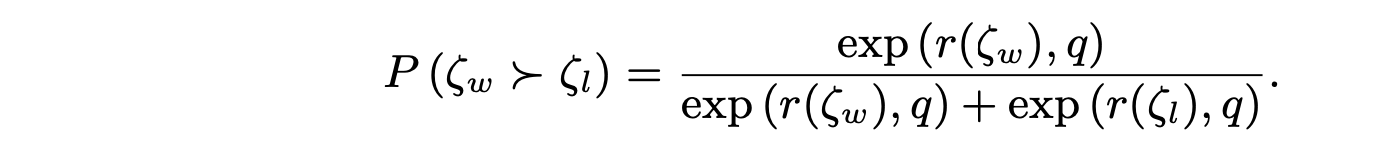
然后,按照 Rafailov (2024) 的方法,得到等价的轨迹偏好优化 (TPO) 损失 L_TPO:
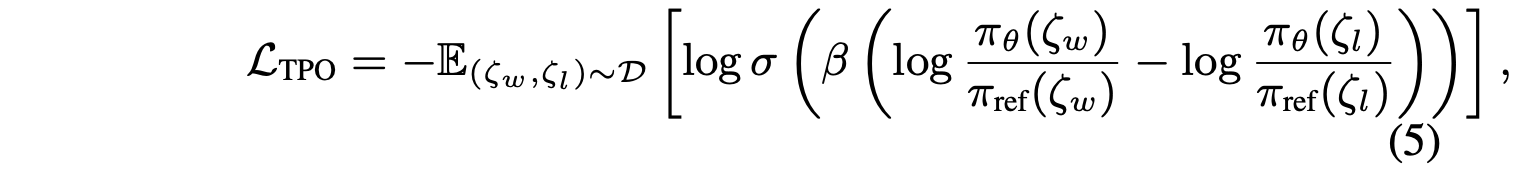
可以进一步利用 MDP 将一个轨迹 ζ 的似然分解为各个状态-动作对,然后得到:
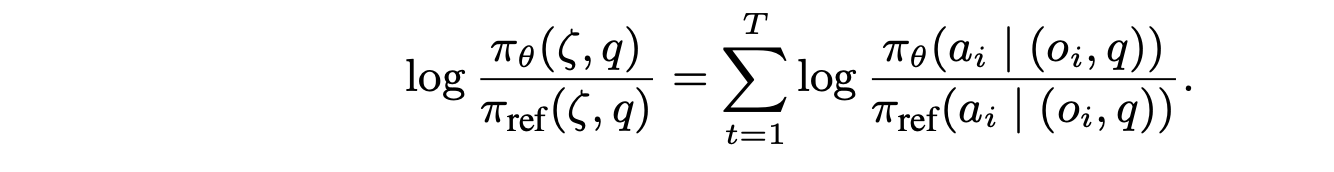
这样的TPO 损失方程非常有益,因为它:(1) 只需使用 VLA 收集的逐步展开,即可在轨迹级别将策略 π_θ 全局地与人类偏好对齐;(2) 通过在轨迹上的所有状态-动作对中反向传播梯度,它稳定策略并使其朝着最终目标前进;(3) 通过 RL 目标从成功和失败的轨迹中学习,它显著提高泛化能力。尽管 Finn (2016) 指出扩大采样轨迹的大小可以减少奖励建模中的偏差,但这也会增加训练成本。因此,虽然本方法可以轻松扩展,但其讨论仅限于二元情况,即只存在一个选择/拒绝的轨迹。
引导-成本偏好生成(GCPG)
虽然给定TPO目标方程,可以将策略与任意目标(这些目标通过按相应偏好排序的轨迹定义)进行对齐,但这会产生高昂的成本,因为它需要人类的专业知识和冗长的手动注释。因此,为了更好地将偏好合成扩展到任意对齐目标(例如,任务完成、安全性、效率),本文提出引导-成本偏好生成(GCPG)方法,以自动整理整合不同对齐目标的偏好。
多-阶段时间关键点约束
基于 Huang (2024) 的见解,将轨迹分解为多个时间阶段并分配成本以量化每个阶段的性能,解决为复杂操作任务指定精确轨迹偏好的复杂性。然后,汇总这些特定于阶段的成本,以获得对每条轨迹的整体评估。具体而言,采用基于 VLM 的阶段分解器 M_D,将轨迹 ζ 划分为一系列 S 个连续阶段,公式如下:
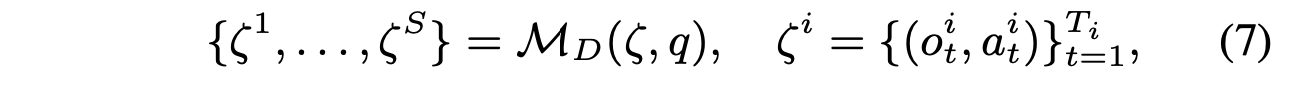
在获得阶段分解后,进一步采用视觉-语言模型(例如 DINOv2 (Oquab et al., 2023))来识别关键点,这些关键点可作为每个阶段的参考指标。然后,利用强大的 LLM (Achiam et al., 2023) 为每个与对齐目标对应的阶段提出成本函数,其中成本越低,目标一致性越好。具体而言,阶段 S_i 的成本 CS_i({κ_S_i }) 是使用其对应的关键点 {κ_S_i } 计算的。
然后,为了汇总整个轨迹的成本,采用指数衰减来捕捉每个时间阶段的因果依赖关系(例如,如果一条轨迹在前几个阶段的成本很高,则预计后续阶段的表现不会很好),并将其定义为外部奖励:

其汇总每个阶段的各个成本和子目标,以解决维数灾难并有效地坚持定制化对齐。
引导-成本偏好生成
为了进一步提高偏好合成的稳定性和最优性,借鉴自我奖励(Zhou et al., 2024b)的思想,认为更优的轨迹应该由外部评判者(如公式 (8) 所示)和模型本身共同确认。因此,引入两个额外的奖励,并得到 GCPG 奖励:
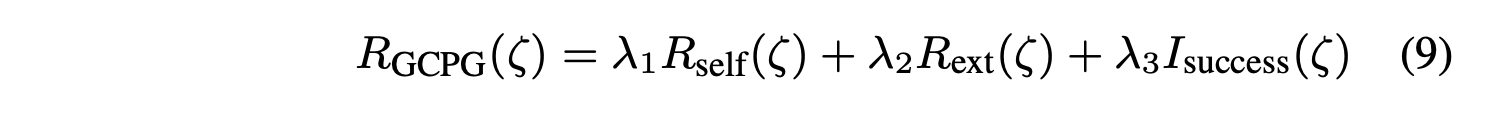
其中 R_self(ζ) 是由 π 提供的自我评估分数,π 等于生成轨迹 ζ 的对数似然:
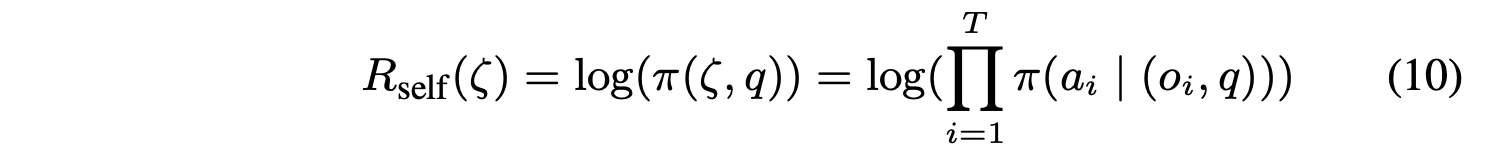
I_success(ζ) 是一个二元指示函数,用于指示轨迹 ζ 是否成功完成任务:
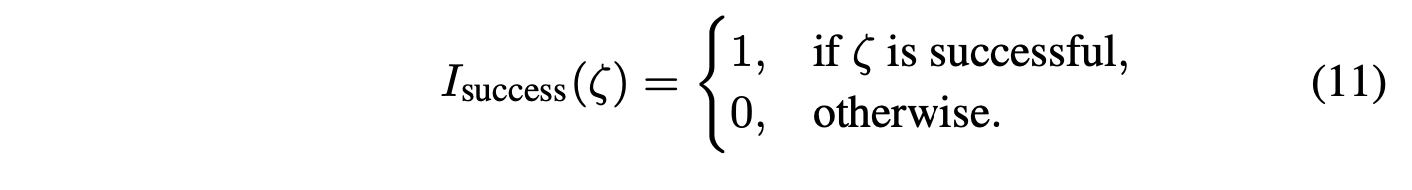
其中 λ 是调整每个奖励重要性的权重参数。直观地,公式 (10) 可以看作是公式 (11) 提供的稀疏信号稠密近似,并通过公式 (8) 进一步对齐,以获得对轨迹的整体评估,该评估既考虑了轨迹的最优性,也考虑了其与公式 (8) 中外部奖励指定的自定义目标的一致性程度。
迭代偏好优化
受在线策略强化学习 (Schulman et al., 2017) 实践的启发,这些实践通常比离线策略训练能产生更优的策略,利用在线收集的轨迹,通过 TPO 迭代地微调 SFT VLA 模型。例如,在第 k 次迭代中, (1) 首先针对各种任务采样大量轨迹并获得 Dk;(2) 然后使用公式 (9) 计算每条轨迹的成本,并根据每个任务对这些轨迹进行相应的排序; (3)将每个任务的前 m 条轨迹和后 m 条轨迹配对,得到 m2 个选择-拒绝轨迹对;(4)然后,根据公式(5)使用 TPO 对相同的采样策略进行微调,得到更新后的策略。将此过程迭代 K 次,得到与目标函数一致的最终模型。在如下算法 1 中详细介绍 GRAPE 迭代偏好优化过程:

实施细节。采用 OpenVLA (Kim et al., 2024) 作为主干模型,并使用 AdamW 优化器对 LoRA 进行微调,进行监督微调和偏好微调。在监督微调阶段,用 4 × 10−5 的学习率和 16 的批次大小。对于偏好微调,应用 2 × 10−5 的学习率和相同的批次大小。
基线模型。首先将 GRAPE 与两种领先的机器人学习模型进行比较,这两种模型以其在机器人控制任务中的强大性能而闻名。第一个模型 Octo (Team et al., 2024) 是一个基于大型 Transformer 的策略模型。第二个模型 OpenVLA (Kim et al., 2024) 是一个 7B VLA 模型。这两个模型都使用从相应环境中采样的相同数据集进行了监督微调。将监督微调模型分别表示为 Octo-SFT 和 OpenVLA-SFT。此外,我们还比较采用轨迹偏好优化的 GRAPE 与原始的逐步直接偏好优化(OpenVLA-DPO),后者直接训练以优化每一步定义的偏好。
仿真评估设置。参照 Kim (2024) 的研究,在两个机器人模拟环境中评估 GRAPE 的性能:Simpler-Env (Li et al., 2024a) 和 LIBERO (Liu et al., 2023)。在 Simpler-Env 中,从三个方面评估模型的域内性能及其泛化能力:主体泛化(泛化到未见物体)、物理泛化(泛化到未见物体的大小/形状)和语义泛化(泛化到未见指令)。在 LIBERO 中,针对四项任务测试模型:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-Long。所有任务均为领域内任务。
真实环境评估设置:针对 30 个任务进行 300 次真实世界实验,以评估 GRAPE 的泛化能力。评估重点关注分布内评估和五种分布外泛化类型:视觉泛化、主体泛化、动作泛化、语义泛化和语言基础泛化。其中,视觉泛化评估适应新视觉环境的能力;主体泛化评估对不熟悉物体的识别和处理能力;动作泛化衡量跨不同动作的表现;语义泛化评估对具有相似含义的提示的响应能力;语言基础泛化衡量对空间方向的理解能力。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)