QLoRA微调 & GGUF
QLoRA微调 & GGUF
一、QLoRA指令微调
1.1 QLoRA概念
QLoRA 是一种高效的大型语言模型微调方法,它显著降低了内存使用量,同时保持了全 16 位微调的性能。它通过在一个固定的、4 位量化的预训练语言模型中反向传播梯度到低秩适配器来实现这一目标。
1.2 QLoRA介绍
我们在训练模型的时候,批次越大,模型训练的越快、效果越好,但是如果模型的参数固定是16位的情况下,微调批次batch一般不会设置很大。为了加速模型训练,可以用8位或者4位来替代训练过程中16位的运算,当我们把16位降到8位或者降到4位的时候,显存占用就降低了,批次就可以调整更大,模型训练起来就会更快。这种训练方式并没有改变模型的参数数量,只是降低了模型的计算精度而已。
1.2.1 QLoRA是否会降低精度
在使用QLoRA之前有一个问题:前面使用量化导出的时候是牺牲精度为代价提升性能,那么在训练过程中使用量化是否会降低模型的的精度呢?答案是不会降低模型的精度。
-
量化导出过程是在模型参数已经固定的情况下,进行量化后再导出,这样降低了原模型的参数精度,它的计算结果发生了变化。在量化部署过程中,由于模型的参数已经固定了,所以降低精度一定会影响结果。
-
在训练过程中模型的参数并未固定,依然处于持续学习状态,所以降低训练过程中的参数精度,对模型的结果不会有太大影响。真正情况下,几乎是没影响的,AI训练的目的、结果不是具体的数值,而是一种趋势。因此在训练过程中数据的精度对AI的模型的效果影响不大。
1.2.2 从数学视角理解QLoRA
在深度学习中,损失函数(Loss) 可以被形式化地看作一个关于输入 x、真实标签 y 以及模型参数 W 的函数:
L(W;x,y) L(W;x,y) L(W;x,y)
尽管实际模型的参数空间维度极高(W∈Rd,其中 d 可达数十亿),为便于直观理解,我们可以将其简化为二维情形进行类比:将 L 视为定义在参数平面上的一个曲面。
模型训练的本质,就是在该高维损失曲面上寻找使 L 最小化的参数 W∗W^∗W∗,这一过程通过梯度下降等优化算法实现,依赖于对 L 关于 W 的偏导数(即梯度)进行迭代更新。
当我们采用 QLoRA 等参数高效微调方法时,会对模型参数进行低精度量化(例如从 FP16 降至 FP16)。这种操作并非仅降低单个参数的精度,而是对整个可训练参数子集施加统一的数值压缩。
从几何角度看,这种量化相当于对原始损失函数 L(W) 进行了一种近似映射或“压缩”,得到一个新的、离散化的损失曲面 L~(W)。该曲面的形状(如局部起伏、曲率)可能与原函数略有差异,但其全局极小值点(或接近最优的区域)在理想情况下应保持不变——因为量化通常保留了参数的主要方向和相对关系,尤其是当结合低秩更新(LoRA)时,关键信息集中在少量可学习矩阵中。
因此,尽管量化会导致训练过程中观测到的 Loss 值发生一定扰动,只要量化误差可控且优化路径未偏离,最终收敛到的解 W∗∗W^**W∗∗仍能逼近原始高精度下的最优解 W∗W^*W∗。换言之,目标函数的极值位置并未发生本质改变,只是我们在一个“压缩版”的损失景观中进行搜索。
这解释了为何 QLoRA 能在大幅降低显存和计算开销的同时,依然保持与全精度微调相近的性能。
1.2.3 深度理解 QLoRA
QLoRA(Quantized Low-Rank Adaptation)是一种高效的参数微调方法,其核心思想是:在训练过程中对模型权重进行量化以节省显存,但计算仍以高精度执行,从而在显著降低资源消耗的同时保持接近全精度微调的性能。
1、量化仅作用于存储,不影响模型参数的原始数据类型
QLoRA 中的量化仅发生在模型权重加载到显存后的存储阶段,并不改变模型本身的参数数据类型。
例如,若原始模型权重为 float16,在 QLoRA 训练时,这些权重会被量化为低精度格式(如 int4)以减少显存占用;但在实际前向/反向计算时,会即时反量化回 float16 进行运算。
✅ 关键点:量化是“存储时压缩,计算时还原”。因此,
QLoRA不会改变模型最终保存的参数类型——微调完成后导出的LoRA适配器或合并模型,依然以原始精度(如float16)存在。
2、QLoRA 并非对“核心权重”做永久量化
QLoRA 不对预训练权重本身进行永久性量化修改,而是:
- 将整个基础模型以低精度(如 4-bit)加载到显存中;
- 立即冻结这些量化后的权重,使其在训练中不可更新;
- 所有可训练参数仅来自新增的
LoRA低秩矩阵(通常以float16存储和计算)。
这种设计使得:
- 显存占用大幅降低(因 基座模型 以 8-bit 存储);
- 计算精度不受损(因计算时反量化 +
LoRA用高精度训练); - 训练效率显著提升,尤其适用于大模型在消费级
GPU上微调。
3、为何需要量化?——显存瓶颈的现实考量
在大批量训练场景下,若不使用量化,显存极易耗尽(“OOM”)。而 QLoRA 通过压缩基座模型的存储空间,释放出足够显存来容纳更大的 batch size 或更长的上下文长度,从而提升训练稳定性与收敛速度。
4、QLoRA 的效果是否一定更好?
在相同模型架构、相同数据集、相同训练配置下,QLoRA 微调的 Loss 下降趋势通常优于或至少接近全参数微调(尤其是在资源受限场景下),但这并非绝对。其最终性能主要受两个关键超参数影响:
LoRA秩:控制低秩矩阵的宽度;LoRA缩放因子:常与rank配合使用,影响更新幅度。
一般而言,增大 rank 或 缩放因子 可提升模型表达能力,使 Loss 降得更低、任务表现更好。但需注意:
⚠️ “更大 ≠ 更好”:当 rank 过大(如超过 128),不仅显存开销显著增加,还可能因过拟合小规模数据而导致泛化性能下降。
5、数据规模与模型容量的匹配问题
当前大模型参数量动辄数十亿甚至千亿,而许多应用场景下的微调数据集却相对较小(如几千至几万条样本)。在这种**“大模型 + 小数据”** 的设定下,即使使用 QLoRA,模型性能的提升也可能不够显著——有时甚至依赖一定的“随机性”(如初始化、数据采样顺序)才能观察到明显差异。
因此,不能期望 QLoRA 在所有小数据场景下都带来巨大收益,需结合任务复杂度、数据质量与数量综合评估。
6、LoRA 模型大小由什么决定
最终 LoRA 适配器的参数量由两方面共同决定:
- Base 模型的规模:模型越大(如 7B → 70B),可插入
LoRA的层越多,总参数量自然更高; - LoRA 超参数设置:主要是 rank r 和目标模块数量(如是否覆盖所有 attention 和 MLP 层)。
例如,对一个 7B 模型,若在所有线性层启用 LoRA 且 rank=64,则新增参数可能达数千万;而若仅在 Q/K/V 投影层启用且 rank=32,则参数量可能仅百万级。
7、LoRA 秩的推荐范围
实践中,LoRA秩 设置在 32~128 之间通常能取得较好效果。低于 32 可能表达能力不足,高于 128 则显存与计算开销急剧上升,且边际收益递减。因此,建议,LoRA秩从 64 开始尝试,并根据任务复杂度和资源情况调整。
二、Llamafactory微调多轮对话
2.1 准备多轮对话数据集
下面使用 QLoRA 微调多轮对话数据集:财经类fintech.json。
- 要注意的是:
history里放的是最早的这是上一轮的结果,instruction和output是最后一轮对话。
2.1.1 配置多轮对话数据集
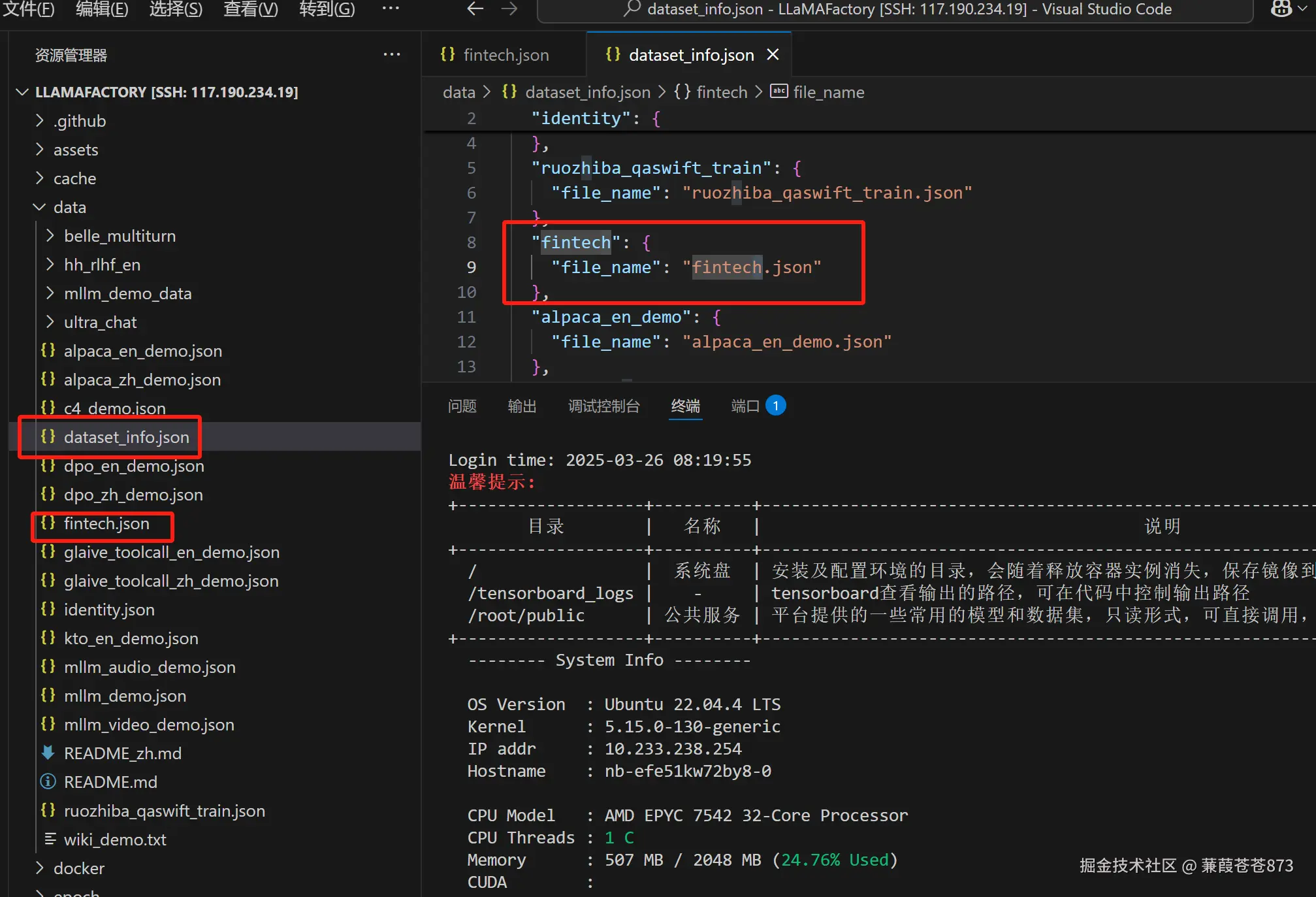
在
dataset_info.json配置文件中配置fintech.json数据集。
2.1.2 QLoRA配置
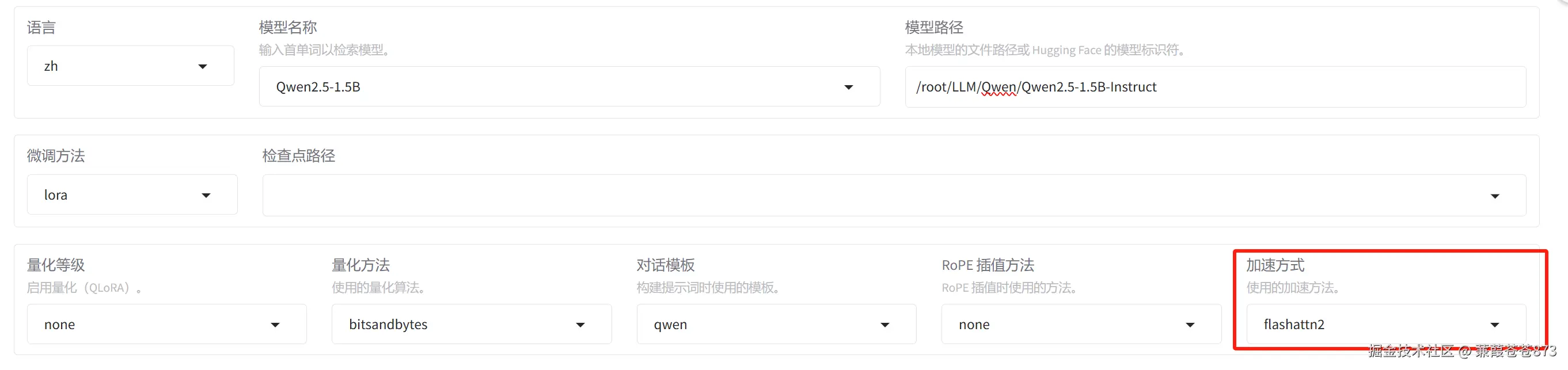
微调方法:
QLoRA微调与LoRA微调方法,此处均选择LoRA;量化等级:一般
QLoRA微调选择8位就可以,LoRA微调选择none;
Flash Attention是一个高性能的注意力机制实现库,主要用于加速和优化大型语言模型和其他基于Transformer架构的深度学习模型;
使用QLoRA时显存占用一定比量化之前低,虽然说做量化的目的是为了节约显存,但节约的显存其实是有限的,不像量化部署时节约的显存。

2.2 准备环境
准备 llamafactory微调环境。
1、新建一个Conda环境
$ conda create -n LlamaFactory python==3.10
- 这里使用
python3.10版本因为版本能兼容大多数的东西
2、激活Conda环境
$ conda activate LlamaFactory
# 或者
$ source activate LlamaFactory
3、先安装 vLLM
# 这里vllm和llamaFactory要装一个环境去
$ pip install vllm
4、再安装最新版本的 llamaFactory
# 从 github上下载最新版本的 llamaFacotry
git clone https://github.com/llama-factory/llamafactory.git
# 然后安装依赖
$ pip install -e ".[bitsandbytes]"
5、然后检查版本
$ nvcc -V
$ pip list | grep -E "torch|transformers|bitsandbytes|triton|accelerate|peft"

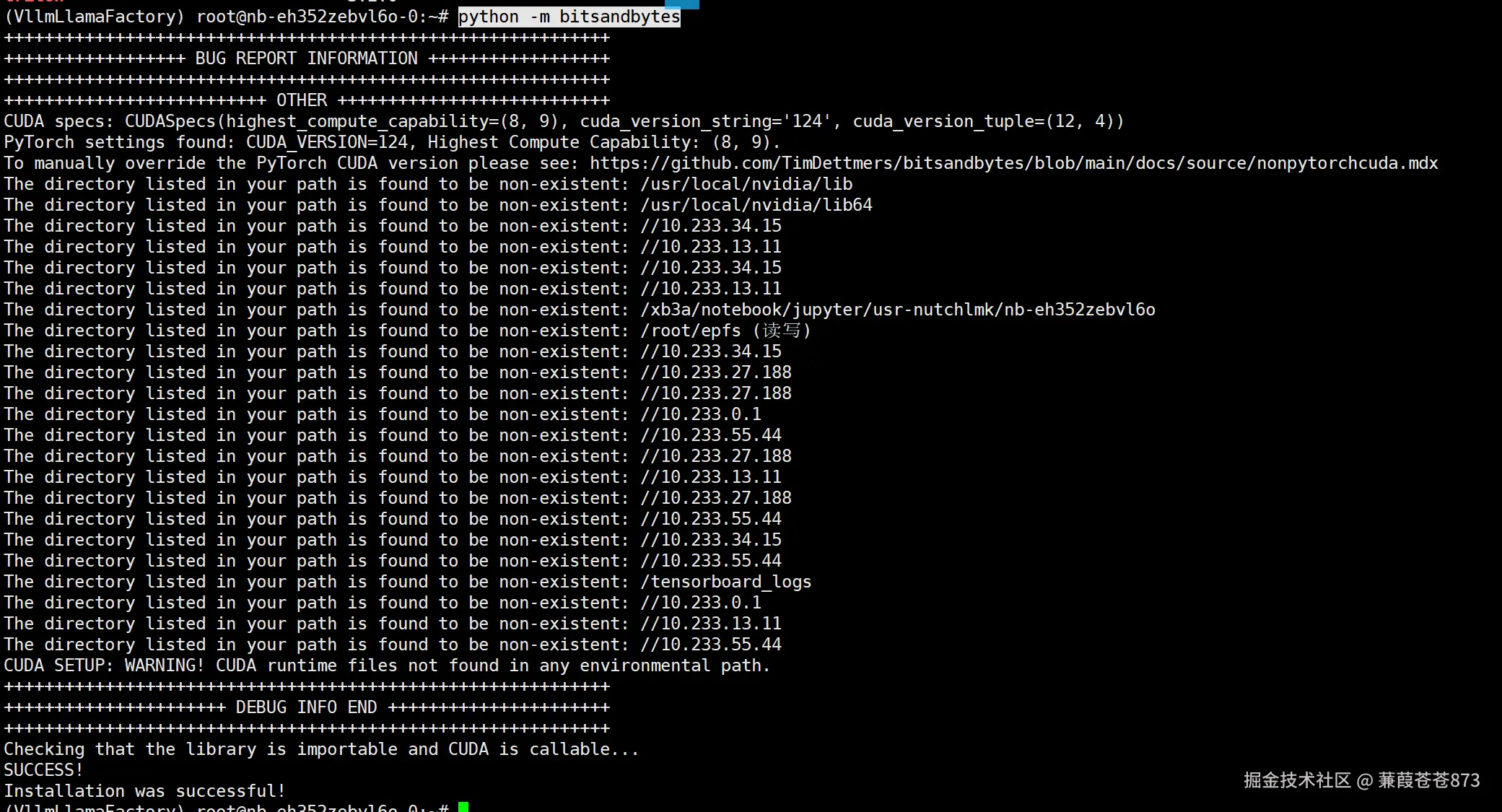
6、检查CUDA与bitsandbytes是否兼容
# 这里不报错基本就是成功了
$ python -m bitsandbytes
如果不兼容的话使用下面命令获取最新版本,或者用==指定版本
$ pip install bitsandbytes --upgrade
$ pip install peft --upgrade
7、启动 llamaFactory
$ DISABLE_VERSION_CHECK=1 llamafactory-cli webui
2.3 测试结果
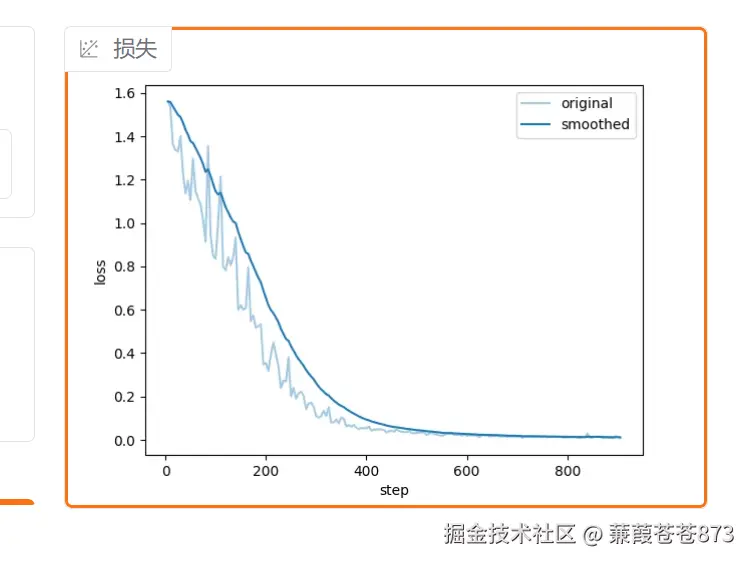
800个step后的损失图如下,基本处于收敛状态。
2.4 模型推理
2.4.1 huggingFace 推理引擎
在
llamafactory界面选择huggingFace推理引擎:

推理结果如下:


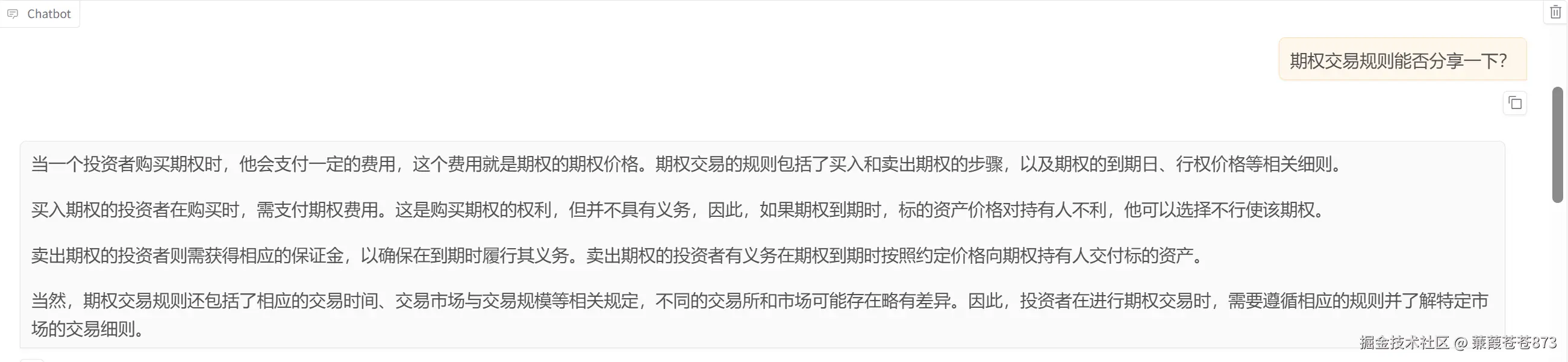
2.4.2 vllm 推理引擎
在
llamafactory界面选择vllm推理引擎:

2.4.3 单独使用推理引擎vllm
将微调后的模型进行合并,单独使用
vllm推理:
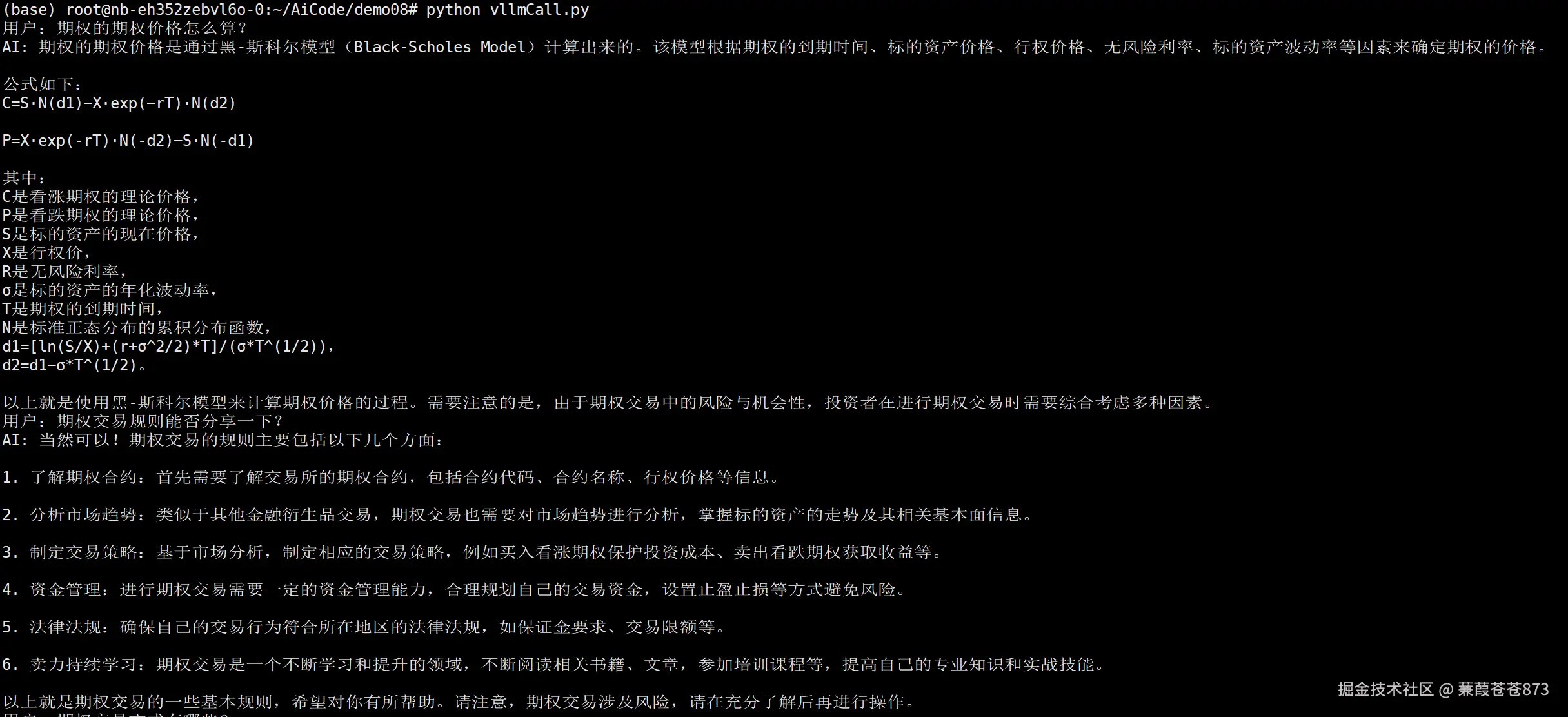

我们注意到:直接使用
vLLM部署模型时的输出,与LLaMA-Factory中使用vLLM引擎的结果存在明显差异。
通常情况下,我们的工作流程是:
- 在
LLaMA-Factory中完成模型的微调训练; - 微调完成后,在
LLaMA-Factory的Chat界面中选择vLLM作为推理引擎进行测试; - 最终将模型单独通过
vLLM部署上线。
按照理想情况,第 2 步和第 3 步的推理结果在语义上应当完全一致(注意:这里“一致”并非指逐字相同,而是指输出内容的含义、风格和逻辑保持一致)。如果两者出现显著偏差,通常可归因于以下三个原因:
- 模型未正确合并:微调后的适配器(如
LoRA)未与基础模型合并,导致部署时加载的是原始基座模型。 - 对话模板(
chat template)不一致:这是最常见的问题。LLaMA-Factory在推理时会自动应用特定的对话模板(如llama-3、chatml等),而独立部署vLLM时若未显式指定相同的模板,输入格式就会不同,从而导致输出差异。 - 基础模型(
base model)选择错误:在合并模型时虽然操作正确,但选错了base模型版本(例如误用了不同版本或不同架构的基座模型)。
在本次情况中,问题根源正是 第 2 点——对话模板不一致。
三、GGUF格式
3.1 什么是GGUF
GGUF 格式的全名为(GPT-Generated Unified Format),是由 Hugging Face 团队推出的一种用于存储和部署机器学习模型的文件格式,提到 GGUF 就不得不提到它的前身GGML (GPT-Generated ModelLanguage)。
GGML 是专门为了机器学习设计的张量库,最早可以追溯到 2022/10,其目的是为了有一个单文件共享的格式,并且易于在不同架构的 GPU 和 CPU 上进行推理。但在后续的开发中,遇到了灵活性不足、相容性及难以维护的问题,所以 GGUF 取代了早期的 GGML 格式,它的核心目标是提升模型的灵活性、可扩展性和跨平台兼容性,尤其适配大语言模型(如 Llama 系列)及其他生成式AI模型的推理需求。
3.2 为什么要转换 GGUF 格式
在传统的 Deep Learning Model 开发中,大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题,于是有了 GGML、GGMF、GGIT 等格式,而在开源社群不停的选代后 GGUF 格式就诞生了。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括:
- 可扩展性:轻松为
GGML架构下的工具添加新功能,或者向GGUF模型添加新Feature,不会破坏与现有模型的兼容性(模型打完包之后,可以更改它的模型结构,这种扩展不会破坏与现有模型的兼容性)。 - 对
mmap(内存映射)的兼容性:该模型可以使用mmap进行加载(原理解析可见参考),实现快速载入和存储。 - 易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的
Librany,同时对于不同编程语言支持程度也高(跨平台移植非常强) - 模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件(传统的
HuggingFace模型:一个文件后面有一大堆配置文件,只要有一个配置文件出问题了,模型就挂了)。 - 有利于模型量化:
GGUF支持模型量化(4 位、8位、F16),在GPU变得越来越昂贵的情况下,节省vRAM成本也非常重要。(现在模型很多是F16,也可以不量化直接变成GGUF格式)
3.3 llama.cpp转换模型为GGUF
1、创建并激活 llama.cpp 的环境
$ conda create -n llamaCpp python==3.10 -y
$ source activate llamaCpp
2、获取 llama.cpp 仓库
$ git clone https://github.com/ggml-org/llama.cpp
- 没有版本依赖,可以不用创建虚拟环境直接装即可
3、安装 llama.cpp 运行环境依赖包
$ pip install -r /root/llama.cpp/requirements.txt
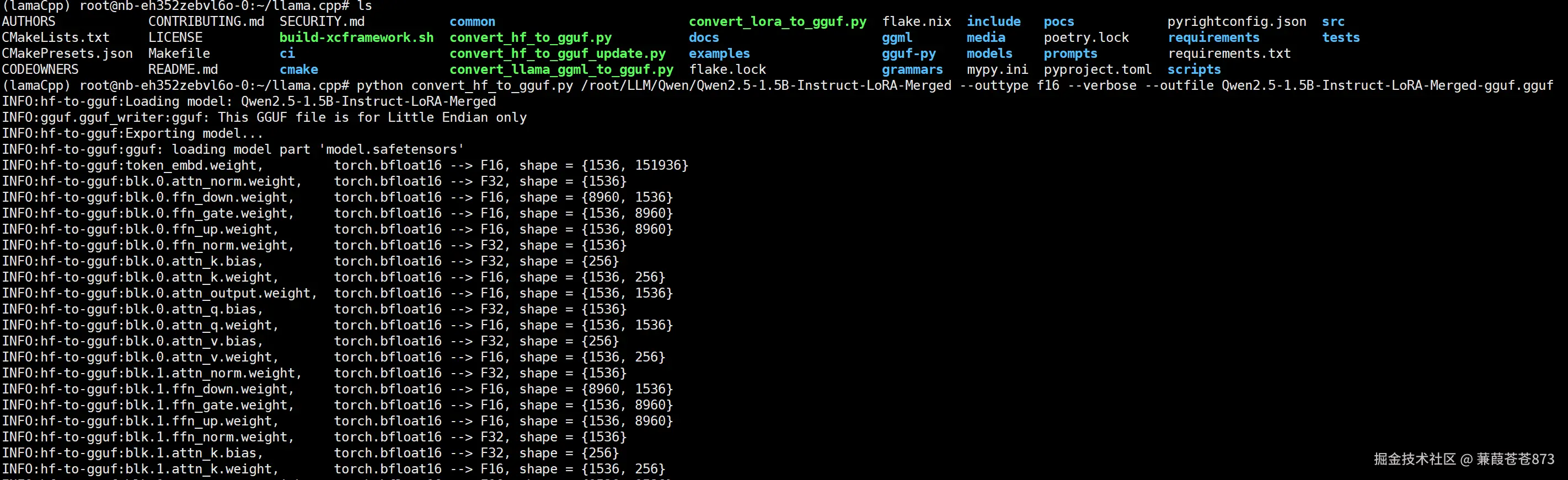
4、执行格式转换
一般来讲格式转换步骤:先把模型合并成 HuggingFace格式,之后再转换成 GGUF 格式,会用到 convert_hf_to.gguf.py文件。
- 如果不量化,保留模型的效果
$ python convert_hf_to_gguf.py /root/LLM/Qwen/Qwen2.5-1.5B-Instruct-LoRA-Merged --outtype f16 --verbose --outfile /root/ollama/Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf.gguf

- 如果需要量化(加速并有损效果),直接执行下面脚本就可以 ,它速度会更快,文件会更小。但是它的精度就没有那么高了
$ python convert_hf_to_gguf.py /root/LLM/Qwen/Qwen2.5-1.5B-Instruct-LoRA-Merged --outtype q8_0 --verbose --outfile /root/ollama/Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf_q8_0.gguf
这里 --outtype 是输出类型,代表含义:
-
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别; -
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。 -
q4_0:这是最初的量化方案,使用4位精度。 -
q4_l和q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景,最大的模型是q4_l,最小的模型是q4_k_s,就是看更偏向于精度高还是性能高,但是没什么实用性,因为拿到量化上面来讲,既然都已经做了量化了,就不分大尺寸和小尺寸。一般就只是量化和不量化,量化就是八位或者是四位。 -
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较 慢。 -
q6_k和q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户,一般选择选择q8_0 -
q8_0:他的精度最高,消耗的资源也高,但推理速度会慢一些,如果显卡比较弱就不推荐使用。 -
fp16和f32:FP16和F32是不量化,保留原始精度的。具体选择是FP16还是F32,得看你的模型。因为现在大多数的大模型的类型都是FP16,F32也是不量化的32位的模型,但是现在32位的模型很少了。
四、使用Ollama运行GGUF
下面使用 Ollama 推理 GGUF 格式的大模型!
1、启动 Ollama 服务
$ ollama serve
2、创建 ModelFile
GGUF格式文件路径:
FROM /root/LLM/Qwen/Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf.gguf

3、创建自定义模型
- 使用
ollama create命令创建自定义模型
# gguf文件和ModelFile 得在同一个目录下才行
$ ollama create Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf --file ModeFile
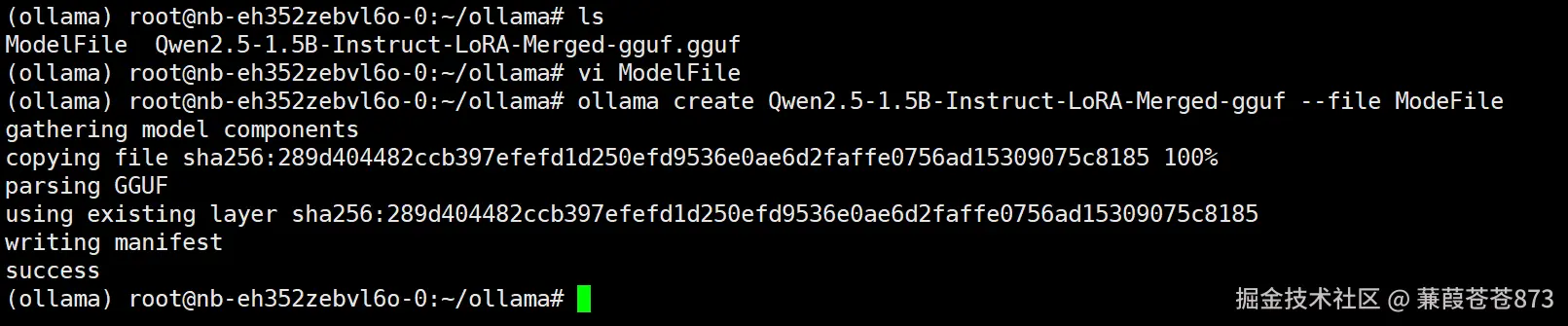
ollama list:查看ollama加载到本地的模型列表

4、运行模型
$ ollama run Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)