静默超时:一次 Pending Pod 背后的 Kubernetes 存储控制流崩塌
本文深入分析了Kubernetes中一个Pod卡在Pending状态的典型案例,揭示了其背后存储系统的复杂机制。通过解构PV/PVC/StorageClass三层架构的设计哲学,详细追踪了从Pod到云API的12层调用链。文章不仅提供了具体的排查路径和诊断方法,更从系统工程角度反思了分层解耦带来的可观测性挑战,提出了控制流穿透、混沌工程等进阶解决方案,为云原生环境下的存储问题诊断提供了系统性思考框
目录
三、技术深潜:VolumeBinding超时的根因定位与系统级诊断
0. 存储供应全景图:从Pod到Cloud API的12层调用链
2. PVC Events 深度解读 —— 控制平面的求救信号
一、故障现场:一个“安静”的Pending Pod
在一次常规的 CI/CD 部署过程中,我们遇到了一个“经典但隐蔽”的问题:
kubectl get pod -n production webapp-76f8c9d5b4-2xklp
NAME READY STATUS RESTARTS AGE
webapp-76f8c9d5b4-2xklp 0/1 Pending 0 8mPod 卡在 Pending 状态长达 8 分钟。第一时间执行标准诊断流程:
kubectl describe pod webapp-76f8c9d5b4-2xklp -n production
关键错误信息如下:
Warning FailedScheduling 5m42s default-scheduler
running PreBind plugin "VolumeBinding": binding volumes: timed out waiting for the condition这行报错乍看之下晦涩难懂,但它直指 Kubernetes 存储系统的核心组件 —— PV、PVC 和 StorageClass
本文将带你从底层机制出发,深入分析该错误的本质,并提供可落地的排查路径和最佳实践建议。
二、核心概念与设计哲学:PV/PVC/SC的深度解耦
在上一部分中,我们分析了一个典型的部署故障:“timed out waiting for the condition”。要真正理解这类问题的根源,我们先回到起点:Kubernetes 为何要设计 PV、PVC 和 StorageClass 这三个看似复杂的抽象层?
这不仅是架构选择,更是云原生时代对 关注点分离(Separation of Concerns)、自动化运维和环境可移植性 的深刻回应。
2.1 三剑客:PV/PVC/SC的本质定义
|
组件 |
全称 |
类型 |
所属命名空间 |
谁创建 |
核心作用 |
|
PV |
PersistentVolume |
集群资源 |
❌ 集群级别 |
管理员 or 系统 |
表示实际的存储设备(如 EBS 卷、NFS 目录) |
|
PVC |
PersistentVolumeClaim |
命名空间资源 |
✅ 属于命名空间 |
开发者/应用 |
用户对存储的“请求”——我要多大容量?是否可读写? |
|
SC |
StorageClass |
集群资源 |
❌ 集群级别 |
管理员 |
定义如何动态创建 PV 的“模板”,实现按需供应 |
核心洞察:
- PV = 物理硬盘
- PVC = 用户申请表:“我需要一块 50GB SSD”
- StorageClass = 工厂生产线:“收到申请后自动生产匹配的硬盘”
Kubernetes通过这种三级抽象,它们共同构成了一个 声明式、解耦、可扩展的持久化存储管理体系。
2.2 为什么在K8s中需要将存储抽象为PV和PVC两个对象,而不是让Pod直接声明所需存储?
将存储抽象为 PersistentVolume(PV)和 PersistentVolumeClaim(PVC)两个对象,主要是为了实现关注点分离和解耦。
PVC 作为用户侧的“存储接口”,由应用开发者定义所需的存储大小、访问模式等需求,而无需关心底层存储的具体实现;PV 则由集群管理员或自动化系统(如 CSI 驱动)提供,代表实际的存储资源(如云盘、NFS、Ceph 等)
若让 Pod 直接声明具体存储(如 hostPath 或特定后端),会导致应用与基础设施强耦合,降低可移植性,并要求开发者具备底层存储专业知识
2.3 为什么StorageClass被设计为动态供应存储的核心机制,而非静态预配?
这触及了 Kubernetes 存储架构设计的核心理念:自动化、弹性与云原生哲学,是因为它的根本目标是实现“按需自动创建存储”,解决传统静态 PV 预配带来的资源浪费、运维复杂和无法弹性伸缩等问题。
换句话说:
❌ 静态预配 = “先造好桌子,等人来坐” → 容易空置或不够用;
✅ StorageClass 动态供应 = “有人来了再现场做一张合适的桌子” → 按需分配,高效灵活。
2.4 这种解耦在实际CI/CD场景中带来了哪些具体优势或复杂性?
1. 环境一致性与可移植性:应用清单(如 Helm Chart)可仅包含 PVC 声明,而不绑定具体存储后端。同一套代码可在开发、测试、生产等不同环境中部署,只要各环境配置了兼容的 StorageClass,即可自动获得适配的 PV,极大提升流水线的通用性。
2. 权限分离与安全合规:PVC/PV 模型允许开发侧只提交声明式需求,而 PV 的创建和管理由运维或平台团队通过独立流程控制,符合最小权限原则。
3. 支持动态供应与自助服务:结合 CSI 和 StorageClass,PVC 可触发自动创建云盘等资源,使开发团队在不依赖人工干预的情况下获得持久化存储,加速交付流程。
然而,也引入一定复杂性:
- 初始配置成本:需预先正确部署 CSI 驱动、配置 StorageClass,并确保命名空间策略允许 PVC 创建,增加了平台搭建门槛。
- 调试难度增加:当 PVC 卡在 Pending 状态时,需跨多层排查(PVC 配置 → StorageClass → CSI Driver → 云平台配额/API 权限),对运维人员要求更高。如何本文遇到的Pending 问题
三、技术深潜:VolumeBinding超时的根因定位与系统级诊断
“timed out waiting for the condition” —— 将通过控制平面组件交互图谱、gRPC调用链追踪、etcd事务分析三大维度,揭示其后的系统级真相。
0. 存储供应全景图:从Pod到Cloud API的12层调用链
要精准定位VolumeBinding超时,必须理解动态存储供应的完整调用链。这不是简单的"Pod→PVC→PV"线性关系,而是一个涉及12个关键组件、3类gRPC接口、5种状态机的复杂系统:
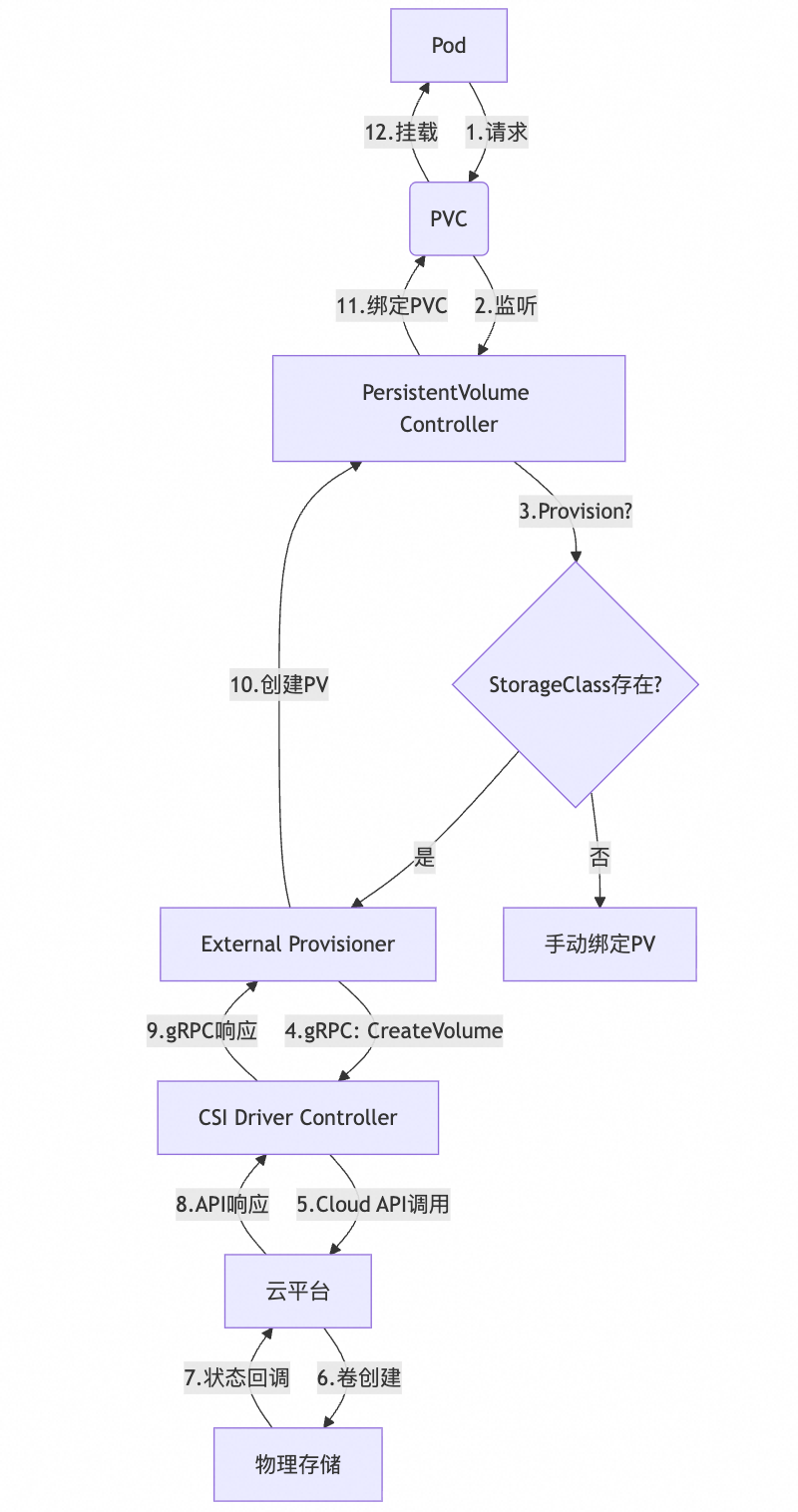
1. Pod Events 分析 —— 故障表象定位
kubectl describe pod webapp-76f8c9d5b4-2xklp -n production输出关键事件:
Warning FailedScheduling 5m42s default-scheduler
running PreBind plugin "VolumeBinding": binding volumes: timed out waiting for the condition技术解析:
- 错误来源:
default-scheduler的VolumeBinding插件(属于scheduler-plugins模块) - 发生时机:PreBind 阶段,即 Pod 已通过所有调度策略(NodeAffinity、Taints 等),即将绑定节点前
- “condition” 指的是:PVC 所请求的 PV 是否已成功创建并处于可绑定状态
- 默认超时时间为 6 分钟(由 kube-scheduler 的
volumeBindingDelayTimeoutSeconds控制)
❗ 注意:这个错误并不一定意味着 PV 创建失败,而是 “等待 PV 出现或就绪的时间超过了阈值”。
2. PVC Events 深度解读 —— 控制平面的求救信号
kubectl describe pvc pvc-console -n production关键事件:
Normal Provisioning 93s (x27 over 90m) persistentvolume-controller
External provisioner is provisioning volume for claim "production/pvc-console"
Normal ExternalProvisioning 2s (x362 over 90m) persistentvolume-controller
waiting for a volume to be created, either by external provisioner "diskplugin.csi.com" or manually created by system administrator深度解析:
Provisioning事件重复出现 27 次 → 表明 External Provisioner 正在尝试创建卷ExternalProvisioning持续 90 分钟未消失 → 说明 PV 始终未被创建- 尽管 provisioner 名称正确(
diskplugin.csi.com),但无后续进展
🟡 初步判断:PVC 已被识别为需要动态供应,但 PV 始终未能生成
3. PV 状态验证 —— 数据平面缺失
kubectl get pv -n ns
# 输出为空结论:
- 没有 PV 被创建 → 说明
External Provisioner或CSI Driver在调用链某处失败 - 不是调度或拓扑问题(如跨 AZ),而是 根本性的 Provisioning 失败
💥 排除法成立:问题不在 volumeBindingMode,而在 卷创建本身卡住
4. StorageClass 审计 —— 排除配置错误
kubectl describe sc alixxx-disk输出摘要:
Name: alixxx-disk
Provisioner: diskplugin.csi.com
Parameters: regionId=hangzhou,type=available
VolumeBindingMode: WaitForFirstConsumer
ReclaimPolicy: Delete
AllowVolumeExpansion: true验证结果:
volumeBindingMode: WaitForFirstConsumer✅ 正确(非 Immediate 导致的拓扑错配)provisioner名称匹配 CSI Driver 注册名 ✅- 参数完整(regionId、type)✅
- 无 Event 异常 ✅
✅ 结论:SC 配置无误,不是问题根源
5:CSI 日志挖掘 —— 最后的真相现场
kubectl logs -n kube-system -l app=csi-provisioner --all-containers=true --tail=200关键错误日志:
GRPC error: rpc error: code = Aborted desc = SDK.ServerError
ErrorCode: Recommend
RequestId: xxxx-xxxx-xxxx
Message: {"data":{},"error":"Failed to get disk, why:'disk_lists' is not defined","code":"xx","msg":"xxx","success":false}深度技术分析:
- gRPC 层面错误类型:
Aborted- 表示操作被中断,通常是临时性失败或前置条件不满足
- 区别于
Internal(内部崩溃)或NotFound(资源不存在)
- SDK.ServerError 来自 CSI Driver 内部封装的云 SDK
diskplugin.csi.com使用Go SDK 发起CreateDisk请求- 返回结构体中包含
"error":"Failed to get disk, why:'disk_lists' is not defined"
- 关键线索:“disk_lists is not defined”
- 并非标准 API 错误码,是 Driver 内部逻辑缺陷或初始化异常
🔍 推测:该 CSI Driver 在调用 CreateVolume 前执行了一段“预检逻辑”,试图查询当前区域的磁盘配额或可用性,但由于代码 bug 导致 panic 或返回错误。
6. 故障链还原:一场跨越三层架构的连锁反应
|
层级 |
事件 |
影响 |
|
应用层 |
Pod 创建,引用 PVC |
触发调度流程 |
|
控制平面 |
PVC Pending → Provisioner 尝试创建 PV |
失败但无明确告警 |
|
CSI 控制服务 |
|
返回 |
|
云平台 API |
未发起实际 |
无资源生成 |
|
调度器 |
等待 PV 就绪超过 6 分钟 |
报错 “timed out waiting for the condition” |
🔄 闭环形成:
- 因为 PV 没创建 → PVC 无法 Bound;
- 因为 PVC 未 Bound → Pod 卡在 PreBind;
- 因为 CSI 返回的是
Aborted而非FailedPrecondition→ Provisioner 持续重试而非快速失败; - 导致整个流程陷入“静默失败 + 长时间等待”的黑洞状态。
7. 根因总结:不仅仅是“CSI 出了问题”
虽然最终定位到 CSI Driver 存在业务逻辑缺陷,但从系统工程角度看,这是一次典型的 可观测性不足 + 异常处理不透明 + 控制流反馈延迟 的复合型故障。
|
维度 |
问题表现 |
改进建议 |
|
可观测性 |
PVC 事件仅显示“waiting”,无具体错误 |
应将 CSI 返回的 |
|
错误传播 |
|
CSI Driver 应对已知错误提前校验并返回 |
|
超时机制 |
6 分钟太长,影响 CI/CD SLA |
可通过 Feature Gate 缩短 |
|
CI 防御 |
未在部署前校验 SC 和 CSI 健康状态 |
增加 pre-flight check 脚本 |
四、终局反思:一次“超时”背后的系统哲学
这起由 timed out waiting for the condition 引发的 Pod Pending 事件,表面上看是一次存储绑定超时,实则暴露了分层解耦是一把双刃剑。
这种设计让我们实现了自动化、可移植性和弹性伸缩——但代价是:当底层出现一个非致命错误(如 gRPC Aborted),上层可能只能看到“无响应”,而非“失败原因”。
作为 CD 工程师,我们必须超越“kubectl describe”的表象。过去,我们习惯于:
kubectl describe pod → 看 Events → 查日志 → 解决问题
但在云原生复杂系统中,这种方法正在失效。真正的诊断能力,来自于对 控制流本质的理解:
| 能力维度 | 初级视角 | 高阶认知 |
|---|---|---|
| 日志查看 | “找 error 关键词” | “理解 gRPC 状态码语义:Aborted ≠ Internal” |
| 事件分析 | “PVC 在 Pending” | “为什么 Provisioner 不创建 PV?” |
| 故障定位 | “是不是调度问题?” | “CSI CreateVolume 是否真正发起 Cloud API 调用?” |
| 系统思维 | “修好这个 Pod” | “如何防止同类问题在其他集群复现?” |
本次故障带来三重认知升级:
- 技术层:掌握"控制流穿透"能力。不要停留在日志表面 -> 构建跨层诊断矩阵
- 流程层:将存储健康纳入CD流水线。引入AI智能系统:在部署前自动验证是否能创建PV -> 部署中诊断是否运行异常 -> ready后服务是否正常
- 思维层:拥抱"混沌工程"的存储观。设计原则:假设每次部署都会遇到存储故障。混沌注入:定期模拟CSI等故障

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)