【万字长文】专业化大语言模型如何重塑AI未来?从领域适应到原生架构的技术演进与收藏指南
专业化大型语言模型(LLMs)已从简单领域适应发展为复杂原生架构,在医疗、金融、法律等领域展现出卓越性能。技术突破包括领域原生设计、参数效率优化、稀疏计算和量化、多模态能力整合等。当前面临知识更新、评估方法和伦理问题等挑战,未来将向高效轻量化、持续学习、多模态集成和可解释性方向发展。
简介
专业化大型语言模型(LLMs)已从简单领域适应发展为复杂原生架构,在医疗、金融、法律等领域展现出卓越性能。技术突破包括领域原生设计、参数效率优化、稀疏计算和量化、多模态能力整合等。当前面临知识更新、评估方法和伦理问题等挑战,未来将向高效轻量化、持续学习、多模态集成和可解释性方向发展。
摘要
专业化大型语言模型(LLMs)的快速发展,已从简单的领域适应演变为复杂的原生架构,标志着人工智能发展的一个范式转变。本调查系统地审视了这一进展在医疗、金融、法律和技术领域中的应用。除了专业化LLMs的广泛应用外,技术突破如领域原生设计的出现、对参数效率的日益重视、稀疏计算和量化、多模态能力的整合等,都应用于最近的LLM代理。我们的分析揭示了这些创新如何解决通用LLMs在专业应用中的根本局限性,专业化模型在领域特定基准上持续获得性能提升。本调查进一步强调了其对电子商务领域填补空白的意义。
引言:AI的“专精特新”时代
大型语言模型(LLMs)的飞速发展开启了人工智能的新纪元,彻底改变了我们处理信息、解决问题和与技术互动的方式。尽管GPT-4等通用LLMs在广泛任务中展现出卓越能力,但在面对专业化、领域特定的挑战时,其性能往往不尽如人意。这一局限性催生了一个重要的范式转变——开发专门针对医疗、法律、金融和工程等专业领域严苛需求的专业化LLMs。
对领域专业化的需求源于通用模型难以充分解决的几个关键因素。首先,专业领域通常需要对技术术语和概念框架的精确理解,这超出了日常语言的使用范围。例如,在医疗保健领域,模型必须准确解释临床术语、诊断代码和复杂的医学关系,才能真正有用。其次,专业领域常常涉及与日常语言使用截然不同的推理模式和知识结构。金融分析需要对市场趋势进行时间推理,法律实践要求对法规进行精确解释,医学诊断则依赖于概率临床推理——所有这些领域通用LLMs都表现出明显的不足。
专业化LLMs的演进经历了几个不同的阶段,每个阶段都以解决先前局限性的技术创新为标志。早期方法主要侧重于利用领域特定语料库对通用模型进行持续预训练,例如BioGPT对GPT-2在生物医学应用中的适应[1]。随后是引入领域感知组件的架构创新,如BloombergGPT的金融时间序列嵌入和Med-PaLM 2的临床推理模块[2]。最近,我们看到了结合LLMs与符号知识库和动态适应机制的混合系统出现,如BLADE的知识注入框架[3]和Self-MoE的专家路由系统[4]。
当前专业化LLMs的格局揭示了几个重要趋势。首先,人们日益认识到,仅仅模型规模并不能保证领域能力——像BioMedLM(2.7B参数)这样更小、精心设计的模型在专业任务上可以超越大得多的通用模型[5]。其次,评估方法变得更加严格,纳入了专家评估和领域特定基准,而不仅仅依赖于通用语言理解指标。第三,人们越来越重视实际应用,模型不仅在静态问答中进行测试,还在动态、交互式场景中进行测试,这更能模拟专业实践。
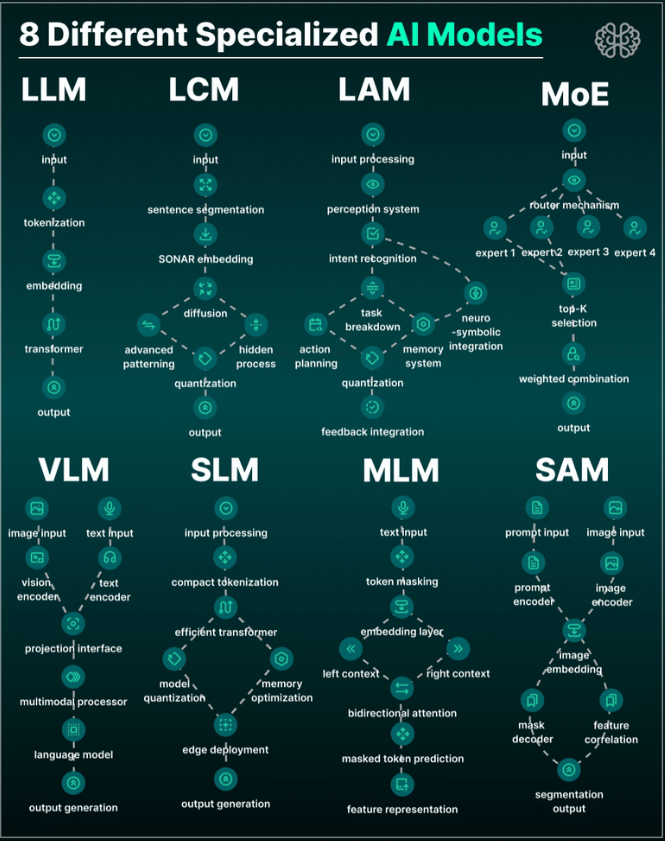
图1:8种专业化AI模型类型(LLM, LCM, LAM, MoE, VLM, SLM等)。
然而,专业化LLMs的开发和部署仍面临重大挑战。知识更新是一个持续存在的问题,尤其是在医学和金融等快速发展的领域,过时信息可能导致严重后果。评估方法仍然难以完全捕捉专业判断的细微差别,常常依赖代理指标而非真实世界有效性的直接衡量。围绕偏见、责任和适当使用的伦理问题继续使高风险领域的部署复杂化。也许最根本的是,当前LLMs的静态性质限制了它们适应新信息和不断演变的专业标准的能力——这一局限性激发了人们对自演进架构的日益增长的兴趣[6]。
本调查旨在全面概述专业化LLM的现状,通过分析架构创新、应用成功案例和主要专业领域面临的持续挑战[7, 8]。我们系统地研究了2022年至2025年间开发的48个前沿模型,识别了关键技术趋势和性能特征。我们的分析揭示了不同的专业化策略——从持续预训练到混合增强——如何影响模型在各个领域的能力。我们还将探讨专业化LLM发展的新兴方向,包括自演进架构、多模态集成和轻量级部署策略。
- 具体突破:专业化LLMs的崛起
近年来,专业化大型语言模型(Specialized LLMs)的研究呈爆炸式增长。在各个领域,针对特定应用场景优化的先进模型不断涌现,这反映了从通用人工智能向垂直领域深度定制解决方案的重大转变。下图2展示了2022年至2025年间专业化LLM的发展历程。
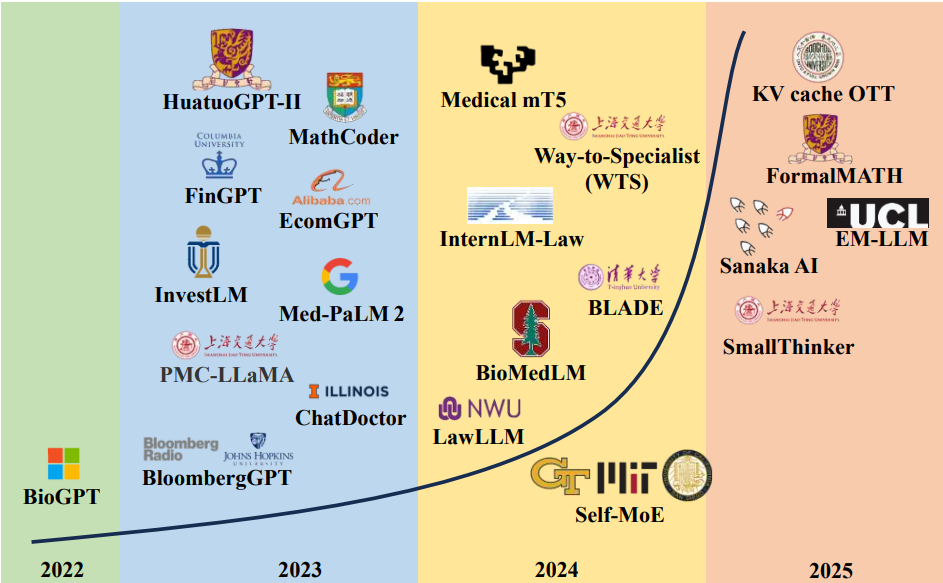
图2:代表性专业化LLMs的演进(2022-2025)。时间线突出了从早期领域微调(BioGPT)到大规模、领域原生架构(Med-PaLM 2,BloombergGPT),以及最近到高效、面向Agent的设计(GLM-4.5,KV-Cache OTT)的转变。
2.1 医疗健康领域:从BioGPT到Med-PaLM 2
在生物医学领域,BioGPT[9](基于GPT-2架构,3.47亿参数)通过生成式预训练在生物医学文本生成和端到端关系抽取方面取得了突破。其继任者BioMedLM[5]通过在PubMed语料库上预训练一个27亿参数的模型,进一步提升了生物医学摘要生成能力。医疗健康领域涌现出更多样化的模型:
•华佗GPT-II[7]:采用指令微调和RLHF优化超过100亿参数的模型,以优化医患对话系统。•Med-PaLM 2[2]:拥有高达3400亿参数,在美国执业医师资格考试(USMLE)中取得了最先进的性能。•PMC-LLaMA[10]和ChatDoctor[11]:均基于LLaMA架构微调,在开放域问答和临床对话任务中展现出显著进步。•WTS (Way-to-Specialist)[12]:引入创新的多阶段专家微调策略,在一个30亿参数的模型上提供专家级别的诊断建议。
2.2 金融与法律领域:专业智慧的结晶
金融领域也涌现出多款突破性模型:
•FinBERT-QA[13]:在BERT-base架构基础上,通过改进的TANDA方法将金融问答性能提升了20%。•FinGPT[14]和InvestLM[15]:分别拥有60亿和27亿参数,采用领域自适应训练策略,在金融市场分析和投资决策支持方面表现出色。•BloombergGPT[8]:在一个庞大的金融语料库上训练,拥有500亿参数,在实体识别和情感分析方面树立了新基准。
在法律领域,LawLLM[16]和Lawyer LLaMA[17](均超过130亿参数)在法律文本理解和法律文档生成方面展现出强大能力。
2.3 数学与多模态:跨越边界的融合
•MathCoder[18]:利用70亿参数通过代码级联合训练增强数学问题解决能力。•FormalMATH[19]:专注于使用15亿参数模型自动化形式定理证明。•EM-LLM[5]:在多模态空间中,采用120亿参数的嵌入调制机制,显著改善了跨模态对齐。
在工业和教育领域,Sanaka AI和SmallThinker等领域特定模型被开发用于解决设备故障诊断和儿童导向的教育问答。
2.4 模型优化与通用代理:效率与智能的飞跃
值得注意的是,模型优化技术也取得了实质性进展:
•BLADE[3]和Self-MoE[4]:通过稀疏和自组织混合专家(MoE)架构提高了推理效率。•KV cache OTT[20]:引入创新方法,将推理过程中的内存使用量减少了70%。•最新的GLM-4.5[21]:基于3550亿参数的MoE架构,成为首个集推理、编码和自主代理能力于一体的原生通用代理模型。•MeLA[22]:通过元认知LLM结合提示演化技术,开创了生成策略优化新范式。
下表1展示了2022-2025年间部分代表性专业化LLMs的概览:
| 年份 | 模型名称 | 领域 |
|---|---|---|
| 2022 | BioGPT | 生物医学 |
| 2023 | 华佗GPT-II | 医疗健康 |
| 2023 | MathCoder | 数学 |
| 2023 | FinGPT | 金融 |
| 2023 | EcomGPT | 电子商务 |
| 2023 | InvestLM | 投资 |
| 2023 | Med-PaLM 2 | 医疗健康 |
| 2023 | PMC-LLaMA | 生物医学 |
| 2023 | ChatDoctor | 医疗健康 |
| 2023 | BloombergGPT | 金融 |
| 2024 | Medical mT5 | 多语言医疗 |
| 2024 | WTS | 医疗健康 |
| 2024 | InternLM-Law | 法律 |
| 2024 | LawLLM | 法律 |
| 2024 | BLADE | 通用 |
| 2024 | BioMedLM | 生物医学 |
| 2024 | Self-MoE | 通用 |
| 2025 | KV cache OTT | 优化 |
| 2025 | FormalMATH | 数学 |
| 2025 | EM-LLM | 多模态 |
| 2025 | Sanaka AI | 工业 |
| 2025 | SmallThinker | 教育 |
| 2025 | GLM-4.5 | 优化 |
| 2025 | MeLA | 优化 |
这些部署共同表明,专业化LLMs已实现行业范围内的普及,在医疗、金融、法律、教育、制造和消费服务等领域确立了标准工具的地位。未来,专业化LLMs将在工业领域发挥更重要的作用。
- 模块化演进:LLMs的深层变革
全面理解专业化大型语言模型(Specialized LLMs)的底层架构,不仅是学术上的先决条件,更是工业成功部署的关键因素。与通用模型不同,专业化LLM模型在四个关键维度上表现出系统性差异:参数机制、数据集创新(如领域特定语料库和多模态数据集的创建)、训练架构创新(如模型架构和学习目标的修改)、评估标准创新(如评估专业化能力的新框架)以及其他模块化创新(如检索增强和记忆系统等组件)。
3.1 数据集专业化:从数量到真实性
为了更好地结合有用的数据集,特别是专家数据,合成专家数据变得至关重要。Self-Instruct[23]表明,仅175个种子任务就可以递归扩展为5.2万个指令-响应对。后续的消融实验显示,在没有正确性过滤的情况下,多样性对MMLU-Medical的下游增益不足3%。Evol-Instruct[24]引入了基于难度的变异操作符,将GSM8K的准确率从42%提高到58%。CodeGen-Synth[25]将LLM代码生成器与沙盒解释器结合,只有通过95%以上单元测试的样本才被保留,从而将幻觉API减少了38%。MedInstruct-200k[26]应用了临床指南验证器,在USMLE风格问题上特异性达到0.94,而未过滤的提示仅为0.78。Constitutional-Poly[27]部署了三个专业LLM进行多轮辩论,生成的10万个宪法法律对话的宪法一致性得分达到0.94,而单代理生成仅为0.71。总的来说,这些工作标志着合成生成从“数量为中心”向“真实性为中心”的转变。
在跨模态方面,最近的研究产生了紧密对齐的语料库,在token级别绑定了符号和感官表示。Anand等人建立了GeoVQA[28],提供了首个大规模、面向中学的多模态几何数据集,将20多万个自然语言问题与高分辨率图表和逐步推理相结合,填补了高中几何教育AI资源的空白。在文档理解方面,mPLUG-DocOwl2[29]引入了一种高分辨率压缩策略,用于无OCR、多页文档理解;该模型将300 dpi的页面压缩到每页少于100个视觉token,并在DocVQA上实现了95.7%的ANLS,比之前的Donut风格基线提高了23.6个绝对百分点,且无需任何OCR预处理。除了视觉,ProtST[30]构建了首个大规模、配对的蛋白质序列和生物医学文本语料库,实现了统一的序列-语言预训练,将零样本蛋白质功能预测的性能比现有单模态基线提高了6-11%。总的来说,这些数据集表明,细粒度token级别的模态特定对齐——而非仅仅语料库数量——推动了当代专业化LLMs的专业化收益。
3.2 训练架构专业化:效率、稀疏与多模态
专业化大型语言模型的最新进展得益于架构设计,这些设计共同优化了参数效率、稀疏性、推理深度和跨模态集成。以下我们将主要贡献分为四个互补的方面:
参数高效微调已从静态LoRA模块发展到动态专家生成。Mixture-of-LoRAs[31]保持骨干网络冻结,并通过轻量级门控网络将每个token路由到前2个领域特定LoRA专家,将激活内存减少7.3倍,同时保留97%的法律领域F1得分。HyperLoRA[32]通过从128维任务嵌入中即时合成LoRA权重,进一步推动了这一进展,使得以每个领域仅128个参数的成本持续添加新的医学专业,并在MedQA-USMLE上额外提高了2.1%的准确率。稀疏混合专家(MoE)在路由效率和系统规模方面同时取得了进展。Expert Choice Routing[33]颠覆了传统范式,让每个专家选择其top-k个token,从而在128个A100 GPU上将节点间通信减少了42%。Task-MoE[34]通过任务感知正则化器增强了损失函数,稳定了异构小批量数据上的路由,将零样本代码完成率提高了3.5%。DeepSpeed-MoE[35]利用专家并行、分层卸载和负载均衡,将万亿参数MoE的训练成本降低到密集等效模型的五分之一,同时保持95%的线性扩展。
图3:小型化与专业化语言模型将引领AI的未来。
压缩和量化策略已针对专业化后的模型进行了重新设计,其中专家权重在其奇异值谱中已经高度偏斜。SpQR[36]通过稀疏-量化表示利用了这种偏斜,将99.7%的权重以3位精度存储,其余异常值以16位存储,在领域特定语料库上实现了近乎无损的困惑度,并将GPU内存减少了3.9倍。SliceGPT[37]利用了微调后专业化子空间是低秩的观察;通过删除25%信息量最少的通道并将剩余权重旋转到压缩基中,该方法在不进行任何再训练的情况下移除了25%的参数,并且下游F1得分仅下降0.8%。
除了效率,推理深度已明确地被设计到前向传播中。System-2-Attention[38]插入了一个草稿本注意力模块,该模块缓存中间推理链并通过可微分的top-k查找检索它们,在不额外预训练的情况下将GSM8K提高了14.7%。Mixture-of-vision-expert adapter[39]已被用于增强模型能力。总的来说,这些协同设计的算法和系统级进展使得专业化LLMs能够同时紧凑、可扩展,并具备跨异构模态的专家级推理能力。
3.3 评估标准专业化:多维度与真实世界
大型语言模型的当代专业化需要评估范式的并行演进,共同探测任务掌握度、安全性、政策合规性和部署效率。MedBench[40]为中文医疗LLMs提供了首个标准化、多维度基准,严格评估诊断准确性、安全性和临床对齐,以确保在不同医疗任务中的可靠评估。Pass@k是另一个有用的评估指标,例如,Chen等人[41]构建了HumanEval基准,其中系统使用pass@k(k=1, 10, 100)来评估代码生成的函数正确性。最近,Chawla等人[42]在其文章中给出了困惑度(PPL)的精确数学定义,并讨论了不同分词器的可比性。困惑度提供了一个单一、敏感且零成本的下一token不确定性衡量标准:当数据漂移时它会立即飙升,在相同分词器下不同模型之间保持可比性,并与下游pass@k增益强相关——使其成为快速对齐检查和大规模超参数扫描的理想首选过滤器。总的来说,这些基准将评估从狭窄的准确性指标转向多维度、对抗性和效率感知的评估,这反映了真实世界专业化LLM部署的复杂性。
3.4 检索增强专业化:从启发式到端到端
2022-2025年专业化大型语言模型的浪潮不仅得益于新数据或更大的预训练预算,还受益于应用于专业化LLM创新的检索增强专业化。检索增强专业化已从后期融合启发式方法发展到完全可微分的检索器-阅读器管道。In-Context RALM[43]表明,缓存的键值向量可以在推理时通过检索到的top-k段落原地覆盖,从而在不进行梯度更新的情况下,在开放域问答中获得4.7个F1得分的提升;RA-DIT[44]通过保持LLM冻结,同时通过从阅读器生成损失中导出的REINFORCE风格奖励信号端到端训练密集检索器,在五个KILT基准上取得了最先进的性能,检索器参数比之前的双编码器系统少了50倍。
3.5 工具使用专业化:从提示工程到约束解码
工具使用专业化也从提示工程转向了学习到的、受约束的解码。Toolformer[45]将API调用token插入到预训练序列中,并通过自监督过滤目标优化其位置,使得68亿参数的模型能够以78%的成功率调用计算器、日历和搜索引擎。Patil等人[46]通过使用有限状态机约束解码器进行微调,将这一范式扩展到1600多个RESTful端点,该解码器保证了JSON参数的语法有效性;在APIBench套件上,该模型达到了85%的pass@1,同时将幻觉参数名称相对于无约束基线减少了41%。
3.6 记忆专业化:LLM代理的持久化能力
记忆也是LLM代理的重要组成部分。对于专业化LLM,mem0[47]引入了一个生产级的长期记忆层,将每次用户交互转化为可即时检索、可更新的嵌入,使得LLM代理能够在不增加上下文窗口的情况下,跨会话保持连贯的个性化上下文。通过将记忆存储与推理解耦,它降低了延迟和成本,同时使代理能够从真实世界的使用中持续学习。此外,记忆解码器(Memory3)[48]首次将“显式记忆”转化为可训练参数,将外部知识标记为词级块并直接嵌入到模型的权重中,将检索延迟从毫秒降至零。实验表明,仅增加0.3%的额外参数,就能在长篇问答中将F1分数提高8.7个点,同时将KV-Cache内存使用量压缩40%。
- 结论与未来方向:专业化LLMs的广阔前景
4.1 结论
近年来,专业化LLMs的研究取得了显著进展,从早期的领域特定微调演变为更先进的原生架构设计和动态知识集成创新。最初的努力主要依赖于通过监督微调将通用模型适应特定领域。尽管这种方法在一定程度上有效,但在可扩展性和领域理解深度方面存在局限性。这些技术进步带来了广泛垂直领域(包括医疗、金融、法律、工程和数学)的显著性能提升。这些领域的专业化LLMs现在通过利用任务对齐的架构、领域自适应训练机制和高效推理策略,持续超越其通用对应模型。
这一演变标志着一个范式转变:研究人员不再仅仅将通用模型适应特定任务,而是从头开始构建领域原生系统,整合专家知识、结构稀疏性和模块化。这些趋势凸显了专业化在LLM发展中日益增长的重要性,特别是在领域精度和推理保真度至关重要的高风险或知识密集型应用中。
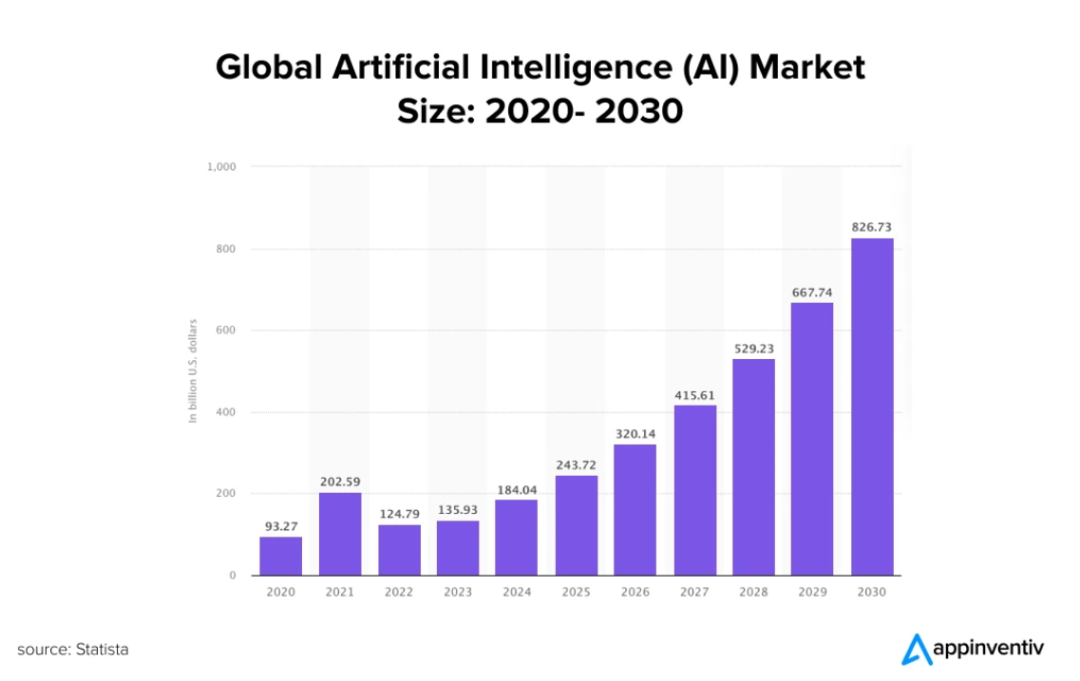
图4:全球人工智能(AI)市场规模:2020-2030。
4.2 对电子商务客户服务的影响
2022年至2025年间专业化大型语言模型的快速成熟,重塑了电子商务客户服务的竞争格局。然而,很少有研究应用于电子商务客户服务领域。首先,当前通用大型模型对电子商务的领域倾向性很小。即使在最近发布的MindFlow[49]中,我们采用的LLM也是一个相对通用的模型,这在一定程度上限制了客户服务准确性的进一步提升。因此,我们需要使用更大规模、更高质量的语料库对其进行微调。这些语料库的验证可以通过类似于困惑度(PPL)的指标来衡量模型的领域理解水平。随后,我们可以利用最先进、高效的框架,如Llama或Unsloth进行微调[50]。最后,在评估阶段,模型可以插入到Ecom-Bench等基准中,并通过pass@k进行评估,以确定新的LLM是否提供强大的电子商务能力[51]。
4.3 未来方向
展望未来,专业化大型语言模型(Specialized LLMs)的发展预计将遵循几个关键方向。首先,模型架构将变得越来越高效和轻量化。量化、稀疏计算和动态推理等创新将使得在边缘设备和资源受限环境中实现高性能部署。这些技术突破将显著降低计算成本并加速推理速度,促进专业化模型在实际应用中的更广泛采用。其次,持续学习和知识更新机制将成为重要的研究领域。未来的专业化LLMs必须能够获取动态知识并进行自我优化,以跟上领域特定信息的快速演变。通过整合知识图谱和检索增强生成等技术,这些模型可以在开放环境中实现持续适应和学习。第三,多模态集成和跨领域协作将获得进一步的重视。专业化LLMs将通过整合文本、图像和时间序列信号等多样化数据类型,超越单模态处理的局限性,构建更全面的领域智能。此外,跨领域迁移学习的进展将提高在标记数据有限的垂直领域中的性能。此外,可解释性和安全性将吸引越来越多的关注。随着专业化LLMs越来越多地部署在医疗和法律等高风险领域,确保模型决策的透明度、可靠性和伦理对齐对于建立信任和遵守法规至关重要。最后,专业化LLMs与基于代理的系统的融合将推动向自主决策的转变。通过整合强化学习、规划和推理能力,未来的模型将支持复杂的任务执行和智能辅助,从而在专业领域实现高水平的决策支持。
总的来说,这些趋势预示着专业化LLMs将变得更加智能、适应性更强、更值得信赖,为更深入地融入垂直行业和任务关键型应用铺平道路。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献783条内容
已为社区贡献783条内容

所有评论(0)