别再用固定长度推理了:Kimi K2 告诉你,未来 AI Agent 必须会自评自测
月之暗面把它叫做"Thinking Agent",核心理念是"模型即 Agent"。简单说,这个模型不只是回答问题,它会主动思考、调用工具、再思考、再调用工具,像人解决复杂问题一样一步步推进。最夸张的是,它能在一个任务里连续执行 200 到 300 步工具调用,中间不需要人插手。比如你让它规划一次伦敦看 Coldplay 演唱会的行程,它会自己搜索演出信息、查日历、订机票、找 Airbnb、预订餐
给你一堆 2020 到 2025 年的薪资数据,让你分析远程工作比例对工资的影响,还要看这个影响在不同经验级别(入门、中级、高级、专家)之间是不是有显著差异。你会怎么做?
Kimi K2 Thinking 的做法是:先加载数据看看结构,然后筛选年份,画小提琴图看分布,把远程比例分成现场、混合、远程三类,跑双因素方差分析,发现数据不够又改成 t 检验,算平均工资,画条形图,计算百分比差异,画散点图,最后生成一个交互式网页报告。
整个过程,16 次 Python 调用,一气呵成。
这就是月之暗面在 2025 年 11 月 6 日发布的 Kimi K2 Thinking——一个会边思考边干活的 AI。
什么是 Kimi K2 Thinking
月之暗面把它叫做"Thinking Agent",核心理念是"模型即 Agent"。简单说,这个模型不只是回答问题,它会主动思考、调用工具、再思考、再调用工具,像人解决复杂问题一样一步步推进。
最夸张的是,它能在一个任务里连续执行 200 到 300 步工具调用,中间不需要人插手。比如你让它规划一次伦敦看 Coldplay 演唱会的行程,它会自己搜索演出信息、查日历、订机票、找 Airbnb、预订餐厅,总共 17 次工具调用,全自动完成。
而且它是开源的。整个模型权重都放在 Hugging Face 上,用的是修改版 MIT 协议。
万亿参数背后的设计
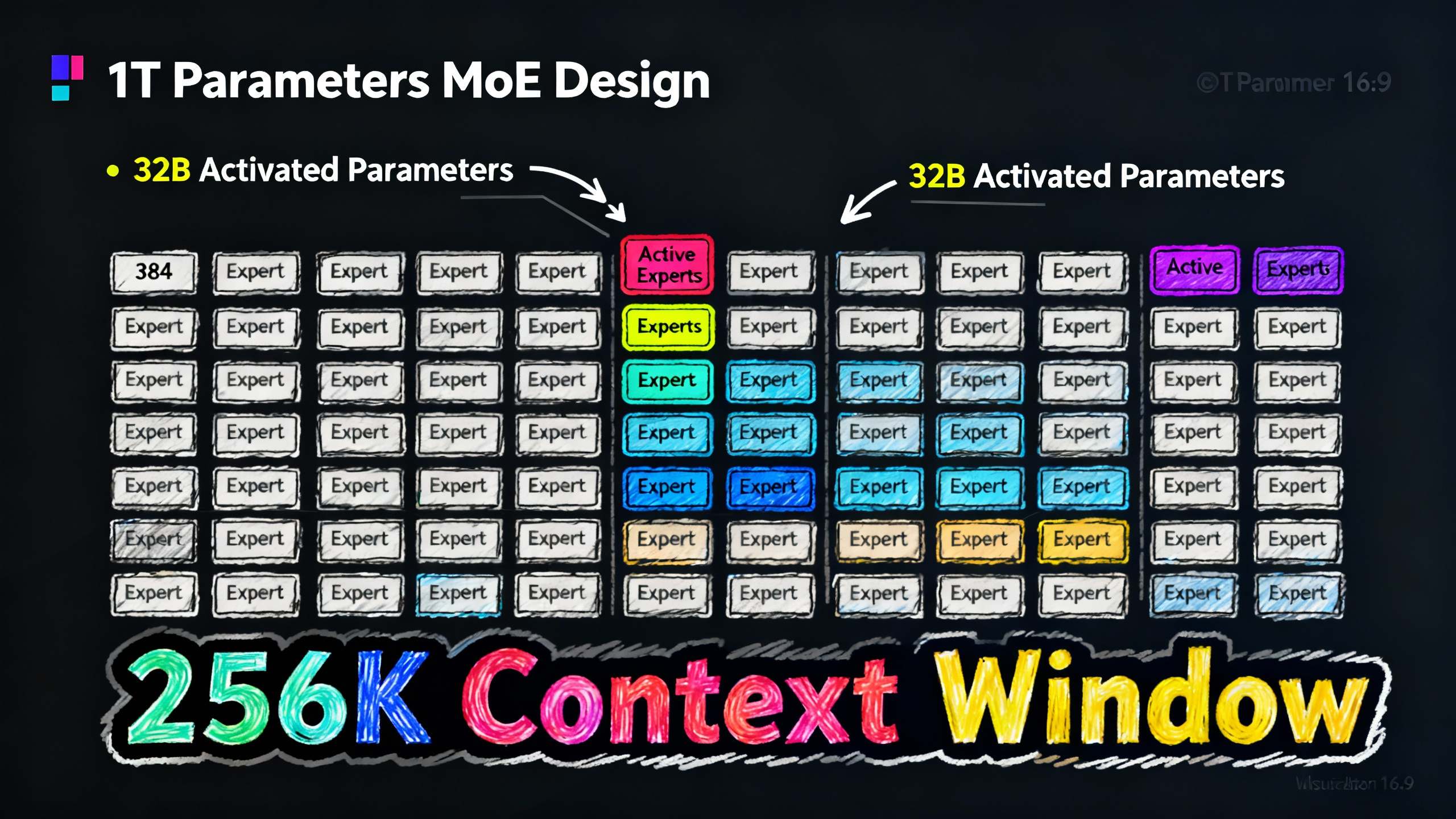
Kimi K2 Thinking 用的是 Mixture-of-Experts 架构,总共 1 万亿参数,但每次推理只激活 320 亿参数。具体来说,模型有 384 个"专家",每次从中选 8 个来处理任务,外加 1 个共享专家。这种设计让模型既有大参数量带来的能力,又不会在推理时太慢。
上下文窗口是 256K tokens,这意味着它能记住很长的对话历史和工具调用记录。
MuonClip 优化器
训练这么大的模型,稳定性是个大问题。月之暗面之前的工作 Moonlight 用的是 Muon 优化器,比常用的 AdamW 更高效,但在扩大规模时遇到了注意力 logits 爆炸的问题——模型训练到一半突然崩溃。
他们的解决方案是 MuonClip,核心是 qk-clip 技术。原理不复杂,在每次更新后直接缩放 query 和 key 的权重矩阵,从源头控制注意力 logits 的规模。公式看起来挺数学的,但效果很实在:Kimi K2 在 15.5 万亿 tokens 的预训练过程中,零训练崩溃。
原生 INT4 量化
大多数模型发布时用的是 FP8 或 BF16 精度,Kimi K2 Thinking 直接用 INT4。这不是训练完再量化,而是在后训练阶段就用量化感知训练,让模型适应 INT4 的精度损失。
好处很明显:模型大小从 1TB 降到 594GB,推理速度提升 2 倍,基准测试成绩基本不掉。而且 INT4 对老一代 GPU 更友好,不需要 Blackwell 架构也能高效推理。
越难的问题,思考越深
Kimi K2 Thinking 的一个关键特性是测试时扩展(test-time scaling)。简单说,遇到简单问题它不会浪费时间,遇到难题它会主动延长思考过程。
拿 Humanity’s Last Exam 这个基准测试来说,这是一套设计来挑战 AI 极限的题目。Kimi K2 Thinking 在不用工具的情况下能答对 23.9%,给它工具之后涨到 44.9%,开启"重度模式"(并行跑 8 条推理路径再综合)能到 51.0%。
数学竞赛的表现更夸张。AIME 2025(美国数学邀请赛)它能拿 99.1 分(满分 100),HMMT 2025(哈佛-麻省理工数学竞赛)95.1 分。这些题目对人类高中生来说都很难。
不同任务的思考 token 预算也不一样。Humanity’s Last Exam 给 96K tokens 的思考空间,每步最多 48K tokens,最多 120 步。IMO AnswerBench(国际数学奥林匹克)给 128K tokens。长文写作给 32K tokens。
这种设计让模型能根据任务难度自适应调整计算资源,而不是所有问题都用固定长度的推理链。
从数据分析到旅行规划
前面提到的薪资数据分析只是个开胃菜。Kimi K2 Thinking 能干的事情范围很广。
有人让它做斯坦福 NLP 研究组的学术家谱可视化网站,它先搜索 5 次找资料,浏览 4 个网页,点击 3 次,滚动 5 次,编辑 6 次代码,部署 2 次,最后生成一个交互式网站。整个过程全自动,你只需要提需求。
还有人让它规划 Coldplay 2025 伦敦演唱会的行程,它会调用搜索、日历、Gmail、航班、Airbnb、餐厅预订等 API,17 次工具调用之后给你一个完整的行程方案。
命令行操作也不在话下。给它访问你的终端,它能编辑文件、运行命令、看日志、调试代码。比如让它把一个 Flask 项目转成 Rust,它会系统地重构代码库,跑性能基准测试,确保结果可靠。
怎么训练出来的
这种 Agent 能力不是天生的,月之暗面做了两件事。
第一是大规模 Agent 数据合成。他们参考 ACEBench 的思路,模拟了几百个领域、几千种工具,生成几百个 Agent,每个 Agent 有不同的工具集。然后让这些 Agent 在模拟环境里执行任务,用 LLM 作为评委根据 rubric 打分,筛选出高质量的训练数据。
第二是通用强化学习。难点在于有些任务有明确对错(比如数学题),有些任务没有标准答案(比如写研究报告)。他们的做法是让模型自己当评委,给自己的输出打分,同时用有明确对错的任务来持续更新这个评委模型,让它越来越准。
这个类比不太严谨,但大概就是这意思:模型一边做题,一边学习怎么给自己打分,而且用简单题的反馈来提升打分的准确度。
基准测试:开源模型的新高度
Artificial Analysis 给 Kimi K2 Thinking 打了 67 分(Intelligence Index),这是开源模型迄今为止的最高分,超过了 MiniMax-M2、DeepSeek-V3.2-Exp、Qwen 235B 等一众对手。在闭源模型里,只有 GPT-5 分数更高。
编程能力方面,LiveCodeBench 它拿了 53.7%(DeepSeek-V3 是 46.9%),SWE-bench Verified(真实 GitHub issue 修复任务)单次尝试 65.8%,多次尝试 71.6%。这个成绩在开源模型里是第一,但还是比不过 Claude 4 Opus 的 80.2%。
Agent 任务是它的强项。Tau2-Bench 的电信客服场景,它拿了 93% 的成绩,这是 Artificial Analysis 测过的所有模型里最高的。BrowseComp(自主网页浏览能力)60.2%,Seal-0(复杂信息收集推理)56.3%,都是 SOTA 水平。
数学和科学推理也不错。GPQA Diamond(研究生级别物理化学生物题)75.1%,ZebraLogic(逻辑推理)89.0%,AutoLogi(自动推理)89.5%。
但它也是最"话痨"的模型。跑完 Artificial Analysis 的全套测试,它用了 1.4 亿个 tokens,是 DeepSeek-V3 的 2.5 倍,GPT-5 的 2 倍。这导致虽然单价便宜(输入 $0.6/百万 tokens,输出 $2.5/百万 tokens),总成本还是不低。而且基础端点的推理速度只有 8 tokens/秒,turbo 端点快一些但贵很多。
开源模型重回前沿
过去一年,中国的 AI 实验室在开源模型领域一直领先。OpenAI 在 2025 年 8 月发布 gpt-oss-120b 的时候短暂夺回了榜首,现在 Kimi K2 Thinking 又把这个位置抢回来了。
这个趋势挺有意思。闭源模型(OpenAI、Anthropic、Google)在绝对性能上还是领先,但开源模型的追赶速度很快,而且差距在缩小。Kimi K2 Thinking 的 67 分已经很接近一些闭源模型的水平,考虑到它完全开源、可以自己部署,这个性价比就很有吸引力了。
它也有问题

月之暗面在官方文档里坦诚地列了一些局限性。
第一个是工具定义不清晰或者任务太难的时候,模型可能生成过多 tokens,导致输出被截断或者工具调用不完整。这个问题和它的"话痨"属性有关,遇到不确定的情况它倾向于多说,而不是简洁地表达。
第二个是某些任务启用工具之后性能反而下降。这听起来很反直觉,但确实存在。可能是模型在判断什么时候该用工具、用哪个工具上还不够精准,有时候直接回答反而更好。
第三个是一次性生成完整软件项目的能力不如在 Agent 框架下分步执行。这其实是个设计取舍,Kimi K2 Thinking 的优势在于多步骤、多工具的协调,而不是一次性输出大量代码。
视觉理解能力目前还没有,官方说未来会加。更高级的思考能力也在规划中。
怎么用
如果你只是想试试,最简单的方式是去 kimi.com,免费用户就能选择 K2 模型。不过目前网页版和 App 的 MCP 工具功能还在开发中,要体验完整的 Agent 能力可能还要等几周。
开发者可以用 Moonshot Platform 的 API,接口兼容 OpenAI 和 Anthropic 的格式,迁移成本很低。价格前面提到了,基础端点输入 $0.6、输出 $2.5 每百万 tokens,turbo 端点贵一些但快很多。
想自己部署的话,推荐用 vLLM、SGLang、KTransformers 或 TensorRT-LLM。模型权重在 Hugging Face 上,594GB 的 INT4 版本,如果你有足够的 GPU 内存可以解压成 FP8 或 BF16。
从 demo 到基础设施
Kimi K2 Thinking 让我觉得有意思的地方,不是它在某个基准测试上拿了第一,而是它展示了一种趋势:AI Agent 正在从研究 demo 变成可以实际部署的基础设施。
以前的推理模型,比如 OpenAI o1 或者 DeepSeek R1,主要优势在于解数学题、写代码这种有明确对错的任务。Kimi K2 Thinking 往前走了一步,它能处理那些需要多步规划、多工具协调、没有标准答案的开放任务。
测试时扩展这个设计思路也值得关注。传统模型是固定推理长度,简单问题和难题用同样的计算资源。K2 Thinking 的做法更像人类,遇到简单问题快速处理,遇到难题花时间深入思考。这种自适应的资源分配可能是未来推理模型的标配。
当然,它现在还有不少毛病,话太多、有时候不知道什么时候该闭嘴、工具使用的判断还不够精准。但考虑到这是个完全开源的模型,任何人都能下载、修改、部署,这些问题迟早会被社区解决。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)