腾讯混元1面:GRPO比PPO到底好在哪?
其中,V 是 critic 模型估计出来的,新引入的 gamma 是一个常量,可将其理解为权衡因子,它控制了在计算当前优势时与未来优势的考量,从强化学习的角度上,它控制了优势估计的方差和偏差。因此这种方法不适合在所有推理领域中进行推广,所以后续也有很多改进工作出现,例如 DAPO,VAPO,GSPO 等等,这些我们也会在后面的分享中逐一讲解,敬请期待。OK,知道了经典的 PPO,我们再来看看 De
是时候准面试和实习了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

DeepSeek-R1 的 GRPO 算法相比 PPO 好在哪里?直接用 PPO 可以吗?这是我的学员在今年秋招大模型面试中遇到的一个问题。
这篇文章,我们就从这个面试题展开,详细聊聊 Deepseek 中的强化学习算法 GRPO,如果你在面试现场被问到相关题目,应该如何作答?
01
面试官心理分析
首先老规矩,我们还是来分析一下面试官的心理,面试官问这个问题呢,其实主要是想考察这么几个点:
-
第一,你对经典的 RLHF 阶段的 PPO 算法了不了解,这个当然是回答这道题目的前提条件了。
-
第二,deepseek 的 RL 阶段是怎么做的?能否从公式层面分析一下它们的差异点?
-
第三,它为什么要这么设计,有什么优势?
好,那接下来我们就沿着面试官的心理预期,来分析一下这道题目!
02
面试题解析
首先看一下,经典的 PPO 算法是怎么做的?
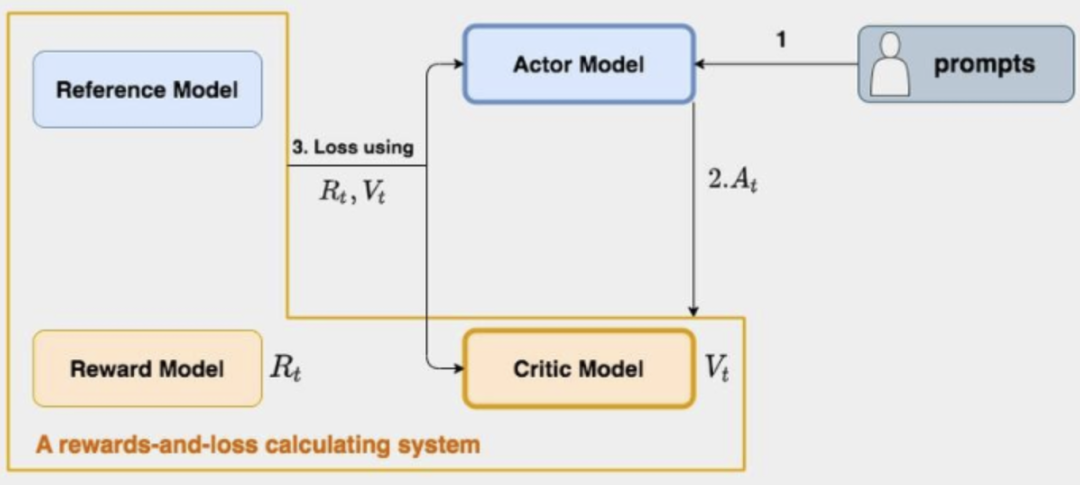
看这张图,我们知道,在 RLHF-PPO 阶段,一共有四个主要模型,分别是:
-
Actor Model,想要训练的目标语言模型。
-
Critic Model,用来预估t时刻的未来期望总收益 Vt。
-
Reward Model,也就是奖励模型,用来计算即时收益 Rt。
-
Reference Model:参考模型,在 RLHF 阶段,给语言模型增加一些“约束”,防止模型训歪。
PPO 具体实现有很多变种,我们这里讲其中一种,用公式展开如下:
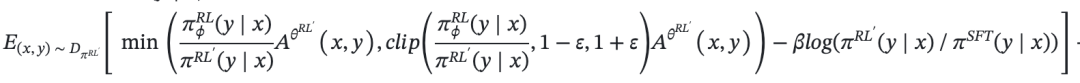
这里公式第一项,是 PPO 的优化目标,说白了,就是根据重要性比值的截断去约束。
第二项是一个惩罚项,约束当前更新的模型不要偏离原始语言模型太远,防止语言模型跑偏。
OK,知道了经典的 PPO,我们再来看看 DeepSeek 的 GRPO 是怎么做的,在哪些地方做了改进?
其实 GRPO 最大的不同点,就是这里的优势函数计算不一样,也就是公式中的红框部分。
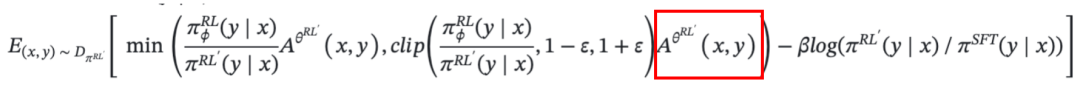
那所谓的优势又是指的什么呢?这里我们通过吃鸡这个游戏,来举个例子。
假设在和平精英中,你想从 G 镇转移到 P 城,这时你有两种选择:
-
走空旷的麦田。
-
走沿途有房区的公路。
现在你选择走房区公路,当做出这个决定后,Critic 模型告诉你预计可能会遇到一个敌人。
结果此刻沿途房区的敌人刚好都在互相交战,你不仅安全通过,还顺手收集了两个敌人掉落的高级物资,收益远超预期。
因为实际收益比预期要多,你尝到了甜头,所以增大了“转移时优先选择房区路线”的概率。这个多出来的“甜头”,就叫做“优势”。
原始的 PPO 计算优势如下:
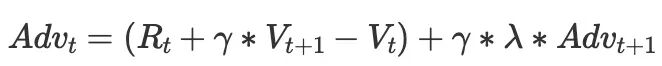
这在强化学习中也叫广义优势估计 GAE。
其中,V 是 critic 模型估计出来的,新引入的 gamma 是一个常量,可将其理解为权衡因子,它控制了在计算当前优势时与未来优势的考量,从强化学习的角度上,它控制了优势估计的方差和偏差。
再来看 GRPO,与 PPO 依赖 critic 模型来引导学习不同,GRPO 直接去掉了 critic 模型!
它的做法是:采样一组输出,通过组内相对奖励来估计基线,从而来优化模型。
我们看这张图:
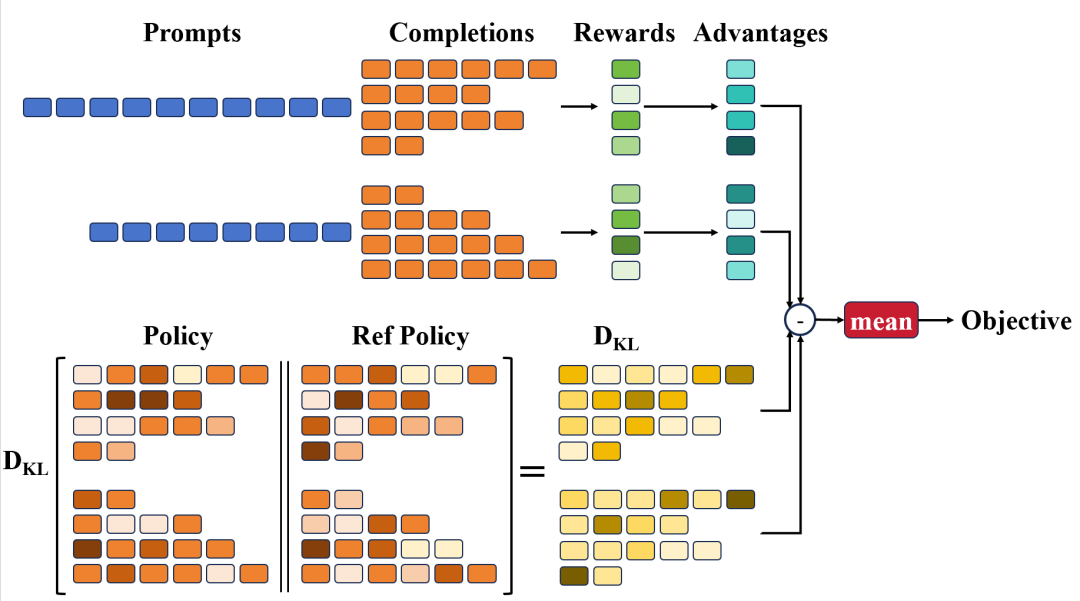
GRPO 通过对一个 prompt 输入要优化的策略模型,采样多个 response,然后根据 reward 模型来计算即时的 reward,最后归一化得到当前 prompt 的优势。
我们看公式:
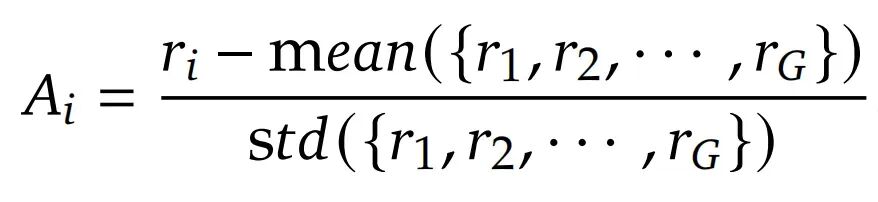
其中 GRPO 的奖励类型有三种:
-
一个是答案是否准确,例如,解答数学题。
-
第二个是格式是否正确,例如,推理过程需要包含在标签中。
-
还有语言一致性奖励,惩罚语言混杂或格式不一致。
来看一个例子,假设查询是“3 * 5 的乘积是多少?”
此时模型会针对该查询生成这样的一组 4 个响应:
-
o1:“答案是 15。”
-
o2:“十伍。”
-
o3:“是 15。”
-
o4:“积是 15。”
对应得到的奖励可能就是这个样子:
-
r1 = 1.0(正确且格式良好)
-
r2 = 0.8(正确但较不正式)
-
r3 = 0.0(错误答案)
-
r4 = 1.0(正确且格式良好)
GRPO 这样设计有什么好处呢?几点:首先去掉了 critic 模型,提高了训练效率,而且节约了显存和计算资源,这在训练超大模型时是非常有用的,毕竟卡不便宜。
另外,在组内建立竞争机制来促进学习,想象一下你正在教一群学生解决一道数学题。
你肯定不会直接告诉他们谁答对了谁答错了,而是比较所有学生的答案,找出谁答得最好(以及原因)。
然后通过奖励和惩罚让差生向好学生学习,并不断优化。这种方式也使得 GRPO 在解决推理任务中表现尤为出色,特别是数学和代码任务,这点我们从开放出来的 benchmark 也可以看出。
但是 GRPO 绝对奖励评估方式难以适应各种复杂任务,比如对 token 级,cot 级细粒度评分,比如我做应用题,改试卷的时候,除了答案能给分以外,有过程也可以给分。
因此这种方法不适合在所有推理领域中进行推广,所以后续也有很多改进工作出现,例如 DAPO,VAPO,GSPO 等等,这些我们也会在后面的分享中逐一讲解,敬请期待。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)