Python爬虫-豆瓣读书爬虫
·
注意事项
请懂得爬虫大数据采集和挖掘的合规性,遵守相关的法律法规,正确守法使用此技术。
实验设备
PC计算机,配置Win10操作系统,Python,PyCharm
实验内容
豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排
名依次存储,存储到Excel中。筛选评价人数>1000的高分书籍:可依
据不同的主题存储到Excel不同的Sheet,采用UserAgent伪装为浏
览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被
封。
(1)运行代码:
import time # 导入时间模块
import urllib.parse # 导入用于URL编解码的模块
import requests # 导入发送HTTP请求的模块
import numpy as np # 导入用于科学计算的模块
from bs4 import BeautifulSoup # 从BeautifulSoup模块中导入BeautifulSoup类
from openpyxl import Workbook # 从openpyxl模块中导入Workbook类
# User Agents
# 设置多个用户代理,用于发送HTTP请求时伪装浏览器身份
hds = [
{'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'},
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'},
{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'}
]
# book_spider函数,目的是爬取指定标签的豆瓣图书信息
def book_spider(book_tag):
# 当前页数
page_num = 0
# 保存书籍信息的列表
book_list = []
# 尝试次数
try_times = 0
while True:
# 构建豆瓣图书标签页面的URL
url = 'http://www.douban.com/tag/' + urllib.parse.quote(book_tag) + '/book?start=' + str(page_num * 15)
time.sleep(np.random.rand() * 5) # 等待一段随机时间
try:
# 发送HTTP GET请求,获取网页内容,page_num % len(hds) 用于循环使用头文件列表中的不同头文件。
req = requests.get(url, headers=hds[page_num % len(hds)])
plain_text = req.text
# 如果请求出现异常会抛出 requests.HTTPError 或 requests.ConnectionError
except (requests.HTTPError, requests.ConnectionError) as e:
print(e)
continue
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(plain_text, 'html.parser')
list_soup = soup.find('div', {'class': 'mod book-list'})
try_times += 1
# 若未找到书籍信息且尝试次数不超过200次,则继续尝试
if list_soup is None and try_times < 200:
continue
# 若未找到书籍信息或列表为空,则结束循环
elif list_soup is None or len(list_soup) <= 1:
break
# 解析每本书的信息并添加到book_list中
for book_info in list_soup.findAll('dd'):
title = book_info.find('a', {'class': 'title'}).string.strip() # 书名
desc = book_info.find('div', {'class': 'desc'}).string.strip() # 书籍描述
desc_list = desc.split('/')
book_url = book_info.find('a', {'class': 'title'}).get('href') # 书籍详情页URL
author_info = '/'.join(desc_list[0:-3]) if len(desc_list) >= 3 else '暂无' # 作者信息
pub_info = '/'.join(desc_list[-3:]) if len(desc_list) >= 3 else '暂无' # 出版社信息
rating = book_info.find('span', {'class': 'rating_nums'}).string.strip() if book_info.find('span', {
'class': 'rating_nums'}) else '0.0' # 评分
try:
# 获取评价人数
people_num = get_people_num(book_url)
people_num = people_num.strip('人评价')
except:
people_num = '0'
# 将书籍信息添加到book_list中
book_list.append([title, rating, people_num, author_info, pub_info])
try_times = 0 # 当获取有效信息时,重置try_times计数器
page_num += 1 # 获取下一页的书籍信息
print('Downloading Information From Page %d' % page_num)
return book_list
# 定义了一个名为 get_people_num 的函数,它接受一个参数 url,表示书籍详情页的 URL。
def get_people_num(url):
try:
# 发送 HTTP GET 请求,使用随机选择的头文件
req = requests.get(url, headers=hds[np.random.randint(0, len(hds))])
plain_text = req.text
except (requests.HTTPError, requests.ConnectionError) as e:
print(e)
# 使用 Beautiful Soup 解析 HTML 内容
soup = BeautifulSoup(plain_text, 'html.parser')
# 查找评价人数信息,并返回人数
# 如果找不到符合条件的 div 元素,说明没有评价人数的信息,返回字符串 '0'
people_num = soup.find('div', {'class': 'rating_sum'}).findAll('span')[1].string.strip() if soup.find('div', {
'class': 'rating_sum'}) else '0'
return people_num
# 定义了一个名为 do_spider 的函数,它接受一个参数 book_tag_lists,该参数是一个包含书籍标签的列表。
def do_spider(book_tag_lists):
# 创建了一个空列表book_lists用于存储爬取到的书籍信息
book_lists = []
for book_tag in book_tag_lists:
book_list = book_spider(book_tag) # 爬取指定标签的书籍信息
book_list = sorted(book_list, key=lambda x: float(x[1]), reverse=True) # 按评分排序
book_lists.append(book_list)
return book_lists
# 定义了一个名为 print_book_lists_excel的函数将书籍信息以 Excel 的格式打印出来
def print_book_lists_excel(book_lists, book_tag_lists):
wb = Workbook() # 创建一个新的Excel工作簿
for book_tag in book_tag_lists:
ws = wb.create_sheet(title=book_tag) # 创建工作表,并设置标题
ws.append(['序号', '书名', '评分', '评价人数', '作者', '出版社']) # 添加表头
count = 1
for bl in book_lists[book_tag_lists.index(book_tag)]:
# 将书籍信息写入表格
ws.append([count, bl[0], float(bl[1]), int(bl[2]), bl[3], bl[4]])
count += 1
save_path = 'book_list'
for tag in book_tag_lists:
save_path += ('-' + tag)
save_path += '.xlsx'
wb.save(save_path) # 保存Excel文件
if __name__ == '__main__':
book_tag_lists = ['科幻', '思维', '金融'] # 要爬取的书籍标签列表
book_lists = do_spider(book_tag_lists) # 开始爬取书籍信息
print_book_lists_excel(book_lists, book_tag_lists) # 将书籍信息写入Excel文件
(2)运行结果截图:
运行时间较长,需耐心等待。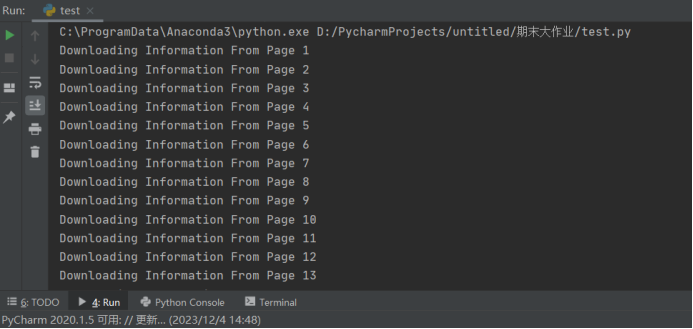
(3)爬取的信息按要求被保存到本地Excel文件不同的Sheet中: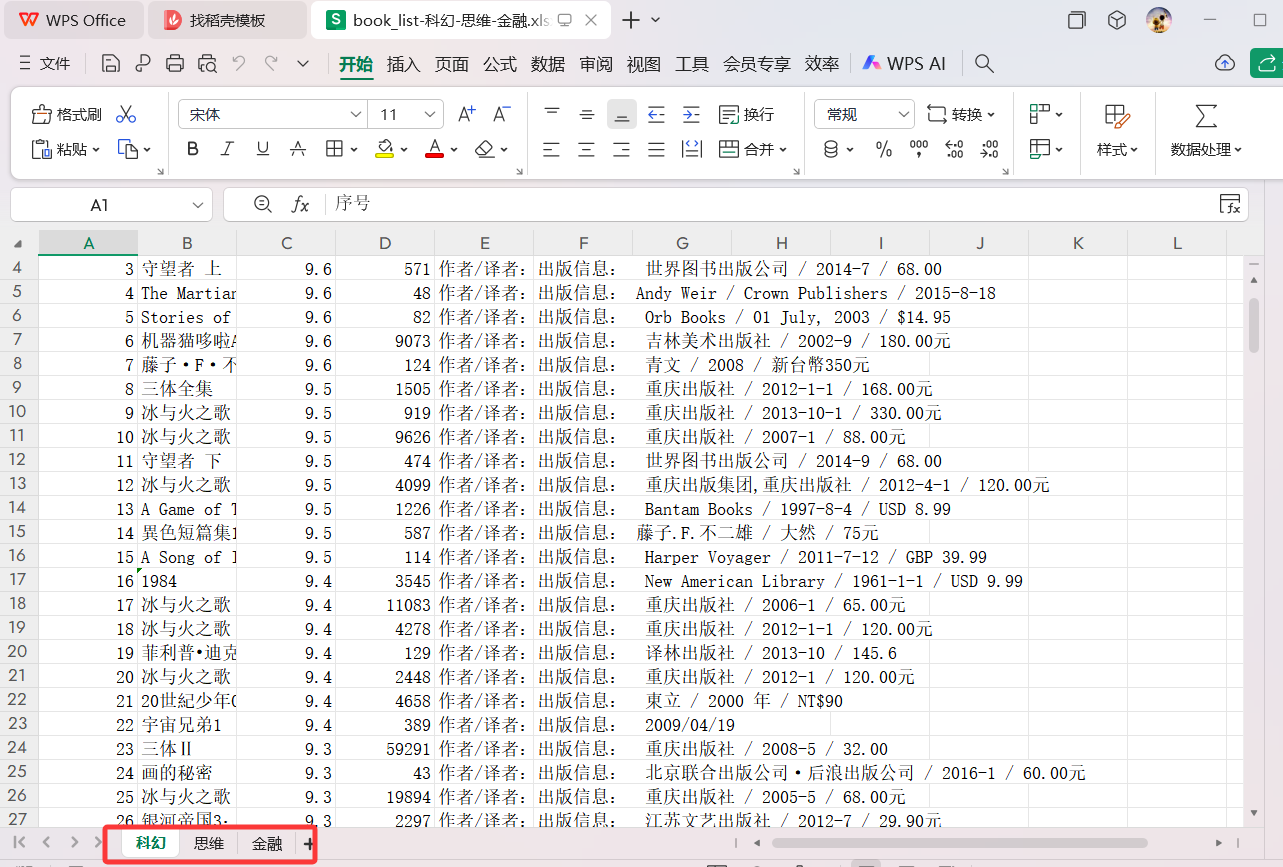
(4)爬取的Excel文件的完整数据在下方链接中,可自行下载查看:
https://download.csdn.net/download/you1234me/91335813

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)