OpenCV中关于图像的预处理基础操作
边缘填充的主要目的是:避免边界像素丢失。保持图像尺寸。减少边界效应。提供上下文信息。支持多种图像操作。通过合理使用边缘填充,可以显著提高图像处理的效果和效率。# 读图# 获取旋转矩阵# 仿射变换函数 实现旋转# 边界复制# 边界反射# 边界反射101# 边界常数# 边界包裹# 显示效果 释放资源。
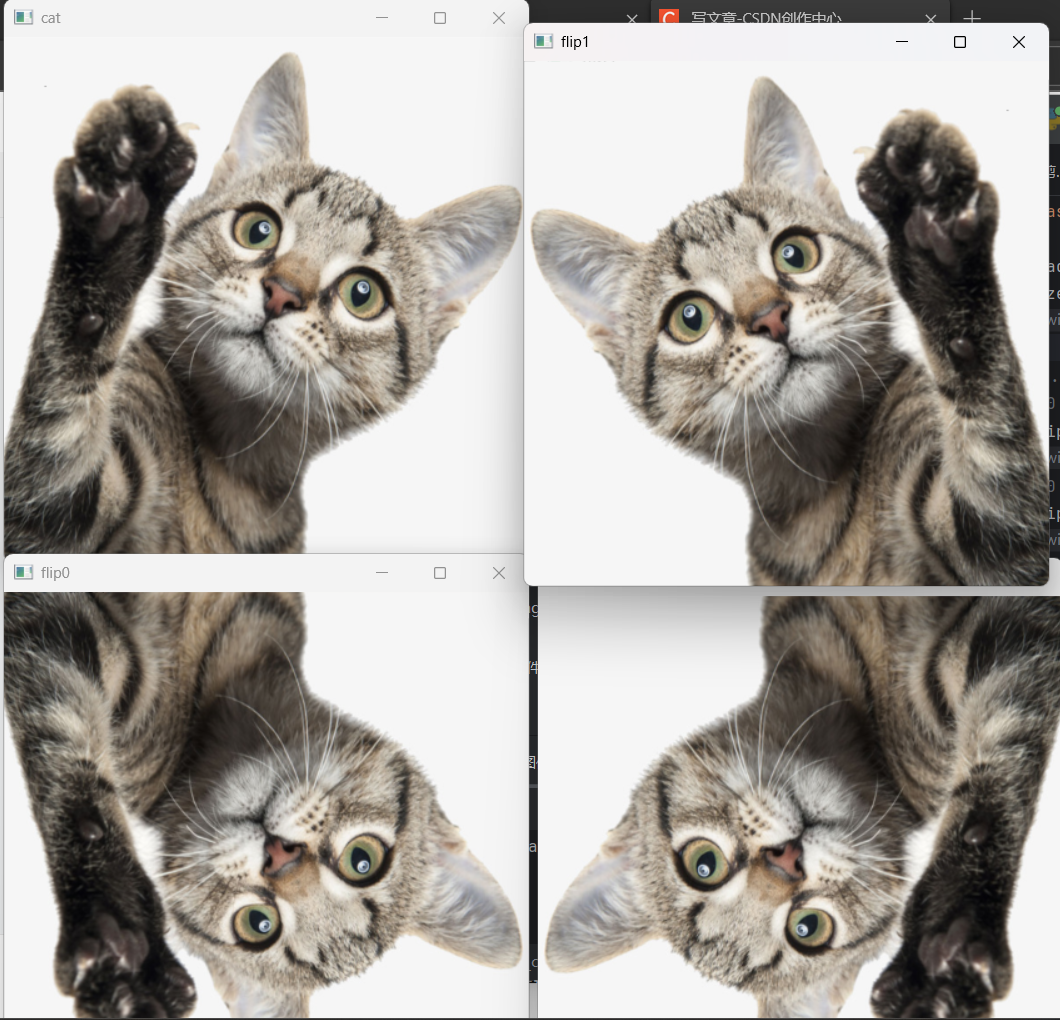
一 镜面翻转
在OpenCV中,图片的镜像旋转是以图像的中心为原点进行镜像翻转的。
-
cv2.flip(img,flipcode)
-
参数
-
img: 要翻转的图像
-
flipcode: 指定翻转类型的标志
-
flipcode=0: 垂直翻转,图片像素点沿x轴翻转
-
flipcode>0: 水平翻转,图片像素点沿y轴翻转
-
flipcode<0: 水平垂直翻转,水平翻转和垂直翻转的结合
-
-
import cv2 as cv
# 读图
cat=cv.imread("../images/cat1.png")
cat=cv.resize(cat,(420,420))
cv.imshow("cat",cat)
# 图像翻转 cv.flip(img,flipcode)
# flipcode>0 水平翻转 沿着y轴
flip1=cv.flip(cat,flipCode=1)
cv.imshow("flip1",flip1)
# flipcode=0 垂直翻转 沿着x轴
flip0=cv.flip(cat,flipCode=0)
cv.imshow("flip0",flip0)
# flipcode<0 水平+垂直
flip=cv.flip(cat,flipCode=-1)
cv.imshow("dst",flip)
cv.waitKey(0)
cv.destroyAllWindows()
结果如图:
二 图像仿射变换
仿射变换(Affine Transformation)是一种线性变换,保持了点之间的相对距离不变。
-
仿射变换的基本性质
-
保持直线
-
保持平行
-
比例不变性
-
不保持角度和长度
-
-
常见的仿射变换类型
-
旋转:绕着某个点或轴旋转一定角度。
-
平移:仅改变物体的位置,不改变其形状和大小。
-
缩放:改变物体的大小。
-
剪切:使物体发生倾斜变形。
-
-
仿射变换的基本原理
-
线性变换
-
二维空间中,图像点坐标为,仿射变换的目标是将这些点映射到新的位置 。
-
为了实现这种映射,通常会使用一个矩阵乘法的形式:
(类似于y=kx+b)
-
,,,是线性变换部分的系数,控制旋转、缩放和剪切。
-
, 是平移部分的系数,控制图像在平面上的移动。
-
输入点的坐标被扩展为齐次坐标形式,以便能够同时处理线性变换和平移
-
-
-
cv2.warpAffine()函数
-
仿射变换函数
cv2.warpAffine(img,M,dsize)
-
img:输入图像。
-
M:2x3的变换矩阵,类型为
np.float32。 -
dsize:输出图像的尺寸,形式为
(width,height)。
-
-
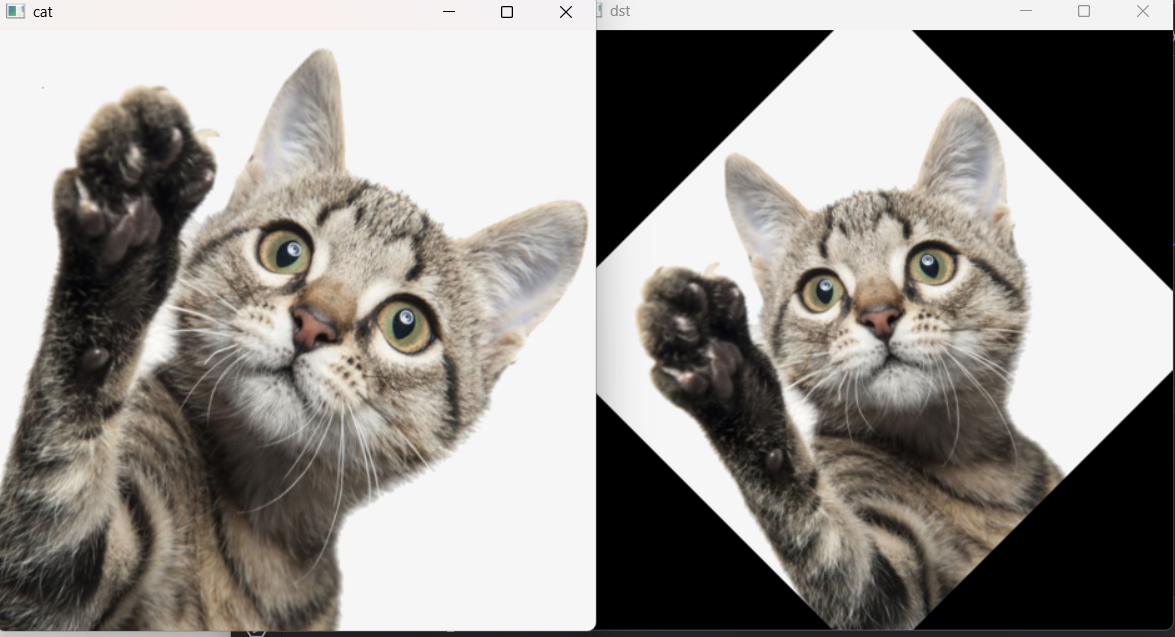
1 图像旋转
旋转图像可以将图像绕着某个点旋转一定的角度。
cv2.getRotationMatrix2D()函数
-
获取旋转矩阵
cv2.getRotationMatrix2D(center,angle,scale)
-
center:旋转中心点的坐标,格式为
(x,y)。 -
angle:旋转角度,单位为度,正值表示逆时针旋转负值表示顺时针旋转。
-
scale:缩放比例,若设为1,则不缩放。
-
返回值:M,2x3的旋转矩阵。
-
import cv2 as cv
# 读图
cat=cv.imread("../images/cat1.png")
cat=cv.resize(cat,(480,480))
h,w=cat.shape[:2]
# 获取旋转矩阵
M=cv.getRotationMatrix2D((w//2,h//2),45,0.8)
# 仿射变换函数 实现旋转
dst=cv.warpAffine(cat,M,(w,h))
# 显示效果 释放资源
cv.imshow("cat",cat)
cv.imshow("dst",dst)
cv.waitKey(0)
cv.destroyAllWindows()
结果如图:
2 图像平移
移操作可以将图像中的每个点沿着某个方向移动一定的距离。
-
假设我们有一个点 ,希望将其沿x轴方向平移*个单位,沿y轴方向平移个单位到新的位置,那么平移公式如下:
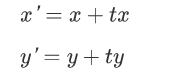
这里的tx和ty分别代表在x轴和y轴上的平移量。
import cv2 as cv
import numpy as np
# 读图
cat=cv.imread("../images/cat1.png")
cat=cv.resize(cat,(480,480))
h,w=cat.shape[:2]
# 定义平移矩阵 np.float32
tx=100
ty=200
M=np.float32([[1,0,tx],[0,1,ty]])
# 仿射变换
dst=cv.warpAffine(cat,M,(w,h))
cv.imshow("dst",dst)
cv.waitKey(0)
cv.destroyAllWindows()
结果如图:

3 图像缩放
缩放操作可以改变图片的大小。
-
假设要把图像的宽高分别缩放为0.5和0.8,那么对应的缩放因子sx=0.5,sy=0.8。
-
点对应到新的位置,缩放公式为:
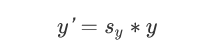
相较于图像旋转中只能等比例的缩放,图像缩放更加灵活,可以在指定方向上进行缩放。
import cv2 as cv
import numpy as np
# 读图
cat=cv.imread("../images/cat1.png")
cat=cv.resize(cat,(480,480))
h,w=cat.shape[:2]
# 定义缩放矩阵
sx=0.5
sy=0.8
M=np.float32([[sx,0,50],[0,sy,100]])
dst=cv.warpAffine(cat,M,(w,h),)
cv.imshow("dst",dst)
cv.waitKey(0)
cv.destroyAllWindows()
结果如图:

4 图像裁剪
剪切操作可以改变图形的形状,以便其在某个方向上倾斜,它将对象的形状改变为斜边平行四边形,而不改变其面积。
-
想象我们手上有一张矩形纸片,如果你固定纸片的一边,并沿着另一边施加一个平行于该边的力,这张纸片就会变形为一个平行四边形。这就是剪切变换的一个直观解释。
-
对于二维空间中的点,对他进行剪切变换:
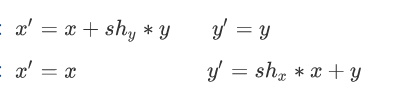
-
当需要同时沿两个方向进行剪切时,
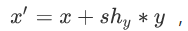 ,
, 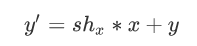
shy和shx分别对应沿x轴和y轴方向上的剪切因子。
-
可以理解为,x不变,y偏移
import cv2 as cv
import numpy as np
# 读图
cat=cv.imread("../images/cat1.png")
cat=cv.resize(cat,(480,480))
h,w=cat.shape[:2]
# 定义剪切矩阵
shx=0.2
shy=0.3
M=np.float32([[1,shy,0],[shx,1,0]])
dst=cv.warpAffine(cat,M,(2*w,2*h))
cv.imshow("dst",dst)
cv.waitKey(0)
cv.destroyAllWindows()
结果如图:
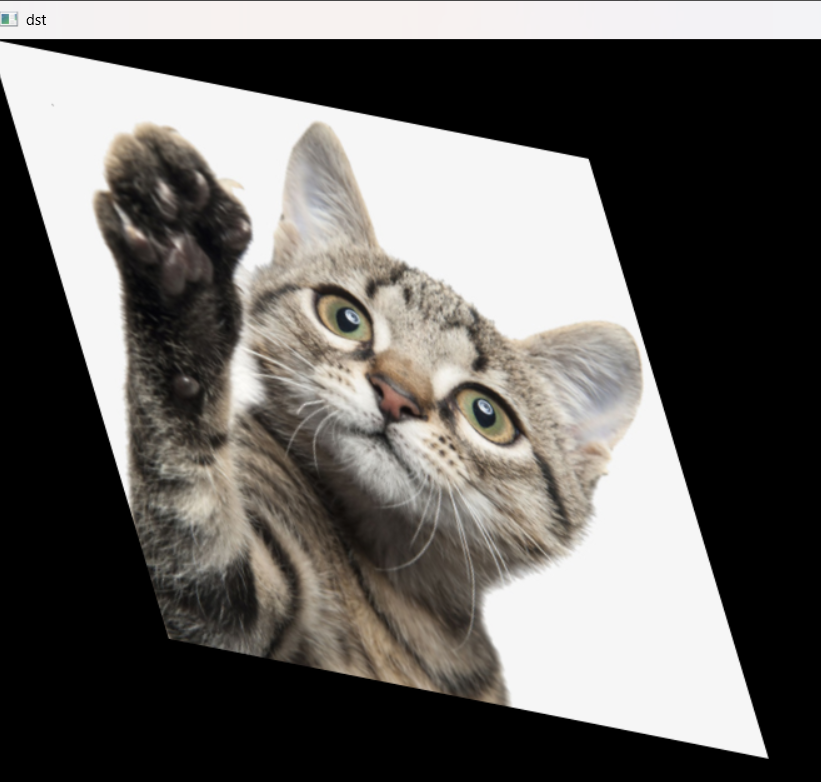
三 插值方法
在图像处理和计算机图形学中,插值(Interpolation)是一种通过已知数据点之间的推断或估计来获取新数据点的方法。它在图像处理中常用于处理图像的放大、缩小、旋转、变形等操作,以及处理图像中的像素值。
图像插值算法是为了解决图像缩放或者旋转等操作时,由于像素之间的间隔不一致而导致的信息丢失和图像质量下降的问题。当我们对图像进行缩放或旋转等操作时,需要在新的像素位置上计算出对应的像素值,而插值算法的作用就是根据已知的像素值来推测未知位置的像素值。
1 最近邻插值
-
CV2.INTER_NEAREST
new_img1=cv.warpAffine(img,M,(w,h),flags=cv.INTER_NEAREST)
首先给出目标点与原图像点之间坐标的计算公式:
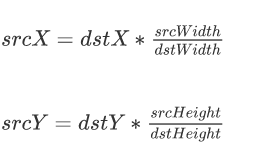

通俗的讲,该公式就是让目标图像中的每个像素值都能找到对应的原图中的像素值,这样才能根据不同的插值方法来获取新的像素值。根据该公式,我们就可以得到每一个目标点所对应的原图像的点,比如一个2*2的图像放大到4*4,如下图所示,其中红色的为每个像素点的坐标,黑色的则表示该像素点的像素值。
那么根据公式我们就可以计算出放大后的图像(0,0)点对应的原图像中的坐标为:
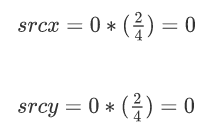
也就是原图中的(0,0)点,而最近邻插值的原则是:目标像素点的像素值与经过该公式计算出来的对应的像素点的像素值相同,如出现小数部分需要进行取整。那么放大后图像的(0,0)坐标处的像素值就是原图像中(0,0)坐标处的像素值,也就是10。接下来就是计算放大后图像(1,0)点对应的原图像的坐标,还是带入公式:
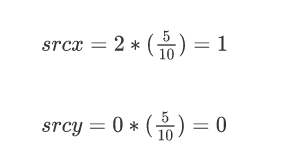
也就是原图中的(0.5,0)点,因此需要对计算出来的坐标值进行取整,取整后的结果为(0,0),也就是说放大后的图像中的(1,0)坐标处对应的像素值就是原图中(0,0)坐标处的像素值,其他像素点计算规则与此相同。
思考:
一张图的第一行像素点的值分别为: 10 10 20 30 40 放大一倍后 新图像的第一行的第3个像素点的值是多少?
点坐标:(2,0)
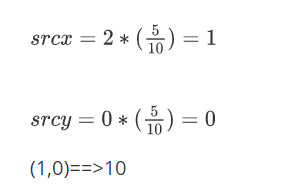
4x2的图像放大到8x4,放大一倍
2 双线性插值
-
CV2.INTER_LINEAR
双线性插值是一种图像缩放、旋转或平移时进行像素值估计的插值方法。当需要对图像进行变换时,特别是尺寸变化时,原始图像的某些像素坐标可能不再是新图像中的整数位置,这时就需要使用插值算法来确定这些非整数坐标的像素值。
双线性插值的工作原理是这样的:
-
假设要查找目标图像上坐标为
(x', y')的像素值,在原图像上对应的浮点坐标为(x, y)。 -
在原图像上找到四个最接近
(x, y)的像素点,通常记作P00(x0, y0),P01(x0, y1),P10(x1, y0),P11(x1, y1),它们构成一个2x2的邻域矩阵。 -
分别在水平方向和垂直方向上做线性插值:
-
水平方向:根据
x与x0和x1的关系计算出P00和P10、P01和P11之间的插值结果。 -
垂直方向:将第一步的结果与
y与y0和y1的关系结合,再在垂直方向上做一次线性插值。
-
综合上述两次线性插值的结果,得到最终位于
(x', y')处的新像素的估计值。
总结: 4乘4的图像 变成6乘6的图像 那么目标图像的(3,3)点的像素是原图中(1.8333,1.8333)的像素颜色,但是坐标必须是整数 它周围有四个像素点 该取谁呢? 按照到各自的距离比例 来分配颜色值
首先要了解线性插值,而双线性插值本质上就是在两个方向上做线性插值。还是给出目标点与原图像中点的计算公式
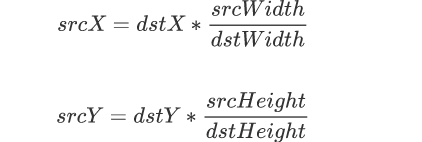
然后根据Q11、Q21得到R1的插值,根据Q12、Q22得到R2的插值,然后根据R1、R2得到P的插值即可,这就是双线性插值。以下是计算过程:
首先计算R1和R2的插值: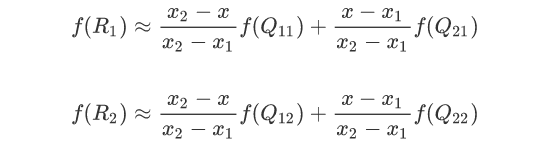
然后根据R1和R2计算P的插值: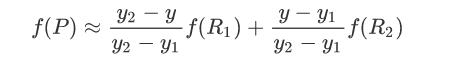
这样就得到了P点的插值。注意此处如果先在y方向插值、再在x方向插值,其结果与按照上述顺序双线性插值的结果是一样的。
双线性插值的对应关系看似比较清晰,但还是有2个问题。首先是根据坐标系的不同,产生的结果不同,这张图是左上角为坐标系原点的情况,我们可以发现最左边x=0的点都会有概率直接复制到目标图像中(至少原点肯定是这样),而且就算不和原图像中的点重合,也相当于进行了1次单线性插值(带入到权重公式中会发现结果)。
下面这张图是右上角为坐标系原点的情况,我们可以发现最右面的点都会有概率直接复制到目标图像中(至少原点肯定是这样),而且就算不和原图像中的点重合,也相当于进行了1次单线性插值。那么当我们采用不同的坐标系时产生的结果是不一样的,而且无论我们采用什么坐标系,最左侧和最右侧(最上侧和最下侧)的点是“不公平的”,这是第一个问题。
第二个问题时整体的图像相对位置会发生变化。如下图所示,左侧是原图像(3,3),右侧是目标图像(5,5),原图像的几何中心点是(1,1),目标图像的几何中心点是(2,2),根据对应关系,目标图像的几何中心点对应的原图像的位置是(1.2,1.2),那么问题来了,目标图像的原点(0,0)和原始图像的原点是重合的,但是目标图像的几何中心点相对于原始图像的几何中心点偏右下,那么整体图像的位置会发生偏移,所以参与计算的点相对都往右下偏移会产生相对的位置信息损失。这是第二个问题。
因此,在OpenCV中,为了解决这两个问题,将公式进行了优化,如下所示:
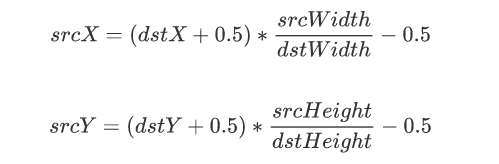
使用该公式计算出原图中的对应坐标后再进行插值计算,就不会出现上面的情况了。
3 像素区域插值
-
cv2.INTER_AREA
像素区域插值主要分两种情况,缩小图像和放大图像的工作原理并不相同。
-
当使用像素区域插值方法进行缩小图像时,它就会变成一个均值滤波器(滤波器其实就是一个核,这里只做简单了解,后面实验中会介绍),其工作原理可以理解为对一个区域内的像素值取平均值。
-
当使用像素区域插值方法进行放大图像时
-
如果图像放大的比例是整数倍,那么其工作原理与最近邻插值类似;
-
如果放大的比例不是整数倍,那么就会调用双线性插值进行放大。
-
其中目标像素点与原图像的像素点的对应公式如下所示:
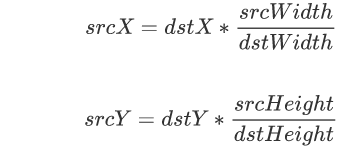
4 双三次插值
-
cv2.INTER_CUBIC
与双线性插值法相同,该方法也是通过映射,在映射点的邻域内通过加权来得到放大图像中的像素值。不同的是,双三次插值法需要原图像中近邻的16个点来加权,也就是4x4的网格。
目标像素点与原图像的像素点的对应公式如下所示:
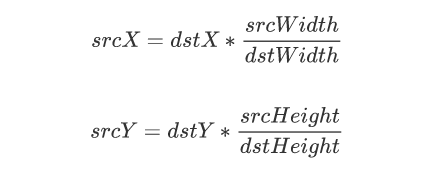
下面我们举例说明,假设原图像A大小为m*n,缩放后的目标图像B的大小为M*N。其中A的每一个像素点是已知的,B是未知的,我们想要求出目标图像B中每一个像素点(X,Y)的值,必须先找出像素(X,Y)在原图像A中对应的像素(x,y),再根据原图像A距离像素(x,y)最近的16个像素点作为计算目标图像B(X,Y)处像素值的参数,利用BiCubic基函数求出16个像素点的权重,图B像素(x,y)的值就等于16个像素点的加权叠加。
BiCubic基函数也就是双三次插值的权重函数,它决定了如何根据距离对周围像素进行加权平均。
假如下图中的P点就是目标图像B在(X,Y)处根据上述公式计算出的对应于原图像A中的位置,P的坐标位置会出现小数部分,所以我们假设P点的坐标为(x+u,y+v),其中x、y表示整数部分,u、v表示小数部分,那么我们就可以得到其周围的最近的16个像素的位置,我们用a(i,j)(i,j=0,1,2,3)来表示,如下图所示。
然后给出BiCubic函数:
a一般取-0.5或-0.75,用于控制插值函数的形状。
d代表的是目标像素点与某个像素点之间的相对距离,、
我们要做的就是将上面的16个点相较于p点的位置距离算出来,获取16像素所对应的权重。然而BiCubic函数是一维的,所以我们需要将像素点的行与列分开计算,比如a00这个点,我们需要将带入BiCubic函数中,计算a00点对于P点的x方向的权重,然后将带入BiCubic函数中,计算a00点对于P点的y方向的权重,其他像素点也是这样的计算过程,最终我们就可以得到P所对应的目标图像B在(X,Y)处的像素值为:
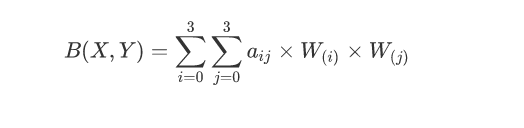
依此办法我们就可以得到目标图像中所有的像素点的像素值。
刚刚我们说拿到了目标点的坐标为 ,其中 、 表示整数部分,u、v表示小数部分。那么我们取坐标的整数部分作为参考点,也就是,小数部分表示目标像素相对于参考点的偏移量。
比如说目标点的坐标为,那么我们的参考点就是。
目标部分相对于参考点的偏移量:
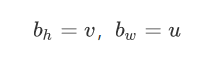
然后我们才需要来计算相邻像素和目标像素的距离:
比如我们的P点在行上的 四个像素![]() ,对应的距离就是:
,对应的距离就是:![]()
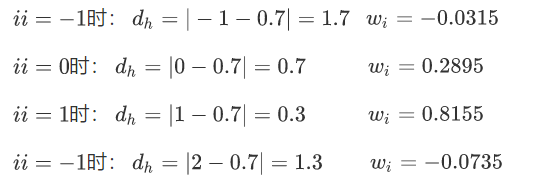
在列上的 四个像素![]() ,对应的距离就是:
,对应的距离就是:![]()
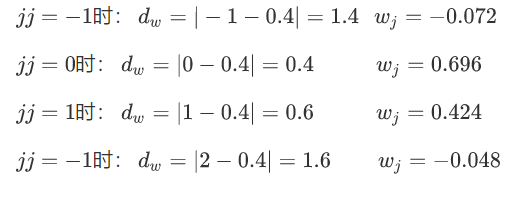
最后利用我们的加权求和算出像素值:
公式
$$B(X,Y)=\sum_{i=0}^{3}\sum_{j=0}^{3}a_{i j}\times W_{(i)}\times W_{(j)}$$
![]()
5 lanczos 插值
###
- ```
cv2.INTER_LANCZOS4
```
Lanczos插值方法与双三次插值的思想是一样的,不同的就是其需要的原图像周围的像素点的范围变成了8\*8,并且不再使用BiCubic函数来计算权重,而是换了一个公式计算权重。
首先还是目标像素点与原图像的像素点的对应公式如下所示: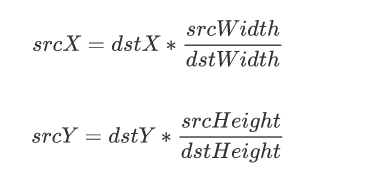
下面我们举例说明,假设原图像A大小为m\*n,缩放后的目标图像B的大小为M\*N。其中A的每一个像素点是已知的,B是未知的,我们想要求出目标图像B中每一个像素点(X,Y)的值,必须先找出像素(X,Y)在原图像A中对应的像素(x,y),再根据原图像A距离像素(x,y)最近的64个像素点作为计算目标图像B(X,Y)处像素值的参数,利用权重函数求出64个像素点的权重,图B像素(x,y)的值就等于64个像素点的**加权**叠加。
假如下图中的P点就是目标图像B在(X,Y)处根据上述公式计算出的对应于原图像A中的位置,P的坐标位置会出现小数部分,所以我们假设P点的坐标为(x+u,y+v),其中x、y表示整数部分,u、v表示小数部分,那么我们就可以得到其周围的最近的64个像素的位置,我们用a(i,j)(i,j=0,1,2,3,4,5,6,7)来表示,如下图所示。

然后给出权重公式:

其中a通常取2或者3,当a=2时,该算法适用于图像缩小。a=3时,该算法适用于图像放大。
与双三次插值一样,这里也需要将像素点分行和列分别带入计算权重值,其他像素点也是这样的计算过程,最终我们就可以得到P所对应的目标图像B在(X,Y)处的像素值为: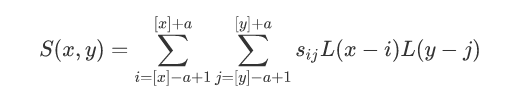
其中$[x]$、$[y]$表示对坐标值向下取整,通过该方法就可以计算出新的图像中所有的像素点的像素值。
6 小结
最近邻插值的计算速度最快,但是可能会导致图像出现锯齿状边缘和失真,效果较差。双线性插值的计算速度慢一点,但效果有了大幅度的提高,适用于大多数场景。双三次插值、Lanczos插值的计算速度都很慢,但是效果都很好。
在OpenCV中,关于插值方法默认选择的都是双线性插值,且一般情况下双线性插值已经能满足大部分需求。
import cv2 as cv
# 读图
cat=cv.imread("../images/cat1.png")
cat=cv.resize(cat,(480,480))
h,w=cat.shape[:2]
# 获取旋转矩阵
M=cv.getRotationMatrix2D((w//2,h//2),45,0.8)
# 仿射变换函数 实现旋转
dst=cv.warpAffine(cat,M,(w,h),flags=cv.INTER_NEAREST)# 最近邻 速度快 精度相较低
dst1=cv.warpAffine(cat,M,(w,h),flags=cv.INTER_AREA)# 像素区域 放大(整数 非整数) 缩小
dst2=cv.warpAffine(cat,M,(w,h),flags=cv.INTER_LINEAR)# 双线性 4个 2x2 2次线性插值 水平+垂直
dst3=cv.warpAffine(cat,M,(w,h),flags=cv.INTER_CUBIC)# 双三次 16个 4x4
dst4=cv.warpAffine(cat,M,(w,h),flags=cv.INTER_LANCZOS4)# lanczos 64个 8x8
# 显示效果 释放资源
cv.imshow("cat",cat)
cv.imshow("dst",dst)
cv.waitKey(0)
cv.destroyAllWindows()
四 边缘填充
在图像处理中,边缘填充(Padding)是一种常用的技术,主要用于解决图像在进行卷积操作、滤波、缩放或其他几何变换时可能出现的问题。以下是进行边缘填充的主要原因:
1. 避免边界像素丢失
在卷积操作(如图像滤波、卷积神经网络中的卷积层)中,卷积核会滑动并覆盖图像的每个像素区域。当卷积核滑动到图像的边缘时,部分卷积核会超出图像边界。如果不进行边缘填充,这些边缘像素将无法被完整地处理,导致图像边缘信息丢失。
例子: 假设有一个 3×3 的卷积核,对一个 5×5 的图像进行卷积操作。如果不进行填充,输出图像的大小会变成 3×3,因为卷积核无法覆盖图像的边缘部分。通过填充,可以保持图像的大小不变。
2. 保持图像尺寸
在某些情况下,我们希望在进行卷积操作后保持图像的尺寸不变。通过在图像边缘添加填充(通常是零填充或镜像填充),可以使卷积操作后的图像大小与原始图像相同。
例子: 如果在卷积操作中使用了填充,输出图像的大小可以保持为 5×5,而不是缩小到 3×3。
3. 减少边界效应
在图像处理中,边界像素通常会受到边界效应的影响,例如在进行滤波操作时,边界像素的滤波结果可能不准确。通过填充,可以减少这种边界效应,使边界像素的处理更加合理。
4. 提供上下文信息
在卷积神经网络中,填充可以帮助网络更好地捕捉图像的上下文信息。通过在边缘添加填充,卷积核可以覆盖更多的像素,从而更好地理解图像的局部结构。
5. 支持多种操作
在进行图像缩放、旋转或其他几何变换时,填充可以确保图像在变换后不会出现空白区域。例如,在进行透视变换时,填充可以确保变换后的图像完整。
常见的填充方式
-
零填充(Zero Padding):在图像边缘填充零值像素。
-
镜像填充(Mirror Padding):在图像边缘填充与边缘像素对称的像素值。
-
复制填充(Replicate Padding):在图像边缘复制边缘像素的值。
-
常数填充(Constant Padding):在图像边缘填充指定的常数值。
总结
边缘填充的主要目的是:
-
避免边界像素丢失。
-
保持图像尺寸。
-
减少边界效应。
-
提供上下文信息。
-
支持多种图像操作。
通过合理使用边缘填充,可以显著提高图像处理的效果和效率。
import cv2 as cv
# 读图
cat=cv.imread("../images/cat1.png")
cat=cv.resize(cat,(480,480))
h,w=cat.shape[:2]
# 获取旋转矩阵
M=cv.getRotationMatrix2D((w//2,h//2),45,0.5)
# 仿射变换函数 实现旋转
# 边界复制
dst=cv.warpAffine(cat,M,(640,640),borderMode=cv.BORDER_REPLICATE)
# 边界反射
dst2=cv.warpAffine(cat,M,(640,640),borderMode=cv.BORDER_REFLECT)
# 边界反射101
dst3=cv.warpAffine(cat,M,(640,640),borderMode=cv.BORDER_REFLECT_101)
# 边界常数
dst4=cv.warpAffine(cat,M,(640,640),borderMode=cv.BORDER_CONSTANT,borderValue=(255,0,0))
# 边界包裹
dst5=cv.warpAffine(cat,M,(640,640),borderMode=cv.BORDER_WRAP)
# 显示效果 释放资源
cv.imshow("cat",cat)
# cv.imshow("dst",dst)
# cv.imshow("dst2",dst2)
# cv.imshow("dst3",dst3)
# cv.imshow("dst4",dst4)
cv.imshow("dst5",dst5)
cv.waitKey(0)
cv.destroyAllWindows()
五 图像矫正
图像矫正的原理是透视变换,下面来介绍一下透视变换的概念。
听名字有点熟,我们在图像旋转里接触过仿射变换,知道仿射变换是把一个二维坐标系转换到另一个二维坐标系的过程,转换过程坐标点的相对位置和属性不发生变换,是一个线性变换,该过程只发生旋转和平移过程。因此,一个平行四边形经过仿射变换后还是一个平行四边形。
而透视变换是把一个图像投影到一个新的视平面的过程,在现实世界中,我们观察到的物体在视觉上会受到透视效果的影响,即远处的物体看起来会比近处的物体小。透视投影是指将三维空间中的物体投影到二维平面上的过程,这个过程会导致物体在图像中出现形变和透视畸变。透视变换可以通过数学模型来校正这种透视畸变,使得图像中的物体看起来更符合我们的直观感受。通俗的讲,透视变换的作用其实就是改变一下图像里的目标物体的被观察的视角。

如上图所示,图左在经过透视变换后得到了图右的结果,带入上面的话就是图像中的vip卡(目标物体)的被观察视角从平视视角变成了俯视视角,这就是透视变换的作用。
假设我们有一个点在三维空间中,并且我们想要将其投影到二维平面上。我们可以先将其转换为齐次坐标,,然后进行透视投影,得到了经过透视投影后的二维坐标。通过将和 分别除以,我们可以模拟出真实的透视效果。
与仿射变换一样,透视变换也有自己的透视变换矩阵:

即
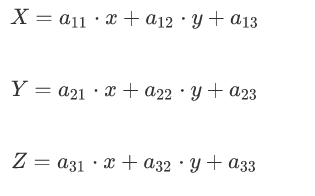
由此可得新的坐标的表达式为:
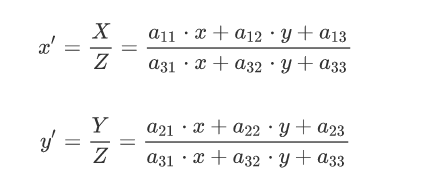
其中x、y是原始图像点的坐标,、是变换后的坐标,a11,a12,…,a33则是一些旋转量和平移量,由于透视变换矩阵的推导涉及三维的转换,所以这里不具体研究该矩阵,只要会使用就行,而OpenCV里也提供了getPerspectiveTransform()函数用来生成该3*3的透视变换矩阵。
-
M=getPerspectiveTransform(src,dst)
在该函数中,需要提供两个参数:
src:原图像上需要进行透视变化的四个点的坐标,这四个点用于定义一个原图中的四边形区域。
dst:透视变换后,src的四个点在新目标图像的四个新坐标。
该函数会返回一个透视变换矩阵,得到透视变化矩阵之后,使用warpPerspective()函数即可进行透视变化计算,并得到新的图像。该函
数需要提供如下参数:
-
cv2.warpPerspective(src, M, dsize, flags, borderMode)
src:输入图像。
M:透视变换矩阵。这个矩阵可以通过getPerspectiveTransform函数计算得到。
dsize:输出图像的大小。它可以是一个Size对象,也可以是一个二元组。
flags:插值方法的标记。
borderMode:边界填充的模式。
import cv2 as cv
import numpy as np
# 读图
card=cv.imread("../images/3.png")
shape=card.shape
# 定义点坐标 184,100 509,142 494,337 120,291
pts1=np.float32([[184,100],[509,142],[494,337],[120,291]])
pts2=np.float32([[0,0],[shape[1],0],[shape[1],shape[0]],[0,shape[0]]])
# 透视变换矩阵
M=cv.getPerspectiveTransform(pts1,pts2)
# 透视变换
dst=cv.warpPerspective(card,M,(shape[1],shape[0]),flags=cv.INTER_LINEAR,borderMode=cv.BORDER_WRAP)
# 显示效果
cv.imshow("card",card)
cv.imshow("dst",dst)
cv.waitKey(0)
cv.destroyAllWindows()
六 色彩空间转换
OpenCV中,图像色彩空间转换是一个非常基础且重要的操作,就是将图像从一种颜色表示形式转换为另一种表示形式的过程。通过将图像从一个色彩空间转换到另一个色彩空间,可以更好地进行特定类型的图像处理和分析任务。常见的颜色空间包括RGB、HSV、YUV等。
-
色彩空间转换的作用
-
提高图像处理效果
-
节省计算资源
-
1 RGB色彩空间
在图像处理中,最常见的就是RGB颜色空间。RGB颜色空间是我们接触最多的颜色空间,是一种用于表示和显示彩色图像的一种颜色模型。RGB代表红色(Red)、绿色(Green)和蓝色(Blue),这三种颜色通过不同强度的光的组合来创建其他颜色,广泛应用于我们的生活中,比如电视、电脑显示屏以及上面实验中所介绍的RGB彩色图。
RGB颜色模型基于笛卡尔坐标系,如下图所示,RGB原色值位于3个角上,二次色青色、红色和黄色位于另外三个角上,黑色位于原点处,白色位于离原点最远的角上。因为黑色在RGB三通道中表现为(0,0,0),所以映射到这里就是原点;而白色是(255,255,255),所以映射到这里就是三个坐标为最大值的点。
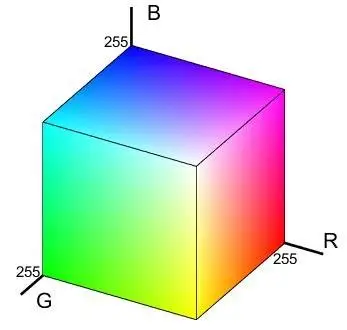
RGB颜色空间可以产生大约1600万种颜色,几乎包括了世界上的所有颜色,也就是说可以使用RGB颜色空间来生成任意一种颜色。
注意:在OpenCV中,颜色是以BGR的方式进行存储的,而不是RGB,这也是上面红色的像素值是(0,0,255)而不是(255,0,0)的原因。
2 颜色加法和颜色加权加法
你可以使用OpenCV的cv.add()函数把两幅图像相加,或者可以简单地通过numpy操作添加两个图像,如res = img1 + img2。两个图像应该具有相同的大小和类型。
OpenCV加法和Numpy加法之间存在差异。OpenCV的加法是饱和操作,而Numpy添加是模运算。
cv2.addWeighted(src1,alpha,src2,deta,gamma)
-
src1、src2:输入图像。 -
alpha、beta:两张图象权重。 -
gamma:亮度调整值。-
gamma > 0,图像会变亮。 -
gamma < 0,图像会变暗。 -
gamma = 0,则没有额外的亮度调整。
-
这其实也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混合或者透明的感觉。图像混合的计算公式如下:
g(x) = (1−α)f0(x) + αf1(x)
通过修改 α 的值(0 → 1),可以实现非常炫酷的混合。
现在我们把两幅图混合在一起。第一幅图的权重是0.7,第二幅图的权重是0.3。函数cv2.addWeighted()可以按下面的公式对图片进行混合操作。
dst = α⋅img1 + β⋅img2 + γ
这里γ取为零。
import cv2 as cv
import numpy as np
x=np.uint8([[250]])
y=np.uint8([[10]])
# 读图
pig=cv.imread("../images/pig.png")
cao=cv.imread("../images/cao.png")
# 饱和操作 cv.add()
add=cv.add(x,y)
# print(add)
img_add=cv.add(pig,cao)
cv.imshow("add",img_add)
# numpy直接相加 取模运算 对256取模 取余
dst=x+y
# print(dst)
img_dst=cao+pig
cv.imshow("dst",img_dst)
# 颜色加权加法
img_weight=cv.addWeighted(cao,0.3,pig,0.7,10)
cv.imshow("img_wight",img_weight)
cv.waitKey(0)
cv.destroyAllWindows()
3 hsv颜色空间
HSV颜色空间指的是HSV颜色模型,这是一种与RGB颜色模型并列的颜色空间表示法。RGB颜色模型使用红、绿、蓝三原色的强度来表示颜色,是一种加色法模型,即颜色的混合是添加三原色的强度。而HSV颜色空间使用色调(Hue)、饱和度(Saturation)和亮度(Value)三个参数来表示颜色,色调H表示颜色的种类,如红色、绿色、蓝色等;饱和度表示颜色的纯度或强度,如红色越纯,饱和度就越高;亮度表示颜色的明暗程度,如黑色比白色亮度低。
HSV颜色模型是一种六角锥体模型,如下图所示:
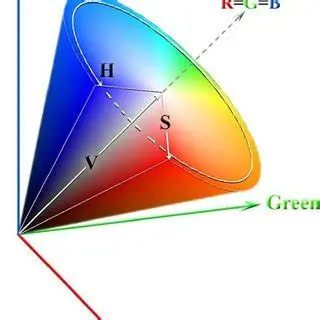
色调H:
使用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,紫色为300°。通过改变H的值,可以选择不同的颜色
饱和度S:
饱和度S表示颜色接近光谱色的程度。一种颜色可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例越大,颜色接近光谱色的程度就越高,颜色的饱和度就越高。饱和度越高,颜色就越深而艳,光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,其中0%表示灰色或无色,100%表示纯色,通过调整饱和度的值,可以使颜色变得更加鲜艳或者更加灰暗。
明度V:
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白),通过调整明度的值,可以使颜色变得更亮或者更暗。
一般对颜色空间的图像进行有效处理都是在HSV空间进行的,然后对于基本色中对应的HSV分量需要给定一个严格的范围,下面是通过实验计算的模糊范围(准确的范围在网上都没有给出)。
H: 0— 180
S: 0— 255
V: 0— 255
此处把部分红色归为紫色范围:
为什么有了RGB颜色空间我们还是需要转换成HSV颜色空间来进行图像处理呢?
-
符合人类对颜色的感知方式:人类对颜色的感知是基于色调、饱和度和亮度三个维度的,而HSV颜色空间恰好就是通过这三个维度来描述颜色的。因此,使用HSV空间处理图像可以更直观地调整颜色和进行色彩平衡等操作,更符合人类的感知习惯。
-
颜色调整更加直观:在HSV颜色空间中,色调、饱和度和亮度的调整都是直观的,而在RGB颜色空间中调整颜色不那么直观。例如,在RGB空间中要调整红色系的颜色,需要同时调整R、G、B三个通道的数值,而在HSV空间中只需要调整色调和饱和度即可。
-
降维处理有利于计算:在图像处理中,降维处理可以减少计算的复杂性和计算量。HSV颜色空间相对于RGB颜色空间,减少了两个维度(红、绿、蓝),这有利于进行一些计算和处理任务,比如色彩分割、匹配等。
因此,在进行图片颜色识别时,我们会将RGB图像转换到HSV颜色空间,然后根据颜色区间来识别目标颜色。
4 RGB转灰度(gray)和RGB转HSV
cv2.cvtColor是OpenCV中的一个函数,用于图像颜色空间的转换。可以将一个图像从一个颜色空间转换为另一个颜色空间,比如从RGB到灰度图,或者从RGB到HSV的转换等。
-
cv2.cvtColor(img,code)
-
img:输入图像,可以是一个Numpy数组绘着一个OpenCV的Mat对象-
Mat是一个核心的数据结构,主要用于存储图像和矩阵数据。在 Python 中使用 OpenCV 时,通常直接处理的是 NumPy 数组,cv2模块自动将Mat对象转换为 NumPy 数组。二者之间的转换是透明且自动完成的。例如,当你使用cv2.imread()函数读取图像时,返回的是一个 NumPy 数组,但在C++中则是Mat对象。
-
-
code:指定转换的类型,可以使用预定义的转换代码。-
例如
cv2.COLOR_RGB2GRAY表示从rgb到灰度图像的转换。
-
-
import cv2 as cv
# 读图
cat=cv.imread("../images/cat1.png")
gray1=cv.imread("../images/cat1.png",cv.IMREAD_GRAYSCALE)
# 转灰度
gray=cv.cvtColor(cat,cv.COLOR_BGR2GRAY)
print(gray.shape)
cv.imshow("gray",gray)
# 转HSV
hsv=cv.cvtColor(cat,cv.COLOR_BGR2HSV)
cv.imshow("hsv",hsv)
# 转RGB
rgb=cv.cvtColor(cat,cv.COLOR_BGR2RGB)
cv.imshow("rgb",rgb)
cv.waitKey(0)
cv.destroyAllWindows()

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 48
48 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)