第二十二课 专属你的小说智能问答助手
本文介绍了一个基于知识库检索与大模型推理的智能对话系统构建流程。测试显示系统在80%情况下表现良好,能清晰梳理人物关系,但在处理"次数类"问题时存在检索结果不完整的局限(仅返回20条内容且缺乏时间顺序),建议优化知识库的分段处理和检索功能。
此智能体简单但实用,它构建一个集成会话管理、知识库检索与大模型推理的智能对话系统。传入一本小说文档,就能帮你解答关于小说的一切问题。
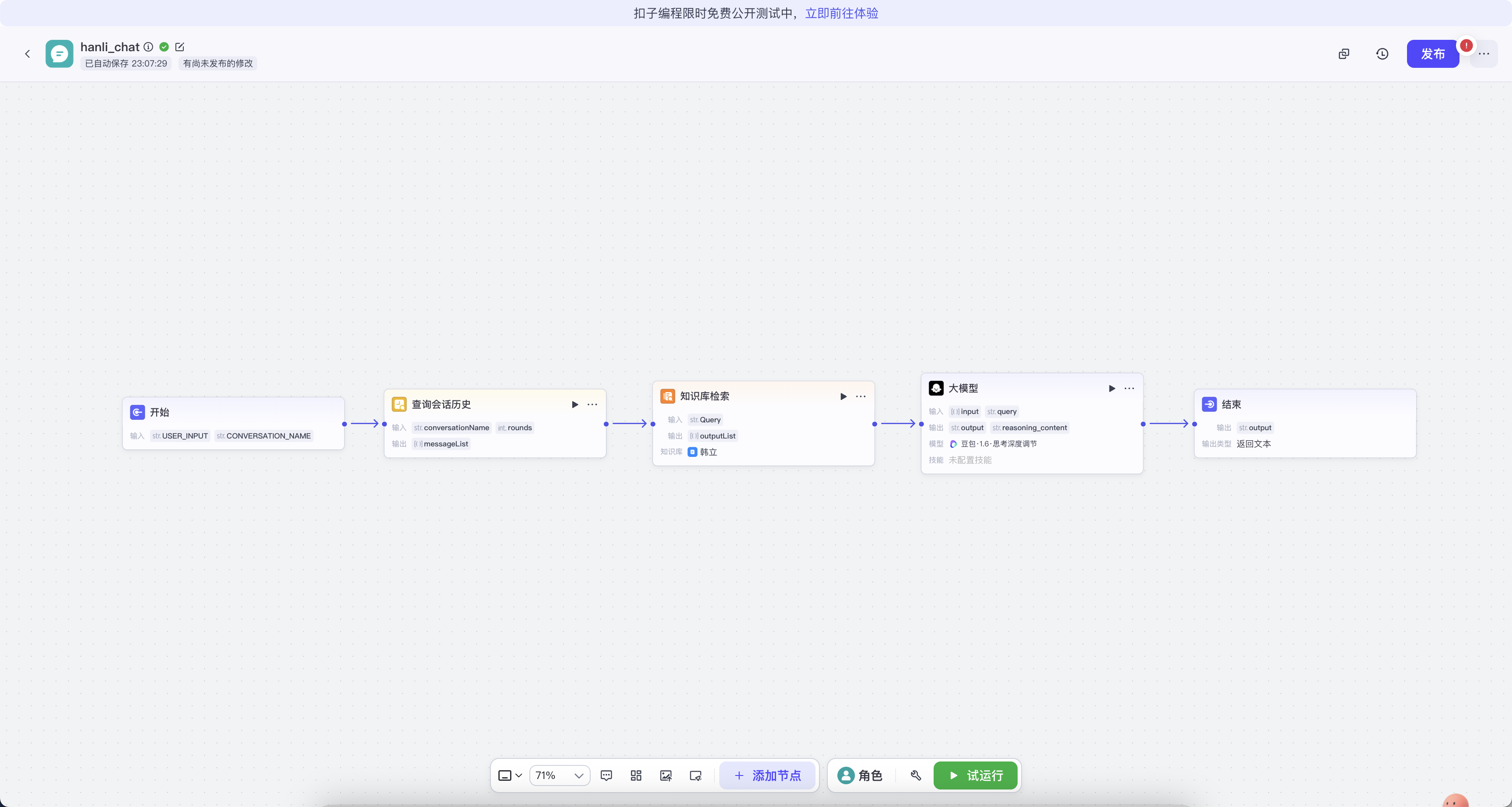
一、工作流整体概览
核心是一条典型的对话工作流,工作流思路:接收用户输入 → 管理会话上下文 → 检索相关知识 → 调用大模型生成回答。
二、分步教学详解
步骤1:开始节点
默认的【开始】节点:工作流的起点,触发后续流程。
- 默认输入【USER_INPUT】:接收用户发送的文本内容,作为本次处理的查询主体(query)。这里是整个工作流的输入来源,通常需在前端界面中配置输入框组件与之绑定。
- 默认输入【CONVERSATION_NAME】:设置或传递当前会话的唯一标识。在多轮对话中,该名称用于区分不同用户或不同对话线程。
步骤2:会话管理
节点【查询会话历史】:根据conversationName检索该会话之前的对话记录(messageList)。这一步是关键,它让AI能够理解上下文,实现连贯的多轮对话。

要先创建知识库,上传小说文档:

步骤3:知识库检索
- 【知识库检索】节点:利用用户当前的
query,在已关联的知识库中进行语义检索。这里会返回与问题相关的知识片段,为后续大模型提供准确、专业的信息支持,避免【凭空捏造】。

注意:最小匹配度的意思是:
- 0.01 表示完全不相关
- 1(0.99) 表示完全匹配,与查询意图100%一致
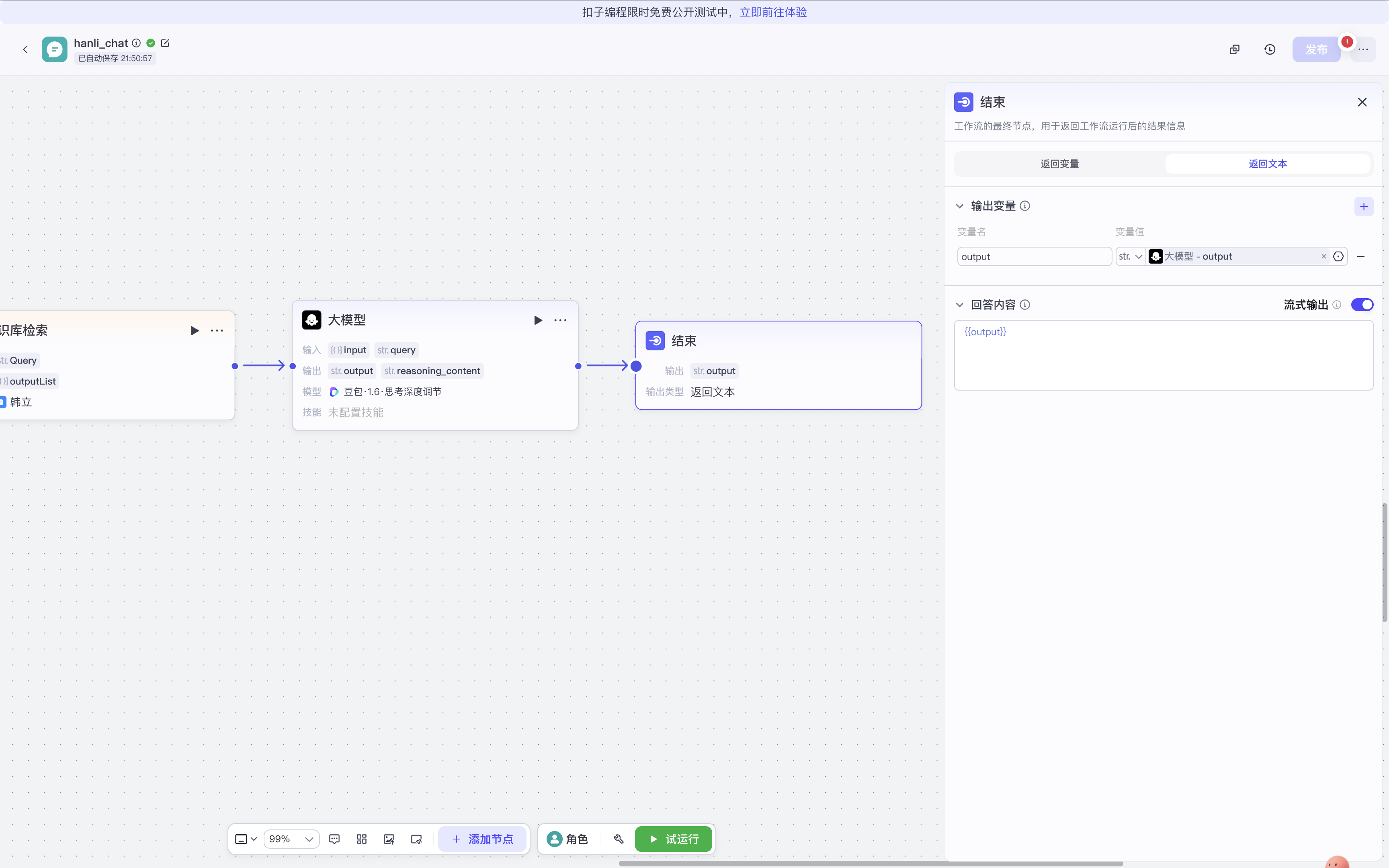
步骤4:大模型调用与推理
- 节点【大模型】:这是工作流的核心处理单元。
-
- 输入:整合之前的
query、历史对话messageList、以及知识库检索结果。 - 处理:大模型基于全部输入信息进行推理,生成回答的思考过程(
reasoning_content)和最终回复内容。
- 特色功能【思考深度调节】:此处可通过参数(如示例中的【豆包:1.6思考深度调节】)控制模型思考的复杂度和细致度。数值越高,模型可能表现得更深入、更周全,但响应时间也可能相应增加。
- 输入:整合之前的
步骤5:输出与返回
- 节点【outputList】:整理并输出最终的回复内容。通常包括:
-
- 模型生成的自然语言答案
- 可选的可解释性内容(如引用来源、简要推理说明)
- 输出结果最终返回给用户,完成一次完整的交互。
- 试运行成功后点击发布。
步骤6:智能体
创建一个智能体,
- 绑定刚刚发布的对话流。
- 人设就让它输出对话流的结果就行。
- 开场白略微写一下。

- 测试无误后点击发布。
小记
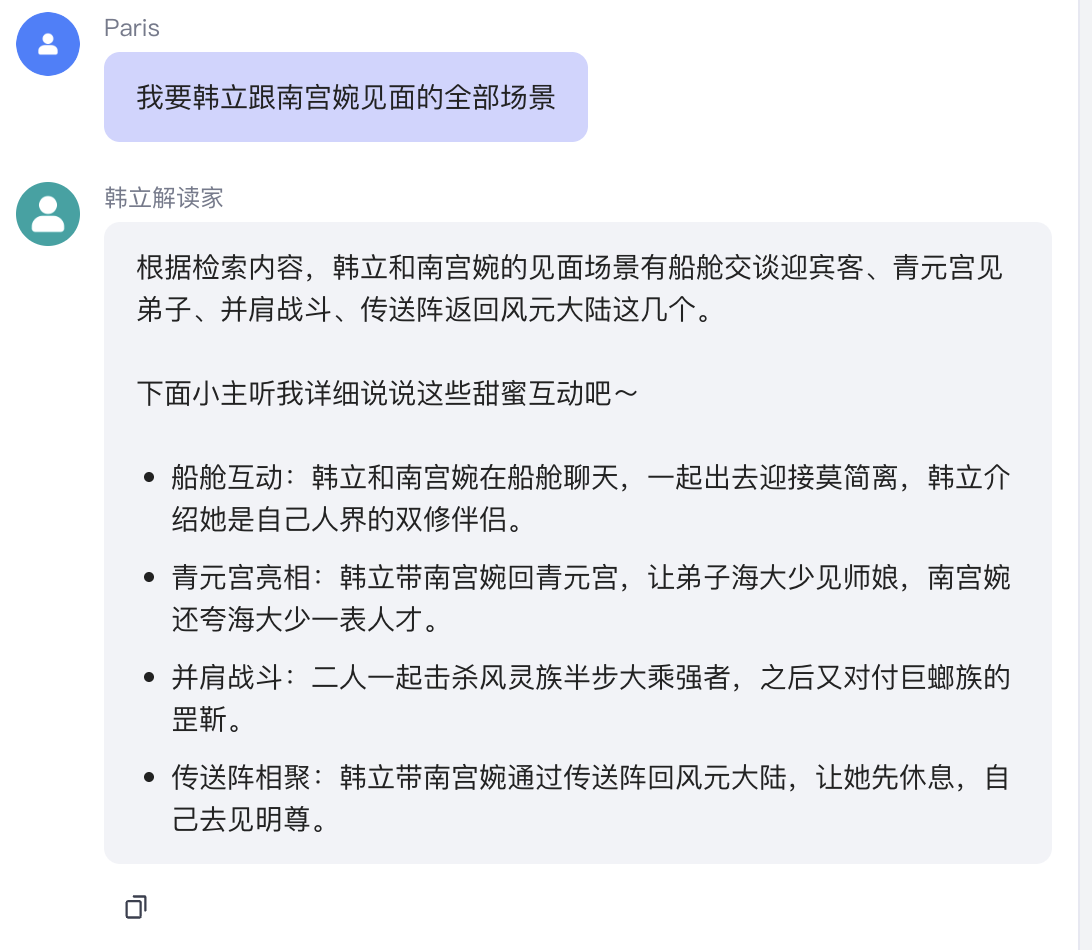
测了多次80%满意,因为问他“多少次”、“第几次”发生的事情时,【数据库检索】节点的输出提取到的内容不完善,原因一是只能检索到20条,原因二是时间顺序好像不存在。导致大模型由于拿到的输入不完全正确,输出也差点意思,如图,问:韩立跟南宫婉见面的场景有哪些?检索了20条内容,大模型输出就5条

继续追问,我要她俩见面的全部场景,倒反天罡,只给了我4个场景:
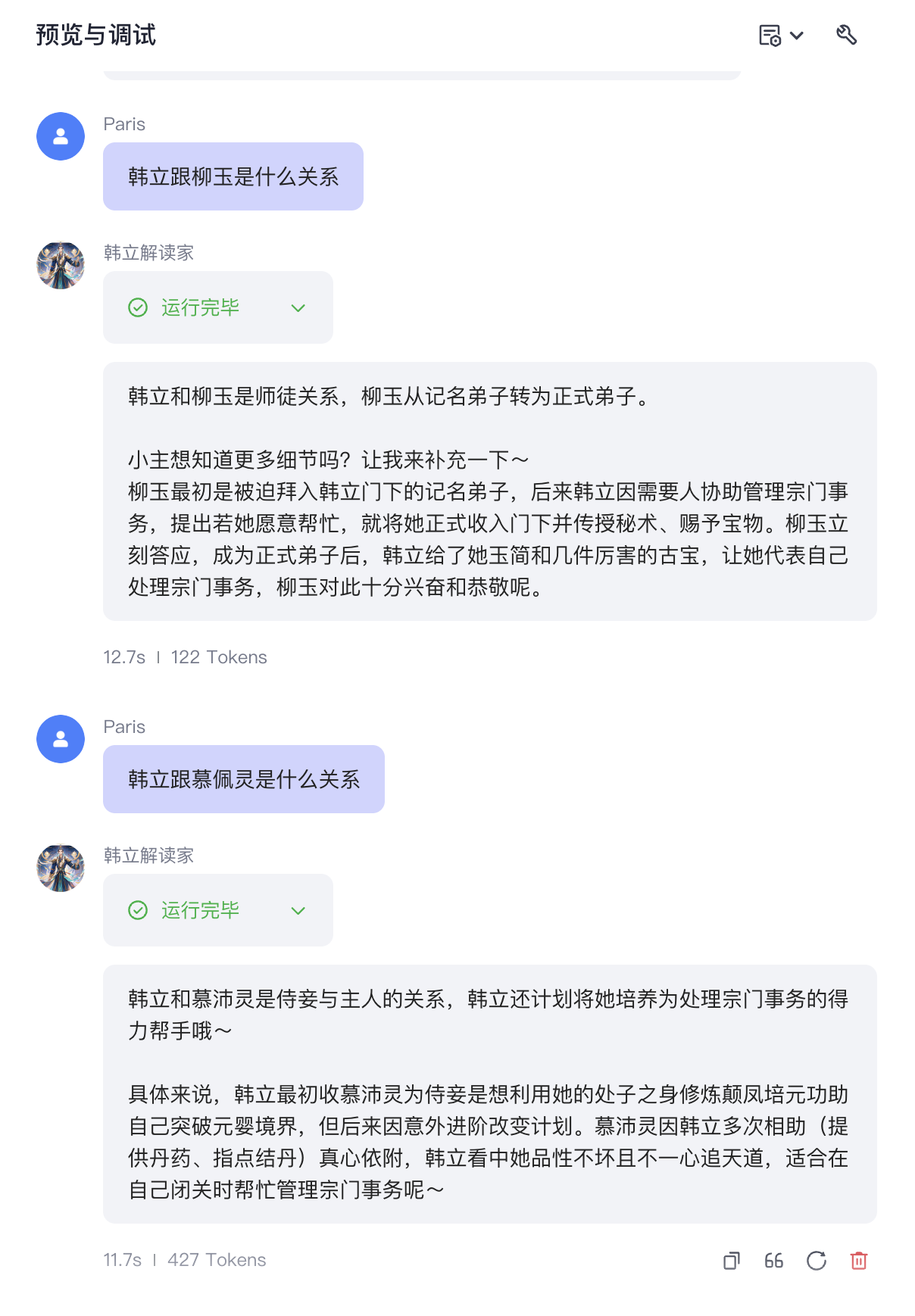
除此之外(不问关于次数的问题)都还挺好的,人物关系捋得很清:
coze的知识库检索应该加一些功能,还有知识库录入的分段,感觉还可以更智能,比如识别章节目录啥的,而不是只有几级标题。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)