小杰-大模型(six)——大模型部署与应用——Chatglm3-6B本地部署
东风袅袅泛崇光,香雾空蒙月转廊。
·
1. Chatglm3-6B本地部署
Chatglm3-6B大模型介绍
网址:https://zhipu-ai.feishu.cn/wiki/WvQbwIJ9tiPAxGk8ywDck6yfnof
部署Chatglm3-6B大模型的步骤
1. 环境准备
1.1使用Conda创建虚拟环境
1.点击开始,并在输入框输入Anaconda如下
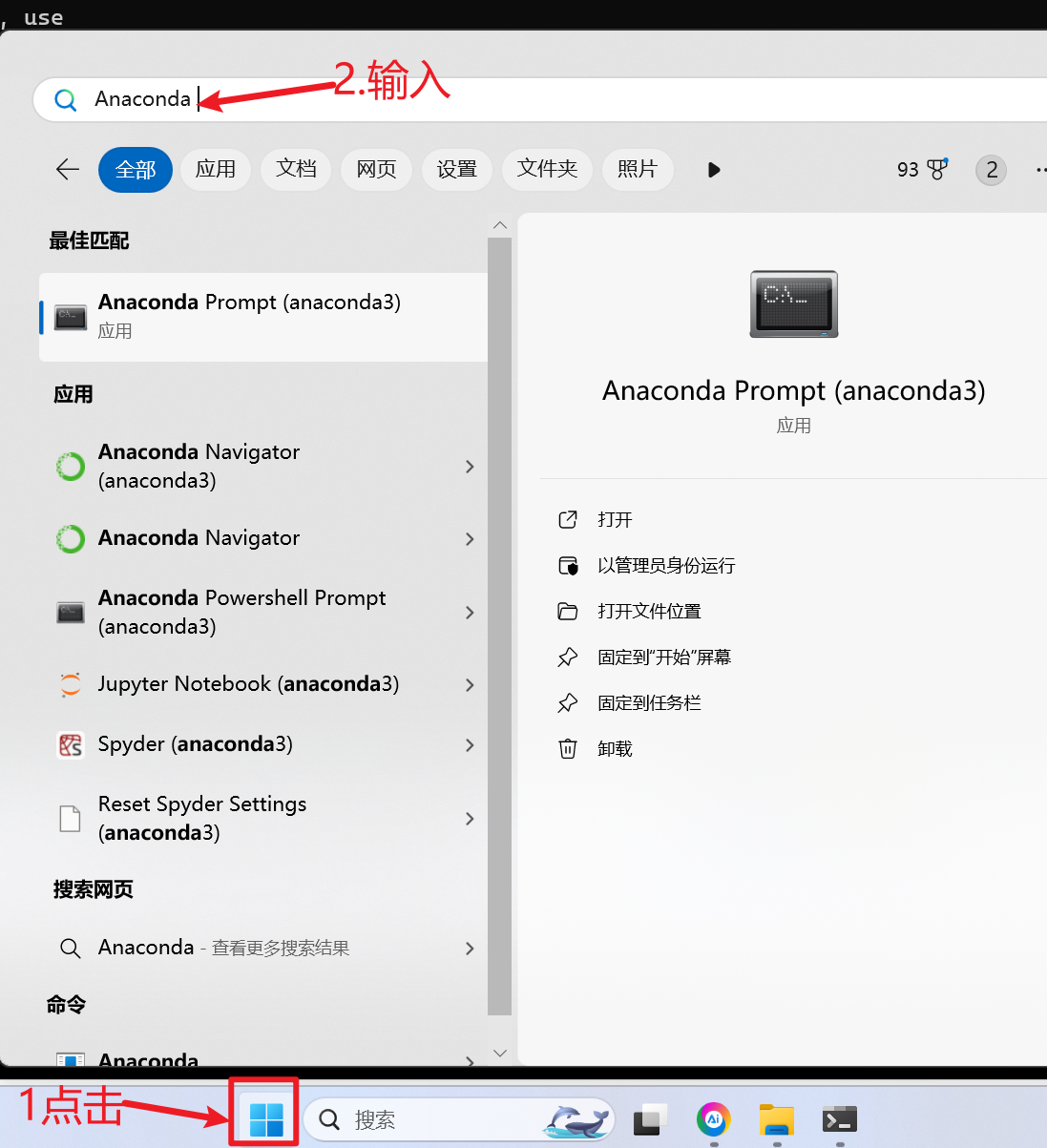
2.选择并打开
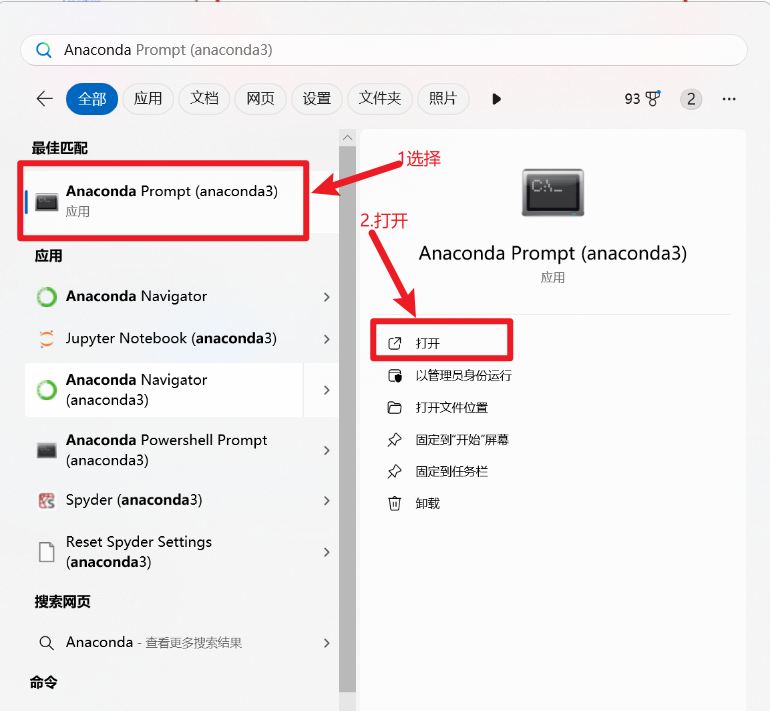
3.创建新的Python虚拟环境
# 安装 Miniconda 或 Anaconda 后,创建新的虚拟环境
conda create --name AI_env python=3.11.9
4.可选择激活或者不激活如下操作
# 激活虚拟环境
conda activate AI_env步骤2:在Pycharm中使用创建的环境
在设置中添加刚创建的虚拟环境。
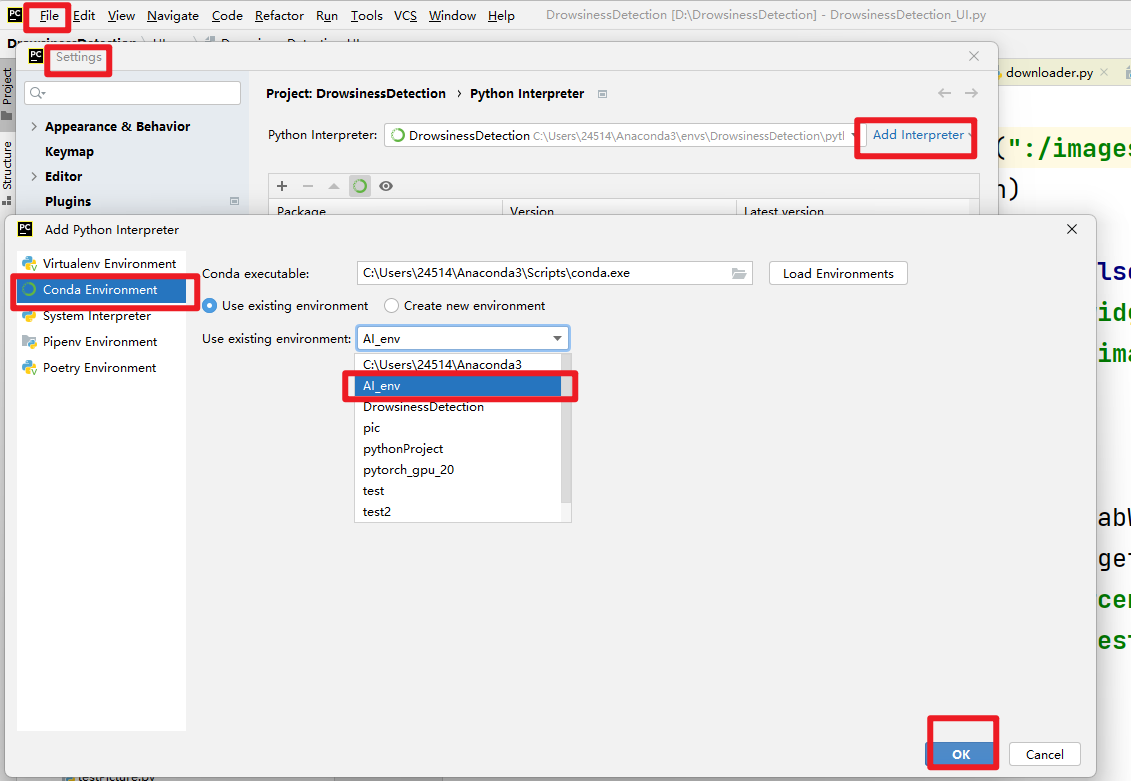
步骤3:安装必要依赖
在pycharm终端 使用以下命令安装所需的依赖库
安装 pytorch cpu版本(可选)
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple/安装 pytorch gpu版本(可选,如果有CUDA)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126安装 transformers(需要更换版本)
pip install transformers==4.41.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/pip install sentencepiece==0.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/2. 下载Chatglm3-6b模型
为了加快下载速度,我们使用魔搭社区的下载方式。
安装魔搭社区
pip install modelscope==1.18.1下载模型
from modelscope.hub.snapshot_download import snapshot_download
llm_model_dir = snapshot_download('ZhipuAI/chatglm3-6b',cache_dir='models')ZhipuAI/chatglm3-6b为魔搭社区上的路径。
models为本地路径。
3. 模型推理
代码示例
from transformers import AutoTokenizer, AutoModel
# 使用预训练模型chatglm3-6b的分词器实例化tokenizer对象。
#trust_remote_code必须得设置为True,不然无法运行
tokenizer = AutoTokenizer.from_pretrained("models/ZhipuAI/chatglm3-6b", trust_remote_code=True)
# 实例化一个预训练的模型
# .half() 是将模型权重从默认的 FP32(单精度浮点数)转换为 FP16(半精度浮点数)。
# 作用:减少显存占用(约节省 50%),提升计算速度(适合支持 FP16 的 GPU)。
model = AutoModel.from_pretrained("models/ZhipuAI/chatglm3-6b", trust_remote_code=True).half().cuda()
model = model.eval()
#glm chat里面封装了分词及转码
response, history = model.chat(tokenizer, "你好我是中国人你是哪里人", history=[])
print(response)
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)