am-ELO:一种稳定的基于竞技场的LLM评估框架
刘子睿 1{ }^{1}1 李佳同 1{ }^{1}1 庄岩 1{ }^{1}1 刘琦*12 沈双宏 2{ }^{2}2 欧阳杰 1{ }^{1}1 程明月 1{ }^{1}1 王世金 13{ }^{13}13基于竞技场的评估是现代AI模型,特别是大语言模型(LLMs)评估中的一个基本但重要的范式。现有的基于ELO评分系统的框架由于排名不一致以及对注释者能力变化的关注不足而不可避免地存在不稳定问题
刘子睿 1{ }^{1}1 李佳同 1{ }^{1}1 庄岩 1{ }^{1}1 刘琦*12 沈双宏 2{ }^{2}2 欧阳杰 1{ }^{1}1 程明月 1{ }^{1}1 王世金 13{ }^{13}13
摘要
基于竞技场的评估是现代AI模型,特别是大语言模型(LLMs)评估中的一个基本但重要的范式。现有的基于ELO评分系统的框架由于排名不一致以及对注释者能力变化的关注不足而不可避免地存在不稳定问题。在本文中,我们通过改进ELO评分系统引入了一种新的稳定竞技场框架来解决这些问题。具体来说,我们将迭代更新方法替换为最大似然估计(MLE)方法,即m-ELO,并提供了模型排名中MLE方法一致性与稳定性的理论证明。此外,我们提出了am-ELO,它修改了ELO评分的概率函数以纳入注释者能力,从而能够同时估计模型得分和注释者可靠性。实验表明,这种方法确保了稳定性,证明该框架为LLMs提供了一种更强大、准确且稳定的评估方法。
1. 引言
大语言模型(LLMs)的快速发展(Jin等人,2024b;Ouyang等人,2025;Cheng等人,2025)导致了“模型竞技场”的激增——这些平台旨在比较和评估多个模型,识别它们的相对优劣势(Chiang等人,2024)。这些竞技场在推动创新和塑造前沿LLMs在各种应用中的部署方面发挥着关键作用。ELO评分系统(Elo,1967),作为一种量化游戏竞争者相对能力的成熟方法论,构成了大多数现有模型竞技场评估系统的理论基础(Bai等人,2022;Boubdir等人,2023)。
当前ELO方法的一个显著问题是其不稳定性,这可以归因于两个主要原因:1) 从算法角度来看,现有的ELO方法将数据视为动态数据,使得结果对数据呈现顺序高度敏感(Aldous,2017;Li等人,2024;Zhang等人,2024a)。换句话说,当相同的记录被打乱并重新评估时,ELO方法通常会产生不一致的分数。例如,如图1所示,显著的误差(灰色突出显示)使相似能力模型的比较复杂化。2) 人类注释者的判断在质量、相关性和文本重要性等方面有所不同。例如,在图1的折线图中,不同的注释者为每个模型提供了不一致的ELO分数。然而,涉及人类参与的竞技场评估范式忽略了这些个体差异(Welinder & Perona,2010;Raykar & Yu,2011)。
忽略这种变异性会将偏差和不稳定性引入评估过程,进一步削弱结果及其衍生决策的可信度
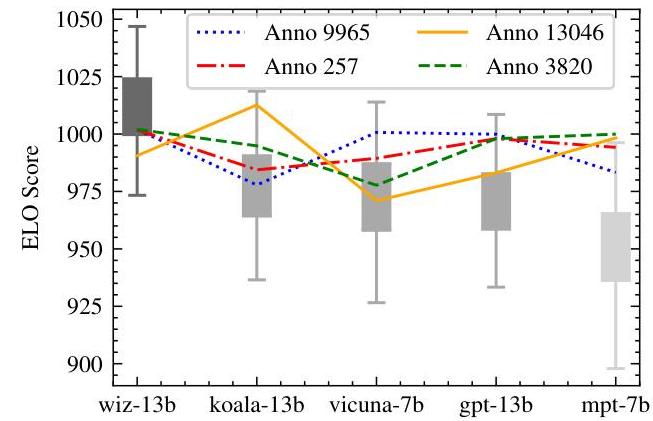
图1. ELO分数的例子。误差棒表示标准差,误差线表示最大值或最小值与平均值之间的差异。折线图表示从特定注释者的记录中估计出的ELO分数。
(Eickhoff, 2018)。这些不稳定性降低了ELO分数的可解释性和实际价值,侵蚀了从中得出结论的信心,特别是在用于影响高风险决策时,如模型部署或研究方向。
在本工作中,我们提出了一种新的稳定竞技场框架以解决这些缺点。如图2所示,为了缓解ELO分数的不一致性,我们引入了一种基于最大似然估计(MLE)的ELO评分方法,称为m-ELO。通过推导该重述的理论性质,我们展示了所提出的方法在不改变原始ELO方法基本原理的情况下产生一致的结果。此外,为了考虑注释者表现的变化,我们提出了一种针对ELO的注释者能力感知增强方法(am-ELO),该方法基于心理测量学(Morizot等人,2009;Furr,2021)。通过修改ELO概率函数,我们估计注释者的能力并相应调整其贡献,从而实现更准确和公平的评估结果聚合。
通过在真实世界数据集上的实验,我们证明了我们的框架在确保ELO分数一致性的同时有效建模注释者。此外,在模拟实验中,我们的方法不仅识别异常注释者,还将ELO分数的不一致性降低到传统ELO方法的30%。这表明我们的方法有效地缓解了传统ELO方法固有的不稳定性。
2. 背景及相关工作
基于竞技场的评估是更大领域内LLM评估的重要子领域。与传统的评估范式(Zellers等人,2019;Hendrycks等人,2020;Cobbe等人,2021;Liang等人,2022;Jin等人,2024a)不同,后者通常根据预定义基准评估模型性能,而基于竞技场的评估涉及模型直接与其他模型竞争。当前该领域的研究通常可以分为三个关键类别:战斗场景、注释者和排名系统。
战斗场景 经典的战斗场景由Chatbot Arena(Chiang等人,2024)体现,其中模型对相同问题作出响应,注释者比较其输出。然而,这种方法容易受到注释者固有偏见的影响。为了解决这个问题,一些研究将多个模型协作生成和评估响应纳入其中,从而实现迭代改进(Zhao等人,2024)。这种方法的典型例子包括LLMChain(Bouchiha等人,2024)和ChatEval(Chan等人,2024)。虽然这些策略提供了更高的公平性,但也伴随着权衡,包括更高的计算成本和潜在的不稳定性。
注释者 在基于竞技场的评估中,结果的比较通常涉及人类注释者(Cheng等人,2024)或高度能干的LLMs,如GPT-4(Achiam等人,2023)和Claude(Anthropic)。此外,一些研究人员探索了使用专门的裁判模型进行此任务,如PandaLM(Wang等人,2023)、JudgeLM(Zhu等人,2023)和Auto-J(Li等人,2023),这些模型旨在增强评估过程。
LLM评估的排名系统 排名系统在基于竞技场的LLM评估中起着至关重要的作用(BusaFekete等人,2014;Szörényi等人,2015;Chernoff,1992)。在现有方法中,许多基于竞技场的方法依赖ELO评分系统来建模LLMs的能力(Coulom,2007;Pelánek,2016)。ELO评分系统基于Bradley-Terry模型(Hunter,2004;Rao & Kupper,1967),广泛应用于竞争性游戏(Sismanis,2010;Ebtekar & Liu,2021),用于根据竞争者相对能力预测一个竞争者胜过另一个的可能性。然而,由于其动态特性,该系统专为传统竞争性游戏设计,在LLM评估中引入了不稳定性。为了缓解这种不稳定性,现有方法通常对注释数据集进行多次随机打乱,并为每次迭代计算ELO分数。然后将这些打乱中的分数统计摘要(如均值或方差)用作最终评估指标。尽管这种策略提供了一个实用的解决方案,但它并未从根本上解决ELO方法中序列更新引入的不一致性。
3. 预备知识
基于竞技场的评估是一种备受期待的LLM评估方法,其中模型在基准或数据集上进行一对一比较,结果由评估人员标注。设 S={(i,j,k,Wij)∣i,j∈[N],k∈[M]}S=\left\{\left(i, j, k, W_{i j}\right) \mid i, j \in[N], k \in[M]\right\}S={(i,j,k,Wij)∣i,j∈[N],k∈[M]}
算法1 传统的ELO评分系统
输入:数据集 SSS,缩放因子 KKK,初始分数 Rinit R_{\text {init }}Rinit
初始化:分数集合 RSi←∅R S_{i} \leftarrow \emptysetRSi←∅,模型分数 Ri←Rinit R_{i} \leftarrow R_{\text {init }}Ri←Rinit
计算ELO分数:
对于 (i,j,Wij)∈S\left(i, j, W_{i j}\right) \in S(i,j,Wij)∈S 执行
Ri′←Ri+K⋅(Wij−P(Ri,Rj))R_{i}^{\prime} \leftarrow R_{i}+K \cdot\left(W_{i j}-P\left(R_{i}, R_{j}\right)\right)Ri′←Ri+K⋅(Wij−P(Ri,Rj))
Rj′←Rj+K⋅(Wji−P(Rj,Ri))R_{j}^{\prime} \leftarrow R_{j}+K \cdot\left(W_{j i}-P\left(R_{j}, R_{i}\right)\right)Rj′←Rj+K⋅(Wji−P(Rj,Ri))
结束for
输出:ELO分数 (R1,⋯ ,RN)\left(R_{1}, \cdots, R_{N}\right)(R1,⋯,RN).
表示我们收集的比较数据集,其中 NNN 是模型的数量,MMM 是注释者的数量。每个元素 (i,j,k,Wij)∈S\left(i, j, k, W_{i j}\right) \in S(i,j,k,Wij)∈S 表示模型 iii 和模型 jjj 进行了一场战斗,注释者 kkk 提供了结果 WijW_{i j}Wij。具体来说,Wij=1W_{i j}=1Wij=1 表示模型 iii 赢得了比赛,Wij=0W_{i j}=0Wij=0 表示模型 jjj 赢得比赛,Wij=0.5W_{i j}=0.5Wij=0.5 表示平局。基于竞技场的评估的目标是根据记录 SSS 估计模型的排名分数 R=(R1,…,RN)R=\left(R_{1}, \ldots, R_{N}\right)R=(R1,…,RN)。
ELO评分系统 ELO评分系统是一种广泛使用的方法,基于成对比较对竞争者进行排名。在ELO系统中,每个竞争者(或模型)被分配一个评分 RRR,代表其相对强度。当两个模型 iii 和 jjj 竞争时,它们各自的评分 RiR_{i}Ri 和 RjR_{j}Rj 用于计算每种结果的预期概率:P(Ri,Rj)=P(Wij=1)=P\left(R_{i}, R_{j}\right)=P\left(W_{i j}=1\right)=P(Ri,Rj)=P(Wij=1)= 11+e−C(Ri−Rj)\frac{1}{1+e^{-C\left(R_{i}-R_{j}\right)}}1+e−C(Ri−Rj)1,其中 CCC 是缩放评分差异的常数。在观察到比赛的实际结果后,评分按照以下方式更新:
Ri′=Ri+K⋅(Wij−P(Ri,Rj))Rj′=Rj+K⋅(Wji−P(Rj,Ri)) \begin{aligned} & R_{i}^{\prime}=R_{i}+K \cdot\left(W_{i j}-P\left(R_{i}, R_{j}\right)\right) \\ & R_{j}^{\prime}=R_{j}+K \cdot\left(W_{j i}-P\left(R_{j}, R_{i}\right)\right) \end{aligned} Ri′=Ri+K⋅(Wij−P(Ri,Rj))Rj′=Rj+K⋅(Wji−P(Rj,Ri))
其中 KKK 是控制评分变化幅度的缩放因子。该过程的伪代码如算法1所示。然而,现有的ELO方法是迭代的,对数据顺序高度敏感。这对LLMs的评估是不合理的,因为评估可以被视为一个静态过程(Zhan等人,2024)。具体来说,ELO方法引入的误差源于算法的动态特性而非数据本身,这削弱了许多模型ELO分数的统计意义。
此外,当前算法未考虑注释者能力的差异。它们假设所有注释者具有相同的能力 CCC,随机混合注释记录。这一假设可能会将偏差和不稳定性引入评估过程。
4. 更好的ELO性能估计
早些时候,我们介绍了传统的ELO方法并突出了其关键挑战,包括排名不一致和未考虑注释者变异性。为了解决这些问题,本节提出了一种改进ELO方法的稳定竞技场框架。
4.1. MLE用于ELO估计 (m-ELO)
传统的ELO评分估计方法基于迭代算法,结果高度依赖样本顺序。这就是为什么ELO评分常常缺乏一致性。受最大似然估计(MLE)对样本顺序不敏感的启发,我们提出了一种基于MLE的ELO估计算法,称为m-ELO。具体来说,对于记录数据集 SSS,其对数似然函数可以表示如下:
lnL=∑(i,j,Wij)∈SWijlnP(Ri,Rj)+WjilnP(Rj,Ri)\ln L=\sum_{\left(i, j, W_{i j}\right) \in S} W_{i j} \ln P\left(R_{i}, R_{j}\right)+W_{j i} \ln P\left(R_{j}, R_{i}\right)lnL=∑(i,j,Wij)∈SWijlnP(Ri,Rj)+WjilnP(Rj,Ri),
其中 P(Ri,Rj)=11+e−C(Ri−Rj)P\left(R_{i}, R_{j}\right)=\frac{1}{1+e^{-C\left(R_{i}-R_{j}\right)}}P(Ri,Rj)=1+e−C(Ri−Rj)1。通过使用梯度下降求解对数似然函数的极值点,可以获得MLE方法的结果 (R1∗,R2∗,…,RN∗)\left(R_{1}^{*}, R_{2}^{*}, \ldots, R_{N}^{*}\right)(R1∗,R2∗,…,RN∗)。具体来说,对于任何给定的模型 n∈[N]n \in[N]n∈[N],其评分 RnR_{n}Rn 的对数似然函数的梯度为:
∂lnL∂Rn=∑(n,j,Wnj)∈SC(Wnj−P(Rn,Rj)) \frac{\partial \ln L}{\partial R_{n}}=\sum_{\left(n, j, W_{n j}\right) \in S} C\left(W_{n j}-P\left(R_{n}, R_{j}\right)\right) ∂Rn∂lnL=(n,j,Wnj)∈S∑C(Wnj−P(Rn,Rj))
通过比较公式1和公式3,我们观察到这两个公式的结构是一致的。这突显了ELO算法的本质:它对每个标注样本执行学习率为 KC\frac{K}{C}CK 的梯度下降。基于单个样本的梯度下降很少收敛,这揭示了传统ELO方法的一个关键缺点。
收敛分析 尽管MLE方法的估计结果不受样本顺序的影响,另一个重要考虑因素是对数似然函数是否只有一个极值点。如果存在多个极值点,仍然可能导致ELO排名的不一致性。不幸的是,由于ELO分数是相对的,很明显,如果 (R1∗,R2∗,…,RN∗)\left(R_{1}^{*}, R_{2}^{*}, \ldots, R_{N}^{*}\right)(R1∗,R2∗,…,RN∗) 是一个极值点,那么 (R1∗+ϵ,R2∗+ϵ,⋯ ,RN∗+ϵ)\left(R_{1}^{*}+\epsilon, R_{2}^{*}+\epsilon, \cdots, R_{N}^{*}+\epsilon\right)(R1∗+ϵ,R2∗+ϵ,⋯,RN∗+ϵ) 也是一个极值点。因此,对数似然函数的极值点不是唯一的。然而,当我们固定其中一个模型的分数时,我们可以得到以下定理(Zermelo,1929):
定理4.1. 假设 R0=0R_{0}=0R0=0 且 ∣S∣|S|∣S∣ 足够大,则对数似然函数 lnL\ln LlnL 关于 (R2,⋯ ,RN)\left(R_{2}, \cdots, R_{N}\right)(R2,⋯,RN) 是凹函数并且最多有一个极值点。
从定理4.1可以看出,通过MLE方法获得的ELO分数在模型之间相对稳定,这意味着任何两个模型之间的能力差异保持稳定。
用MLE方法取代迭代方法使ELO方法更加灵活。此外,它允许我们在评估过程中建模注释者能力。在下一节中,我们将采用心理测量学的思想提出一种可行的建模方法并分析其可解释性。
4.2. 注释者建模 m-ELO (am-ELO) 估计
尽管能力建模在LLM评估中并不常见,但在教育和心理测量学中已经开发了许多能力建模方法(Liu等人,2019;Wang等人,2022;Zhang等人,2024b;Zhuang等人,2022;Liu等人,2024)。一个突出的方法是项目反应理论(IRT)(Embretson & Reise,2013;Zhu等人,2022;Nguyen & Zhang,2022;Polo等人,2024)。IRT认为,应试者在测试中的表现仅取决于其能力 θ\thetaθ 和问题的属性。标准模型是两参数逻辑(2PL)模型,定义为:Pj(θ)=P(yj=1)=11+e−aj(θ−xj)P_{j}(\theta)=P\left(y_{j}=1\right)=\frac{1}{1+e^{-a_{j}\left(\theta-x_{j}\right)}}Pj(θ)=P(yj=1)=1+e−aj(θ−xj)1,其中 yj=1y_{j}=1yj=1 表示正确回答问题 jjj,而 aja_{j}aj 和 bj∈Rb_{j} \in \mathbb{R}bj∈R 分别代表问题 jjj 的区分度和难度。
正如所指出的,IRT中的参数 aaa 可以解释为区分参数。类似地,在ELO方法中,固定值 CCC 也可以理解为区分参数。为了考虑注释者变异性,我们用特定于注释者 kkk 的参数 θk\theta_{k}θk 替代概率密度估计中的固定值 CCC :
P(Ri,Rj∣θk)=11+e−θk(Ri−Rj) P\left(R_{i}, R_{j} \mid \theta_{k}\right)=\frac{1}{1+e^{-\theta_{k}\left(R_{i}-R_{j}\right)}} P(Ri,Rj∣θk)=1+e−θk(Ri−Rj)1
这个新公式具有以下性质:
- 保持对称性:即使将常数 CCC 修改为与注释者相关的参数 θk\theta_{k}θk,模型能力 RiR_{i}Ri 和 RjR_{j}Rj 的对称性仍然得以保留,使得 P(Ri,Rj∣θk)+P(Rj,Ri∣θk)=1P\left(R_{i}, R_{j} \mid \theta_{k}\right)+P\left(R_{j}, R_{i} \mid \theta_{k}\right)=1P(Ri,Rj∣θk)+P(Rj,Ri∣θk)=1
-
- 区分能力 (θk>0)\left(\theta_{k}>0\right)(θk>0) :当两个模型的能力相同时,能力值小变化引起的获胜概率变化与注释者能力 θk=4∂P(Ri,r)∂Ri∣Rj=r\theta_{k}=\left.4 \frac{\partial P\left(R_{i}, r\right)}{\partial R_{i}}\right|_{R_{j}=r}θk=4∂Ri∂P(Ri,r) Rj=r 正相关。因此,注释者能力 θk\theta_{k}θk 表示最大区分能力。
-
- 异常注释者 (θk<0)\left(\theta_{k}<0\right)(θk<0) :当区分能力 θk\theta_{k}θk 时,观察到对于任何能力大于模型 jjj 的模型 iii,注释者 kkk 认为模型 iii 获胜的概率小于0.5 。这表明这是一个异常注释者。
为了估计概率函数的参数,我们考虑其对数似然函数,类似地:
- 异常注释者 (θk<0)\left(\theta_{k}<0\right)(θk<0) :当区分能力 θk\theta_{k}θk 时,观察到对于任何能力大于模型 jjj 的模型 iii,注释者 kkk 认为模型 iii 获胜的概率小于0.5 。这表明这是一个异常注释者。
∑(i,j,k,Wij)∈SWijlnP(Ri,Rj∣θk)+WjilnP(Rj,Ri∣θk) \sum_{\left(i, j, k, W_{i j}\right) \in S} W_{i j} \ln P\left(R_{i}, R_{j} \mid \theta_{k}\right)+W_{j i} \ln P\left(R_{j}, R_{i} \mid \theta_{k}\right) (i,j,k,Wij)∈S∑WijlnP(Ri,Rj∣θk)+WjilnP(Rj,Ri∣θk)
修改概率函数后,我们需要在梯度下降过程中同时考虑模型的ELO分数 R=(R1,…,RN)R=\left(R_{1}, \ldots, R_{N}\right)R=(R1,…,RN) 和注释者的能力 Θ=(θ1,…,θM)\Theta=\left(\theta_{1}, \ldots, \theta_{M}\right)Θ=(θ1,…,θM)。对于模型 n∈[N]n \in[N]n∈[N] 和注释者 m∈m \inm∈ [M][M][M],lnL\ln LlnL 对它们的梯度可以表示为:
∂lnL∂Rn=∑(x,j,k,Wnj)∈Sθk(Wnj−P(Rn,Rj∣θk))∂lnL∂θm=∑(i,j,m,Wij)∈S(Ri−Rj)(Wij−P(Ri,Rj∣θm)) \begin{aligned} & \frac{\partial \ln L}{\partial R_{n}}=\sum_{\left(x, j, k, W_{n j}\right) \in S} \theta_{k}\left(W_{n j}-P\left(R_{n}, R_{j} \mid \theta_{k}\right)\right) \\ & \frac{\partial \ln L}{\partial \theta_{m}}=\sum_{\left(i, j, m, W_{i j}\right) \in S}\left(R_{i}-R_{j}\right)\left(W_{i j}-P\left(R_{i}, R_{j} \mid \theta_{m}\right)\right) \end{aligned} ∂Rn∂lnL=(x,j,k,Wnj)∈S∑θk(Wnj−P(Rn,Rj∣θk))∂θm∂lnL=(i,j,m,Wij)∈S∑(Ri−Rj)(Wij−P(Ri,Rj∣θm))
这种方法允许我们在MLE过程中同时估计注释者的能力。除了改进的概率函数引入的区分概念外,我们还应在竞技场背景下探讨这种能力估计的实际意义。通过分析,我们发现估计的注释者能力 θk\theta_{k}θk 具有以下两个性质:
定理4.2. 假设 θ\thetaθ 表示由am-ELO估计的注释者能力,可以得出以下结论:
(1) 如果两位注释者对同一组样本 Wij,Wij′W_{i j}, W_{i j}^{\prime}Wij,Wij′ 标记,其能力分别为 θ1\theta_{1}θ1 和 θ2(θ2>θ1)\theta_{2}\left(\theta_{2}>\theta_{1}\right)θ2(θ2>θ1),则:
∑(i,j,Wij)∈S′(Ri−Rj)Wij<∑(i,j,Wij′)∈S′(Ri−Rj)Wij′ \sum_{\left(i, j, W_{i j}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right) W_{i j}<\sum_{\left(i, j, W_{i j}^{\prime}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right) W_{i j}^{\prime} (i,j,Wij)∈S′∑(Ri−Rj)Wij<(i,j,Wij′)∈S′∑(Ri−Rj)Wij′
(2) 如果 θk<0\theta_{k}<0θk<0,对于注释者 kkk 的每个正样本 (i,j,k,1)(i, j, k, 1)(i,j,k,1),其损失 ∂lni∂Ri<0\frac{\partial \ln i}{\partial R_{i}}<0∂Ri∂lni<0,而对于注释者 kkk 的每个负样本 (i,j,k,0),∂lni∂Ri>0(i, j, k, 0), \frac{\partial \ln i}{\partial R_{i}}>0(i,j,k,0),∂Ri∂lni>0。
从定理4.2可以看出,从MLE得出的注释者能力具有实际意义。具体来说,∑(i,j,Wij)∈S(Ri−Rj)Wij\sum_{\left(i, j, W_{i j}\right) \in S}\left(R_{i}-R_{j}\right) W_{i j}∑(i,j,Wij)∈S(Ri−Rj)Wij 可以解释为注释 WijW_{i j}Wij 与排名 Ri−RjR_{i}-R_{j}Ri−Rj 之间的相关性。定理4.2 (1) 意味着较高的注释者能力对应较大的 ∑(i,j,Wij)∈S′(Ri−Rj)Wij\sum_{\left(i, j, W_{i j}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right) W_{i j}∑(i,j,Wij)∈S′(Ri−Rj)Wij 值,意味着较大的 θk\theta_{k}θk 表示注释者 kkk 的注释与整体排名更一致。同时,定理4.2 (2) 表明具有负能力的注释者可能注释不一致或随意,am-ELO可以识别这些异常注释者。
归一化 尽管这种方法对建模注释者具有很强的可解释性,但不难观察到,对于这样的优化问题,如果 (R1∗,⋯ ,RN∗,θ1∗,⋯ ,θM∗)\left(R_{1}^{*}, \cdots, R_{N}^{*}, \theta_{1}^{*}, \cdots, \theta_{M}^{*}\right)(R1∗,⋯,RN∗,θ1∗,⋯,θM∗) 是一个极值点,那么
算法2 am-ELO评分系统
输入:数据集 SSS,学习率 α\alphaα,轮次 Epoch
初始化:模型分数 RRR 和注释者能力 Θ\ThetaΘ 对于 t=1t=1t=1 到 EpochE p o c hEpoch 执行
计算MLE:lnL←MLE(R,Θ,S)\ln L \leftarrow \operatorname{MLE}(R, \Theta, S)lnL←MLE(R,Θ,S)
优化:R←R+α∂lnL∂R,Θ←Θ+α∂lnL∂ΘR \leftarrow R+\alpha \frac{\partial \ln L}{\partial R}, \Theta \leftarrow \Theta+\alpha \frac{\partial \ln L}{\partial \Theta}R←R+α∂R∂lnL,Θ←Θ+α∂Θ∂lnL
归一化:Θ←ΘV⋅Θ\Theta \leftarrow \frac{\Theta}{V \cdot \Theta}Θ←V⋅ΘΘ
结束for
输出:ELO分数和注释者能力 (R,Θ)(R, \Theta)(R,Θ)。
算法3 稳定竞技场框架
输入:学习率 (α)(\alpha)(α),轮次 Epoch,能力阈值 (ϵ)(\epsilon)(ϵ)。
初始化:数据集 (S←∅)(S \leftarrow \emptyset)(S←∅),数据量阈值 (δ)(\delta)(δ)。
while True do
(S←S∪Snew )(S \leftarrow S \cup S_{\text {new }})(S←S∪Snew )
for (k=1)(k=1)(k=1) 到 (M)(M)(M) do
KaTeX parse error: Expected 'EOF', got '\right' at position 67: …mid x=k\right\}\̲r̲i̲g̲h̲t̲|)
end for
(S′←{(i,j,k,Wij)∣δk>δ})(S^{\prime} \leftarrow\left\{\left(i, j, k, W_{i j}\right) \mid \delta_{k}>\delta\right\})(S′←{(i,j,k,Wij)∣δk>δ})
((R,Θ)←am−ELO(S′,α, Epoch ))((R, \Theta) \leftarrow \operatorname{am}-\operatorname{ELO}\left(S^{\prime}, \alpha, \text { Epoch }\right))((R,Θ)←am−ELO(S′,α, Epoch ))
((R1,⋯ ,RN)=R)(\left(R_{1}, \cdots, R_{N}\right)=R)((R1,⋯,RN)=R)
输出:ELO分数 ((R1,⋯ ,RN))(\left(R_{1}, \cdots, R_{N}\right))((R1,⋯,RN))
((θ1,⋯ ,θN)=Θ)(\left(\theta_{1}, \cdots, \theta_{N}\right)=\Theta)((θ1,⋯,θN)=Θ)
筛选注释者:(S←{(i,j,k,Wij)∣θk>ϵ})(S \leftarrow\left\{\left(i, j, k, W_{i j}\right) \mid \theta_{k}>\epsilon\right\})(S←{(i,j,k,Wij)∣θk>ϵ})
end while
(αR1∗,⋯ ,αRN∗,1αθ1∗,⋯ ,1αθM∗)\left(\alpha R_{1}^{*}, \cdots, \alpha R_{N}^{*}, \frac{1}{\alpha} \theta_{1}^{*}, \cdots, \frac{1}{\alpha} \theta_{M}^{*}\right)(αR1∗,⋯,αRN∗,α1θ1∗,⋯,α1θM∗) 也是一个极值点。因此,当 α<0\alpha<0α<0 时,模型分数排名将完全反转,可能导致潜在的不稳定性。为减轻这一问题,我们对注释者能力施加约束:
θ1+θ2+⋯+θM=1 \theta_{1}+\theta_{2}+\cdots+\theta_{M}=1 θ1+θ2+⋯+θM=1
从定理4.2 (2) 可知,θk>0\theta_{k}>0θk>0 对应正常标注的用户。这种归一化操作的意义本质上基于多数注释者群体负责任标注的假设(Nowak & Rüger, 2010)。基于这一假设,我们确定模型排名是否应遵循原始顺序或反转。
4.3. 稳定竞技场框架
算法2展示了am-ELO算法的伪代码。am-ELO算法在整个数据集上对负对数似然函数进行梯度下降(Ruder, 2016),找到极值点,最终返回模型分数和注释者能力。具体来说,当仅考虑m-ELO算法时,其对数似然函数的凹性使得在优化过程中可以使用牛顿法(Galántai, 2000; Kelley, 2003)。这允许动态调整学习率,从而提高收敛效率。
基于前面讨论的对ELO方法的改进,我们引入了稳定竞技场框架,这是一种新颖的基于竞技场评估的新范式,详见算法3。为了确保更稳健的评估,我们在应用am-ELO方法前后仔细筛选注释数据。具体来说,在纳入新的注释样本后,我们首先过滤掉标注记录少于 δ\deltaδ 的注释者。这是关键,因为标注记录较少的注释者往往产生不太可靠的结果。但这并不意味着永久排除;一旦这些注释者积累了足够的标注记录,其记录将被重新考虑。
在评估模型和注释者后,我们通过基于估计能力筛选注释者进一步完善流程。能力值为负或低于阈值 ϵ\epsilonϵ 的注释者被认为对评估过程有害。对于这些注释者,我们发出警告或完全将其排除在进一步评估之外。此外,由于较高的 θ\thetaθ 表示注释与整体排名的一致性更高,LLM评估平台可以根据其展示的能力按比例奖励注释者。
5. 实验
在本节中,我们介绍并比较了我们提出的方法与传统ELO方法在预测注释结果方面的性能,强调am-ELO的优越建模能力。此外,我们通过比较不同ELO方法产生的模型排名以及案例研究,展示了传统ELO方法的局限性。接下来,我们验证了我们方法生成的ELO排名的收敛性,进一步强化了我们方法在评估LLMs方面的有效性。最后,为了评估ELO方法的稳定性,我们应用四种不同策略扰动注释者。我们的结果显示,我们的方法不仅在测试中保持稳定性,还能有效识别异常注释者,强调了我们方法的优势。
5.1. 数据集
我们在一个真实的注释数据集Chatbot(Zheng等人,2023)上进行实验,该数据集是在2023年4月至6月期间从Chatbot Arena中13,000个不同IP地址收集的。数据集包含33,000个经过策划的对话,具有成对的人类偏好。每个条目包括问题ID、两个模型的名称、完整的对话记录、注释者的投票及其ID。由于本次实验需要MLE,个别样本可能引入不稳定性。因此,我们排除了注释样本少于50个的注释者。过滤后的数据集的统计信息如表1所示。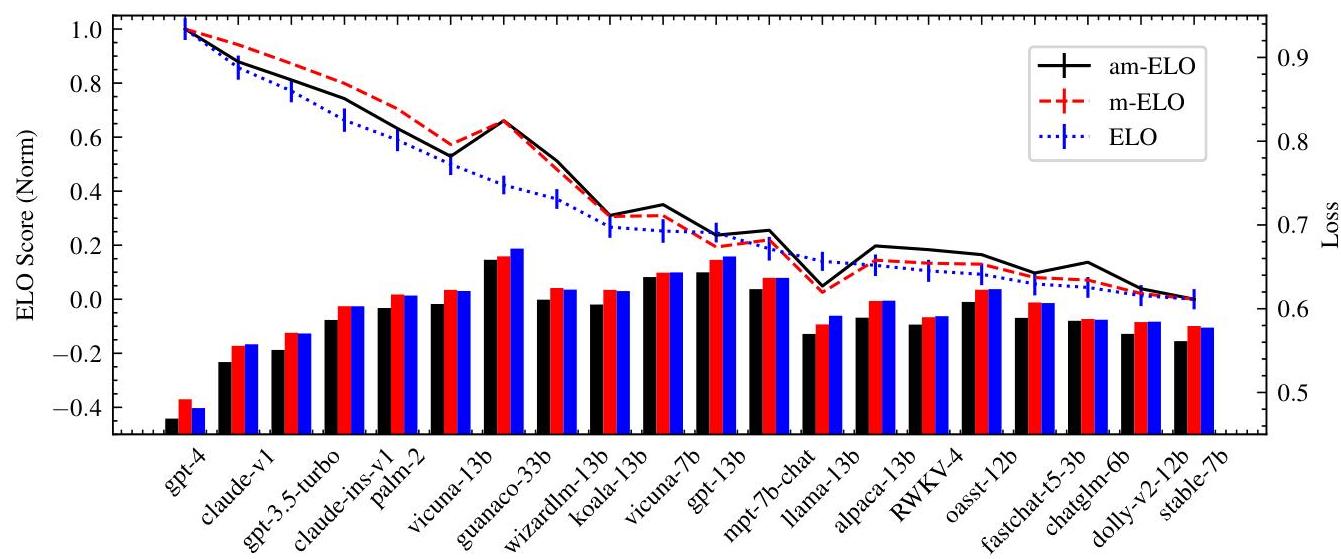
图3. 不同评估方法下各LLMs的结果。具体来说,折线图表示不同评估方法下每个LLM的标准化ELO分数 ↑\uparrow↑(范围从0到1)。柱状图表示不同评估方法下每个LLM的比赛记录的损失 ↓\downarrow↓(对数似然函数)。
表1. 数据集的统计信息
| 数据集 | Chatbot |
|---|---|
| #注释者 | 42 |
| #模型 | 20 |
| #响应日志 | 4321 |
| #每位注释者的响应日志 | 102.88 |
| #每位模型的响应日志 | 216.05 |
| #每对模型的响应日志 | 22.74 |
5.2. 设置
在本实验中,我们考虑了一个基线模型,即传统的ELO方法,以及我们提出的两种方法:m-ELO和am-ELO。对于迭代ELO方法,我们通过对数据集进行1000次打乱并取平均值进行重复实验。MLE通过梯度下降(GD)方法求解,学习率为0.1,固定迭代次数为2000次。
5.3. 结果与案例研究
图3中的柱状图展示了每种方法的平均对数似然损失。如图所示,共享相同概率函数的m-ELO和ELO之间的损失差异很小,而am-ELO的损失明显低于其他两种方法。这表明am-ELO表现出更好的拟合能力。此外,如表2所示,am-ELO在预测任务中显著优于其他两种基线模型,表明am-ELO表现出优越的泛化能力。这也证明了改进的概率函数有效地建模了注释者。
表2. ELO方法预测的性能。
| 方法 | MSE ↓\downarrow↓ | AUC ↑\uparrow↑ |
|---|---|---|
| ELO | 0.1238±0.00310.1238 \pm 0.00310.1238±0.0031 | 0.7492±0.00680.7492 \pm 0.00680.7492±0.0068 |
| m-ELO | 0.1234±0.00290.1234 \pm 0.00290.1234±0.0029 | 0.7503±0.00660.7503 \pm 0.00660.7503±0.0066 |
| am-ELO | 0.1208±0.0034\mathbf{0 . 1 2 0 8} \pm 0.00340.1208±0.0034 | 0.7581±0.0067\mathbf{0 . 7 5 8 1} \pm 0.00670.7581±0.0067 |
| 更好 | 0 | 207 | 148 | 28 | 0 |
|---|---|---|---|---|---|
| koala-13b | 46 | 0 | 10 | 5 | 147 |
| vicuna-7b | 46 | 9 | 0 | 2 | 66 |
| gpt-13b | 11 | 0 | 0 | 0 | 13 |
| 更差 | 0 | 60 | 42 | 11 | 0 |
图4. 热图显示了各种模型之间战斗的胜利次数(三种能力相似的模型koala13b、vicuna-7b、gpt-13b以及比它们更好或更差的模型)。图中的每个数字表示行模型在战斗中击败列模型的次数。
同时,图3中的折线图说明了来自三种ELO方法的ELO分数。显然,我们提出的方法的排名趋势与传统ELO方法紧密一致。然而,某些特定模型的排名存在一些差异,例如koala13b、vicuna-7b和gpt-13b。
为了分析这些能力相似的模型,我们根据其ELO分数将剩余模型分为两组:“更好”和“更差”,分别代表比上述模型更好或更差的模型。我们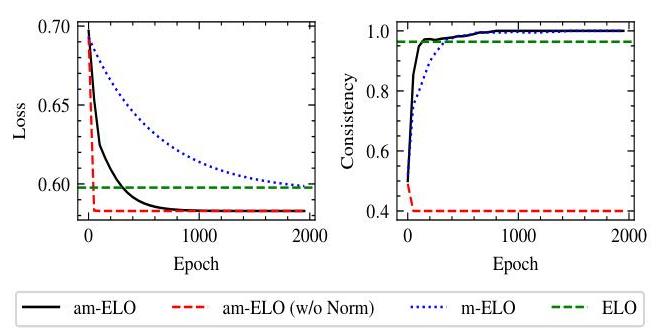
图5. 在Chatbot数据集上每轮训练中评估方法的损失和一致性。
可视化这些模型之间的比赛次数。如图4所示,每个数字表示行模型击败列模型的次数。例如,第一行和第三列表示vicuna-7b输给了“更好”模型148次。由此我们观察到,尽管koala-13b和vicuna-7b之间的正面交锋记录没有区分它们的能力,但两者都击败了相同数量的“更好”模型。同时,vicuna-7b输给更少的“更好”和“更差”模型。基于这一结果,我们得出结论,vicuna-7b比koala-13b更强,这与am-ELO和m-ELO提供的排名一致。
然而,由于Koala-13B战胜“更差”模型的次数较多,传统ELO方法在评分过程中过度重视这些胜利,最终将Koala-13B的排名置于Vicuna-7B之上。这一问题表明,避免强对手并反复击败弱对手可能会人为抬高模型的排名,这是不希望看到的结果。
5.4. ELO方法的收敛性和效率
在本小节中,我们讨论了提出的am-ELO的收敛性和效率。我们的比较方法不仅包括上述三种模型,还包括am-ELO(w/o Norm),即在训练过程中不进行归一化的am-ELO。为了分析每种评估方法获得的结果的收敛性和效率,我们记录了梯度下降过程中的损失(Loss)。此外,我们对模型参数进行了五次随机初始化,并计算了这些模型在每轮训练中输出的ELO分数的一致性(Consistency)(Hastie & Tibshirani,1997)。需要注意的是,传统ELO方法的迭代过程不同于MLE的梯度下降方法。因此,我们直接记录传统ELO方法的最终输出损失和一致性。结果如图5所示。
从损失来看,三种基于MLE的方法都在有限次数的迭代内收敛到局部最小值。m-ELO的收敛损失几乎
与传统ELO相同,这是意料之中的,因为这两种方法共享相同的概率估计函数。这再次证明了m-ELO和传统ELO本质上是等价的。此外,am-ELO(w/o Norm)收敛最快,其次是am-ELO,m-ELO最慢。这是因为am-ELO比m-ELO有更多的可调参数,而am-ELO(w/o Norm)在梯度下降过程中受益于更少的约束。然而,从一致性来看,am-ELO(w/o Norm)快速收敛到不同的局部最小值,其一致性稳定在0.4 。这表明该方法的五次输出表现出两个有序序列和三个反向序列 (C22+C22C22=\left(\frac{C_{2}^{2}+C_{2}^{2}}{C_{2}^{2}}=\right.(C22C22+C22= 0.4)。另一方面,am-ELO在充分的梯度下降迭代后不仅实现了稳定的排名,而且比m-ELO更高效。这表明我们提出的am-ELO方法在收敛和效率之间达到了平衡。
5.5. 各种ELO方法的稳定性
由于在评估过程中直接验证am-ELO方法的稳定性具有挑战性,我们使用模拟实验对注释者引入扰动。具体来说,我们使用四种策略扰动注释者的结果,以模拟测试中可能出现的异常注释者:
- 随机:如果模型A获胜,结果有 50%50 \%50% 的机会变为“平局”,有 50%50 \%50% 的机会变为“模型B获胜”,反之亦然。
-
- 平局:所有结果变为“平局”。
-
- 反转:如果模型A获胜,结果将反转为“模型B获胜”,反之亦然。“平局”结果保持不变。
-
- 混合:为每个实例从前三种扰动策略中随机选择。
这些扰动模拟了注释中标记故意错误的情况。考虑到竞技场中的大多数注释者将正常标注,我们模拟实验中的扰动数量不会超过总注释者数量的一半。我们期望一种稳定的评分方法具有两个关键属性:(1) 它应该产生与无扰动情况下一致的ELO排名,(2)它应该识别异常的注释者。ELO分数一致性的基准是ELO排名有和无扰动情况下的成对比较,而识别异常注释者的基准是从am-ELO获得的注释者能力的F1分数(Chen & Lin, 2006)。较高的F1分数表示检测扰动的准确性更高。
- 混合:为每个实例从前三种扰动策略中随机选择。
图6中的折线图显示了扰动比例与ELO分数一致性之间的关系。我们观察到,am-ELO在各种类型的扰动下保持更高的一致性。具体来说,除了“平局”扰动本身不太可能影响排名,导致所有ELO方法的一致性较高外,在其他三种扰动场景中,am-ELO将不一致性率降低到m-ELO或传统ELO的30%。同时,图6底部的散点图显示了每种扰动下注释者能力的变化。红点代表正常的注释者,而绿点代表异常的注释者。显然,几乎所有异常注释者的能力得分都在0以下,表明它们被识别为噪声点。此外,图7展示了在不同阈值(0和0.005)下检测扰动的F1分数。在不同的扰动下,当ϵ=0\epsilon=0ϵ=0时,识别准确率达到90%,甚至当ϵ=0.005\epsilon=0.005ϵ=0.005时高达95%。这些结果表明我们的方法有效检测扰动、建模注释者并保持结果的一致性,从而缓解了ELO不一致的问题。
6. 结论
在本研究中,我们探讨了ELO方法在LLM评估中的不稳定性,强调其对评估结果可靠性的影响。为了解决这一问题,我们引入了稳定竞技场框架,该框架利用MLE方法进行ELO评分估计,并将注释者能力参数纳入概率函数。我们的实验表明,am-ELO不仅实现了更稳定的收敛,还有效识别了异常注释者,从而使排名更符合人类直觉。这些发现表明,我们的方法可以显著减少ELO的不稳定性,增强LLM评估的可信度和稳健性,同时提供了一个更稳定且易于实施的竞技场评估框架。
然而,我们的方法存在某些局限性。具体来说,注释者建模的维度较为简单,主要捕捉注释者的辨别能力和与其他注释者的一致性。这使得难以全面捕捉注释者的广泛能力。在未来的工作中,我们旨在完善注释者能力维度的设计,以更好地利用众包进行竞技场评估。
致谢
本研究得到了国家重点研发计划(资助号:2024YFC3308200)、国家自然科学基金(62337001)、安徽省重点技术研发计划(编号:202423k09020039)、中国博士后科学基金(资助号:2024M760725)和中央高校基本科研业务费的支持。
影响声明
本文的目标是推动机器学习领域的发展。我们的工作有许多潜在的社会影响,但我们认为无需在此特别强调任何一项。
参考文献
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 技术报告。arXiv预印本 arXiv:2303.08774, 2023.
Aldous, D. Elo评分和体育模型:应用概率的一个被忽视的话题?2017.
Anthropic, S. 模型卡片补充:Claude 3.5 Haiku 和升级版Claude 3.5 Sonnet。URL https: //api.semanticscholar.org/CorpusID: 273639283.
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. 使用来自人类反馈的强化学习训练有益且无害的助手。arXiv预印本 arXiv:2204.05862, 2022.
Boubdir, M., Kim, E., Ermis, B., Hooker, S., and Fadaee, M. Elo揭秘:语言模型评估中的稳健性和最佳实践。arXiv预印本 arXiv:2311.17295, 2023.
Bouchiha, M. A., Telnoff, Q., Bakkali, S., Champagnat, R., Rabah, M., Coustaty, M., and Ghamri-Doudane, Y. LLMChain:用于共享和评估大语言模型的区块链声誉系统。在2024年IEEE第48届年度计算机、软件和应用会议(COMPSAC),pp. 439-448, 2024. doi: 10.1109/COMPSAC61105.2024.00067.
Boyd, S. 和 Vandenberghe, L. 凸优化。剑桥大学出版社,2004.
Busa-Fekete, R., Hüllermeier, E., and Szörényi, B. 基于统计模型的偏好排序引出:Mallows案例。在国际机器学习会议,pp. 1071-1079. PMLR, 2014.
Chan, C., Chen, W., Su, Y., Yu, J., Xue, W., Zhang, S., Fu, J., and Liu, Z. ChatEval:通过多智能体辩论实现更好的基于LLM的评估者。在第十二届国际学习表征会议,ICLR 2024,奥地利维也纳,2024年5月7日至11日。OpenReview.net, 2024. URL https: / openreview. net/ forum?id=FQepisCUWu.
Chen, Y.-W. 和 Lin, C.-J. 组合支持向量机与各种特征选择策略。特征提取:基础与应用,pp. 315-324, 2006.
Cheng, M., Zhang, H., Yang, J., Liu, Q., Li, L., Huang, X., Song, L., Li, Z., Huang, Z., 和 Chen, E. 使用匿名众包平台进行大规模语言模型的个性化评估。在2024年ACM Web Conference伴随论文集,pp. 10351038, 2024.
Cheng, M., Luo, Y., Ouyang, J., Liu, Q., Liu, H., Li, L., Yu, S., Zhang, B., Cao, J., Ma, J., et al. 知识导向检索增强生成综述。arXiv预印本 arXiv:2503.10677, 2025.
Chernoff, H. 序贯试验设计。Springer, 1992.
Chiang, W., Zheng, L., Sheng, Y., Angelopoulos, A. N., Li, T., Li, D., Zhu, B., Zhang, H., Jordan, M. I., Gonzalez, J. E., 和 Stoica, I. Chatbot Arena:通过人类偏好评估LLMs的开放平台。在第四十一届国际机器学习会议,ICML 2024,奥地利维也纳,2024年7月21日至27日。OpenReview.net, 2024. URL https://openreview.net/forum?id=3MW8GKNyzI.
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. 训练验证器解决数学文字问题。arXiv预印本 arXiv:2110.14168, 2021.
Coulom, R. 计算围棋中的“Elo评分”。ICGA期刊,30(4):198-208, 2007.
Ebtekar, A. 和 Liu, P. 一种适用于大规模多人竞赛的Elo类系统。arXiv预印本 arXiv:2101.00400, 2021.
Eickhoff, C. 众包中的认知偏差。在第十一届ACM国际网络搜索和数据挖掘会议论文集,pp. 162-170, 2018.
Elo, A. E. 提议的USCF评分系统及其发展、理论和应用。Chess Life, 22(8):242-247, 1967.
Embretson, S. E. 和 Reise, S. P. 项目反应理论。Psychology Press, 2013.
Furr, R. M. 心理测量学:导论。SAGE publications, 2021.
Galántai, A. 牛顿法理论。Journal of Computational and Applied Mathematics, 124(1-2):2544, 2000.
Hastie, T. 和 Tibshirani, R. 通过成对耦合分类。Advances in neural information processing systems, 10, 1997.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., 和 Steinhardt, J. 测量大规模多任务语言理解。arXiv预印本 arXiv:2009.03300, 2020.
Hunter, D. R. MM算法广义Bradley-Terry模型。The annals of statistics, 32(1):384-406, 2004.
Jin, Y., Choi, M., Verma, G., Wang, J., 和 Kumar, S. MMSOC:在社交媒体平台上评估多模态大型语言模型。在 ACL,2024aA C L, 2024 aACL,2024a.
Jin, Y., Zhao, Q., Wang, Y., Chen, H., Zhu, K., Xiao, Y., 和 Wang, J. AgentReview:使用LLM代理探索同行评审动态。在EMNLP, 2024b.
Johnson, C. R. 正定矩阵。The American Mathematical Monthly, 77(3):259-264, 1970.
Kelley, C. T. 使用牛顿法求解非线性方程。SIAM, 2003.
Li, C., Shi, L., Zhou, C., Huan, Z., Tang, C., Zhang, X., Wang, X., Zhou, J., 和 Liu, S. 基于归并排序的大规模语言模型评估排名系统。在Bifet, A., Krilavičius, T., Miliou, I., 和 Nowaczyk, S. (eds.), Machine Learning and Knowledge Discovery in Databases. Applied Data Science Track, pp. 240-255, Cham, 2024. Springer Nature Switzerland. ISBN 978-3-031-70378-2.
Li, J., Sun, S., Yuan, W., Fan, R.-Z., Zhao, H., 和 Liu, P. 生成评估对齐的裁判。arXiv预印本 arXiv:2310.05470, 2023.
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., et al. 大规模语言模型的整体评估。arXiv预印本 arXiv:2211.09110, 2022.
Liu, Q., Huang, Z., Yin, Y., Chen, E., Xiong, H., Su, Y., 和 Hu, G. EKT:针对学生表现预测的练习感知知识追踪。IEEE Transactions on Knowledge and Data Engineering, 33(1):100-115, 2019.
Liu, Z., Yan, Z., Liu, Q., Li, J., Zhang, Y., Huang, Z., Wu, J., 和 Wang, S. 计算机自适应测试通过协作排名。在Neural Information Processing Systems, 2024. URL https://api.semanticscholar. org/CorpusID:276259892.
Morizot, J., Ainsworth, A. T., 和 Reise, S. P. 向现代心理测量学迈进。Handbook of research methods in personality psychology, 407, 2009.
Nguyen, D. 和 Zhang, A. Y. 项目反应理论的谱系方法。在Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., 和 Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 38818-38830. Curran Associates, Inc., 2022.
Nowak, S. 和 Rüger, S. 众包标注的可靠性:关于多标签图像标注的注释者间一致性的研究。在Proceedings of the international conference on Multimedia information retrieval, pp. 557-566, 2010.
Ouyang, J., Pan, T., Cheng, M., Yan, R., Luo, Y., Lin, J., 和 Liu, Q. Hoh:一个动态基准评估过时信息对检索增强生成的影响,2025. URL https://arxiv.org/abs/ 2503.04800 .
O’Meara, O. T. Introduction to quadratic forms, volume 117. Springer, 2013.
Pelánek, R. 自适应教育系统中Elo评分系统的应用。Computers & Education, 98:169179, 2016.
Polo, F. M., Weber, L., Choshen, L., Sun, Y., Xu, G., 和 Yurochkin, M. tinybenchmarks:用更少的例子评估LLMs。在第四十一届国际机器学习会议,ICML 2024,奥地利维也纳,2024年7月21日至27日。OpenReview.net, 2024. URL https:// openreview.net/forum?id=qAm13FpfhG.
Rao, P. 和 Kupper, L. L. 配对比较实验中的平局:Bradley-Terry模型的推广。Journal of the American Statistical Association, 62(317): 194-204, 1967.
Raykar, V. C. 和 Yu, S. 众包标注任务中的注释者排名。Advances in neural information processing systems, 24, 2011.
Ruder, S. 梯度下降优化算法概述。ArXiv, abs/1609.04747, 2016. URL https://api.semanticscholar.org/ CorpusID:17485266.
Shi-gu, J. 拉格朗日中值定理的应用。2014. URL https://api.semanticscholar. org/CorpusID:124971556.
Sismanis, Y. 我如何赢得“国际象棋评分——Elo vs世界其他地区”比赛。arXiv预印本 arXiv:1012.4571, 2010.
Szörényi, B., Busa-Fekete, R., Paul, A., 和 Hüllermeier, E. Plackett-Luce在线排名引出:配对博弈方法。Advances in neural information processing systems, 28, 2015.
Thacker, W. C. 在模型拟合测量中的海森矩阵的作用。Journal of Geophysical Research: Oceans, 94(C5):6177-6196, 1989.
Wang, F., Liu, Q., Chen, E., Huang, Z., Yin, Y., Wang, S., 和 Su,Y\mathrm{Su}, \mathrm{Y}Su,Y. NeuralCD:认知诊断的一般框架。IEEE Transactions on Knowledge and Data Engineering, 2022.
Wang, Y., Yu, Z., Zeng, Z., Yang, L., Wang, C., Chen, H., Jiang, C., Xie, R., Wang, J., Xie, X., et al. PandALM:用于LLM指令调优优化的自动评估基准。arXiv预印本 arXiv:2306.05087, 2023.
Welinder, P. 和 Perona, P. 在线众包:评级注释者并获取成本效益标签。在2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, pp. 25-32. IEEE, 2010.
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., 和 Choi, Y. Hellaswag:机器真的能完成你的句子吗?arXiv预印本 arXiv:1905.07830, 2019.
Zermelo, E. 将锦标赛结果计算作为概率计算的最大化问题。Mathematische Zeitschrift, 29(1):436-460, 1929.
Zhan, J., Wang, L., Gao, W., Li, H., Wang, C., Huang, Y., Li, Y., Yang, Z., Kang, G., Luo, C., et al. Evaluatology:评估的科学与工程。BenchCouncil Transactions on Benchmarks, Standards and Evaluations, 4(1):100162, 2024.
Zhang, Y., Zhang, M., Yuan, H., Liu, S., Shi, Y., Gui, T., Zhang, Q., 和 Huang, X. LLMEval:如何评估大规模语言模型的初步研究。在AAAI人工智能会议论文集,volume 38, pp. 19615-19622, 2024a.
Zhang, Z., Wu, L., Liu, Q., Liu, J.-Y., Huang, Z., Yin, Y., Yan, Z., Gao, W., 和 Chen, E. 理解和改进认知诊断中的公平性。Sci. China Inf. Sci., 67, 2024b. URL https: //api.semanticscholar.org/CorpusID: 269473652.
Zhao, Q., Wang, J., Zhang, Y., Jin, Y., Zhu, K., Chen, H., 和 Xie, X. CompeteAI:理解基于大规模语言模型的代理的竞争行为。在ICML, 2024.
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., 和 Stoica, I. 判断作为评委的LLM与MT-Bench和Chatbot Arena,2023.
Zhu, L., Wang, X., 和 Wang, X. Judgelm:微调的大规模语言模型是可扩展的评委。arXiv预印本 arXiv:2310.17631, 2023.
Zhu, Z., Arthur, D., 和 Chang, H.-H. 教育CDM中基于机器学习的新人员适配方法。British Journal of Mathematical and Statistical Psychology, 75(3):616-637, 2022.
Zhuang, Y., Liu, Q., Huang, Z., Li, Z., Shen, S., 和 Ma, H. 完全自适应框架:在线教育的神经计算机自适应测试。在AAAI人工智能会议论文集,volume 36, pp. 47344742, 2022.
A. 定理4.1的证明
证明. 假设 R1=0R_{1}=0R1=0 并考虑剩余变量 (R2,⋯ ,RN)\left(R_{2}, \cdots, R_{N}\right)(R2,⋯,RN)。对于每个样本 (i,j,Wij)\left(i, j, W_{i j}\right)(i,j,Wij),考虑该样本的对数似然函数 lnl\ln llnl 如下:
lnl=WijlnP(Ri,Rj)+WjilnP(Rj,Ri) \ln l=W_{i j} \ln P\left(R_{i}, R_{j}\right)+W_{j i} \ln P\left(R_{j}, R_{i}\right) lnl=WijlnP(Ri,Rj)+WjilnP(Rj,Ri)
lnl\ln llnl 的二阶偏导数为:
∂2lnl∂Ri2=−C2P(Ri,Rj)(1−P(Ri,Rj)),i≠1∂2lnl∂Ri∂Rj=C2P(Ri,Rj)(1−P(Ri,Rj)),i,j≠1 \begin{aligned} & \frac{\partial^{2} \ln l}{\partial R_{i}^{2}}=-C^{2} P\left(R_{i}, R_{j}\right)\left(1-P\left(R_{i}, R_{j}\right)\right), i \neq 1 \\ & \frac{\partial^{2} \ln l}{\partial R_{i} \partial R_{j}}=C^{2} P\left(R_{i}, R_{j}\right)\left(1-P\left(R_{i}, R_{j}\right)\right), i, j \neq 1 \end{aligned} ∂Ri2∂2lnl=−C2P(Ri,Rj)(1−P(Ri,Rj)),i=1∂Ri∂Rj∂2lnl=C2P(Ri,Rj)(1−P(Ri,Rj)),i,j=1
现在,设模型 iii 和模型 jjj 之间的比赛次数为 δij\delta_{i j}δij,定义 aij=δijC2P(Ri,Rj)(1−P(Ri,Rj))a_{i j}=\delta_{i j} C^{2} P\left(R_{i}, R_{j}\right)\left(1-P\left(R_{i}, R_{j}\right)\right)aij=δijC2P(Ri,Rj)(1−P(Ri,Rj))。对于对数似然函数 ∂2lnL∂R∂RT\frac{\partial^{2} \ln L}{\partial \mathbf{R} \partial \mathbf{R}^{T}}∂R∂RT∂2lnL 的黑塞矩阵(Thacker, 1989),其二次形式(O’Meara, 2013)可以表示为:
x∂2lnL∂R∂RTxT=−∑i=2N∑j=2Naij(xi−xj)2−∑i=2Nai1xi2−∑j=2Na1jxj2 \mathbf{x} \frac{\partial^{2} \ln L}{\partial \mathbf{R} \partial \mathbf{R}^{T}} \mathbf{x}^{T}=-\sum_{i=2}^{N} \sum_{j=2}^{N} a_{i j}\left(x_{i}-x_{j}\right)^{2}-\sum_{i=2}^{N} a_{i 1} x_{i}^{2}-\sum_{j=2}^{N} a_{1 j} x_{j}^{2} x∂R∂RT∂2lnLxT=−i=2∑Nj=2∑Naij(xi−xj)2−i=2∑Nai1xi2−j=2∑Na1jxj2
注意 aij≥0a_{i j} \geq 0aij≥0,因此:
x∂2lnL∂R∂RTxT≤0 \mathbf{x} \frac{\partial^{2} \ln L}{\partial \mathbf{R} \partial \mathbf{R}^{T}} \mathbf{x}^{T} \leq 0 x∂R∂RT∂2lnLxT≤0
等式成立当且仅当 xi=xj=0x_{i}=x_{j}=0xi=xj=0,即 x=0\mathbf{x}=\mathbf{0}x=0。由于对于所有非零向量 x\mathbf{x}x,二次形式严格为负,黑塞矩阵 ∂2lnL∂R∂RT\frac{\partial^{2} \ln L}{\partial \mathbf{R} \partial \mathbf{R}^{T}}∂R∂RT∂2lnL 是负定的(Johnson, 1970)。这意味着对数似然函数 lnL\ln LlnL 是凹的。因此,lnL\ln LlnL 最多有一个极值点(Boyd & Vandenberghe, 2004),确保了最大似然解的唯一性。
B. 定理4.2的证明
证明. (1) 对于注释者1和2,可以从公式6得到以下公式:
∂lnL∂θ1=∑(i,j,Wij)∈S′(Ri−Rj)(Wij−P(Ri,Rj∣θ1))∂lnL∂θ2=∑(i,j,Wij′)∈S′(Ri−Rj)(Wij′−P(Ri,Rj∣θ2)) \begin{aligned} \frac{\partial \ln L}{\partial \theta_{1}} & =\sum_{\left(i, j, W_{i j}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right)\left(W_{i j}-P\left(R_{i}, R_{j} \mid \theta_{1}\right)\right) \\ \frac{\partial \ln L}{\partial \theta_{2}} & =\sum_{\left(i, j, W_{i j}^{\prime}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right)\left(W_{i j}^{\prime}-P\left(R_{i}, R_{j} \mid \theta_{2}\right)\right) \end{aligned} ∂θ1∂lnL∂θ2∂lnL=(i,j,Wij)∈S′∑(Ri−Rj)(Wij−P(Ri,Rj∣θ1))=(i,j,Wij′)∈S′∑(Ri−Rj)(Wij′−P(Ri,Rj∣θ2))
由于 ∂lnL∂θ1=∂lnL∂θ2=0\frac{\partial \ln L}{\partial \theta_{1}}=\frac{\partial \ln L}{\partial \theta_{2}}=0∂θ1∂lnL=∂θ2∂lnL=0,可以得到两式之差:
∑(i,j,Wij)∈S′(Ri−Rj)(Wij−Wij′)=∑(i,j,Wij′)∈S′(Ri−Rj)(P(Ri,Rj∣θ1)−P(Ri,Rj∣θ2)) \sum_{\left(i, j, W_{i j}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right)\left(W_{i j}-W_{i j}^{\prime}\right)=\sum_{\left(i, j, W_{i j}^{\prime}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right)\left(P\left(R_{i}, R_{j} \mid \theta_{1}\right)-P\left(R_{i}, R_{j} \mid \theta_{2}\right)\right) (i,j,Wij)∈S′∑(Ri−Rj)(Wij−Wij′)=(i,j,Wij′)∈S′∑(Ri−Rj)(P(Ri,Rj∣θ1)−P(Ri,Rj∣θ2))
根据拉格朗日中值定理(Shi-gu, 2014),可以得出以下推导:
=∑(i,j,Wij′)∈S′(Ri−Rj)2Pij(ξij)(1−Pij(ξij))(θ1−θ2) =\sum_{\left(i, j, W_{i j}^{\prime}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right)^{2} P_{i j}\left(\xi_{i j}\right)\left(1-P_{i j}\left(\xi_{i j}\right)\right)\left(\theta_{1}-\theta_{2}\right) =(i,j,Wij′)∈S′∑(Ri−Rj)2Pij(ξij)(1−Pij(ξij))(θ1−θ2)
由于 Pij(ξij)(1−Pij(ξij))>0P_{i j}\left(\xi_{i j}\right)\left(1-P_{i j}\left(\xi_{i j}\right)\right)>0Pij(ξij)(1−Pij(ξij))>0 且 θ1<θ2\theta_{1}<\theta_{2}θ1<θ2 :
∑(i,j,Wij)∈S′(Ri−Rj)(Wij−Wij′)<0 \sum_{\left(i, j, W_{i j}\right) \in S^{\prime}}\left(R_{i}-R_{j}\right)\left(W_{i j}-W_{i j}^{\prime}\right)<0 (i,j,Wij)∈S′∑(Ri−Rj)(Wij−Wij′)<0
(2) 因为 0<P(Ri,Rj∣θk)<10<P\left(R_{i}, R_{j} \mid \theta_{k}\right)<10<P(Ri,Rj∣θk)<1 且 θk<0\theta_{k}<0θk<0,对于注释者 kkk 的每个正样本 (i,j,k,1)(i, j, k, 1)(i,j,k,1),我们有 ∂lnl∂Ri=θk(1−P(Ri,Rj∣θk))<0\frac{\partial \ln l}{\partial R_{i}}=\theta_{k}\left(1-P\left(R_{i}, R_{j} \mid \theta_{k}\right)\right)<0∂Ri∂lnl=θk(1−P(Ri,Rj∣θk))<0。同样地,对于注释者 kkk 的每个负样本 (i,j,k,0)(i, j, k, 0)(i,j,k,0),我们有 ∂lnl∂Ri=θk(0−P(Ri,Rj∣θk))>0\frac{\partial \ln l}{\partial R_{i}}=\theta_{k}\left(0-P\left(R_{i}, R_{j} \mid \theta_{k}\right)\right)>0∂Ri∂lnl=θk(0−P(Ri,Rj∣θk))>0。
参考论文:https://arxiv.org/pdf/2505.03475

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)