BLIP2:使用冻结图像编码器和大型语言模型进行语言图像预训练的引导方法
传统都是使用单模态的对齐,而我们就不一样了,同时利用冻结的图像编码器和冻结的语言编码器,同时引用Q-Former,将视觉特征映射到LLM可理解的文本空间,解决跨模态对齐的方法。BLIP2提出了一种高效的通用的提升VLP的方法,通过利用冻结的单模态模型(预训练视觉模型+预训练语言模型)减少计算成本,通过Querying Transformer解决模态对齐问题。VLP(视觉语言预训练),单模态模型在视
主要问题:
近年来视觉余元预训练模型变得越来越昂贵,主要是因为,训练模型的规模越来越大。需要端到端的训练,计算成本有点高,对于我们这种本科生很不友好,相信大多数课题组的经费都不支持研究吧。所以论文提出了BLIP2,降低训练成本,同时能保持性能。
模型采用两阶段的训练策略,先从冻结的编码器中学习视觉语言表征。再从冻结的大语言模型中学习视觉到语言的生成能力。通过冻结部分参数的模型,来减少训练的成本。
端到端(模型从输入到输出整个过程都是完全自动化,不需要人工额外干预中间步骤)。
创新与优势:
VLP(视觉语言预训练),单模态模型在视觉和语言领域都有广泛应用(大语言模型LLMs),能否利用这些现有的预训练模型提高VLP。
模态对齐的难题:冻结LLM后,如何使其理解视觉信息?
BLIP2提出了一种高效的通用的提升VLP的方法,通过利用冻结的单模态模型(预训练视觉模型+预训练语言模型)减少计算成本,通过Querying Transformer解决模态对齐问题。
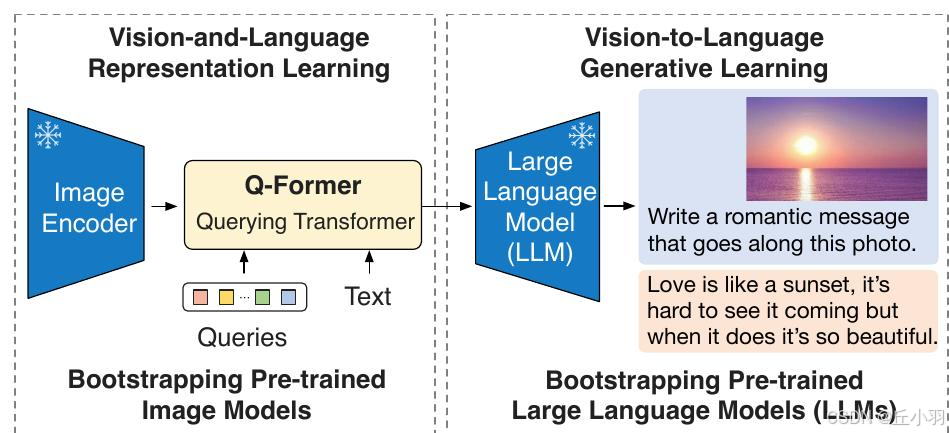
第一阶段是视觉语言表征学习,使用Q-Former学习视觉表征,并使其与文本高度相关,将图像特征转化为LLM能理解的模式,并作为输入传输给LLM。主要目的是根据输入的视觉特征生成自然语言文本。
相关工作:
目前主流的视觉语言预训练(VLP):旨在学习多模态基础模型,提升在视觉语言任务中的表现。大多数VLP方法采用端到端预训练,需要大规模的图文数据集。难以灵活的利用现成的单模态模型。
模块化的VLP利用已有的预训练模型,在训练过程中保持她们冻结。虽然使用冻结模型,但是仍然面对着跨模态对齐的挑战。传统都是使用单模态的对齐,而我们就不一样了,同时利用冻结的图像编码器和冻结的语言编码器,同时引用Q-Former,将视觉特征映射到LLM可理解的文本空间,解决跨模态对齐的方法。
方法:
主要是Q-Former,主要用于弥合冻结图像编码器和冻结LLM之间的模态差距。
核心组件是两部分的Transformer子模块:
图像Transformer:负责与冻结的图像编码器相互交互,以提取视觉特征。
文本Transformer:既可以作为文本编码器又可以作为文本解码器。
可学习查询向量:
作为图像Transformer的输入,利用自注意力机制进行信息交互,通过交叉注意力连接冻结的图像编码器。
查询向量可以与文本交互,通过不同的自注意力掩码控制交互方式。
Q-Former仅从图像编码器中提取固定数量的特征,与输入图像分辨率无关。
训练细节,采用瓶颈结构,强迫查询向量仅仅提取最关键的视觉信息,从而提高对文本的相似性。
自注意力机制:神经网络的一种计算方式,允许输入序列的每个元素关注序列中的其他元素。
torch.matmul表示相乘
def self_attention(x,wq,xk,wv):
Q=torch.matmul(x,wq)#计算查询矩阵Q
K=torch.matmul(x,wk)#计算键矩阵K
V=torch.matmul(x,wv)#计算值矩阵V
dk=K.shape[-1]
attention_scores=torch.matmul(Q,K.T)/torch.sqrt(torch.tensor(d_k))#计算QK*T/sqrt(d_k)
attention_weights=F.softmax(attention_scores,dim=-1)#计算注意力分数并进行归一化
output=torch.matmul(attention_weights,V)#计算最终的输出
return output交叉注意力:CA用于处理两个不同模态之间的信息交互,例如视觉语言(将图像特征传递给语言特征)和文本文本。计算的是目标序列的查询与原序列的键和值进行计算。
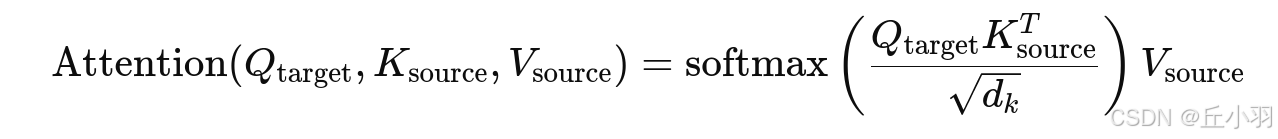
自注意力掩码:限制Transformer在计算注意力时访问特定信息的方法。在自注意力机制计算的时候,人为的控制某些元素进行交互。用来屏蔽无关信息。
在BLIP2视觉语言模型中,我们是从图像特征--Q-Former--语言模型。
我们希望前几层只让图像特征自注意力,不与文本交互。后几层让图像特征和文本特征交互。
scores=scores.masked_fill(mask==0,float('-inf'))瓶颈结构旨在减少特征表示的维度,让模型提取更重要的信息,从而提高计算效率。
class Bottleneck(nn.Module):
def __inti__(self,input_dim,bottleneck_dim):
super().__init__()
self.fc1=nn.Linear(input_dim,bottleneck_dim)#降维
self.fc2=nn.Linear(bottleneck_dim,input_dim)#还原
self.relu=nn.ReLU()
def forward(self,x):
bottleneck=self.fc1(x)
bottleneck=self.relu(bottleneck)
output=self.fc2(bottleneck)
return output| 概念 | 定义 | 作用 | BLIP-2 应用 |
|---|---|---|---|
| 自注意力(Self-Attention) | 计算序列中每个元素对其他元素的重要性 | 提取全局依赖关系 | Q-Former 让查询向量自交互 |
| 交叉注意力(Cross-Attention) | 计算两个不同序列之间的注意力 | 让视觉特征适配语言模型 | Q-Former 连接图像编码器和 LLM |
| 自注意力掩码(Self-Attention Masking) | 限制自注意力访问信息 | 控制查询向量和文本交互 | Q-Former 预训练使用不同掩码策略 |
| 瓶颈结构(Bottleneck Architecture) | 降低特征维度,提取关键信息 | 提高计算效率,避免冗余 | Q-Former 仅提取 32 × 768 维度视觉信息 |
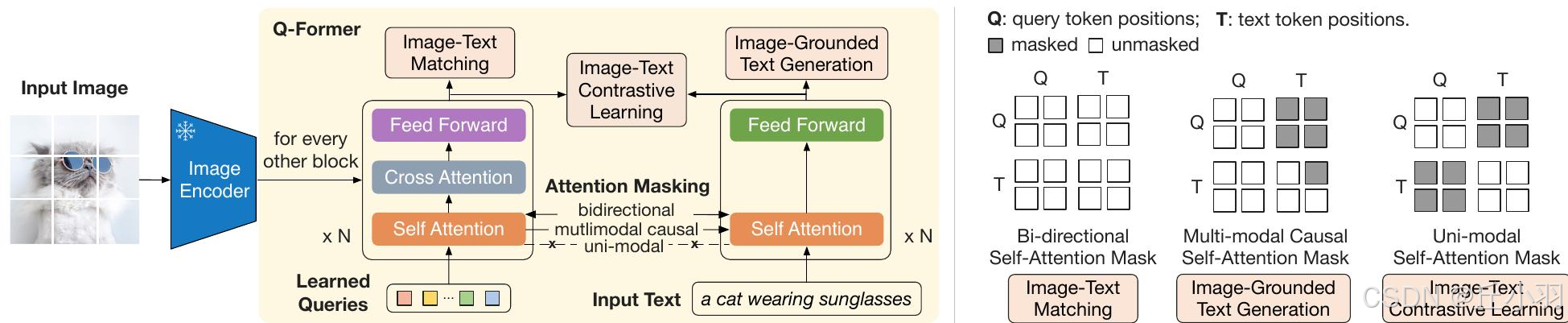
自注意力掩码的使用方法:
双向自注意力用于图文匹配(判断图文是否匹配,是0/1分类的问题),全白表示完全可见。
多模态因果掩码用于基于图像的文本生成,查询可以看到完整的图像,但是文本只能看到之前的部分。单模态掩码用于图文对比学习,各自只关注自己。
BLIP-2 第一阶段的核心是 Q-Former 在冻结图像编码器的基础上进行视觉-语言学习,同时优化 ITC, ITG, ITM 三个任务:
| 任务 | 目标 | 方法 | 注意力掩码 |
|---|---|---|---|
| ITC (图文对比学习) | 让匹配的图文对靠近,不匹配的远离 | 计算 图像查询向量 Z & 文本 [CLS] 之间的相似度,优化对比损失 | 单模态掩码(Queries & Text 互不可见) |
| ITG (基于图像的文本生成) | 训练模型生成文本 | 让 查询向量提取信息,并传递给 LLM 生成文本 | 多模态因果掩码(Queries 互相可见,文本只能看过去信息) |
| ITM (图文匹配) | 预测图像和文本是否匹配 | 计算 图像查询向量 Z 作为匹配得分 | 双向掩码(Queries & Text 互可见) |
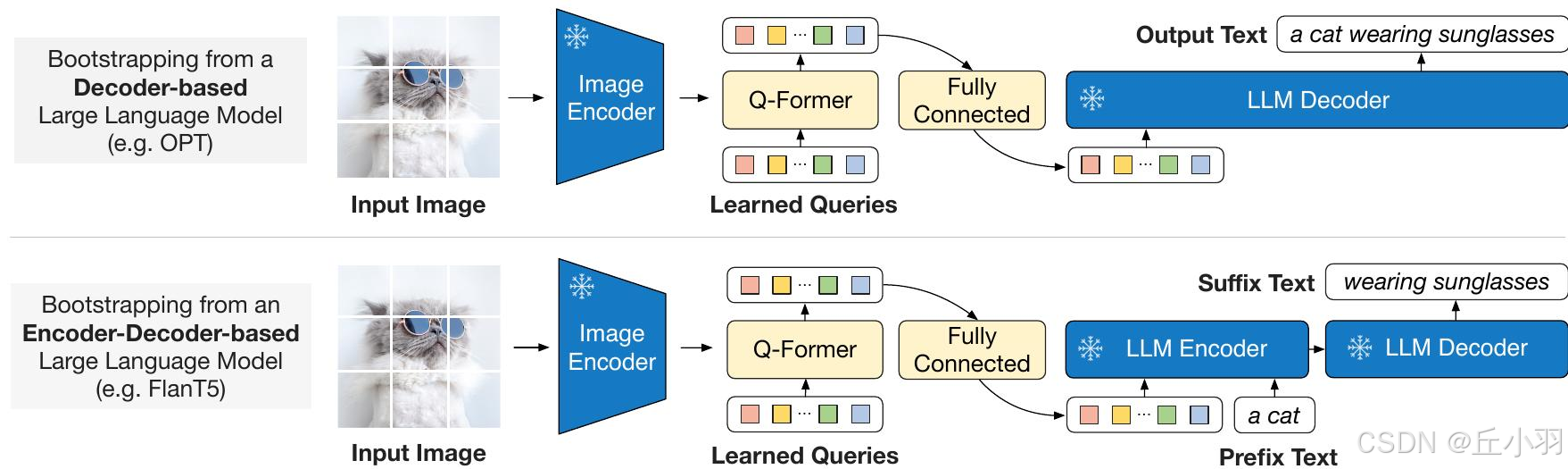
第二阶段,从冻结的大模型学习从视觉到语言生成能力。
为了让LLM能够接受视觉信息,BLIP2使用Q-Former作为视觉信息提取器,并采用全连接层进行向量转化。
BLIP2兼容两种LLM,第一种是基于解码器的LLM,采用语言建模损失,上图中上半部分,生成完整的文本,和基于编码解码器的LLM,采用前缀语言建模损失,将文本分为前缀+后缀,前缀文本+视觉特征作为LLM编码器的输入,后缀文本作为LLM解码器的输出。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)