FragFake: 一个用于细粒度检测编辑图像的视觉语言模型数据集
局部编辑图像的细粒度检测对于评估内容真实性至关重要,特别是现代扩散模型和图像编辑方法能够生成高度逼真的操作。然而,这一领域面临三个挑战:(1) 二分类器仅提供全局真假标签而无法定位;(2) 传统计算机视觉方法通常依赖昂贵的像素级注释;(3) 缺乏大规模高质量的数据集以支持现代图像编辑检测技术。为解决这些差距,我们开发了一条自动化数据生成管道,创建了FragFake——第一个专用于编辑图像检测的基准
孙振 1{ }^{1}1 张子一 1{ }^{1}1 罗泽然 1{ }^{1}1 邵泽阳 2{ }^{2}2 丛天朔 3{ }^{3}3 李正 4{ }^{4}4 崔世文 2{ }^{2}2 王伟强 2{ }^{2}2 魏嘉衡 1{ }^{1}1 何新磊 1×{ }^{1 \times}1× 李琦 3{ }^{3}3 汪倩 5{ }^{5}5
1{ }^{1}1 香港科技大学(广州) 2{ }^{2}2 蚂蚁集团
3{ }^{3}3 清华大学 4{ }^{4}4 山东大学 5{ }^{5}5 武汉大学
摘要
局部编辑图像的细粒度检测对于评估内容真实性至关重要,特别是现代扩散模型和图像编辑方法能够生成高度逼真的操作。然而,这一领域面临三个挑战:(1) 二分类器仅提供全局真假标签而无法定位;(2) 传统计算机视觉方法通常依赖昂贵的像素级注释;(3) 缺乏大规模高质量的数据集以支持现代图像编辑检测技术。为解决这些差距,我们开发了一条自动化数据生成管道,创建了FragFake——第一个专用于编辑图像检测的基准数据集,包括来自多种编辑模型的高质量图像和各种编辑对象。基于FragFake,我们首次在编辑图像分类和编辑区域定位任务中使用视觉语言模型(VLM)。实验结果表明,微调后的VLM在所有数据集中实现了更高的平均目标精度,显著优于预训练模型。我们进一步进行了消融分析和可转移性分析,以评估不同配置和编辑场景下的检测器性能。据我们所知,这是首次将局部图像编辑检测重新定义为视觉-语言理解任务的工作,为该领域建立了新的范式。我们预计这项工作将为多模态内容真实性的后续研究奠定坚实的基础。代码 1{ }^{1}1 和数据集 2{ }^{2}2 是开源的。
1 引言
由于扩散模型的迅速进步,它们生成的图像,通常称为AI生成内容(AIGC),已经变得极其逼真 [1, 2, 3]。同时,图像编辑技术也取得了显著进展 [4,5,6][4,5,6][4,5,6]。与传统方法不同的是,
这些方法不再生成完全合成的图像,而是通过自然语言引导进行局部修改,同时保留图像其余部分不变 [4]。
基于真实图像的这些部分编辑版本通常看起来非常真实,因为它们大部分视觉内容保持不变。然而,这种现实主义也可能带来严重的安全威胁。此类图像可以被用来制造极具说服力的假新闻或操纵公众舆论 [7]。例如,在2024年7月,美联社的一张照片显示特勤局特工在一次暗杀未遂事件后严肃地保护唐纳德·特朗普。这张照片的编辑版本在社交媒体上传播开来,其中特工被欺骗性地编辑成微笑的样子。由于这一修改,一些用户错误地将该事件解读为一场“政治表演”,从而引发了广泛的错误信息和公众困惑 [8]。因此,准确区分部分编辑图像和真实图像的能力已成为一项迫切且不可或缺的挑战。
大多数传统的图像伪造检测器都是在由完全真实或完全生成的图像组成的数据集上训练的。因此,当面对仅包含局部编辑的图像时,其性能会显著下降。例如,开源的AIGC检测器Hive Moderation [9] 在100张部分编辑的图像中只能正确识别出55张为AI生成(详见附录B)。这种局限性源于图像中存在大量真实内容,容易误导分类器预测为真实。此外,大多数现有的检测方法依赖于二分类策略,仅对整个图像提供“真实”或“虚假”的决策。这些方法缺乏指出具体哪些区域被编辑的能力,因此不适合实际的取证和来源应用。虽然一些计算机视觉方法探索了编辑区域的定位,但它们通常依赖于昂贵的像素级注释 [10]。此外,使用的数据集往往涉及过时的编辑模型,无法反映现代生成技术的真实性。
*通讯作者(sinleihe@fiknot-gz.edu.cn).
${ }^{1}$ 代码链接: https://github.com/Vincent-NRUST02/FragFake.
${ }^{2}$ 数据集链接: https://huggingface.co/datasets/Vincent-

图1:由四种不同模型生成的编辑图像示例,展示了两种操作类型:对象添加和对象替换。
1.1 我们的贡献
为了解决这些问题,我们提出利用视觉语言模型(VLMs) [11] 进行编辑图像检测,包括分类和定位。预训练的VLMs在大规模图像文本对上进行训练,具有强大的视觉理解能力,并可以高效地微调用于各种下游任务。
由于使用VLMs进行编辑图像检测是一项新颖的任务,目前没有高质量的公共数据集存在,我们构建了一个专门的图像数据集,称为FragFake,其中包括由几个先进的图像编辑模型生成的编辑图像,包括三个开源模型(MagicBrush [6], GoT [12], 和 UltraEdit [12])以及一个商业部署的模型(Gemini,以下简称Gemini-IG [13] 用于“图像生成”)。数据集涵盖了两种主要的编辑操作类型:对象添加和对象替换。
为了确保源图像的多样性,我们从COCO数据集 [14] 的80个类别中每个类别采样20张图像,总共得到1,600张原始图像。由于大多数现代图像编辑方法支持自然语言驱动的编辑,我们使用GPT40 [15] 根据这些原始图像生成总共3,200条编辑指令。在此过程中,我们观察到许多指令中指定的目标对象是重复的。因此,我们将此版本称为Easy版本。在此基础上,我们进一步优化数据集,通过过滤和替换重叠的目标对象来生成Hard版本,其中包含1,930条独特的指令,所有目标对象均无冗余。结合四个编辑模型,这些指令生成了20,222张编辑图像。这种图像生成和指令创建完全是自动化的,形成了一种可扩展和可扩展的管道。需要注意的是,当前数据集主要用于验证和展示我们管道的可行性;因此,只生成了大约20,000张图像。然而,该管道具有高度的可扩展性,可以扩展生成数十万张样本以支持更大规模的研究。生成的编辑图像及其对应的指令随后转换为图像文本对,用于训练VLMs。我们微调了四个广泛使用的模型来进行此任务:Llava-1.5 [16], Qwen2-VL [17], Qwen2.5-VL [18] 和 Gemma3 [19]。
我们的评估分为两个层次:编辑图像
分类性能(使用Accuracy和F1-score)和编辑区域定位性能,使用区域精度(RP)和对象精度(OP)。在所有预训练的VLMs中,GPT-4o在Hard版本上的表现最佳,Accuracy为0.810,Object Precision (OP) 为45.0%,而在Gemini-IG数据集的Easy版本上,Accuracy为0.825,OP为46.0%。相比之下,经过LoRA微调的Qwen2.5-VL(7B)探测器表现出显著的最佳性能,在Hard和Easy版本上分别获得了0.990和0.965的Accuracy分数,以及69.0%69.0 \%69.0%和74.0%74.0 \%74.0%的OP值。与预训练模型最初的约5.0% OP相比,微调后的Qwen2.5-VL显示出显著的改进。这突显了我们构建的数据集的有效性。
此外,我们进行了消融研究,以检查数据平衡策略、训练规模和LoRA秩如何影响模型性能。结果显示,较大的模型在较低的LoRA秩下表现更好,表明较少的可训练参数足以实现有效的适应。我们还进行了迁移实验,表明在Gemini-IG和GoT上训练的探测器在不同领域的泛化性能良好,而那些在MagicBrush和UltraEdit上训练的探测器表现较差。在一种编辑类型上训练的探测器也能很好地泛化到另一种类型,表明强烈的跨任务迁移能力。
总之,我们的主要贡献如下:
- 我们首次提出将编辑图像检测(分类和编辑区域定位)重新定义为视觉语言理解任务,以减少对昂贵注释的依赖。为此,我们构建了FragFake,这是一个包含超过20,000个编辑图像文本对的大规模数据集,通过完全自动化的管道生成,涵盖了多样化的编辑模型和目标对象。
-
- 为了解决预训练VLMs性能差的问题,我们微调并基准测试了几种广泛使用的VLMs(Llava1.5, Qwen2-VL/2.5-VL, Gemma3),在检测性能方面取得了远超GPT-4o的表现。
-
- 我们进行了消融和可迁移性研究:消融实验揭示了最佳的LoRA秩、平衡的数据策略和足够的训练规模显著增强了检测性能;迁移性测试演示了强大的跨域和跨任务泛化能力,为该领域的未来研究提供了启示。
2 相关工作
2.1 图像编辑
最近,图像编辑技术有了显著的发展,使用户能够通过选择性编辑特定区域直观地修改图像 [5, 6, 12]。这与传统的图像生成不同,因为它需要理解用户的意图并保留原始图像的语义。然而,创建逼真的编辑图像的简便性也增加了滥用的可能性,包括虚假信息、欺诈和诽谤,突显了有效检测方法的紧迫需求 [7]。本工作重点研究两种主要的编辑技术:基于扩散模型的编辑和闭源模型编辑。
- 基于扩散模型的编辑。扩散模型极大地推动了图像编辑的发展。MagicBrush在大规模标注数据集上微调InstructPix2Pix,显著提高了图像质量 [6, 5]。UltraEdit使用大型语言模型(LLMs)和真实图像自动生成广泛的编辑指令,增强了数据集的多样性 [12]。GoT将推理引导的语言分析与扩散模型相结合,增强了编辑输出的语义和空间连贯性,表现出优越的性能 [20]。
-
- 闭源模型编辑。闭源模型,如Google的Gemini-IG [13] 和Flux AI的Magic Edit [21],提供了高级的多模态图像生成和编辑功能。Gemini-IG特别支持多模态输入和复杂的编辑任务,而Magic Edit则擅长交互式的聊天编辑。然而,有限的API访问限制了它们的更广泛应用。
2.2 假图像检测和编辑区域定位
人工智能生成内容的激增,特别是逼真的操控图像,加剧了虚假信息的风险 [22, 23]。DE-FAKE整合了检测和归属模型以区分真实和虚假图像 [24]。系统性评估表明,人类和自动化工具都能有效识别AI生成的图像 [25],
但传统的二元分类器难以应对微妙的编辑。为解决这一问题,零样本方法如ZeroFake利用图像反转期间的稳定性差异 [26]。尽管二元分类方法表现良好,但在编辑图像的细粒度检测中更为重要。先前的工作,如 [10],使用像素级注释训练分割模型,通常通过SAM [27] 自动化,但仍需高资源成本。为降低负担,我们用VLM推断编辑区域和对象取代像素级掩码,显著降低了注释开销。
3 数据集构建
在本节中,我们描述了编辑图像检测数据集FragFake的构建。
3.1 构建目标
如第1.1节所述,我们首先需要构建一个可用于训练和评估编辑图像检测性能的数据集。构建的数据集应具有以下属性:
- 编辑模型的多样性:我们包括4个图像编辑模型:1个闭源商业模型(GeminiIG [13])和3个开源模型(MagicBrush [6], GoT [12], 和 UltraEdit [12])。
-
- 质量:所有四个模型都生成高度逼真的图像,如图1所示。为确保测试集的质量,我们手动标注每组子集的100个代表性样本,覆盖所有8个子集(2个版本 ×4\times 4×4 模型),总计800张图像。
-
- 编辑对象的多样性:如第3.2节所述,我们使用GPT-4o生成广泛的编辑指令。为消除目标对象的重复,我们通过过滤和重新查询步骤创建Hard版本,其中每个目标对象都是唯一的。
3.2 构建管道
为了构建一个全面的数据集,我们使用广泛使用的COCO数据集 [14],从每个类别中随机抽取20张图像 (20×80=1600(20 \times 80=1600(20×80=1600 张图像总计),作为我们的基础。然后我们应用四个图像编辑模型来编辑图像,图2展示了管道和数据集统计。
编辑指令创建。这些图像编辑模型通过自然语言指令操作。手动编写这些指令既耗时又劳动密集,所以我们使用预训练的VLM GPT4o-2024-11-20(温度设置为1)自动生成。首先,我们应用统一的任务模板(参见附录A.1)为1600张原始图像生成初始编辑提示。分析显示,许多待添加或用于替换现有对象的目标对象是重复的,例如“盆栽植物”出现了58次(我们称这个子集为Easy版本)。为减少冗余,我们实施了一个目标对象缓存:如果新生成的指令中的目标对象已经在缓存中,则追加提示“重要:请不要使用以下对象:[对象]”,并提示GPT4o重新生成指令。如果同一对象在三次尝试后仍重复出现,我们丢弃该指令。剩余的指令和图像构成了Hard版本,其中每个目标对象都是唯一的。
FragFake。在生成编辑指令后,我们使用每个编辑模型处理图像,即 MagicBrush, UltraEdit, GoT 和 Gemini-IG。前三个是开源模型,我们在本地环境中运行,而 Gemini-IG(也称为 Gemini-2.0-flashexp)是一个闭源商业模型,其输入和输出经过内容过滤。这种过滤防止了一些图像被编辑,因此 Gemini-IG 的编辑输出数量略低于其他模型,如图2所示。一旦获得所有编辑图像,我们将其转换为VLM训练所需的图像文本对格式。每对由编辑图像和明确标识编辑对象的相应模型响应组成;这些对构成完整的FragFake。然后我们手动审查每个编辑方法的编辑图像及其相关响应以确保正确性。对于每个子集,我们随机选择100个审查过的编辑图像及其原始对应图像(总计200张图像)以形成测试集。所有剩余图像都包括在训练集中,无需进一步过滤。
4 实验设置
评估指标。我们使用两个级别的指标来评估图像编辑检测。第一级别涉及二元分类,以确定图像是否已被编辑,这里我们使用准确性(Accuracy)和F1分数(F1-score)作为指标。这些指标是基于关键词匹配计算的。第二级别包括细粒度评估指标:区域精度(Region Precision)和对象精度(Object Precision)。区域精度衡量VLM是否正确识别编辑位置,而对象精度评估模型是否正确识别编辑对象。由于这些指标单独使用预训练的VLM难以评估,我们采用人工标注进行准确评估。具体来说,区域精度是一个比对象精度更宽泛的评估标准。例如,在预测过程中,VLM可能生成与地面实况(GT)措辞不同的输出,但人工标注者可以判断预测对象位于与GT相同的区域内。图9提供了一个这样的人工评估示例。对象精度侧重于模型输出与地面实况之间的语义一致性。在人工评估中,我们将表达具有相同或高度相似含义的情况视为正确匹配。例如,“花瓶”和“花束”或“水果篮”和“新鲜水果碗”都被判定为语义一致,因此计为真阳性。人工评估结果基于两位作者的交叉验证。平均而言,评估5个样本大约需要1分钟。我们使用Label Studio平台进行人工标注,如图12所示。
用于训练的VLM。我们选择四个VLM进行微调。对于Llava-1.5,我们使用llava-1.5-7b-hf版本 [28]。对于Qwen2-VL [29] 和Qwen2.5-VL [30],我们使用它们各自的7B版本。对于Gemma3,我们使用gemma-3-4b-it模型 [31] 进行微调。
用于测试的VLM。除了上述四个开源模型外,我们还选择了四个强大的商业闭源模型进行评估:GPT-4o-mini (2024-07-18) [32],GPT-4o (2024-11-20) [15],GLM-4V (glm-4v-plus-0111) [33] 和Gemini-2.5 (gemini-2.5-flash-preview-04-17) [34]。所有模型均通过其API访问,温度设置为0.1 。
训练超参数。我们采用LoRA [35] 进行模型微调,这是一种广泛使用且高效的参数高效调整方法。实现基于Llama-Factory框架 [36]。我们使用单个NVIDIA L20 GPU进行训练。超参数设置如下:秩设置为64 ,学习率为 5e−45 \mathrm{e}-45e−4,训练周期数为5 ,批大小为16 。我们使用训练后获得的最终检查点进行评估。由于FragFake的Hard和Easy版本包含不同数量的样本,我们从每个版本中随机抽取3,000对图像(编辑图像和相应的原始图像按 1:11: 11:1 比例)进行训练。当某个版本中的原始图像数量少于编辑图像时,我们补充非冗余的COCO数据集图像以保持样本平衡。
5 评估
5.1 不同VLM的比较
预训练VLM的性能。具有强大图像理解能力的VLM即使未经微调,通常在下游视觉问答任务中表现良好。为了研究它们直接识别图像中对象是否被编辑的能力,我们在FragFake测试集的Gemini-IG子集上对其进行评估。我们测试两类模型:(1) 流行的专有生产VLM,包括GPT4o-mini, GPT4o, GLM-4V和Gemini-2.5;(2) 广泛使用的开源VLM,包括Llava-1.5, Qwen2-VL, Qwen2.5-VL和Gemma3。为此检测任务,我们设计了一个统一的提示,如附录A.2所示。
如表1所示,GPT4o在所有检测器中表现最佳,在Gemini-IG的Easy版本上达到了0.825的Accuracy和46.0%的Object Precision,在Hard版本上达到了0.810的Accuracy和45.0%的Object Precision。GPT4o-mini也在Hard版本上表现相对较好,Object Precision达到了42.0%,但在二元分类性能上较弱(Accuracy为0.620)。Qwen2-VL也表现出良好的检测能力,在Hard版本上达到了0.805的Accuracy,但在Object Precision上仅为25.0%,表明其在细粒度分类方面的局限性。
表1:预训练VLM在Gemini-IG子集上的性能。
| Hard | Easy | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Acc. | F1 | RP | OP | Acc. | F1 | RP | OP |
| GPT4o-mini | 0.620 | 0.703 | 42.0%42.0 \%42.0% | 42.0%42.0 \%42.0% | 0.620 | 0.686 | 30.0%30.0 \%30.0% | 30.0%30.0 \%30.0% |
| GPT4o | 0.810\mathbf{0 . 8 1 0}0.810 | 0.798 | 45.0%\mathbf{4 5 . 0 \%}45.0% | 45.0%\mathbf{4 5 . 0 \%}45.0% | 0.825\mathbf{0 . 8 2 5}0.825 | 0.813\mathbf{0 . 8 1 3}0.813 | 46.0%\mathbf{4 6 . 0 \%}46.0% | 46.0%\mathbf{4 6 . 0 \%}46.0% |
| GLM-4V | 0.535 | 0.614 | 35.0%35.0 \%35.0% | 34.0%34.0 \%34.0% | 0.470 | 0.558 | 26.0%26.0 \%26.0% | 26.0%26.0 \%26.0% |
| Gemini-2.5 | 0.605 | 0.368 | 20.0%20.0 \%20.0% | 20.0%20.0 \%20.0% | 0.575 | 0.286 | 11.0%11.0 \%11.0% | 11.0%11.0 \%11.0% |
| Llava-1.5 | 0.500 | 0.565 | 8.0%8.0 \%8.0% | 8.0%8.0 \%8.0% | 0.505 | 0.571 | 9.0%9.0 \%9.0% | 9.0%9.0 \%9.0% |
| Qwen2-VL | 0.805 | 0.804\mathbf{0 . 8 0 4}0.804 | 25.0%25.0 \%25.0% | 25.0%25.0 \%25.0% | 0.810 | 0.808 | 22.0%22.0 \%22.0% | 22.0%22.0 \%22.0% |
| Qwen2.5-VL | 0.535 | 0.256 | 5.0%5.0 \%5.0% | 5.0%5.0 \%5.0% | 0.515 | 0.157 | 4.0%4.0 \%4.0% | 4.0%4.0 \%4.0% |
| Gemma3 | 0.500 | 0.667 | 28.0%28.0 \%28.0% | 27.0%27.0 \%27.0% | 0.500 | 0.667 | 30.0%30.0 \%30.0% | 30.0%30.0 \%30.0% |
注意:Acc.: Accuracy, F1: F1-score, RP: Region Precision, OP: Object Precision.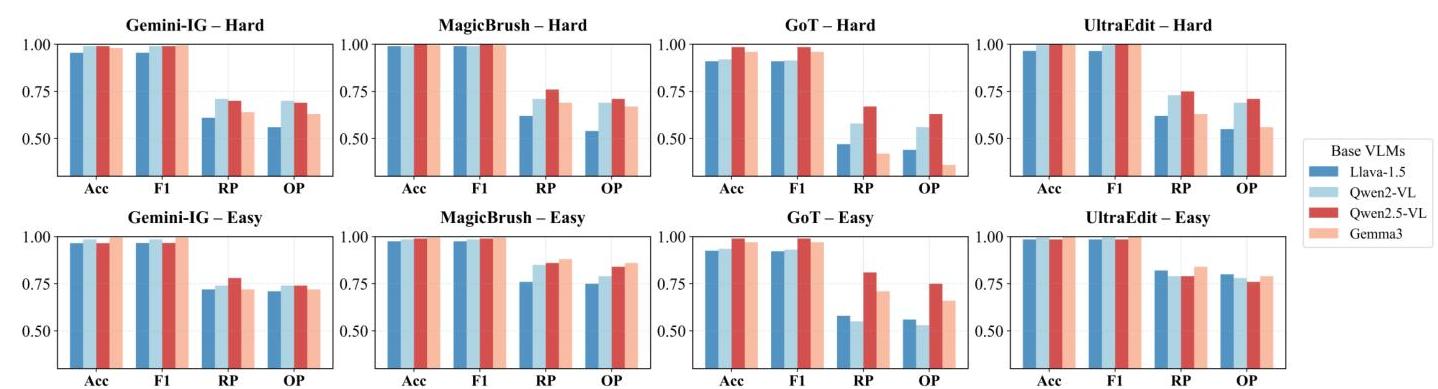
图3:不同版本下不同检测器的性能比较。
其他检测器在这两种设置下的表现相当差。例如,GLM-4V在Hard版本上记录的Accuracy为0.535,Object Precision为34.0%34.0 \%34.0%。Gemini-2.5和Llava-1.5在Hard版本上的Object Precision值分别为20.0%20.0 \%20.0%和8.0%8.0 \%8.0%,几乎不具备细粒度对象识别能力。Qwen2.5-VL的表现接近随机猜测,Hard和Easy版本的Object Precision均为5.0%5.0 \%5.0%左右,完全无法处理该任务。尽管Qwen2.5-VL在标准视觉问答(VQA)基准测试中优于Qwen2-VL [18],但在我们的细粒度对象检测任务中得分较低,这表明我们的数据集与传统VQA基准测试有根本区别。有趣的是,尽管Gemma3的Accuracy仅为0.500,但其Object Precision仍达到27.0−30.0%27.0-30.0 \%27.0−30.0%,与GPT4o-mini等模型相当。这表明,虽然Gemma3在分类任务上表现不佳,但它可能仍保留一定的编辑区域定位能力。总体而言,除GPT4o系列外,现有的预训练VLM在面对Gemini-IG生成的复杂场景时,仍明显缺乏细粒度分类和定位能力。
微调VLM的性能。然后我们微调
四个开源VLM作为检测器,分别是Llava-1.5, Qwen2-VL, Qwen2.5-VL和Gemma3,以验证微调是否能增强它们检测编辑图像的能力。如图3所示,所有检测器在Accuracy和F1-score方面都表现出色的二元分类性能,显示出强大的整体编辑检测能力。Qwen2.5VL表现最为突出。在Hard版本上,它达到了平均Accuracy/F1为0.994/0.994和平均区域/对象精度为72.0%/68.5%72.0 \% / 68.5 \%72.0%/68.5%;在Easy版本上,相应的平均值上升到0.983/0.9830.983 / 0.9830.983/0.983和81.0%/77.3%81.0 \% / 77.3 \%81.0%/77.3%,在细粒度定位和对象识别方面远远优于其他检测器。此外,在Gemini-IG子集上,Qwen2.5-VL在Hard版本上达到了69.0%69.0 \%69.0%的对象精度,在Easy版本上达到了74.0%74.0 \%74.0%的对象精度,相对于表1中的基线分别提高了64.0%64.0 \%64.0%和70.0%70.0 \%70.0%。
Gemma3和Qwen2-VL紧随其后,在Easy版本上都保持了较强的性能,平均对象精度超过70.0%70.0 \%70.0%。然而,Gemma3在Hard版本上的表现显著下降,平均对象精度降至约56.0%56.0 \%56.0%。在GoT编辑方法的Hard版本中,它们的区域精度评分降至42.0%42.0 \%42.0%和58.0%58.0 \%58.0%,对象精度评分降至36.0%36.0 \%36.0%和56.0%56.0 \%56.0%,表明该子集中的细微修改带来了更大的挑战。相比之下,Llava-1.5的表现最弱。其Accuracy从Hard版本的0.955提高到Easy版本的0.963,而对象精度在两者情况下都很低,Hard版本为52.3%52.3 \%52.3%,Easy版本为70.5%70.5 \%70.5%。
表2:使用不同数据准备策略在4,000样本Gemini-IG子集上微调的Llava-1.5模型性能比较。
| 样本策略 | Hard | Easy | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | RP | OP | Acc. | F1 | RP | OP | |
| 无处理 | 0.885 | 0.878 | 54.0%54.0 \%54.0% | 51.0%51.0 \%51.0% | 0.670 | 0.731 | 73.0%73.0 \%73.0% | 72.0%72.0 \%72.0% |
| 仅图像增强 | 0.970 | 0.970 | 59.0%59.0 \%59.0% | 54.0%54.0 \%54.0% | 0.950 | 0.950 | 67.0%67.0 \%67.0% | 65.0%65.0 \%65.0% |
| 从COCO Extras抽样 | 0.965 | 0.965 | 64.0%64.0 \%64.0% | 59.0%59.0 \%59.0% | 0.975 | 0.975 | 74.0%74.0 \%74.0% | 71.0%71.0 \%71.0% |
| Bootstrap重抽样 | 0.955 | 0.955 | 62.0%62.0 \%62.0% | 57.0%57.0 \%57.0% | 0.955 | 0.956 | 72.0%72.0 \%72.0% | 70.0%70.0 \%70.0% |
注意:Acc.: Accuracy, F1: F1-score, RP: Region Precision, OP: Object Precision.
表3:流行视觉骨干在Gemini-IG(Easy版本)上的性能比较。
| 指标 | ResNet- 50[37]\mathbf{5 0}[37]50[37] |
DenseNet- 121\mathbf{1 2 1}121 [38] |
MobileNet- 12\mathbf{1 2}12 [39] |
ViT- B/16 [40] |
Inception- V3 [41] |
ConvNeXt- Base [42] |
Swin- B/4W7 [43] |
|---|---|---|---|---|---|---|---|
| 准确率 | 0.890 | 0.905 | 0.855 | 0.940 | 0.905 | 0.995 | 1.000\mathbf{1 . 0 0 0}1.000 |
| F1-score | 0.890 | 0.907 | 0.857 | 0.940 | 0.903 | 0.995 | 1.000\mathbf{1 . 0 0 0}1.000 |
注意:ViT-B/16 = vit_base_patch16_224; Swin-B/4W7 = swin_base_patch4_window7_224.
总体而言,编辑方法的选择显著影响检测难度。与预训练模型相比,微调后的VLM不仅在二元编辑检测方面取得了显著提升,还在细粒度定位和对象识别方面达到了令人印象深刻的水平。尽管Hard版本的训练和测试集包含不相交的编辑目标,导致相对较低的性能,但每个模型仍然保持平均二元分类准确率高于0.950,并满足细粒度检测的实际需求。
5.2 消融研究
LoRA秩对检测性能的影响。我们使用LoRA进行微调,不同的LoRA秩对应不同数量的额外可训练参数。因此,我们研究LoRA秩如何影响检测性能。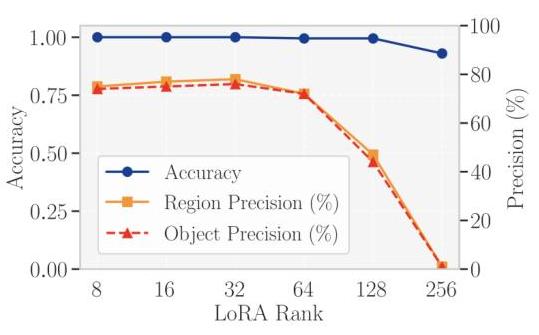
图4:Gemma3检测器:在Gemini-IG(Easy版本)数据集上不同秩设置的性能。
图4和14显示了随着LoRA秩增加,Gemini-IG Easy版本数据集上的分类准确率、区域精度和对象精度的趋势。对于Gemma3(4 B参数),性能随着秩的增加而提高,并在秩为32时达到峰值,准确率为1.000,区域精度为78.0%78.0 \%78.0%,对象精度约为76.0%76.0 \%76.0%。超出此秩后,所有三个指标都会下降。对于
Qwen2.5-VL(7 B参数),最佳性能出现在秩为8时,区域精度为81.0%81.0 \%81.0%,对象精度为78.0%78.0 \%78.0%。这些结果表明,不同规模和架构的检测器需要不同数量的可训练参数,因为较大的模型已经具备更大的表达能力,可以通过较小的LoRA秩有效适应,而将秩设置得过高可能会破坏基础模型的预训练能力。
不同数据平衡策略的比较。参考图2,我们的原始数据集包含1,600张图像,其中100张被预留作测试集。我们现在探讨一种情况,即训练集中编辑图像的数量(设定为2,000)超过原始图像的数量。在这种情况下,我们旨在确定哪种数据平衡策略能产生最佳性能。对于无处理基线,我们在所有可用数据上进行训练(1,500原始 + 2,000编辑 = 3,500张图像),在Hard版本上获得0.885的准确率和51.0%51.0 \%51.0%的对象精度,在Easy版本上获得67.0%的准确率和72.0%的对象精度。为了充分利用4,000张图像预算并保持原始和编辑图像各占2,000张的平衡,我们通过三种策略之一将原始集从1,500扩展到2,000:(1) 仅图像增强通过应用随机旋转、水平翻转和中心裁剪生成400个新样本;(2) 从COCO Extras抽样从原始拆分中未使用的COCO数据集中抽取400张图像;(3) Bootstrap重抽样从1,500个原始图像中重复抽样,直到集达到2,000张图像。
如表2所示,仅图像增强将Hard准确率提高到0.970(54.0% OP),Easy准确率提高到0.950(65.0% OP)。从COCO Extras抽样在Hard上达到0.965准确率(59.0%59.0 \%59.0% OP),在Easy上达到0.975准确率(71.0%71.0 \%71.0% OP),并在Hard版本上实现了最高的区域精度64.0%64.0 \%64.0%。Bootstrap重抽样在Hard上获得0.955准确率(57.0%57.0 \%57.0% OP),在Easy上获得0.956准确率(70.0%70.0 \%70.0% OP),表明即使是简单的原始集重抽样也可以显著提高性能。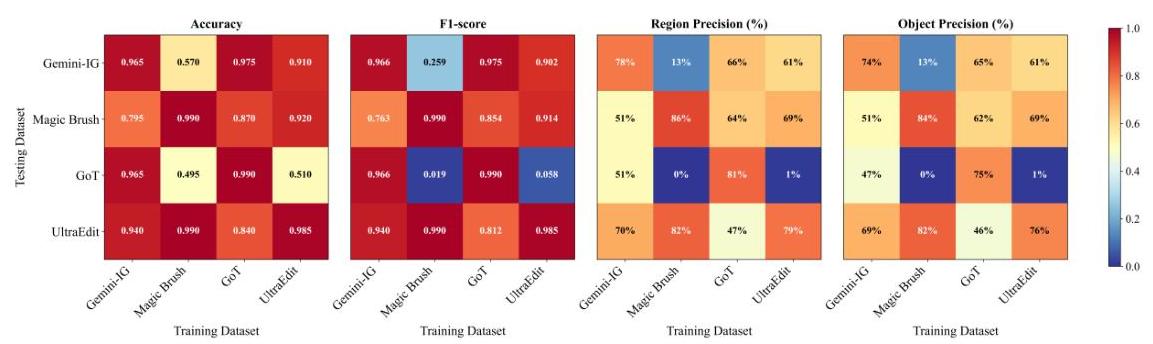
图5:四个数据集(Gemini, MagicBrush, GoT, UltraEdit)在Easy设置下的交叉评估结果,显示准确率、F1-score、区域精度和对象精度。(注意:微调模型是Qwen2.5-VL)
数据规模对检测的影响。我们评估Gemini-IG子集中,当训练图像数量从1,000增加到4,000时,模型性能如何变化,同时保持原始图像和编辑图像的比例为1:1。我们使用LoRA秩为64的Gemma3模型进行微调。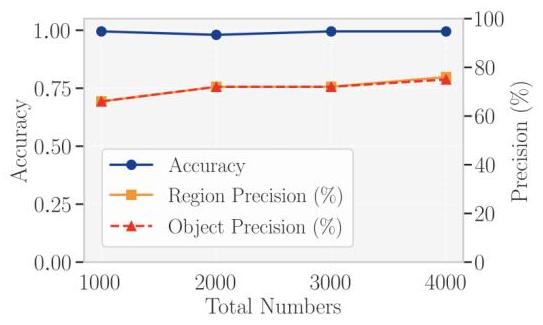
图6:Gemma3训练数据集的扩展行为。
如图6所示,整体分类准确率在所有样本规模下几乎保持在1.000,仅在2,000图像时有轻微波动。相比之下,随着数据集的增长,区域精度和对象精度稳步提高。区域精度从1,000图像时的66.0%66.0 \%66.0%增加到4,000图像时的76.0%76.0 \%76.0%,对象精度从66.0%66.0 \%66.0%上升到75.0%75.0 \%75.0%。这些发现表明,尽管分类准确率在早期阶段就饱和了,但更详细的指标仍能从更大的训练集中受益。不同视觉骨干的比较。我们使用Gemini-IG Easy版本数据集评估传统视觉骨干在编辑图像检测任务中的性能。结果如表3所示。我们比较了两组中的七个视觉骨干:传统的卷积网络和基于变压器的网络。传统卷积网络(ResNet-50, DenseNet-121, MobileNet-V2 和 Inception-V3)的准确率范围为0.855至0.905。MobileNet-V2的准确率最低为0.855,而DenseNet-121和Inception-V3都达到了0.905。基于变压器的骨干(ViT-B/16, ConvNeXtBase 和 Swin-B/4W7)表现出更大的差异:ViT-B/16 达到了0.940,ConvNeXt-Base 达到了0.995,SwinB/4W7 达到了1.000。在VLM中,当前表现最好的Gemma3在该任务上也达到了1.000的准确率(见图4的秩32结果)。然而,正如上面提到的,只有能够提供更精确对象描述的检测器
才能在实际应用中提供更大的价值。
5.3 零样本迁移能力
在本节中,我们研究检测器在没有任何额外微调的情况下,对未见过的编辑场景进行图像编辑检测的能力。
在不同数据集上的迁移能力。我们评估Qwen2.5-VL的零样本迁移能力,因为它始终优于其他微调模型。如图5和13所示,训练在Gemini-IG或GoT上的检测器表现最佳。在Easy设置下,Gemini-IG在转移到GoT时达到0.965的准确率和47.0%47.0 \%47.0%的对象精度,并在UltraEdit上保持69.0%69.0 \%69.0%,但在MagicBrush上下降到51.0%51.0 \%51.0%。GoT训练的检测器在转移到Gemini-IG、MagicBrush和UltraEdit时分别达到65.0%,62.0%65.0 \%, 62.0 \%65.0%,62.0%, 和46.0%46.0 \%46.0%。相比之下,MagicBrush训练的检测器表现出较差的泛化能力,在转移到Gemini-IG时对象精度下降到13.0%13.0 \%13.0%,在转移到GoT时下降到0.0%0.0 \%0.0%,尽管在UltraEdit上仍保持82.0%82.0 \%82.0%,这表明两者之间存在相似性。同样的模式也适用于Hard版本,尽管总体得分较低。
总之,单数据集检测器在域内表现良好,但在跨域时性能下降,这突显了在多样化的数据集上进行联合微调以实现稳健的开放世界检测的必要性。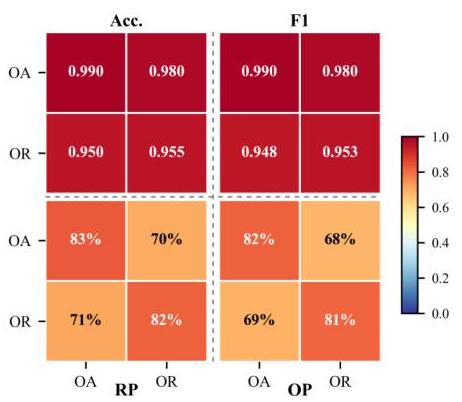
图7:Qwen2.5-VL检测器在Gemini-IG数据集(Easy版本)上的OA和OR任务迁移能力。
不同编辑任务上的迁移能力。我们分别使用不同的训练和测试集训练和评估两种任务类型,对象添加(OA)和对象替换(OR)。
我们选择Gemini-IG和UltraEdit数据集(Easy版本)进行此实验。每个特定任务的训练集包含2,000张图像,相应的测试集包含200张图像,原始图像与编辑图像的比例为1:1。Qwen2.5-VL也在所有设置中通过LoRA进行微调。
如图7所示,在Gemini-IG数据集中,经过OA训练的检测器达到了0.990的准确率和82.0%82.0 \%82.0%的对象精度。当转移到OR任务时,它仍然保持了0.950的准确率和69.0%69.0 \%69.0%的对象精度。同样,经过OR训练的检测器也保留了高准确率和可迁移性。这些结果表明,这两种任务类型共享某些特征,并表现出跨任务泛化的潜力。在UltraEdit数据集上也观察到了类似的结果,如图11所示。
6 局限性
我们构建了第一个系统性的数据集FragFake,专门用于检测AI编辑的图像。然而,仍存在几个局限性:
- 编辑目标类型的有限性。在本文中,我们仅考虑了两种编辑操作:对象添加和对象替换。然而,图像编辑涵盖更广泛的修改 [4],例如背景变化和情感表达的修改,这些可以在未来的工作中进行探索。
-
- 编辑方法的多样性有限。我们的数据集包括四种具有代表性的图像编辑方法。虽然这些涵盖了多种实际案例,但领域中还存在许多其他编辑技术,可以在后续研究中纳入以提高覆盖范围和鲁棒性。
-
- 缺乏对训练样本的自动过滤。我们没有对训练数据进行过滤,因为手动验证非常耗时。然而,我们观察到一些编辑输出偏离了原始指令,偶尔修改了非预期的对象。这些实例引入了训练集中的噪声。我们认为,应用高效的数据过滤或质量保证机制可以进一步提高微调模型的性能。
7 结论
我们的工作首次实现了无需人工注释即可使用VLMs进行编辑区域定位。我们设计了一条完全自动化且可扩展的数据集构建管道,并发布了FragFake,这是第一个用于编辑图像检测的高多样性VLM导向数据集。我们使用LoRA微调VLMs并进行了广泛评估,证明了VLMs能够有效执行高精度图像编辑检测和定位。我们的结果显示了强大的跨域和编辑任务的可迁移性,为未来的自动化图像取证和篡改检测研究奠定了坚实基础。我们还在第6节中讨论了局限性和未来方向。
参考文献
[1] 陈航, 项倩, 胡佳欣, 叶美琳, 余超, 程浩, 张磊. 扩散模型在图像生成中的全面探索:综述. 人工智能评论, 58(4):99, 2025. I
[2] 杨玲, 张志龙, 宋洋, 洪世达, 徐润生, 赵越, 张文涛, 崔斌, 杨明轩. 扩散模型:方法和应用的全面综述. ACM计算调查, 56(4):105:1-105:39, 2024. I
[3] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. 使用潜在扩散模型的高分辨率图像合成. 在IEEE/CVF计算机视觉和模式识别会议, CVPR 2022, 美国路易斯安那州新奥尔良, 2022年6月18日至24日, 第10674-10685页. IEEE, 2022. I
[4] 黄毅, 黄建程, 刘一帆, 颜明福, 吕嘉锡, 刘健庄, 熊伟, 张鹤, 陈世锋, 曹亮亮. 基于扩散模型的图像编辑:综述. CoRR, abs/2402.17525, 2024. I, 8
[5] Tim Brooks, Aleksander Holynski, Alexei A. Efros. InstructPix2Pix: 学习遵循图像编辑指令. 在IEEE/CVF计算机视觉和模式识别会议, CVPR 2023, 加拿大不列颠哥伦比亚省温哥华, 2023年6月17日至24日, 第18392-18402页. IEEE, 2023. 1, 3
[6] 张凯, 莫凌波, 陈文虎, 孙欢, 苏宇. Magicbrush: 一个用于指导式图像编辑的手动注释数据集. 在Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, Sergey Levine编著, 第36届神经信息处理系统大会进展, NeurIPS 2023, 美国路易斯安那州新奥尔良, 2023年12月10日至16日, 2023. 1, 2, 3
[7] Alexander Loth, Martin Kappes, Marc-Oliver Pahl. 神器还是诅咒?生成式AI对假新闻影响的综述. CoRR, abs/2404.03021, 2024. 1, 3
[8] MELISSA GOLDIN. 照片编辑使其看起来像是特勤局特工在特朗普遇刺后微笑. https://apnews.com/article/fact-check-trump-shooting-secret-service-amilingphoto-427049284678, 2024. 访问日期: 2025-05-03. I
[9] Hive Moderation. https://hivemoderation.com/. 访问日期: 2025-05-15. I
[10] 孙智豪, 方海鹏, 曹娟, 赵新英, 王丹顶. 生成式AI时代重新思考图像编辑检测. 在Cai Jianfei, Mohan S. Kankanhalli, Balakrishnan Prabhakaran, Susanne Boll, Ramanathan Subramanian, 郑梁, Singh Vivek K., Pablo César, Lexing Xie, Dong Xu编著, 第32届ACM国际多媒体会议论文集, MM 2024, 澳大利亚维多利亚州墨尔本, 2024年10月28日至11月1日, 第3538-3547页. ACM, 2024. 1, 3
[11] 李宗霞, 武曦洋, 杜洪洋, 刘福潇, Nghiem Huy, 石光耀. 最先进的大型视觉语言模型综述:对齐、基准、评估和挑战, 2025. 2
[12] 赵昊哲, Ma Xiaojian (Shawn), 陈良, 施淑正, 吴濡杰, 安凯凯, 余培宇, 张敏佳, 李昭海, 李青, 常宝宝. Ultraedit: 大规模基于指令的细粒度图像编辑. 在Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, Cheng Zhang编著, 第38届神经信息处理系统大会进展, NeurIPS 2024, 加拿大不列颠哥伦比亚省温哥华, 2024年12月10日至15日, 2024. 2,3
[13] gemini-2.0-flash-exp. https://developers.googleblog.com/en/experiment-with-gemini-20-flash-native-image-generation/, 2, 3
[14] 林聪义, Maire Michael, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, C. Lawrence Zitnick. Microsoft COCO: 上下文中的常见对象. 在David J. Fleet, Tomás Pajdla, Bernt Schiele, Tinne Tuytelaars编著, 计算机视觉 - ECCV 2014 - 第13届欧洲会议, 瑞士苏黎世, 2014年9月6日至12日, 论文集, 第五部分, Lecture Notes in Computer Science系列, 第8693卷, 第740-755页. Springer, 2014. 2, 3
[15] OpenAI. Hello gpt-4o. https://openai.com/index/hello-gpt-4o/, 2024. 访问日期: 2025-05-13. 2, 4
[16] 刘浩天, 李春远, 吴庆阳, 李永杰. 视觉指令调优. 在Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, Sergey Levine编著, 第36届神经信息处理系统大会进展, NeurIPS 2023, 美国路易斯安那州新奥尔良, 2023年12月10日至16日, 2023. 2
[17] 王鹏, 白帅, 谭思楠, 王世杰, 范志皓, 白金泽, 陈克勤, 刘雪婧, 王家林, 葛文斌, 范杨, 党凯, 杜梦菲, 任轩成, 门睿, 刘大意亨, 周昌, 周靖人, 林俊阳. Qwen2-vl: 提升任何分辨率下的视觉语言模型的世界感知能力. CoRR, abs/2409.12191, 2024. 2
[18] 白帅, 陈科勤, 刘雪婧, 王家林, 葛文斌, 宋思博, 党凯, 王鹏, 王世杰, 唐军, 中文人类, 朱元智, 杨明轩, 李兆海, 万建强, 王鹏飞, 丁卫, 福哲仁, 许义恒, 叶加波, 张希, 谢天文, 程泽森, 张行, 杨志波, 许海扬, 林俊阳. Qwen2.5-vl技术报告. CoRR, abs/2502.13923, 2025. 2, 5
[19] Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, JeanBastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Beyer, 尹晓海, Anton Tsitsulin, Robert Busa-Fekete, Alex Feng, Noveen Sachdeva, Benjamin Coleman, 高奕, Basil Mustafa, Iain Barr, Emilio Parisotto, David Tian, Matan Eyal, Colin Cherry, Jan-Thorsten Peter, Danila Sinopalnikov, Surya Bhupatiraju, Rishabh Agarwal, Mehran Kazemi, Dan Malkin, Ravin Kumar, David Vilar, Idan Brusilovsky, 娄剑鸣, Andreas Steiner, Abe Friesen, Abhanshu Sharma, Abheesht Sharma, Adi Mayrav Gilady, Adrian Goedeckemeyer, Alaa Saade, Alexander Kolesnikov, Alexei Bendebury, Alvin Abdagic, Amit Vadi, András György, André Susano Pinto, Anil Das, Ankur Bapna, Antoine Miech, Antoine Yang, Antonia Paterson, Ashish Shenoy, Ayan Chakrabarti, Bilal Piot, Bo Wu, Bobak Shahriari, Bryce Petrini, Charlie Chen, Charline Le Lan, Christopher A. Choquette-Choo, CJ Carey, Cormac Brick, Daniel Deutsch, Danielle Eisenbud, Dee Cattle, Derek Cheng, Dimitris Paparas, Divyashree Shivakumar Sreepathihalli, Doug Reid, Dustin Tran, Dustin Zelle, Eric Noland, Erwin Huizenga, Eugene Kharitonov, Frederick Liu, Gagik Amirkhanyan, Glenn Cameron, Hadi Hashemi, Hanna Klimczak-Plucinska, Harman Singh, Harsh Mehta, Harshal Tushar Lehri, Hussein Hazimeh, Ian Ballantyne, Idan Szpektor, 和 Ivan Nardini. Gemma 3技术报告. CoRR, abs/2503.19786, 2025. 2
[20] Fang Rongyao, Duan Chengqi, Wang Kun, Huang Linjiang, Li Hao, Yan Shilin, Tian Hao, Zeng Xingyu, Zhao Rui, Dai Jifeng, Liu Xihui, Li Hongsheng. Got: 释放多模态大语言模型的推理能力用于视觉生成和编辑. CoRR, abs/2503.10639, 2025. 3
[21] Magic edit. https://flux1.ai/magic-edit/. 3
[22] 孙振, 张宗敏, 沈新月, 张子一, 刘玉乐, Backes Michael, 张阳, 何新磊. 我们已经进入AI生成文本的世界了吗?量化和监控社交媒体上的AIGT. CoRR, abs/2412.18148, 2024. 3
[23] 张涛. 深伪生成与检测,综述. 多媒体工具与应用, 81(5):6259-6276, 2022. 3
[24] Sha Zeyang, 李正, 余宁, 张阳. DEFAKE: 检测和归因由文本到图像生成模型生成的假图像. 在Meng Weizhi, Jensen Christian Damsgaard, Cremers Cas, Kirda Engin编著, 第2023届ACM SIGSAC计算机和通信安全会议论文集, CCS 2023, 丹麦哥本哈根, 2023年11月26日至30日, 第3418-3432页. ACM, 2023. 3
[25] Anna Yoo Jeong Ha, Josephine Passananti, Ronik Bhaskar, Shawn Shan, Reid Southen, Zheng Hai-Tao,
和 Ben Y. Zhao. 有机还是扩散:我们能否区分人类艺术与AI生成的图像?在Bo Luo, Xiaojing Liao, Jun Xu, Engin Kirda, David Lie编著, 第2024届ACM SIGSAC计算机和通信安全会议论文集, CCS 2024, 美国犹他州盐湖城, 2024年10月14日至18日, 第4822-4836页. ACM, 2024. 3
[26] Zeyang Sha, Tan Yicong, Li Mingjie, Backes Michael, 张阳. ZeroFake: 零样本检测由文本到图像生成模型生成和编辑的假图像. 在Bo Luo, Xiaojing Liao, Jun Xu, Engin Kirda, David Lie编著, 第2024届ACM SIGSAC计算机和通信安全会议论文集, CCS 2024, 美国犹他州盐湖城, 2024年10月14日至18日, 第4852-4866页. ACM, 2024. 3
[27] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloé Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross B. Girshick. 分割一切. CoRR, abs/2304.02643, 2023. 3
[28] LLaVA团队. llava-1.5-7b-hf. https://huggingface.co/llava-hf/llava-1.5-7b-hf. 访问日期: 2025-05-14. 4
[29] Qwen团队. Qwen2-vl-7b-instruct. https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct. 访问日期: 2025-05-14. 4
[30] Qwen团队. Qwen2.5-vl-7b-instruct. https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct. 访问日期: 2025-05-14. 4
[31] Google. gemma-3-4b-it. https://huggingface.co/google/gemma-3-4b-it. 访问日期: 2025-05-14. 4
[32] OpenAI. Gpt-4o mini: 推进成本效益智能. https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/, 2024. 访问日期: 2025-05-13. 4
[33] Zhipu AI. Glm-4v模型, 2024. 访问日期: 2025-05-11. 4
[34] Google. Gemini 2.5闪存概述, 2024. 访问日期: 2025-05-11. 4
[35] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen. LoRA: 大型语言模型的低秩适应. 在第十届国际学习表示会议, ICLR 2022, 虚拟活动, 2022年4月25日至29日. OpenReview.net, 2022. 4
[36] Zheng Yaowei, Zhang Richong, Zhang Junhao, Ye Yanhan, Luo Zheyan, Ma Yongqiang. Llamafactory: 统一高效的100多个语言模型微调. CoRR, abs/2403.13372, 2024. 4
[37] He Kaiming, Zhang Xiangyu, Ren Shaoqing, Sun Jian. 深度残差学习用于图像识别. 在2016年IEEE计算机视觉和模式识别会议, CVPR 2016, 美国内华达州拉斯维加斯, 2016年6月
27-30日, 第770-778页. IEEE计算机学会, 2016. 6
[38] Gao Huang, Zhuang Liu, Kilian Q. Weinberger. 密集连接卷积网络. CoRR, abs/1608.06993, 2016. 6
[39] Mark Sandler, Andrew G. Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen. MobileNetV2: 倒置残差和线性瓶颈. 在2018年IEEE计算机视觉和模式识别会议, CVPR 2018, 美国犹他州盐湖城, 2018年6月18-22日, 第4510-4520页. 计算机视觉基金会/IEEE计算机学会, 2018. 6
[40] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. 一张图片值16x16个词:大规模图像识别的变压器. 在国际学习表示会议, 2021. 6
[41] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, Zbigniew Wojna. 重新思考计算机视觉中的Inception架构 . 在2016年IEEE计算机视觉和模式识别会议(CVPR),第2818-2826页. IEEE计算机学会, 2016. 6
[42] 刘壮, 毛汉之, 吴朝元, Christoph Feichtenhofer, Trevor Darrell, 谢赛宁. 2020年代的ConvNet . 在2022年IEEE/CVF计算机视觉和模式识别会议(CVPR),第11966-11976页. IEEE计算机学会, 2022. 6
[43] 刘泽, 林昱彤, 曹悦, 胡涵, 魏亿轩, 张峥, 林步炎, 郭百宁. Swin Transformer: 使用移位窗口的分层视觉Transformer. 在2021年IEEE/CVF国际计算机视觉会议(ICCV),第9992-10002页, 2021. 6
[44] Gabriela Ben Melech Stan, Estelle Aflalo, Raanan Yehezkel Rohekar, Anahita Bhiwandiwalla, Tseng Shao-Yen, Matthew Lyle Olson, Gurwicz Yaniv, Wu Chenfei, Duan Nan, Vasudev Lal. Lvlm-interpret: 一种用于大型视觉语言模型的可解释性工具. arXiv预印本arXiv:2404.03118, 2024. 12
A 任务模板
A. 1 编辑指令创建模板
编辑指令创建模板
VLM:
您是一位专注于图像编辑任务的专家视觉指令生成器。
任务:高级图像修改指令生成描述:给定一个对应于图像中对象的COCO数据集对象标签,以及图像和修改目标(例如,对象添加),生成以下四个输出:
- 对象标题:生成一个自然语言标题来描述该对象(例如,“森林中穿着带有图案衬衫的女人”)。
-
- 简要修改指令:提供一个简洁、命令式的修改指令(例如,“添加一架附近的战斗机”)。
-
- 符号修改:输出一个简洁的表示,仅指示对象的添加或删除。使用 ’ + ’ 表示添加和 ’ - ’ 表示删除。 - 对于添加:“+fighter jet” - 对于删除:“-fighter jet” - 对于替换:“-woman +man”
输入: - COCO对象标签:{coco_label} - 图像:{提供的图像} - 修改目标:{对象添加/对象替换}
输出(以有效JSON格式):{ “object_caption”: “”, “brief_modification_instruction”: “”, “symbolic_modification”: " " }
- 符号修改:输出一个简洁的表示,仅指示对象的添加或删除。使用 ’ + ’ 表示添加和 ’ - ’ 表示删除。 - 对于添加:“+fighter jet” - 对于删除:“-fighter jet” - 对于替换:“-woman +man”
A. 2 编辑图像检测模板
编辑图像检测模板
VLM:
任务描述:
您是一名视觉分析助理。您的任务是检查给定的图像,判断图像中的任何对象是否已被数字方式修改或操控。密切注意照明、阴影、纹理、边缘、透视或逻辑构图中的细微不一致。仔细分析这些视觉线索后再做出判断。
指令:
- 提供详细解释您的推理过程。
-
- 然后,根据您的分析,提供以下两种格式之一的最终结果: - 如果有编辑过的内容:“图像中的东西已被修改。”(将“东西”替换为被修改对象的简短清晰描述,例如“猫”,“天空”,“左侧的树”等)。如果没有任何编辑:“此图像中没有任何内容被修改。”
重要约束条件:
- 您的解释必须出现在结果声明之前。
-
- 不要同时输出两个声明;只能根据您的判断出现一个最终结果。
-
- 谨慎:小的编辑可能难以检测,但如果可见,仍然应该标记出来。
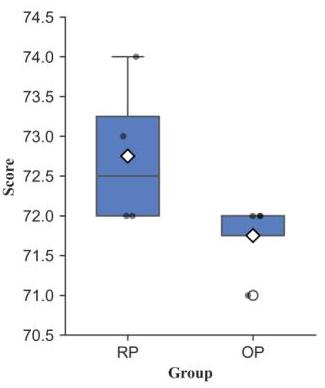
图8:RP和OP组重复实验结果的箱形图。
B Hive Moderation分类结果
Hive Moderation是一种商业假图像检测器。我们使用来自Gemini-IG Easy测试集的100张编辑图像进行手动测试。我们观察到,对于一些编辑图像,Hive Moderation报告的AI可能性接近零,如图10所示。总体而言,只有55张编辑图像被成功检测到。这一结果表明,主要在完全生成的图像上训练的检测器在应用于部分编辑内容时缺乏鲁棒性。
B. 1 可解释性分析
我们使用LVLM-Interpret [44] 对编辑图像进行可解释性分析。如图15所示,模型在生成检测结果时集中在小木屋上。预测修改(“小木屋”)与相应的视觉区域之间的这种一致性证明了模型输出的可靠性和可解释性。
C 重复实验验证
由于我们的评估数据集需要人工标注,重复测试非常耗时。因此,我们不对每次实验进行多次评估运行。然而,我们使用在Gemini-IG Easy版本数据集上训练的Llava-1.5检测器进行重复试验,并观察到RP和OP仅表现出轻微波动,如图8所示。
D 更广泛的影响
我们的工作旨在改进部分编辑图像的检测,这有助于打击虚假信息并支持在越来越逼真的AI生成内容时代维护媒体完整性。通过无需人工标注即可实现编辑的细粒度定位,我们的方法提供了可扩展的内容验证和数字取证工具。
然而,此类工具也可能被滥用——例如,被知情的对手用来改进操纵的微妙之处。此外,必须小心确保模型行为公平无偏,因为数据集生成过程可能会反映底层模型或提示中的偏差。
图9:关于区域精度的人工标注示例。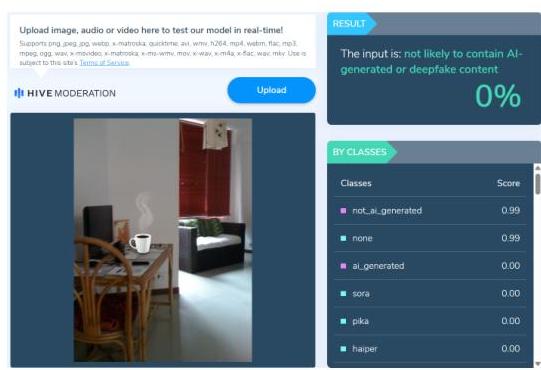
图10:使用Hive Moderation检测编辑图像(真实情况:图像中的咖啡杯已被修改。)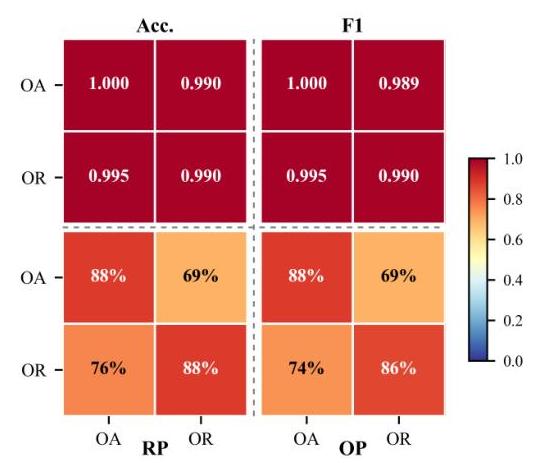
图11:Qwen2.5-VL检测器在UltraEdit上的对象添加(OA)和对象替换(OR)任务之间的交叉任务性能比较。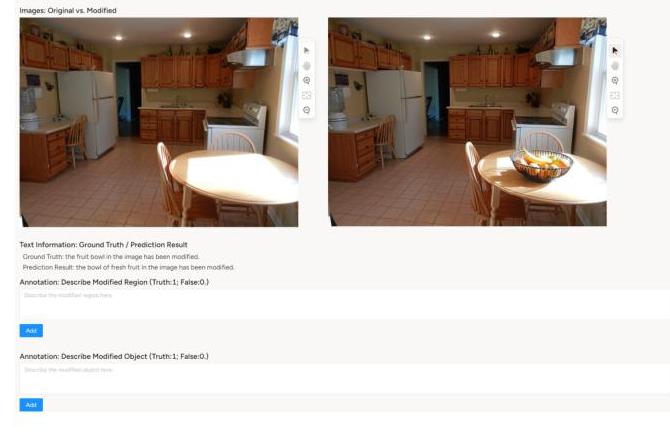
图12:我们使用Label Studio构建的标注平台。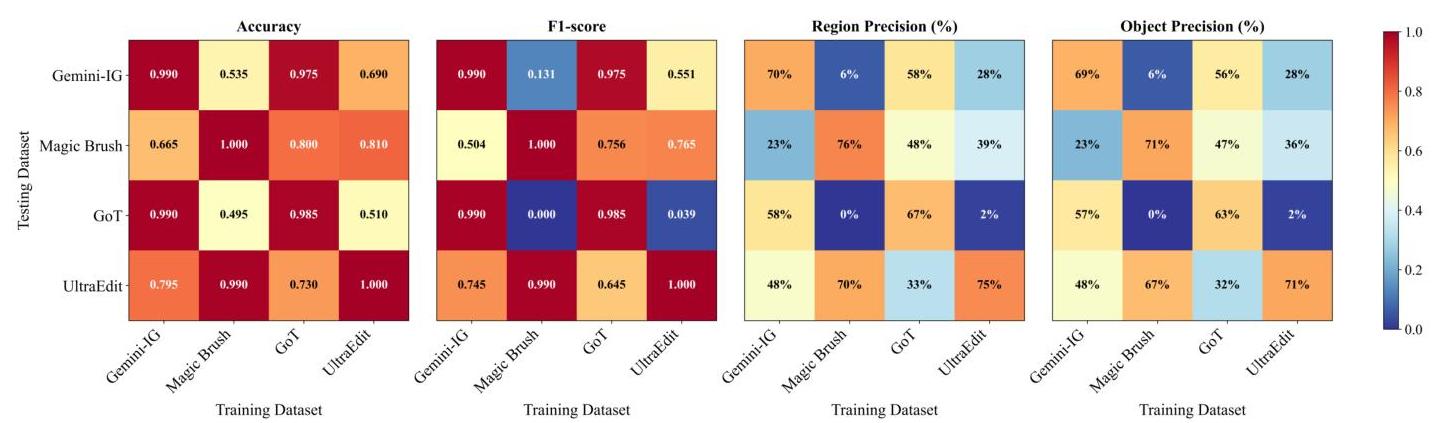
图13:四个数据集(Gemini, MagicBrush, GoT, UltraEdit)在Hard设置下的交叉评估结果,显示准确率、F1-score、区域精度和对象精度。(注意:微调模型是Qwen2.5-VL)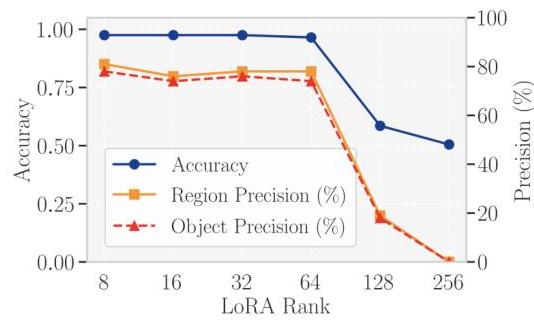
图14:Qwen2.5-VL检测器在Gemini-IG(Easy版本)数据集上不同秩设置的性能。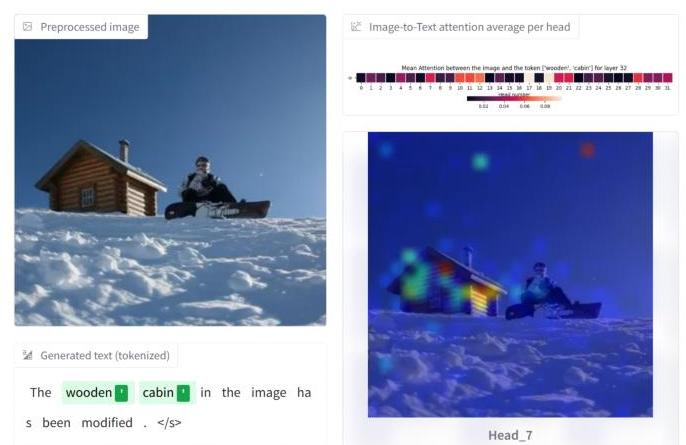
图15:LVLM-Interpret用于展示编辑图像的模型输出。
参考论文:https://arxiv.org/pdf/2505.15644

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)