初识Word2Vec的CBOW模型-从结构到正反向传播数学推导
本文介绍了连续词袋模型(CBOW)的工作原理。CBOW通过上下文词预测中心词,包含三个关键层:1)embeddings层将词索引转换为词向量并求平均;2)线性层将向量映射到词汇表大小;3)Softmax层输出概率分布。损失函数采用负对数似然,通过反向传播更新嵌入矩阵和线性层权重。重点分析了前向传播的计算过程和各层梯度推导,阐明了CBOW不设激活函数的原因。该模型通过上下文词的平均向量预测中心词,能
CBOW(连续词袋模型)
使用上下文词预测中心词
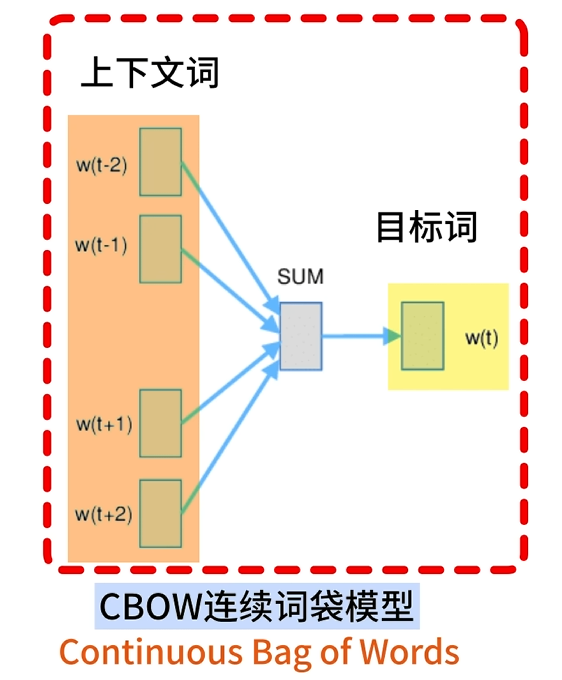
前向传播
embeddings层
embeddings层其实是输入层和投影层的结合,负责接受输入的词索引,并映射成词向量后输出
输入的one−hot编码向量为w1×Vembeddings层是一个V×M的矩阵Q,其中:V:词典中词语个数M:词向量维度Q就是我们最终希望得到的嵌入矩阵 输入的one-hot编码向量为w_{1\times V}\\ embeddings层是一个V\times M的矩阵Q,其中:\\ V:词典中词语个数\\ M:词向量维度\\ Q就是我们最终希望得到的嵌入矩阵\\ 输入的one−hot编码向量为w1×Vembeddings层是一个V×M的矩阵Q,其中:V:词典中词语个数M:词向量维度Q就是我们最终希望得到的嵌入矩阵
一个词的上下文会包含多个词语,这些词语会被同时输入embeddings层,每个词语都会转换成一个词向量
w1Q=c1w2Q=c2⋮wkQ=ckC=[c1,c2,⋯ ,ck]C是序列对应的词向量矩阵,每个元素ci(每一行)对应一个词的word embedding输入embeddings层k个上下文词,得到k个对应的词向量需要对多个上下文词进行统一表示:h=1k∑i=1kci w_1Q = c_1 \\ w_2Q = c_2\\ \vdots\\ w_kQ = c_k\\ C = [c_1,c_2,\cdots,c_k]\\ C是序列对应的词向量矩阵,每个元素c_i(每一行)对应一个词的word\ embedding\\ 输入embeddings层k个上下文词,得到k个对应的词向量\\ 需要对多个上下文词进行统一表示:\\ h = \frac{1}{k}\sum_{i=1}^{k}c_i w1Q=c1w2Q=c2⋮wkQ=ckC=[c1,c2,⋯,ck]C是序列对应的词向量矩阵,每个元素ci(每一行)对应一个词的word embedding输入embeddings层k个上下文词,得到k个对应的词向量需要对多个上下文词进行统一表示:h=k1i=1∑kci
embeddings层的输出结果就是:将语义信息平均的向量h
embeddings层的本质就是一个查找表(look up table),因为其每一行都对应着一个词向量(如图所示)
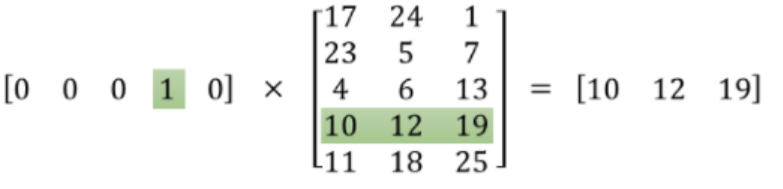
优点
- embeddings层是可训练的,也就是说每一行对应的词向量可以更新,使最终词与词之间的语义关系能更好的表示
- 可以不进行矩阵运算,仅进行查表操作,效率高很多
线性层/输出层
特点:不设置激活函数
前面的embeddings层输入进来的向量h∈R1×M线性层的输出的结果是一个词向量v∈R1×V所以线性层的权重矩阵W∈RM×Vv1×V=h⋅Wv=[u1,u2,⋯ ,uV]uj=WjThWj:线性层权重矩阵的第i行线性层输出U=[u1,u2,⋯ ,um] 前面的embeddings层输入进来的向量h \in R^{1\times M} \\ 线性层的输出的结果是一个词向量v \in R^{1\times V} \\ 所以线性层的权重矩阵W \in R^{M\times V} \\ v_{1\times V} =h\cdot W\\ v = [u_1,u_2,\cdots,u_V] \\ u_j = W_j^Th\\ W_j:线性层权重矩阵的第i行\\ 线性层输出U = [u_1,u_2,\cdots,u_m] 前面的embeddings层输入进来的向量h∈R1×M线性层的输出的结果是一个词向量v∈R1×V所以线性层的权重矩阵W∈RM×Vv1×V=h⋅Wv=[u1,u2,⋯,uV]uj=WjThWj:线性层权重矩阵的第i行线性层输出U=[u1,u2,⋯,um]
为什么CBOW中不设置激活函数Tanh或者ReLU呢(?)
LLNM中设置激活函数(第一层感知机)是为了让预测下一个词变得更准确- 但是
CBOW中,我们只是想得到嵌入矩阵Q,然后进行正常的反向传播更新Q和W就可以- 并且embeddings层输出时,是进行了求平均向量这步线性操作,如果使用了非线性的激活函数,会破坏词向量之间的语义关系
Softmax层
将线性层的输出向量转换为概率分布
P(yj∣context)=exp(uj)∑i=1Vexp(ui) P(y_j | context) = \frac{exp(u_j)}{\sum_{i=1}^{V}exp(u_i)} P(yj∣context)=∑i=1Vexp(ui)exp(uj)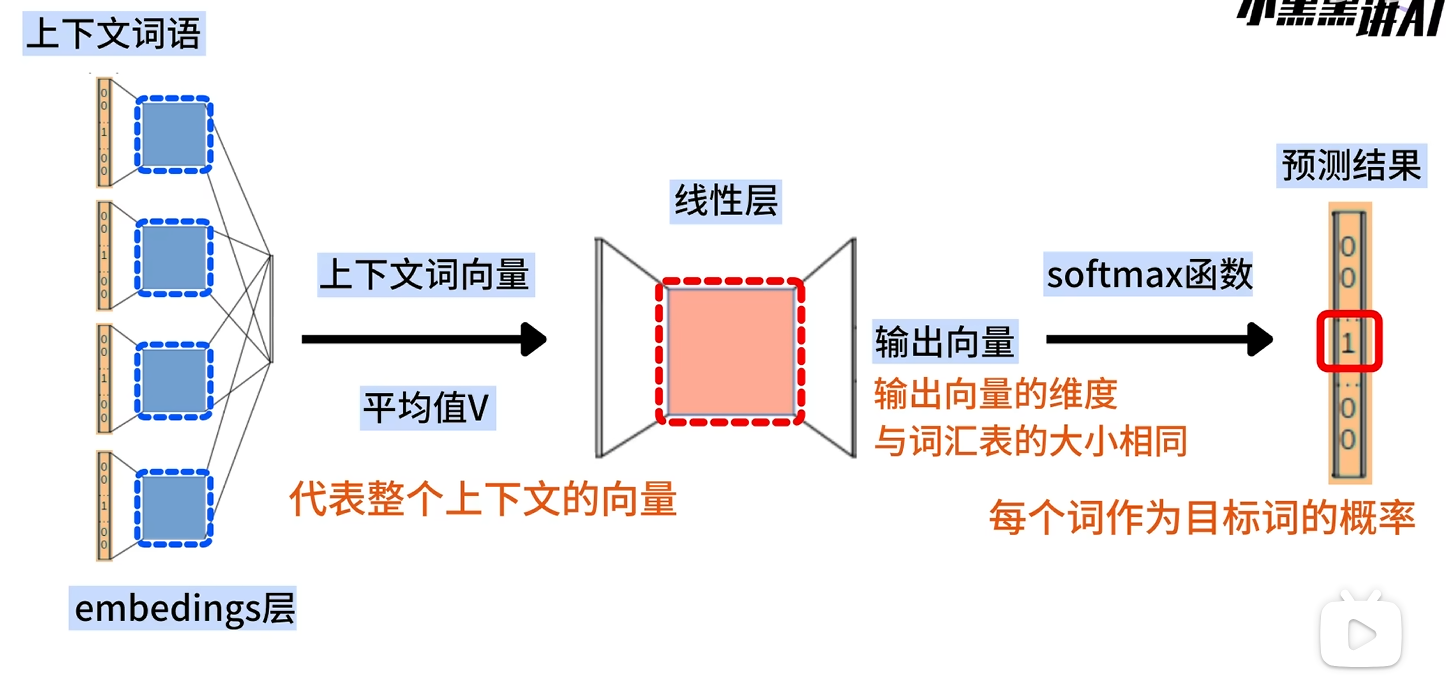
损失函数
L=−logP(wt∣wc)=−logPtruewt:中心词wc:所有上下文词Ptrue:Softmax输出的对应目标词位置的概率 L = -logP(w_t | w_c) = -logP_{true} \\ w_t:中心词\\ w_c:所有上下文词\\ P_{true}:Softmax输出的对应目标词位置的概率 L=−logP(wt∣wc)=−logPtruewt:中心词wc:所有上下文词Ptrue:Softmax输出的对应目标词位置的概率
使用mini-batch进行训练:
L=−1B∑i=1BlogP(wt(i)∣wc(i))B:Batch_size;一个Batch的样本数(i):第i个样本 L = -\frac{1}{B}\sum_{i=1}^{B}logP(w_t^{(i)}|w_c^{(i)}) \\ B:Batch\_size;一个Batch的样本数\\ ^{(i)}:第i个样本 L=−B1i=1∑BlogP(wt(i)∣wc(i))B:Batch_size;一个Batch的样本数(i):第i个样本
反向传播
先回顾一下前向传播;embeddings层输出:h=1V∑i=1Vwi⋅Q线性层:uj=WjThU=[u1,u2,⋯ ,um]Softmax层:pj=P(wj∣context)=exp(uj)∑i=1Vexp(ui) 先回顾一下前向传播;\\ embeddings层输出:h = \frac{1}{V}\sum_{i=1}^{V}w_i\cdot Q \\ 线性层:u_j = W_j^Th\\ U = [u_1,u_2,\cdots,u_m]\\ Softmax层:p_j = P(w_j|context) = \frac{exp(u_j)}{\sum_{i=1}^{V}exp(u_i)}\\ 先回顾一下前向传播;embeddings层输出:h=V1i=1∑Vwi⋅Q线性层:uj=WjThU=[u1,u2,⋯,um]Softmax层:pj=P(wj∣context)=∑i=1Vexp(ui)exp(uj)
对于损失函数:
E=−logP(wt∣wc)=−log(exp(ut)∑i=1Vexp(ui))=−log(exp(WtT⋅h)∑i=1Vexp(WiT⋅h))=−(WtT⋅h−log∑i=1Vexp(WiT⋅h))=−WtT⋅h+log∑i=1Vexp(WiT⋅h)=−WtT⋅∑i=1Vwi⋅QV+log∑i=1Vexp(WiT⋅∑i=1Vwi⋅Q)V E = -logP(w_t | w_c)\\ =-log(\frac{exp(u_{t})}{\sum_{i=1}^{V}exp(u_i)})\\ = -log(\frac{exp(W^T_{t}\cdot h)}{\sum_{i=1}^{V}exp(W_i^T\cdot h)})\\ =-(W_t^T\cdot h - log\sum_{i=1}^{V}exp(W_i^T\cdot h))\\ =-W_t^T\cdot h + log\sum_{i=1}^{V}exp(W_i^T\cdot h)\\ =-\frac{W_t^T\cdot \sum_{i=1}^{V}w_i\cdot Q}{V}+log\sum_{i=1}^{V}\frac{exp(W_i^T\cdot \sum_{i=1}^{V}w_i\cdot Q)}{V} E=−logP(wt∣wc)=−log(∑i=1Vexp(ui)exp(ut))=−log(∑i=1Vexp(WiT⋅h)exp(WtT⋅h))=−(WtT⋅h−logi=1∑Vexp(WiT⋅h))=−WtT⋅h+logi=1∑Vexp(WiT⋅h)=−VWtT⋅∑i=1Vwi⋅Q+logi=1∑VVexp(WiT⋅∑i=1Vwi⋅Q)
计算梯度
首先是对线性层的权重矩阵W求梯度:对当前的中心词wt∇Wt=∂E∂Wt=∂∂Wt(−WtT⋅h+log∑i=1Vexp(WiT⋅h))=−h+∂∂Wtexp(WtT⋅h)∑i=1Vexp(WiT⋅h)=−h+exp(WtT⋅h)⋅h∑i=1Vexp(WiT⋅h)=−h+pt⋅h=(pt−1)⋅h对其他上下文词wc∇Wc=∂E∂Wc=∂∂Wc(−WtT⋅h+log∑i=1Vexp(WiT⋅h))=pc⋅h可以得到一个统一形式:∇W=(pi−yi)⋅h (yi=1,当i=t) 首先是对线性层的权重矩阵W求梯度:\\ 对当前的中心词w_t\\ \nabla_{W_t} = \frac{\partial E}{\partial W_t}=\frac{\partial}{\partial W_t}(-W_t^T\cdot h + log\sum_{i=1}^{V}exp(W_i^T\cdot h))\\ = -h +\frac{\frac{\partial}{\partial W_t}exp(W_t^T\cdot h)}{\sum_{i=1}^{V}exp(W_i^T\cdot h)} = -h+\frac{exp(W_t^T\cdot h)\cdot h}{\sum_{i=1}^{V}exp(W_i^T\cdot h)} = -h+p_t\cdot h = (p_t-1)\cdot h\\ 对其他上下文词w_c\\ \nabla_{W_c} = \frac{\partial E}{\partial W_c}=\frac{\partial}{\partial W_c}(-W_t^T\cdot h + log\sum_{i=1}^{V}exp(W_i^T\cdot h))\\ =p_c\cdot h\\ 可以得到一个统一形式:\\ \nabla_{W} = (p_i-y_i)\cdot h\ \ (y_i=1,当i=t) 首先是对线性层的权重矩阵W求梯度:对当前的中心词wt∇Wt=∂Wt∂E=∂Wt∂(−WtT⋅h+logi=1∑Vexp(WiT⋅h))=−h+∑i=1Vexp(WiT⋅h)∂Wt∂exp(WtT⋅h)=−h+∑i=1Vexp(WiT⋅h)exp(WtT⋅h)⋅h=−h+pt⋅h=(pt−1)⋅h对其他上下文词wc∇Wc=∂Wc∂E=∂Wc∂(−WtT⋅h+logi=1∑Vexp(WiT⋅h))=pc⋅h可以得到一个统一形式:∇W=(pi−yi)⋅h (yi=1,当i=t)
对embeddings层的嵌入矩阵Q求梯度:∇Q=∂E∂U∂U∂h∂h∂Q=(pi−yi)⋅Wi⋅∂∂Q(1V∑i=1Vwi⋅Q)=1V((pi−yi)⋅Wi⋅∑i=1Vwi)因为wi是one−hot编码得到的二进制向量∑i=1Vwi相当于是一个长度为V的全1向量所以得到最终的梯度:∇Q=1V(pi−yi)⋅Wi 对embeddings层的嵌入矩阵Q求梯度:\\ \nabla_Q = \frac{\partial E}{\partial U}\frac{\partial U}{\partial h}\frac{\partial h}{\partial Q}\\ =(p_i-y_i)\cdot W_i\cdot \frac{\partial}{\partial Q}(\frac{1}{V}\sum_{i=1}^{V}w_i\cdot Q )\\ =\frac{1}{V}((p_i-y_i)\cdot W_i\cdot \sum_{i=1}^{V}w_i) \\ 因为w_i是one-hot编码得到的二进制向量 \\ \sum_{i=1}^{V}w_i相当于是一个长度为V的全1向量\\ 所以得到最终的梯度:\\ \nabla_Q = \frac{1}{V}(p_i-y_i)\cdot W_i 对embeddings层的嵌入矩阵Q求梯度:∇Q=∂U∂E∂h∂U∂Q∂h=(pi−yi)⋅Wi⋅∂Q∂(V1i=1∑Vwi⋅Q)=V1((pi−yi)⋅Wi⋅i=1∑Vwi)因为wi是one−hot编码得到的二进制向量i=1∑Vwi相当于是一个长度为V的全1向量所以得到最终的梯度:∇Q=V1(pi−yi)⋅Wi

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)