GLaMoR:使用图语言模型检查OWL本体一致性的方法
语义推理旨在从现有知识中推导出新知识,OWL本体提供了一个标准化的框架来组织信息。语义推理中的一个关键挑战是验证本体的一致性。然而,最先进的推理器计算成本高昂,并且随着本体规模的增长,其效率会下降。虽然经典机器学习模型已被用于一致性检查,但它们难以捕捉本体内的复杂关系。大型语言模型(LLMs)在简单推理任务中表现出有希望的结果,但在结构化推理方面表现不佳。最近引入的图语言模型(GLM)提供了一种同
Justin Mücke, Ansgar Scherp
乌尔姆大学
乌尔姆,德国
firstname.lastname@uni-ulm.de
摘要
语义推理旨在从现有知识中推导出新知识,OWL本体提供了一个标准化的框架来组织信息。语义推理中的一个关键挑战是验证本体的一致性。然而,最先进的推理器计算成本高昂,并且随着本体规模的增长,其效率会下降。虽然经典机器学习模型已被用于一致性检查,但它们难以捕捉本体内的复杂关系。大型语言模型(LLMs)在简单推理任务中表现出有希望的结果,但在结构化推理方面表现不佳。最近引入的图语言模型(GLM)提供了一种同时处理图结构数据和文本的方法。本文提出了GLaMoR(用于推理的图语言模型),这是一个推理管道,将OWL本体转换为图结构数据,并调整GLM架构以进行一致性检查。我们在NCBO BioPortal存储库的本体上评估了GLaMoR,将其转换为适合模型输入的三元组。我们的结果显示,GLM优于所有基线模型,在达到95%准确率的同时比经典推理器快20倍。代码可在以下地址获取:HTTPS://GITHUB.COM/ JustiNMEECKE/GLAMoR
索引术语—语义网、OWL、一致性检查。
I. 引言
随着知识表示和推理系统复杂性的增加,本体在各种领域中起着至关重要的作用,例如生物医学专家知识。Web本体语言(OWL)1{ }^{1}1 是广泛采用的本体表示标准,允许描述概念及其之间的关系。OWL为基于本体的各种任务提供了稳定的基石。OWL 2 [1] 基于SROTQ\mathcal{S R O T Q}SROTQ [2] 描述逻辑,支持复杂的推理,同时保持逻辑一致性。为了从这些本体中推导额外的知识,语义推理器通过逻辑蕴涵推断新的事实。这些推理器对于分类、查询回答和一致性检查等关键任务至关重要,通过利用形式逻辑系统进行精确和可靠的推断。一个突出的例子是HermiT [3],一个符合OWL 2的推理器,它使用超表格算法高效地执行推理任务。它在一致性检查运行时间上优于许多经典推理器[4]。
尽管像HermiT这样的推理器取得了进展,但由于在大规模复杂本体上进行推理的高计算成本[5],可扩展性仍然是一个重大挑战。为了解决这些限制,研究人员探索了替代方法,从传统的语义推理转向机器学习范式。一种尝试将一致性检查视为二元分类问题,其中训练分类器以区分一致和不一致的本体[5]。然而,这种方法仅关注A-Box一致性,而忽略了T-Box一致性。另一条研究路线是使用强化学习在底层知识图结构上进行推理以执行问答(QA)任务[6]-[9]。这种方法类似于A-Box推理,因为重点在于发现隐含关系。例如,给定一个包含事实(Freddy Mercury,singer-of,Queen)和(Jer Bulsara,mother-of,Freddy Mercury)的知识图,模型应该推断出Jer Bulsara是Queen乐队歌手的母亲[10]。此外,人们还尝试使用大型语言模型(LLMs)进行问答推理。虽然语义推理器基于明确定义的逻辑规则工作,LLMs是语言驱动的,依赖于文本中的统计模式而不是形式公理。研究表明,虽然LLMs可以处理知识图中短距离的推理,例如上述示例中的两步推理,但当任务涉及长距离连接时,其性能会下降[10]。图语言模型(GLMs)[11]作为一种潜在解决方案出现,将文本解释能力与图神经网络中使用的注意力机制相结合。这些模型在诸如知识图中实体间关系分类等任务中表现出成功,表明它们可以适应语义推理任务,例如当被视为二元图分类问题时的本体一致性检查。这项工作提出了一种新颖的图语言模型推理(GLaMoR)管道,该管道通过调整提出的GLM架构将数据转换并训练推理模型以应用于本体一致性检查任务。我们的贡献包括:
- 一种本体一致性检查管道GLaMoR,调整图语言模型[11]以支持序列分类。GLaMoR将一致性检查视为图分类任务。我们考虑T5-base和T5-small作为基础语言模型。
1{ }^{1}1 https://www.w3.org/OWL/
- 我们发布了一个新型的本体模块一致性检查数据集,既包括逻辑上一致的也包括不一致的数据点。为了引入不一致的数据点,我们根据14个反模式向本体中注入公理[12]。
-
- 我们将GLaMoR与几种经典和现代基线进行了比较,发现GLMs的表现优于它们。作为经典基线,我们使用了逻辑回归[13]、随机森林[14]、SVM[15]、朴素贝叶斯[16]以及应用于本体平均池化嵌入的WideMLP[17]。我们还与现代模型进行了比较,包括PRODIGY[18](另一种图基础模型)、微调后的ModernBERT[19]、LongT5[20]以及零样本设置下的Llama3[21]模型。
-
- 我们比较了机器学习模型的总运行时间,即训练时间和测试集上的推理时间,与语义推理器HermiT在测试集上进行一致性检查的运行时间。虽然HermiT耗时122小时,最慢的机器学习模型仅需11小时完成训练。
-
- 我们通过从训练数据中排除某一种注入的不一致性来进行鲁棒性研究,以评估GLM的泛化能力。我们得出结论,模型对简单的不一致性原因具有鲁棒性,其中全局设置下的GLM总体上是最鲁棒的。
II. 相关工作
本节首先重申OWL和本体推理及模块化的核心概念,提供了关于本体嵌入的见解,并介绍了图基础模型和机器学习推理的信息。
A. Web本体语言
OWL是一种由万维网联盟(W3C)监督开发的形式语言2{ }^{2}2。它旨在建模各类对象间的复杂关系[22],例如,我们可以公理化定义一所大学的结构:首先定义类“Class: Professor”,“Class: Student”和“Class: Course”。连同关系“ObjectProperty: teaches”和“ObjectProperty: enrolledIn”以及个体“Individual: Dr.Smith, Types: Professor”,“Individual: Alice, Types: Student”和“Individual: AICourse, Types: Course”,我们可以建模为:“Dr.Smith teaches AICourse, Alice enrolledIn AICourse”。最新版本OWL 2与SROIQ\mathcal{S} \mathcal{R O} \mathcal{I} \mathcal{Q}SROIQ描述逻辑一样表达性强[2]。OWL建立在资源描述框架(RDF)之上,并主要使用RDF的XML语法进行表示。它由关键组件组成,如类、类间关系、类实例、属性和限制条件[23]。此外,OWL中的本体可分为三个主要部分:1) A-Box,2) T-Box,和3) R-Box。A-Box包含断言组件,处理有关个体的断言,
如“对象A,实例,类C”。另一方面,T-Box处理概念断言。RBox,不是所有本体都包含的部分,处理关系间的关系。这些本体构成了语义推理的基础。
B. 本体推理和模块化
由于专家构建的本体仍存在错误空间,因此必须设计工具以自动验证其结构和逻辑完整性。此外,我们希望从现有的本体中推断出新知识。基于这些需求,出现了四个主要的推理问题:(1) 本体可满足性检查,(2) 概念可满足性检查,(3) 概念子类检查,和 (4) 实例检查。由于这些问题可以归结为本体可满足性检查,因此被称为语义推理器的工具主要用于执行此任务[24]。语义推理器是自动化推理工具,确保一致性、推断关系并验证数据是否符合本体。这些问题对于语义推理,尤其是在语义网的背景下尤为重要,其中像Pellet[25]或HermiT[3]这样的推理器被用来确保大规模知识库的连贯性和功能性。为了进行推理,Pellet使用表格算法从由图和标签函数组成的本体中构建树模型。通过扩展规则构建图时,如果在此过程中出现任何冲突,则识别出不一致性。HermiT通过引入超表格演算改进了这一概念,从而从扩展机制中去除了非确定性行为。另一个推理器是RDFox[26]。它使用Datalog,一种基于规则的查询语言,在RDF数据集上执行推理任务。Datalog规则采用逻辑蕴涵的形式,如H←B1∧…∧BkH \leftarrow B_{1} \wedge \ldots \wedge B_{k}H←B1∧…∧Bk,其中头HHH在所有条件BiB_{i}Bi成立时被推断。RDFox通过迭代应用这些规则从OWL本体中推导出新事实。由于机器学习范式的使用对本体大小施加了约束,我们需要一种减少本体总大小的方法。本体模块化的目的是将给定的本体O\mathcal{O}O划分为模块M={M1,…,Mn}\mathcal{M}=\left\{\mathcal{M}_{1}, \ldots, \mathcal{M}_{n}\right\}M={M1,…,Mn}。每个模块本身应自包含、一致且主题集中[27]。已知的本体模块化方法包括PATO[28]和OAPT[29]。PATO通过创建代表OWL本体中元素依赖关系的图结构工作。然后将该图划分为本体元素集,作为创建模块的基础。OAPT利用基于种子的聚类找到不同模块的根节点,并迭代扩展这些根节点。
C. 本体嵌入模型
对于许多机器学习任务来说,将提供的数据嵌入到nnn维向量空间中是至关重要的。对于文本和图,嵌入应确保共现词或相邻节点具有相似的向量表示。在OWL本体中,维持语义意义同样重要。如果两个对象在语义上彼此相关,则它们的向量也应接近。最初的尝试受知识图(KGs)嵌入的启发。这包括翻译模型、语义匹配模型、神经网络模型和路径模型[30]。翻译模型通过两个实体之间的距离衡量事实的合理性。特别是TransE[31]在同一空间中表示实体和关系,并力求保证如果(s,r,o)(s, r, o)(s,r,o)是KG的一部分,则hs+hr∼hoh_{s}+h_{r} \sim h_{o}hs+hr∼ho在向量空间中成立。语义匹配模型依赖语义相似性来定义评分函数。这包括DistMult[32],它专注于复数值嵌入,使其能够捕获对称和反对称关系。神经网络模型利用深度学习模型的表征学习能力。ConvE[33]使用二维卷积预测KG中缺失的链接。RDF2Vec[34]是基于路径的方法之一,它依赖随机游走生成节点和边序列,使用跳字模型计算嵌入。由于RDF2Vec难以捕捉OWL本体的逻辑公理,开发了OWL2Vec*[35]。它通过基于推理的物化显式纳入OWL本体的逻辑语义,添加推断出的公理以丰富图。特别地,它创建了一个本体图,结合本体中的三元组、通过使用OWL推理器获得的推理三元组以及链接到实体的文本节点,使文本信息影响嵌入。
D. 图基础模型
受自然语言处理和视觉领域基础模型成功的启发,图基础模型旨在通过对多样化图数据进行预训练来实现图学习的通用化,并启用特定任务的微调[36]。一种这样的架构是图语言模型(GLM)。由于传统语言模型擅长处理文本但无法处理图结构数据,它旨在结合语言模型的文本处理能力和图变换器的图处理能力。GLMs通过用T5模型[38]的参数初始化图变换器[37](GT)实现了这一点,从而将GT的图先验与T5的语言理解能力结合起来[11]。为了将这种架构应用于知识图,输入图必须经过适当的预处理。首先将KG转换为Levi图,这是一种将每条边替换为包含关系名的节点并将该节点连接到原始头尾节点的转换。这种转换有助于通过相对位置编码维护三元组作为标记序列的结构。这些编码保留了转换后图中的关系结构,使GLM能够有效推理组合的图和文本数据。它进一步支持两种操作模式:全局GLM和局部GLM,分别指代所考虑的位置编码。在全局设置下,自注意力机制可以连接任意节点到其他节点,而在局部设置下,自注意力被限制在相同三元组的标记内。另一种基础模型PRODIGY[18]通过引入上下文学习探索了不同的方法。上下文学习使模型可以通过推理提示而非更新权重来推广到新任务。PRODIGY将这一概念扩展到图任务中,通过引入提示图提供统一的方式来表示多样化的图任务。这表明这允许模型无需微调即可跨任务推广。这些提示图包括数据图和任务图。数据图由提示示例组成,任务图通过指示真或假二进制标签的边将每个数据点连接到每个标签。PRODIGY使用基于注意力的GNN传播数据节点和标签节点之间的信息。它推理图数据中的关系并有效推广跨任务而无需微调。该模型作为基于提示模型系列的基线使用,该系列还包括PSP[39]和GraphAny[40]等模型。
E. 机器学习推理
先前的研究调查了经典机器学习模型在本体A-Box一致性检查中的应用,包括决策树、朴素贝叶斯、支持向量机和随机森林[5]。尽管展示了机器学习范式在一致性检查中的潜力,但它们仅关注A-Box,忽略T-Box,即仅考虑关系断言和主体与对象的所有类型断言,而不考虑底层本体的完整语义。另一种方法是使用强化学习进行知识库补全。例如DeepIPath[6]、AttnPath[7]、MINERVA[8]和MultiHopKG[9]等方法训练代理探索知识图中的推理路径。主要目标是优化奖励函数以检索实体之间的多步关系。虽然这种方法在推断隐含事实方面有效,但它们不适合一致性检查。这些方法的主要缺点在于任务的局部性。在问答中,所需信息可以在短关系路径上找到,例如1步或2步推理,而一致性检查需要全局视图所有关系和限制,确保不同公理之间不存在矛盾。这尤其适用于检测基数或存在量化违反的情况,因为这些超越了简单的实体关系。类似地,大型语言模型(LLMs)已被探索用于自然语言中的多步推理任务。LLMs在一步推理中达到合理的准确性,但随着复杂度增加,多步推理变得困难。它们的主要限制是对统计关联的依赖,而不是逻辑推理[10]。因此,基于LLM的推理缺乏明确的逻辑约束表示。由于强化学习方法和LLMs的能力局限于围绕问答主题的局部区域,因此它们也不适合作为基线,因为它们缺乏检测底层知识库中多个步骤之外的限制违反的能力。
III. GLAMOR流水线
在这项工作中,我们将图语言模型架构改编为分类OWL本体是否一致。本节提供了将数据集转换为必要格式的步骤信息。我们使用的数据由BioPortal存储库提供,该存储库通过REST API提供对所有本体的访问。处理检索数据的所有步骤可见于图1。
A. 模块化
BioPortal [41]是一个在线本体库,包含1,143个本体,总共包含15,598,52515,598,52515,598,525个类。由于本体平均包含13,647个类,因此需要某种形式的模块化,因为GLM输入的最大三元组数量受到限制。为此,我们使用本体分析和分区工具(OAPT)[29],它遵循四个关键步骤生成模块:(1)排名本体概念,(2)确定集群头部,(3)分区本体,和(4)生成模块。为了排名本体概念,量化每个概念在本体中的重要性。由此产生的重要概念随后可用作分区的头部,形成分区的基础。在确定集群头部时,重要的是定义所需头部的数量和哪些概念应考虑。为了分区本体,为每个集群头部启动一个分区。每个头部的直接子节点随后放置在相应的集群中,剩余尚未分配到集群的概念使用隶属函数排序到合适的分区。结果概念集群随后用于创建模块,同时确保同一分区内的概念之间的内部关系。
B. 修改
为了训练我们的模型区分一致和不一致的OWL本体,我们需要一组多样化的不一致例子。据我们所知,没有专门的存储库存在,所以我们通过向现有本体中注入公理来生成不一致性。为了避免偏向单一类型的不一致性,我们引入了一个涵盖各种不一致性来源的均衡数据集。我们系统地使用OWL反模式创建不一致性,这些反模式定义了导致逻辑矛盾的公理。通常,模式指的是如何正确形成本体的指南。因此,反模式描述了系统地创建有缺陷本体的方式。具体而言,我们的方法基于之前定义的逻辑模式[12],并引入了三种附加模式。超出范围和超出域反模式发生在个体以违反本体类约束的方式分配给属性时。具体而言,该个体是与属性预期域或范围不相交的类的实例,导致不一致性。循环子类反模式描述了子类中的循环结构。给定一个包含nnn个公理的反模式,我们验证想要引入不一致性的本体是否包含n−1n-1n−1或n−2n-2n−2个这些公理。如果包含,我们注入
缺少的公理以完成反模式。因此,我们可以程序化地创建不一致的本体。定义的反模式可以在表I中看到。
表I
形成逻辑不一致的反模式列表。前几个已在之前定义[12],下面三个由我们引入。
| 名称 | 模式 |
|---|---|
| AndIsOr (AIO) | c1⊑∃R.(c2⊓c3), Disj (c2,c3)\begin{aligned} & c_{1} \sqsubseteq \exists R .\left(c_{2} \sqcap c_{3}\right), \\ & \text { Disj }\left(c_{2}, c_{3}\right) \end{aligned}c1⊑∃R.(c2⊓c3), Disj (c2,c3) |
| EquivalenceIsDifference (EID) | c1≡c3,Disj(c1,c2)c_{1} \equiv c_{3}, \operatorname{Disj}\left(c_{1}, c_{2}\right)c1≡c3,Disj(c1,c2) |
| OnlynessIsLoneliness (OIL) | c1⊑∀R.c2,c1⊑∀R.c3 Disj (c2,c3)\begin{aligned} & c_{1} \sqsubseteq \forall R . c_{2}, c_{1} \sqsubseteq \forall R . c_{3} \\ & \text { Disj }\left(c_{2}, c_{3}\right) \end{aligned}c1⊑∀R.c2,c1⊑∀R.c3 Disj (c2,c3) |
| OILWithInheritence (OILWI) | c1⊑∀R.c3,c2⊑∀R.c4c1⊑c2,Disj(c3,c4)\begin{aligned} & c_{1} \sqsubseteq \forall R . c_{3}, c_{2} \sqsubseteq \forall R . c_{4} \\ & c_{1} \sqsubseteq c_{2}, \operatorname{Disj}\left(c_{3}, c_{4}\right) \end{aligned}c1⊑∀R.c3,c2⊑∀R.c4c1⊑c2,Disj(c3,c4) |
| OILWithPropertyInheritance (OILWPI) | c1⊑∀R2.c3,c1⊑∀R1.c2R1⊑R2,Disj(c2,c3)\begin{aligned} & c_{1} \sqsubseteq \forall R 2 . c_{3}, c_{1} \sqsubseteq \forall R_{1} . c_{2} \\ & R_{1} \sqsubseteq R_{2}, \operatorname{Disj}\left(c_{2}, c_{3}\right) \end{aligned}c1⊑∀R2.c3,c1⊑∀R1.c2R1⊑R2,Disj(c2,c3) |
| UniversityalExistence(UE) | c1⊑∀R.c2,c1⊑∃R.c3 Disj (c2,c3)\begin{aligned} & c_{1} \sqsubseteq \forall R . c_{2}, c_{1} \sqsubseteq \exists R . c_{3} \\ & \text { Disj }\left(c_{2}, c_{3}\right) \end{aligned}c1⊑∀R.c2,c1⊑∃R.c3 Disj (c2,c3) |
| UEWithInheritance1 (UEWL1) | c3⊑∀R.c4,c1⊑∃R.c3c1⊑c2,Disj(c3,c4)\begin{aligned} & c_{3} \sqsubseteq \forall R . c_{4}, c_{1} \sqsubseteq \exists R . c_{3} \\ & c_{1} \sqsubseteq c_{2}, \operatorname{Disj}\left(c_{3}, c_{4}\right) \end{aligned}c3⊑∀R.c4,c1⊑∃R.c3c1⊑c2,Disj(c3,c4) |
| UEWithInheritance2 (UEWL_2) | c2⊑∃R.c4,c1⊑∀R.c3c1⊑c2,Disj(c3,c4)\begin{aligned} & c_{2} \sqsubseteq \exists R . c_{4}, c_{1} \sqsubseteq \forall R . c_{3} \\ & c_{1} \sqsubseteq c_{2}, \operatorname{Disj}\left(c_{3}, c_{4}\right) \end{aligned}c2⊑∃R.c4,c1⊑∀R.c3c1⊑c2,Disj(c3,c4) |
| UEWithPropertyInheritance (UEWPI) | c1⊑∀R2.c3,c1⊑∃R1.c2R1⊑R2,Disj(c2,c3)\begin{aligned} & c_{1} \sqsubseteq \forall R_{2} . c_{3}, c_{1} \sqsubseteq \exists R_{1} . c_{2} \\ & R_{1} \sqsubseteq R_{2}, \operatorname{Disj}\left(c_{2}, c_{3}\right) \end{aligned}c1⊑∀R2.c3,c1⊑∃R1.c2R1⊑R2,Disj(c2,c3) |
| UEWithInverseProperty (UEWIP) | c2⊑∃R−1⋅c1,c1⊑∀R.c3 Disj (c2,c3)\begin{aligned} & c_{2} \sqsubseteq \exists R^{-1} \cdot c_{1}, c_{1} \sqsubseteq \forall R . c_{3} \\ & \text { Disj }\left(c_{2}, c_{3}\right) \end{aligned}c2⊑∃R−1⋅c1,c1⊑∀R.c3 Disj (c2,c3) |
| SumOfSometelsNeverEqualToOne (SOSINETO) | c1⊑∃R.c2,c1⊑∃R.c3c1⊑≤1.T,Disj(c2,c3)\begin{aligned} & c_{1} \sqsubseteq \exists R . c_{2}, c_{1} \sqsubseteq \exists R . c_{3} \\ & c_{1} \sqsubseteq \leq 1 . T, \operatorname{Disj}\left(c_{2}, c_{3}\right) \end{aligned}c1⊑∃R.c2,c1⊑∃R.c3c1⊑≤1.T,Disj(c2,c3) |
| OutOfDomain (OOD) | c1=Domain(p),p(a,b),a∈c2,Disj(c1,c2)\begin{aligned} & c_{1}=\operatorname{Domain}(p), p(a, b), \\ & a \in c_{2}, \operatorname{Disj}\left(c_{1}, c_{2}\right) \end{aligned}c1=Domain(p),p(a,b),a∈c2,Disj(c1,c2) |
| OutOfRange (OOR) | c1=Range(p),p(a,b)b∈c2,Disj(c1,c2)\begin{aligned} & c_{1}=\operatorname{Range}(p), p(a, b) \\ & b \in c_{2}, \operatorname{Disj}\left(c_{1}, c_{2}\right) \end{aligned}c1=Range(p),p(a,b)b∈c2,Disj(c1,c2) |
| CyclicSubClass (CSC) | c1⊑c2,c2⊑c3,c3⊑c1\begin{aligned} & c_{1} \sqsubseteq c_{2}, c_{2} \sqsubseteq c_{3}, c_{3} \sqsubseteq c_{1} \end{aligned}c1⊑c2,c2⊑c3,c3⊑c1 |
C. 翻译
OAPT生成的模块使用XML/RDF语法保存。由于这种语法包含所有前缀,并且其主要目标不是便于人类阅读,我们将在Manchester语法中翻译这些本体。这种语法主要是为了便于人类阅读,将类和关系的前缀移到本体的顶部,从而提供更简单和更有结构的格式。我们使用Manchester语法中的数据进一步将本体转换为一组三元组(主语,关系,宾语)。这些三元组可以直接用作我们GLM的输入。由于我们想利用语言模型的特性,这些三元组需要形成正确的句子。因此,我们首先删除标识对象来源的前缀,例如RDFs或OWL。此外,我们将结构翻译成英文。示例见C节
D. 嵌入
由于如逻辑回归和PRODIGY等模型需要本体的嵌入作为输入,我们使用OWL2Vec* [35]嵌入我们的模块。为了嵌入OWL本体,OWL2Vec*遵循几个步骤:(1)提取RDF图,(2)在图上进行随机游走,(3)提取词汇信息,(4)创建结构和词汇文档,(5)合并文档和(6)训练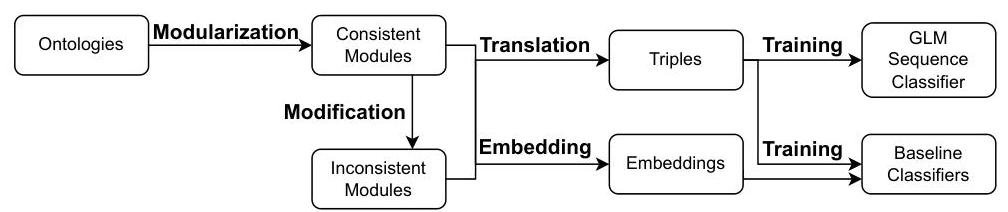
图1. GLaMoR流程图,展示获取和预处理数据并用其训练图语言模型(GLM)的过程。
使用组合文档作为输入训练word2vec模型。为了提取RDF图,他们根据W3C提供的映射转换简单公理,并将复杂公理拆分为多个三元组。词汇信息包含本体中存在的标签和注释信息。通过在RDF图上进行随机游走,他们创建了由实体URI组成的句子,而词汇文档包含由单词组成的句子。这些的组合可以用于应用NLP方法进行嵌入。在这种情况下,使用word2vec [42],可以通过改变游走长度、上下文窗口和嵌入大小进行微调。
E. 训练
使用每个模块的三元组序列,以及包含序列是否一致的标签,我们训练一个GLM进行二元分类。因此,我们需要调整提出的GLM架构,因为它最初是为了进行掩码令牌预测 [11] 设计的。我们通过调整模型的输出,不是预测单个输入令牌的logits,而是输出所有logits的平均值来实现这一点。此外,我们对嵌入进行均值池化,并将其用作逻辑回归的输入,这作为我们实验的基线。我们还使用OWL2Vec*创建的嵌入训练一个PRODIGY模型和一个WideMLP,以与GLM的性能进行比较。最后,我们使用三元组作为连续文本来微调一个LongT5和一个ModernBERT模型。此外,我们在零样本设置下使用一个Llama3模型。Llama3的提示可以在D节找到
IV. 实验装置
我们描述了我们的实验装置,包括数据集和预处理统计、超参数优化、过程和使用的指标。
A. 数据集
由于本文旨在创建基于OWL本体一致性的二元分类模型,我们需要一个数据集,该数据集1)由OWL本体组成,2)包含一致和不一致的数据点。此外,我们希望数据集包含尽可能多的不同种类的关系和结构。因此,我们决定不包括像DBpedia 3{ }^{3}3 这样的数据集,因为在其他作品 [5] 中使用过,它主要由知识图结构组成,几乎没有本体约束,使得逻辑一致性检查的意义较小。由于没有任何现有数据集提供结构化的OWL本体和已知的不一致性,我们构建了自己的数据集来填补这一空白。作为数据集的基础,我们使用了NCBO BioPortal存储库 [41] 提供的本体。我们能够访问1,054个提供的本体,总共有 15,604,43715,604,43715,604,437 个类和 36,28636,28636,286 个属性。有关这些本体的更多统计信息,请参见表II。由于GLM限制了可以作为输入使用的最大序列长度,我们需要减小这些本体的大小。应用第III-A节中描述的模块化方法,我们能够将本体转换为7,505个一致模块。平均而言,单个本体可以分为7.74个模块。更多详细信息请参阅A节。在表II中,我们还可以看到由于模块化,类别的中位数减少了 29.82%29.82 \%29.82%,属性的中位数减少了 83.33%83.33 \%83.33%. 此外,使用第III-B节中定义的修改规则,我们能够创建19,902个不一致模块。有关注入了哪些反模式的详细信息,请参阅B节。
表II
NCBO BioPORTAL本体中的OWL类和属性数量及其在模块中的分解。
| 1,054个本体 | 中位数 | 平均值 | 标准差 |
|---|---|---|---|
| OWL类 | 295.00 | 10,039.9910,039.9910,039.99 | 53,620.5653,620.5653,620.56 |
| 属性 | 12.00 | 119.07 | 2132.41 |
| 7,505个模块 | 中位数 | 平均值 | 标准差 |
| OWL类 | 210.00 | 1,770.571,770.571,770.57 | 11,391.9211,391.9211,391.92 |
| 属性 | 2.00 | 27.03 | 621.40 |
B. 预处理
在将数据点提交到管道之前,我们执行了一些预处理步骤。下载的本体包含旨在提高人类可读性的公理。由于我们只对底层本体的语义感兴趣,我们排除了这些公理。这包括像SKOS和OBO公理这样的注释公理,它们主要用于链接本体之间的知识,以及旨在提高可读性的描述和标签公理。
C. 超参数优化
首先,我们使用OWL2Vec*算法创建了嵌入,该算法的嵌入大小为100,训练底层Word2Vec模型的迭代次数为10次
3{ }^{3}3 https://www.dbpedia.org/
窗口为5。为了优化决策树、逻辑回归、随机森林、SVM和朴素贝叶斯的参数,我们对各自的参数进行了网格搜索。对于每个模型,我们使用85%的数据进行10折交叉验证,并根据剩余15%的数据上的准确性选择最佳模型。决策树在最大深度为5、最小样本叶子为5、最小样本分裂为20且熵为分裂标准时表现最佳。对于逻辑回归,我们得出了正则化强度为0.03359,L2正则化作为惩罚项,最大迭代次数为50,使用L-BFGS优化算法[43]。随机森林在使用最大深度为9、无最大特征、最大叶节点为20和100个估计器时提供了最佳结果。此外,SVM在使用RBF核和代价为1时表现最佳。最后,朴素贝叶斯使用平滑系数为10−910^{-9}10−9。对于以下模型,我们也进行了网格搜索,并使用了(70,15,15)的划分,并选择了测试划分上准确率最高的参数。这种情况下的学习率为1⋅10−41 \cdot 10^{-4}1⋅10−4,权重衰减为5⋅10−45 \cdot 10^{-4}5⋅10−4,权重参数设为45。当使用WideMLP时,我们发现当学习率设为5⋅10−55 \cdot 10^{-5}5⋅10−5,权重衰减设为0,dropout设为0.5时表现最佳。对于ModernBERT,网格搜索结果得出学习率为1⋅10−51 \cdot 10^{-5}1⋅10−5,权重衰减为1⋅10−41 \cdot 10^{-4}1⋅10−4。LongT5在学习率为5⋅10−55 \cdot 10^{-5}5⋅10−5和权重衰减为0时表现最佳。对于GLMs,根据原论文的指导,我们测试了不同的学习率,最大训练轮数为50轮,并使用提前停止。所有GLMs在学习率为10−410^{-4}10−4时表现最佳。
D. 过程
首先,我们从获取的全部数据点中创建了一个平衡的数据集。由于我们想训练GLM模型,我们还需要遵守模型允许的最大输入序列长度。由于T5模型的序列长度最多为4,096个标记,这是我们用来过滤数据集的阈值。这个过滤是必要的,因为模型必须处理整个本体才能对其进行分类。剩下的数据点,我们平衡了一致和不一致的示例。对于反模式EID、CSC、UE和AIO,我们使用随机采样的一部分,保持它们之间的原始分布不变,因为我们相对于其他模式有更多的这些模式的数据点。最终的示例分布可以在表III中看到。然后我们创建了(70,15,15)的训练/验证/测试划分。为了训练经典的机器学习模型,我们需要模块的图嵌入,因此我们使用OWL2Vec*算法嵌入模块并平均池化特征向量。此外,这些嵌入还用于训练WideMLP以及PRODIGY,后者使用Adam优化器。我们将模块转换为三元组以使用AdamW优化器训练GLM。我们使用局部和全局设置与T5-small和T5-base模型的组合作为基础模型。此外,我们
将三元组组合成带有适当标点的单个文本,以微调LongT5以及ModernBERT模型。我们还使用文本在零样本设置下测试Llama3。我们使用经典推理器HermiT对测试集进行一致性检查,以比较其运行时间与模型的运行时间。
最后,我们进行了一项鲁棒性研究,调查图语言模型在训练期间处理缺失数据的能力。因此,我们根据其基本错误对不一致性进行分组,例如OIL、OILWI和OILWPI被认为是OIL*组。对于每一组,我们再次训练模型,将这些组排除在训练数据之外,并分析测试数据上的准确率、精确率和召回率的变化。
表III
我们根据模块的标记长度进行过滤,丢弃任何长度超过4,096个标记的模块。因此,“总计”反映了符合大小限制的模块数量,“使用”是保留的模块数量。
| 模块数量 | 总计 | 使用 |
|---|---|---|
| 一致模块 | 4,169 | 4,169 |
| 不一致模块 | 10,079 | 4,169 |
| AIO | 1,338 | 538 |
| EID | 3,656 | 1,467 |
| OIL | 1 | 1 |
| OILWI | 1 | 1 |
| OILWPI | 0 | 0 |
| UE | 1,357 | 544 |
| UEWI1 | 63 | 63 |
| UEWI2 | 62 | 62 |
| UEWPI | 4 | 4 |
| UEWIP | 20 | 20 |
| SOSINETO | 6 | 6 |
| OOR | 27 | 27 |
| OOD | 24 | 24 |
| CSC | 3,520 | 1,412 |
E. 指标
我们使用二元准确率、召回率和精确率进行序列分类。准确率衡量模型做出的整体正确预测比例,包括一致和不一致的本体。它提供了一个总体指示,说明模型如何正确分类两类。召回率评估模型识别不一致本体的有效性。它计算实际不一致性中模型正确分类为不一致的比例。高召回率意味着模型在检测不一致性方面表现良好。精确率衡量预测为不一致的本体中有多少确实是不一致的。它反映了模型在分类本体为不一致时的准确性。高精确率对应于模型较少出现假阳性错误。
V. 结果
表IV报告了所考虑模型的准确率、精确率和召回率。我们可以看到,经典机器学习方法的表现相似。其中,SVM的准确率最高,而朴素贝叶斯的精确率和召回率最高。尽管PRODIGY模型在召回率上超过了所有模型,但它的准确率最低。
表IV
模型性能。对于GLMs,“SMALL/BASE”表示T5模型大小。每种度量的最佳机器学习模型结果用粗体表示,第二佳用斜体表示,第三佳用下划线表示。对于度量,报告的是多次运行的平均值。标准差在下标中报告。对于训练和推理时间,仅报告平均值。
| 模型 | 准确率 | 精确率 | 召回率 | 训练时间 | 推理时间 |
|---|---|---|---|---|---|
| 决策树 | 56.11(0.99)56.11_{(0.99)}56.11(0.99) | 56.94(00.79)56.94_{(00.79)}56.94(00.79) | 48.00(08.56)48.00_{(08.56)}48.00(08.56) | 00:00:00.4400: 00: 00.4400:00:00.44 | 0:00:00.000: 00: 00.000:00:00.00 |
| ------ | |||||
| LR | 60.64(0.99)60.64_{(0.99)}60.64(0.99) | 61.89(01.89)61.89_{(01.89)}61.89(01.89) | 57.48(01.66)57.48_{(01.66)}57.48(01.66) | 00:00:00.0200: 00: 00.0200:00:00.02 | 0:00:00.000: 00: 00.000:00:00.00 |
| 随机森林 | 60.50(2.23)60.50_{(2.23)}60.50(2.23) | 61.71(02.49)61.71_{(02.49)}61.71(02.49) | 56.97(02.90)56.97_{(02.90)}56.97(02.90) | 00:00:26.3400: 00: 26.3400:00:26.34 | 0:00:00.010: 00: 00.010:00:00.01 |
SVM | 59.70(1.18)59.70_{(1.18)}59.70(1.18) | 61.47(01.52)61.47_{(01.52)}61.47(01.52) | 54.15(01.52)54.15_{(01.52)}54.15(01.52) | 00:00:01.5600: 00: 01.5600:00:01.56 | 0:00:00.470: 00: 00.470:00:00.47 |
朴素贝叶斯 | 60.64(1.39)60.64_{(1.39)}60.64(1.39) | 61.98(02.33)61.98_{(02.33)}61.98(02.33) | 54.13(02.18)54.13_{(02.18)}54.13(02.18) | 00:00:00.0000: 00: 00.0000:00:00.00 | 0:00:00.000: 00: 00.000:00:00.00 |
PRODIGY | 50.00(0.38)50.00_{(0.38)}50.00(0.38) | 62.19(35.89)62.19_{(35.89)}62.19(35.89) | 98.47(01.95)\mathbf{9 8 . 4 7}_{(01.95)}98.47(01.95) | 00:06:47.3800: 06: 47.3800:06:47.38 | 0:00:13.440: 00: 13.440:00:13.44 |
WideMLP | 61.18(1.68)61.18_{(1.68)}61.18(1.68) | 61.47(01.33)61.47_{(01.33)}61.47(01.33) | 61.18(01.68)61.18_{(01.68)}61.18(01.68) | 00:00:14.6400: 00: 14.6400:00:14.64 | 0:00:00.070: 00: 00.070:00:00.07 |
ModernBERT | 94.27‾(2.09)\underline{94.27}_{(2.09)}94.27(2.09) | 95.82(02.31)95.82_{(02.31)}95.82(02.31) | 92.65(02.40)92.65_{(02.40)}92.65(02.40) | 04:57:40.5704: 57: 40.5704:57:40.57 | 0:04:07.120: 04: 07.120:04:07.12 |
LongT5 | 75.75(3.99)75.75_{(3.99)}75.75(3.99) | 79.36(08.18)79.36_{(08.18)}79.36(08.18) | 72.24(15.17)72.24_{(15.17)}72.24(15.17) | 11:07:55.3011: 07: 55.3011:07:55.30 | 0:04:41.190: 04: 41.190:04:41.19 |
Llama3零样本 | 52.53(0.20)52.53_{(0.20)}52.53(0.20) | 55.48(00.11)55.48_{(00.11)}55.48(00.11) | 40.04(00.23)40.04_{(00.23)}40.04(00.23) | - | 1:13:23.001: 13: 23.001:13:23.00 |
/GLM-small | 86.47(0.97)86.47_{(0.97)}86.47(0.97) | 86.55(02.13)86.55_{(02.13)}86.55(02.13) | 86.67(04.13)86.67_{(04.13)}86.67(04.13) | 04:29:11.3604: 29: 11.3604:29:11.36 | 0:14:32.120: 14: 32.120:14:32.12 |
/GLM-base | 91.26(0.97)91.26_{(0.97)}91.26(0.97) | 93.27(02.18)93.27_{(02.18)}93.27(02.18) | 89.46(01.12)89.46_{(01.12)}89.46(01.12) | 04:27:56.2704: 27: 56.2704:27:56.27 | 0:16:53.060: 16: 53.060:16:53.06 |
gGLM-small | 94.80(0.43)94.80_{(0.43)}94.80(0.43) | 95.28‾(01.18)\underline{95.28}_{(01.18)}95.28(01.18) | 94.68(01.07)94.68_{(01.07)}94.68(01.07) | 05:45:48.1005: 45: 48.1005:45:48.10 | 0:15:30.320: 15: 30.320:15:30.32 |
gGLM-base | 95.13(1.10)\mathbf{9 5 . 1 3}_{(1.10)}95.13(1.10) | 96.10(01.97)\mathbf{9 6 . 1 0}_{(01.97)}96.10(01.97) | 94.17‾(01.97)\underline{94.17}_{(01.97)}94.17(01.97) | 04:28:15.2104: 28: 15.2104:28:15.21 | 0:17:51.300: 17: 51.300:17:51.30 |
HermiT | 100 | 100 | 100 | - | 122:24:32.42122: 24: 32.42122:24:32.42 |
表V
当特定不一致性的家族从训练数据中排除时的模型性能。一个家族由“*”表示,并代表所有具有相同基础不一致性的反模式。
| fGLM-s Pre \begin{gathered} \text { fGLM-s } \\ \text { Pre } \end{gathered} fGLM-s Pre | fGLM-b | gGLM-s | gGLM-b | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 反模式 | 准确率 | 精确率 | 召回率 | 准确率 | 准确率 | 精确率 | 召回率 | 准确率 | 精确率 | 召回率 | 准确率 | 精确率 |
| AIO | 85.21 | 91.14 | 78.16 | 92.44 | 95.58 | 89.08 | 95.31 | 95.84 | 94.77 | 95.62 | 96.45 | 94.77 |
| EID | 83.30 | 90.89 | 74.20 | 91.33 | 95.79 | 86.55 | 95.54 | 97.36 | 93.67 | 95.62 | 98.00 | 93.19 |
| OIL* | 87.36 | 91.13 | 82.91 | 91.65 | 96.30 | 86.70 | 95.31 | 96.43 | 94.14 | 96.02 | 97.70 | 94.30 |
| UE* | 86.24 | 89.09 | 82.75 | 89.66 | 87.18 | 81.80 | 90.30 | 96.36 | 83.86 | 90.93 | 97.43 | 84.17 |
| SOSINETO | 84.81 | 88.34 | 80.37 | 89.74 | 90.49 | 88.92 | 95.31 | 95.40 | 95.25 | 96.26 | 96.80 | 95.72 |
| OO* | 85.05 | 82.64 | 88.92 | 92.36 | 92.27 | 92.56 | 94.83 | 93.95 | 95.88 | 95.23 | 97.66 | 92.72 |
| CSC | 80.12 | 92.82 | 65.50 | 89.82 | 93.15 | 86.07 | 94.83 | 97.64 | 91.93 | 95.54 | 95.71 | 95.41 |
总体而言。另一个与PRODIGY表现相似较差的模型是零样本设置下的Llama3,其准确率和精确率略高于50%,而召回率仅为40%,这是所有模型中最差的召回率。尽管WideMLP比经典模型高出几个百分点,但它仍然落后于LongT5(75%准确率)和ModernBERT,后者是最强的基线。ModernBERT表现出类似于以T5-small作为底层模型的全局GLM的性能,达到了94.27%的准确率。虽然局部GLMs优于经典模型,但它们始终不如全局GLMs。具有T5-base作为底层LLM的全局GLM报告了最高的准确率和召回率。
在运行时间方面,如表IV的最后一列所示,ML模型的运行时间远低于经典推理器的运行时间。虽然经典推理器HermiT花费超过122小时检查测试集中的模块,但训练时间最长的机器学习模型是LongT5,训练时间为11小时。其他模型所需时间更少,除了LongT5外,所有模型的训练时间均不到6小时,而经典模型甚至不足一分钟。
关于我们的鲁棒性分析,我们可以从表V中看到,复杂度较高的模式缺失数据的影响更大。特别是,排除UE家族的模式导致准确率下降最大。另一方面,简单模式如AIO和CSC的准确率几乎不受影响。
VI. 讨论
在本节中,我们讨论结果带来的关键见解、鲁棒性研究的结果、对本工作有效性的威胁以及未来的工作和影响。
A. 关键见解
我们的结果表明,在图语言模型中加入全局注意力机制可以显著提高分类性能。此外,增加底层模型的大小并不一定能提高一致性检查能力。此外,平均池化嵌入很可能不适合此任务,因为它们无法保留实体之间的语义关系。我们的研究结果揭示了图语言模型在应用于一致性检查问题时的潜力。如表IV所示,在使用T5-base作为底层模型的全局设置下,GLM达到了最佳准确率
95.13% 和所有考虑模型中最高的精确度。因此,它将一致本体误分类为不一致的情况最少,仅有3%的不一致本体实际上是正确的本体。同时,使用局部设置的模型表现更差,即使随着底层T5模型尺寸的增加,准确度有所提升。然而,与共享相同基础模型的LongT5相比,局部GLM仍通过10%的准确度优势展示出GLM中使用的图注意力对整体一致性检查能力有重大影响。另一个高性能模型是微调后的ModernBERT,仅被全局GLMs超越。它在发现反模式方面表现出色,达到94.27%的准确度。此外,经典机器学习模型以及依赖本体嵌入的PRODIGY和WideMLP表现明显较差。造成这种不良表现的一个因素可能是嵌入本身未能很好地捕捉结构。很可能,嵌入的平均池化导致了嵌入中包含的语义信息的丢失,从而使得检测不一致性变得困难。尽管召回率接近完美,PRODIGY的50%准确率表明它过度预测了不一致性。在一个平衡的数据集中,一半的数据被错误分类,显示大多数一致实例被标记为不一致。
此外,我们还查看了单个模式的分类情况,发现没有模型特别难以处理任何特定的反模式。如果某个模型的表现优于其他模型,那么其性能差异在测试数据中的所有反模式中都显而易见。
如表IV所示,GLMs花费的时间最长来训练和分类测试集,其中使用T5 base的局部GLM需要六个小时来标记数据并训练模型。将其与HermiT进行比较,HermiT是优化较好的经典推理器之一[4],它花费了122小时来检查测试集的一致性。考虑到我们将自己限制在较小的本体模块上,这仍然是一个显著的改进。全局GLMs提供了最佳的性能与运行时间比率,训练时间不到六小时,却超越了所有其他模型,包括ModernBERT和T5。
B. 鲁棒性研究
查看表V,我们可以看到模型在训练数据中处理缺失数据的能力如何。将全局和局部设置下训练的模型结果进行比较,我们可以看到全局模型总体上比其局部对应物更为稳健。从数据中出现的另一个趋势是,移除UE家族的模式对所有模型的性能影响最大。造成这种情况的原因之一可能是它们是数据中更复杂的模式。此外,它们与其他模式的重叠较少,因为它们是唯一包含通用(∀)(\forall)(∀)和存在(∃)(\exists)(∃)限制的模式。此外,CSC模式对局部模型的性能产生了相当大的影响。这种形式的模式对于局部设置下的模型来说很难处理,因为它们基于延伸超出其注意力范围的循环,例如,CSC包含跨越三个公理的循环,而局部注意力仅覆盖单个公理。这些问题在全局模型的性能中并不明显,这表明它们能够捕捉长距离依赖。总的来说,这些结果表明模型展现出强大的泛化能力,特别是在全局设置下。带有T5-base架构的全局GLM展示了最高的鲁棒性,即使在特定不一致家族未包含在训练中时,仍保持超过90%的准确率。这突显了其学习广泛表示的能力,这些表示对未见过的不一致具有良好的泛化能力。这项分析确认,全局模型不仅在原始准确率上胜出,而且在关键不一致模式缺失时也具有更好的泛化能力。
C. 对有效性构成威胁的因素
我们工作的主要问题是不一致本体的不可用性,因此需要程序化地创建不一致本体。为了充分捕捉图语言模型的能力,一个包含利用OWL 2所有功能的不一致性数据集将提供更好的洞察。尽管如此,本研究中使用的不一致性基于之前在实际应用中反复出现的已识别模式[12]。因此,这项研究仍然提供了一个坚实的调查现代机器学习模型一致性检查能力的方法。另一个问题可能在于本体的选择上,因为所有本体都来自一个与生物医学研究相关的存储库。虽然这可能会引入一些偏差到数据集中,但它们不应影响模型的性能,因为在将数据转换为三元组或嵌入本体时,所有可能链接到特定领域的潜在IRIs都被移除了。
D. 未来工作和影响
尽管我们的工作已经展示了图语言模型在OWL本体一致性检查方面的潜力,但仍需进一步研究以解决关键限制。本研究中的主要挑战之一是不一致本体的可用性和GLMs施加的序列长度限制。为了解决第一个问题,建立一个包含在实际建模场景中出现的真实世界不一致本体的存储库至关重要。这样的数据集将提供两个主要优势:(1)它将允许更精确地评估对现实世界应用的影响,(2)它将捕捉超出本研究中程序化注入的结构化模式之外的更广泛的OWL 2不一致性。此外,值得探索GLM架构内的替代大型语言模型(LLMs)。尽管T5表现出卓越的性能,其主要限制仍然是默认输入大小为512个标记,本研究中手动将其增加了四倍。具有更大上下文窗口或无限输入长度的模型将更具可扩展性,使这种方法能够在传统推理器面临计算成本问题的情况下应用。未来的研究应调查是否进一步增加序列长度会持续提高性能,或者是否替代架构(例如检索增强型或稀疏注意力模型)能更好地处理本体推理中的长序列。
VII. 结论
我们研究了图语言模型(GLMs)在OWL本体一致性检查中的能力,这是确保语义数据逻辑完整性的关键任务。我们开发了一条流水线,将本体转换为更小的模块,然后将这些模块转换为三元组并嵌入向量空间。使用这些数据点,我们训练了多个模型以评估它们在一致性检查中的表现。我们的研究发现表明,GLMs,特别是那些在全球设置下经过训练且具有全局位置编码的模型,优于局部模型以及基于嵌入的模型,如PRODIGY、逻辑回归、随机森林、决策树、SVM和朴素贝叶斯。这种优势归因于全局GLM捕捉整个图中依赖关系的能力,使其在处理复杂的连续性模式时更加有效。此外,全局GLM对先前未见过的不一致性模式最为稳健,例如新的逻辑矛盾或新型反模式。这些结果不仅表明一致性检查不再是语义推理器的专属领域,还表明机器学习模型在提供可扩展、高精度的本体管理替代方案方面显示出巨大的前景。
参考文献
[1] B. C. Grau, I. Horrocks, B. Motik, B. Parsia, P. Patel-Schneider, and U. Sattler, “OWL 2: The next step for OWL,” Journal of Web Semantics, vol. 6, no. 4, pp. 309-322, 2008. Semantic Web Challenge 2006/2007.
[2] I. Horrocks, O. Kutz, and U. Sattler, “The even more irresistible SROIQ.,” Kr, vol. 6, pp. 57-67, 2006.
[3] B. Glimm, I. Horrocks, B. Motik, G. Stoilos, and Z. Wang, “Hermit: An OWL 2 reasoner,” J. Autom. Reason., vol. 53, no. 3, pp. 245-269, 2014.
[4] K. Dentler, R. Cornet, A. ten Teije, and N. de Keizer, “Comparison of reasoners for large ontologies in the OWL 2 EL profile,” Semantic Web, vol. 2, no. 2, pp. 71-87, 2011.
[5] H. Paulheim and H. Stuckenschmidt, “Fast approximate a-box consistency checking using machine learning,” in The Semantic Web. Latest Advances and New Domains - 13th International Conference, ESWC 2016, Heraklion, Crete, Greece, May 29 - June 2, 2016, Proceedings (H. Sack, E. Blomqvist, M. d’Aquin, C. Ghidini, S. P. Ponzetto, and C. Lange, eds.), vol. 9678 of Lecture Notes in Computer Science, pp. 135-150, Springer, 2016.
[6] W. Xiong, T. Hoang, and W. Y. Wang, “Deeppath: A reinforcement learning method for knowledge graph reasoning,” CoRR, vol. abs/1707.06690, 2017.
[7] H. Wang, S. Li, R. Pan, and M. Mao, “Incorporating graph attention mechanism into knowledge graph reasoning based on deep reinforcement learning,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (K. Inui, J. Jiang, V. Ng, and X. Wan, eds.), (Hong Kong, China), pp. 2623-2631, Association for Computational Linguistics, Nov. 2019.
[8] R. Das, S. Dhuliawala, M. Zaheer, L. Vilnis, I. Durugkar, A. Krishnamurthy, A. Smola, and A. McCallum, “Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning,” in 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings, OpenRcview.net, 2018.
[9] X. V. Lin, R. Socher, and C. Xiong, “Multi-hop knowledge graph reasoning with reward shaping,” 2018.
[10] S. Yang, E. Gribovskaya, N. Kassner, M. Geva, and S. Riedel, “Do large language models latently perform multi-hop reasoning?,” 2024.
[11] M. Plenz and A. Frank, “Graph language models,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (L.-W. Ku, A. Martins, and V. Srikumar, eds.), (Bangkok, Thailand), pp. 4477-4494, Association for Computational Linguistics, Aug. 2024.
[12] O. Corcho, C. Roussey, and L. M. Vilches-Blázquez, “Catalogue of antipatterns for formal ontology debugging,” 012009.
[13] D. R. Cox, “The regression analysis of binary sequences,” Journal of the Royal Statistical Society: Series B (Methodological), vol. 20, no. 2, pp. 215-232, 1958.
[14] L. Breiman, “Random forests,” Mach. Learn., vol. 45, no. 1, pp. 5-32, 2001.
[15] B. Schölkopf, K. K. Sung, C. J. C. Burges, F. Girosi, P. Niyogi, T. A. Poggio, and V. Vapnik, “Comparing support vector machines with gaussian kernels to radial basis function classifiers,” IEEE Trans. Signal Process., vol. 45, no. 11, pp. 2758-2765, 1997.
[16] D. D. Lewis, “Naive (bayes) at forty: The independence assumption in information retrieval,” in Machine Learning: ECML-98, 10th European Conference on Machine Learning, Chemnitz, Germany, April 21-23, 1998, Proceedings (C. Nedellec and C. Rouveirol, eds.), vol. 1398 of Lecture Notes in Computer Science, pp. 4-15, Springer, 1998.
[17] L. Galke and A. Scherp, “Bag-of-words vs. graph vs. sequence in text classification: Questioning the necessity of text-graphs and the surprising strength of a wide MLP,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), (Dublin, Ireland), pp. 4038-4051, Association for Computational Linguistics, May 2022.
[18] Q. Huang, H. Ren, P. Chen, G. Kržmanc, D. Zeng, P. Liang, and J. Leskovec, “Prodigy: Enabling in-context learning over graphs,” 2023.
[19] B. Warner, A. Chaffin, B. Clavié, O. Weller, O. Hallström, S. Taghadouini, A. Gallagher, R. Biswas, F. Ladhak, T. Aarsen, N. Cooper, G. Adams, J. Howard, and I. Poli, “Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference,” 2024.
[20] M. Guo, J. Ainslie, D. Uthus, S. Ontanon, J. Ni, Y.-H. Sung, and Y. Yang, “Longt5: Efficient text-to-text transformer for long sequences,” 2022.
[21] M. AI, “Meta-llama-3-8h.” https://huggingface.co/meta-llama/ Meta-Llama-3-8B, 2024.
[22] I. Horrocks, P. F. Patel-Schneider, and F. van Harmelen, “From SHIQ and RDF to OWL: The making of a web ontology language,” Journal of Web Semantics, vol. 1, no. 1, pp. 7-26, 2003.
[23] G. Antoniou and F. v. Harmelen, Web Ontology Language: OWL, pp. 91110. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009.
[24] B. Glimm and Y. Kazakov, Classical Algorithms for Reasoning and Explanation in Description Logics, pp. 1-64. Cham: Springer International Publishing, 2019.
[25] E. Sirin and B. Parsia, “Pellet: An OWL DI, reasoner,” in Proceedings of the 2004 International Workshop on Description Logics (DL2004), Whistler, British Columbia, Canada, June 6-8, 2004 (V. Haarslev and R. Möller, eds.), vol. 104 of CEUR Workshop Proceedings, CEURWS.org, 2004.
[26] Y. Nesov, R. Piro, B. Motik, I. Horrocks, Z. Wu, and J. Banerjee, “RDFOX: A highly-scalable RDF store,” in The Semantic Web - ISWC 2015 (M. Arenas, O. Corcho, E. Simperl, M. Strohmaier, M. d’Aquin, K. Srinivas, P. Groth, M. Dumontier, J. Heflin, K. Thirunarayan, and S. Staab, eds.), (Cham), pp. 3-20, Springer International Publishing, 2015.
[27] A. Algergawy and B. König-Ries, “Partitioning of bioportal ontologies: An empirical study.,” in SWAT4HCLS, pp. 84-93, 2019.
[28] A. Schlicht and H. Stuckenschmidt, “A flexible partitioning tool for large ontologies,” in 2008 IEEE / WIC / ACM International Conference on Web Intelligence, WI 2008, 9-12 December 2008, Sydney, NSW, Australia, Main Conference Proceedings, pp. 482-488, IEEE Computer Society, 2008.
[29] A. Algergawy, S. Babalou, F. Klan, and B. König-Ries, “OAPT: A tool for ontology analysis and partitioning,” in Proceedings of the 19th International Conference on Extending Database Technology, EDBT 2016, Bordeaux, France, March 15-16, 2016, Bordeaux, France, March 15-16, 2016 (E. Pitoura, S. Maabout, G. Koutrika, A. Marian, L. Tanca, I. Manolescu, and K. Stefanidis, eds.), pp. 644-647, OpenProceedings.org, 2016.
[30] R. Biswas, L.-A. Kaffee, M. Cochez, S. Dumbrava, T. E. Jendal, M. Lissandrini, V. Lopez, E. L. Mencía, H. Paulheim, H. Sack, E. K. Vakaj, and G. de Melo, “Knowledge Graph Embeddings: Open Challenges and Opportunities,” Transactions on Graph Data and Knowledge, vol. 1, no. 1, pp. 4:1-4:32, 2023.
[31] A. Bordes, N. Usunier, A. Garcia-Durán, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” in Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS’13, (Red Hook, NY, USA), p. 2787-2795, Curran Associates Inc., 2013.
[32] B. Yang, W. tau Yih, X. He, J. Gao, and L. Deng, “Embedding entities and relations for learning and inference in knowledge bases,” 2015.
[33] T. Dettmers, P. Minervini, P. Stenetorp, and S. Riedel, “Convolutional 2d knowledge graph embeddings,” 2018.
[34] P. Ristoski and H. Paulheim, “RDF2vec: RDF graph embeddings for data mining,” in The Semantic Web - ISWC 2016 (P. Groth, E. Simperl, A. Gray, M. Sabou, M. Krötzsch, F. Lecue, F. Flöck, and Y. Gil, eds.), (Cham), pp. 498-514, Springer International Publishing, 2016.
[35] J. Chen, P. Hu, E. Jimenez-Ruiz, O. M. Holter, D. Antonyrajah, and I. Horrocks, “OWL2vec*: Embedding of OWL ontologies,” 2021.
[36] J. Liu, C. Yang, Z. Lu, J. Chen, Y. Li, M. Zhang, T. Bai, Y. Fang, L. Sun, P. S. Yu, and C. Shi, “Towards graph foundation models: A survey and beyond,” 2024.
[37] V. P. Dwivedi and X. Bresson, “A generalization of transformer networks to graphs,” 2021.
[38] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” 2023.
[39] Q. Ge, Z. Zhao, Y. Liu, A. Cheng, X. Li, S. Wang, and D. Yin, “PSP: Pre-training and structure prompt tuning for graph neural networks,” 2024.
[40] J. Zhao, H. Mostafa, M. Galkin, M. M. Bronstein, Z. Zhu, and J. Tang, “Graphany: A foundation model for node classification on any graph,” CoRR, vol. abs/2405.20445, 2024.
[41] P. L. Whetzel, N. F. Noy, N. H. Shah, P. R. Alexander, C. Nyulas, T. Tudorache, and M. A. Musen, “Bioportal: Enhanced functionality via new web services from the national center for biomedical ontology to access and use ontologies in software applications,” Nucleic Acids Research, vol. 39, no. Web Server issue, pp. W541-W545, 2011. Epub 2011 Jun 14.
[42] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” 2013.
[43] Y. Xiao, Z. Wei, and Z. Wang, “A limited memory bfgs-type method for large-scale unconstrained optimization,” Computers & Mathematics with Applications, vol. 56, no. 4, pp. 1001-1009, 2008.
补充材料
附录A
模块化
从NCBO BioPortal存储库中检索到的1,054个本体,我们将其模块化为7,505个模块。可以从每个本体中提取多少模块可见于图2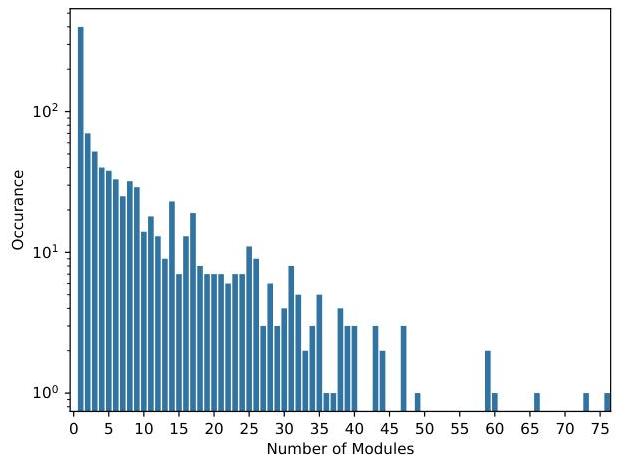
图2. 可分为特定数量模块的本体数量分布。
附录B
修改
为了创建不一致模块,我们在一致模块中注入了公理。对于每个模块,我们尝试完成每个反模式。如果不能通过一次注入完成该模式,则我们尝试通过两次注入完成该模式。每个模式能完成的频率可见于表VI
表VI
通过向7,505个一致模块中注入公理创建的不一致模块数量。一次注入指通过一个公理注入的模式。两次注入指通过两个公理注入。
| 反模式 | 一次注入 | 两次注入 | 总计 |
|---|---|---|---|
| AIO | 673 | 2,487 | 3,160 |
| EID | 2,809 | 3,743 | 6,552 |
| OIL | 3 | 3 | 6 |
| OILWI | 3 | 0 | 3 |
| OILWPI | 0 | 0 | 0 |
| UE | 4 | 3,111 | 3,115 |
| UEWI_1 | 263 | 0 | 263 |
| UEWI_2 | 261 | 0 | 261 |
| UEWPI | 12 | 0 | 12 |
| UEWIP | 37 | 0 | 37 |
| SOSINETO | 76 | 0 | 76 |
| OOD | 36 | 0 | 36 |
| OOR | 39 | 0 | 39 |
| CSC | 6,344 | 0 | 6,344 |
| 总计 | 10,560 | 9,342 | 19,902 |
| 总计;4,096标记 | 10,079 |
附录C
转换
为了利用GLM的语言理解能力,我们将本体转换为英语表达式的三元组。这些转换的示例可以在表VII中看到。
表VII
用于将曼彻斯特语法中的本体转换为英语语言中三元组的翻译规则示例。
| 曼彻斯特语法 | 三元组 |
|---|---|
| 类名 NAME | (“NAME” “is a” “class”) |
| IND 类型 CLASS_NAME | (“IND” “has class” “CLASS_NAME”) |
| CLASS1 不相交 CLASS2 | (“CLASS1” “is disjoint with” “CLASS2”) |
附录D
提示
由于我们想在零样本设置下使用Llama3,我们需要将任务打包成一个单一提示,以给LLM指令以及执行任务所需的信息,即输入。因此,我们将单个提示分为3部分。前缀包括有关任务和信息结构的信息。中间部分包含信息,即文本形式的本体。后缀定义输出应该如何形成。因此,我们的提示如下所示:
- 前缀:"确定以下文本描述的是一个一致的本体。每个句子代表一个单独的三元组。\n\n\backslash n \backslash n\n\n "
-
- 后缀:" \n\n\backslash n \backslash n\n\n 如果是一致的则回答0,如果不一致则回答1。\nAnswer:"
-
- 提示:前缀 + 示例 + 后缀
参考论文:https://arxiv.org/pdf/2504.19023
- 提示:前缀 + 示例 + 后缀

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)