翻译:CarPlanner:用于自动驾驶大规模强化学习的一致性自回归轨迹规划(一)
的训练效率、普通和一致的自回归框架的性能、在强化学习训练中使用反应式和非反应式模型的情况,以及改变时间范围所产生的影响。值得注意的是,在训练轨迹生成器时,我们可以灵活选择使用强化学习(它包含两个部分:交叉熵损失和辅助任务损失。带有模仿学习的生成器损失。损失由三部分组成:策略损失、价值损失和熵损失。,而是分别探索它们各自的特点。诱导出的策略分布(高斯分布的均值和标准差),函数。无模型设置下的训练效率
A. 培训流程
算法 1 概述了 CarPlanner 框架的训练过程。值得注意的是,在训练轨迹生成器时,我们可以灵活选择使用强化学习(RL)或模仿学习(IL),但在本研究中,我们并未同时结合 RL 和 IL,而是分别探索它们各自的特点。损失函数的定义如下。
非反应性转换模型丢失。非反应性转换模型 β 是根据初始状态 s0 训练出来的,用于模拟智能体的轨迹。对于每个数据样本 (s0, s1:N,gt
1: T
对于所有 \( ) \in D \),模型预测的轨迹为 s1:N 1:T =
β(s 0),并且训练目标是使 L1 损失最小化:
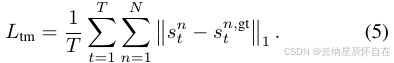
模式选择器损失。它包含两个部分:交叉熵损失和辅助任务损失。交叉熵损失定义为:
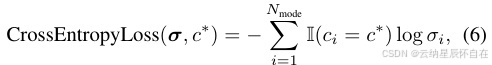
其中 σi 是为模式 ci 分配的分数,Nmode 是候选模式的数量,I 是指示函数。辅助任务损失定义为:
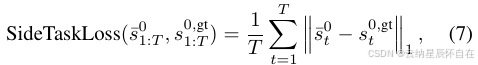
其中 s¯0t 表示输出的自我未来轨迹。
基于强化学习的生成器损失。PPO [31] 损失由三部分组成:策略损失、价值损失和熵损失。策略损失定义为:
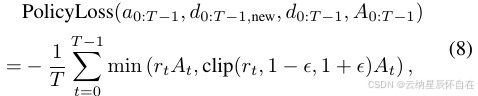

其中比率 rt 由 rt = 给出
Prob(a, dtt, new) / Prob(at, dt), dt, new
并且 dt 和 πold 分别是策略 π 和 πold 在时间步 t 诱导出的策略分布(高斯分布的均值和标准差),函数 Prob(a, d) 计算给定动作 a 在分布 d 下的概率,而 At 是使用 GAE [30] 估计的优势。价值损失和熵损失定义为:
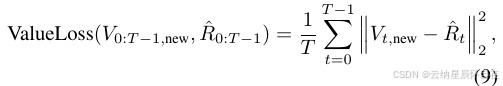
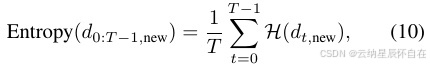
其中 Vt,new 和 R
ˆt 是预测收益和实际收益,
并且 H 表示策略分布 d 的熵。
带有模仿学习的生成器损失。在模仿学习中,生成器会最小化自身规划的轨迹 s01:T 与真实轨迹 s0,gt 之间的轨迹误差。
1:T。损失定义为:
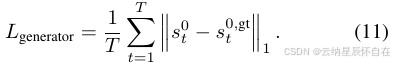
B. 实施细节
模型架构的超参数、PPO 相关参数以及损失权重总结在表 5 中。价值、策略和熵损失的量级分别为 10⁻3、10⁻0 和 10−3 。轨迹生成器以 1 秒间隔生成 8 秒时间范围内的轨迹,对应时间范围 T = 8。在测试期间,这些轨迹被插值到 0.1 秒间隔。规则选择器和模式选择器生成的分数权重设置为 1 : 0.3 的比例。如果自车候选轨迹都不满足规则选择器评估的安全标准,则触发紧急制动。对于 Test14-Random 基准测试,采用 10Hz 的重规划频率,遵循官方 nuPlan 模拟配置。相比之下,对于 Reduced-Val14 基准测试,使用 1Hz 的重规划频率,以确保与 Gen-Drive [18] 进行公平比较。
C. 关于强化学习训练的消融研究
在本部分,我们将研究 CarPlanner 的训练效率、普通和一致的自回归框架的性能、在强化学习训练中使用反应式和非反应式模型的情况,以及改变时间范围所产生的影响。
训练效率。我们将基于模型的框架的效率与 ScenarioNet [24] 进行了比较,ScenarioNet 是一个用于在真实世界数据集上进行无模型强化学习训练的开源平台 [2, 9]。如表 6 所示,Car-Planner 在采样效率方面取得了显著的提升。
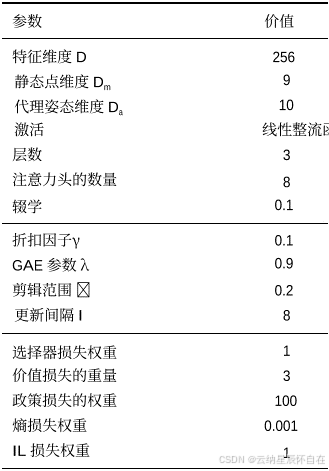
表 5. 模型架构的超参数、PPO 相关参数以及损失权重。

表 6. 无模型设置下的训练效率比较。实验结果基于 Test14-Random 非反应性基准测试得出。
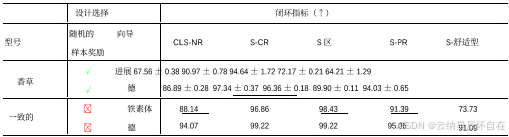
表 7. 不同引导奖励设计下普通与一致自回归框架的对比。实验结果基于 Test14-Random 非反应式基准得出。
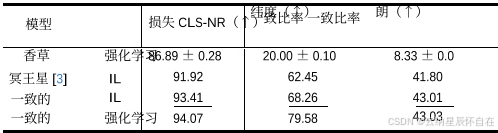
表 8. 一致性比较。实验结果基于 Test14-Random 非反应性基准测试得出。
效率,比 ScenarioNet 高出两个数量级。此外,CarPlanner 不仅在效率方面表现出色,而且在.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)