ICCV 2025 | CoopTrack 震撼发布!清华联手百度,端到端合作感知新突破!
合作序列感知旨在通过融合自车感知数据与其他智能体信息,实现对周围环境的长期全面理解。本文聚焦车-路协同3D多目标跟踪任务,以图像为输入,预测随时间变化的3D边界框集合BtB_{t}Bt,且框的ID在帧间保持一致。每个边界框bti∈Btbti∈Bt包含中心坐标、尺寸、方向、速度及类别标签,定义为btixyzwlhθvxvybtixyzwlhθvxvy。

- 论文标题:CoopTrack: Exploring End-to-End Learning for Efficient Cooperative Sequential Perception
- 作者:Jiaru Zhong, Jiahao Wang, Jiahui Xu, Xiaofan Li, Zaiqing Nie, Haibao Yu
- 作者单位:1 Institute for AI Industry Research, Tsinghua University;2 The Hong Kong Polytechnic University;3 The University of Hong Kong;4 School of Vehicle and Mobility, Tsinghua University;5 Baidu Inc.
- 项目链接:https://github.com/zhongjiaru/CoopTrack
- 论文链接:https://arxiv.org/abs/2507.19239
- 另外,我整理了ICCV 2025计算机视觉相关论文+源码,感兴趣的dd我~
- 论文这里~
2. 【论文速读】
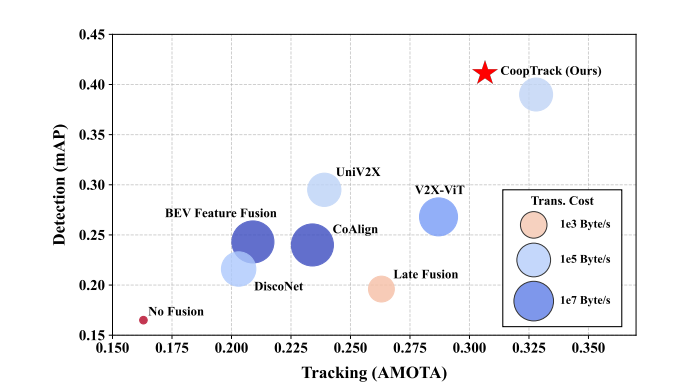
合作感知旨在通过多智能体之间的信息交换来解决单车辆自动驾驶系统的固有局限性。以往的研究主要集中在单帧感知任务上,然而,更具挑战性的合作序列感知任务(如合作3D多目标跟踪)尚未得到深入研究。为此,研究者提出了CoopTrack,这是一个用于合作跟踪的完全实例级端到端框架,其特点是具有可学习的实例关联,与现有方法有本质区别。CoopTrack传输稀疏的实例级特征,在保持低传输成本的同时显著增强了感知能力。此外,该框架包括两个关键组件:多维特征提取模块以及跨智能体关联与聚合模块,它们共同实现了具有语义和运动特征的全面实例表示,以及基于特征图的自适应跨智能体关联与融合。在V2X-Seq和Griffin数据集上的实验表明,CoopTrack取得了优异的性能。具体而言,它在V2X-Seq上实现了最先进的结果,mAP为39.0%,AMOTA为32.8%。
3.【背景及相关工作】
3.1 研究背景
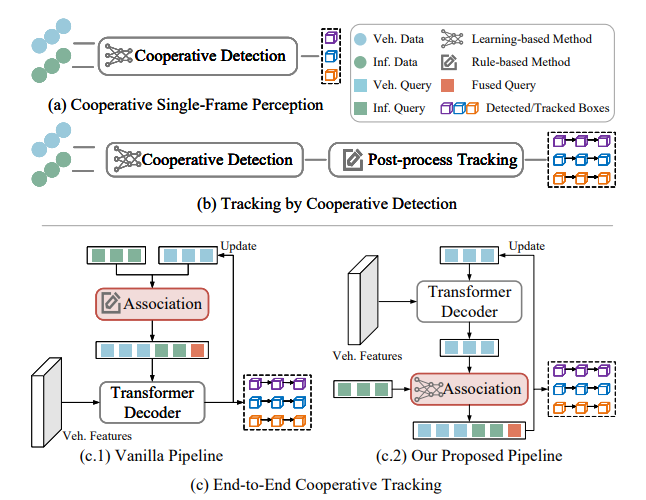
- 单车辆感知因视角限制存在局限,合作感知借助V2X通信成为解决方案,但其在合作序列感知(如3D多目标跟踪)领域研究不足。
- 传统方法采用“跟踪-by-合作检测”流程,无法充分利用融合信息;端到端学习虽能提升跟踪性能,但现有框架(如UniV2X)因规则化关联和融合流程存在性能缺陷。
3.2 相关工作
- 合作感知:分为早期、中期、晚期融合,中期融合为主流;现有研究多聚焦单帧任务,合作序列感知中,3D多目标跟踪多依赖传统范式,性能受限。
- 3D多目标跟踪:早期遵循“跟踪-by-检测”范式,存在优化解耦问题;端到端方法借助目标查询提升性能,但未涉及多智能体视角,本文旨在填补此空白。
4.【Method】
4.1 问题定义
合作序列感知旨在通过融合自车感知数据与其他智能体信息,实现对周围环境的长期全面理解。本文聚焦车-路协同3D多目标跟踪任务,以图像为输入,预测随时间变化的3D边界框集合 B t B_{t} Bt,且框的ID在帧间保持一致。每个边界框 b t i ∈ B t b_{t}^{i} \in B_{t} bti∈Bt包含中心坐标、尺寸、方向、速度及类别标签,定义为 b t i = [ x , y , z , w , l , h , θ , v x , v y ] b_{t}^{i}=[x, y, z, w, l, h, \theta, v_{x}, v_{y}] bti=[x,y,z,w,l,h,θ,vx,vy]。
4.2 CoopTrack框架
CoopTrack包含车辆和基础设施两个子系统,核心特点包括:
- 精心设计的pipeline,区别于现有端到端方法;
- 基于新型特征提取过程的实例级特征融合,在性能与传输成本间实现最优平衡;
- 具备可学习跨智能体对齐和基于图的关联的端到端学习,增强协同能力。
在每个时间戳 t t t,自车将前一时刻 t − 1 t-1 t−1的跟踪查询与固定数量随机初始化的查询拼接为查询 Q t v Q_{t}^{v} Qtv,每个查询 q t i ∈ Q t q_{t}^{i} \in Q_{t} qti∈Qt包含特征向量和3D参考点,即 q t i = { f t i ∈ 1 × d } q_{t}^{i}=\{f_{t}^{i} \in 1×d\} qti={fti∈1×d}, p t i ∈ R 1 × 3 p_{t}^{i} \in \mathbb{R}^{1 ×3} pti∈R1×3,其中 d d d为特征维度。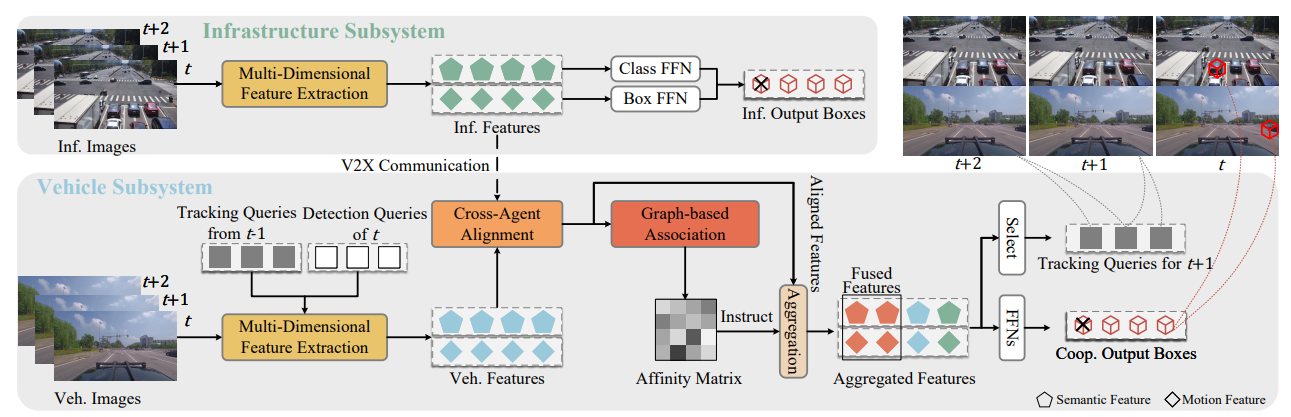
4.3 多维特征提取(MDFE)
该模块用于获取实例的全面表示,车辆和基础设施的处理过程相同。查询与当前图像特征、历史特征在MDFE中交互,公式为:
M t V , S t V = M D F E ( F t V , Q t V , M t − τ : t − 1 V , S t − τ : t − 1 V ) {\mathcal{M}}_{t}^{V}, {\mathcal{S}}_{t}^{V}=MDFE\left(F_{t}^{V}, {\mathcal{Q}}_{t}^{V}, {\mathcal{M}}_{t-\tau: t-1}^{V}, {\mathcal{S}}_{t-\tau: t-1}^{V}\right) MtV,StV=MDFE(FtV,QtV,Mt−τ:t−1V,St−τ:t−1V)
其中 M t V ∈ R N V × d M_{t}^{V} \in \mathbb{R}^{N_{V} ×d} MtV∈RNV×d和 S t V ∈ R N V × d S_{t}^{V} \in \mathbb{R}^{N_{V} ×d} StV∈RNV×d分别为运动特征和语义特征, N V N_{V} NV为自车观测到的实例数量, τ \tau τ为历史特征长度。
基础设施经相同过程得到多维特征 M t I ∈ R N I × d M_{t}^{I} \in \mathbb{R}^{N_{I} ×d} MtI∈RNI×d和 S t I ∈ R N I × d S_{t}^{I} \in \mathbb{R}^{N_{I} ×d} StI∈RNI×d, N I N_{I} NI为基础设施的实例数量。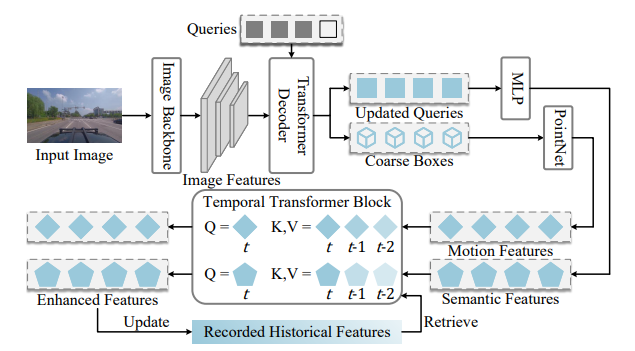
4.4 跨智能体关联与聚合
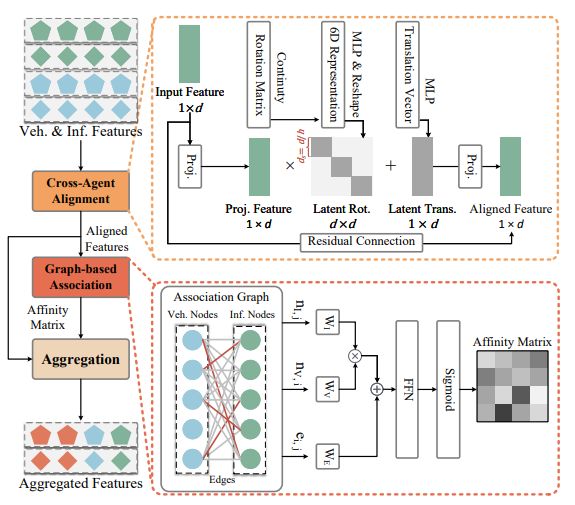
4.4.1 跨智能体对齐(CAA)
用于弥合不同智能体特征间的领域差距,公式为:
M ~ t V , S ~ t V , M ~ t I , S ~ t I = C A A ( M t V , S t V , M t I , S t I , R , t ) \tilde{\mathcal{M}}_{t}^{V}, \tilde{\mathcal{S}}_{t}^{V}, \tilde{\mathcal{M}}_{t}^{I}, \tilde{\mathcal{S}}_{t}^{I}=C A A\left({\mathcal{M}}_{t}^{V}, {\mathcal{S}}_{t}^{V}, {\mathcal{M}}_{t}^{I}, {\mathcal{S}}_{t}^{I}, R, t\right) M~tV,S~tV,M~tI,S~tI=CAA(MtV,StV,MtI,StI,R,t)
其中 M ~ t V \tilde{M}_{t}^{V} M~tV、 S ~ t V \tilde{S}_{t}^{V} S~tV、 M ~ t I \tilde{M}_{t}^{I} M~tI、 S ~ t I \tilde{S}_{t}^{I} S~tI为对齐后的特征, R ∈ R 3 × 3 R \in \mathbb{R}^{3 ×3} R∈R3×3、 t ∈ R 1 × 3 t \in \mathbb{R}^{1 ×3} t∈R1×3分别为旋转和平移矩阵。
潜在空间变换过程为:
M ~ I = M I ⋅ R ^ ⊤ + t ^ \tilde{\mathcal{M}}^{I}={\mathcal{M}}^{I} \cdot \hat{R}^{\top}+\hat{t} M~I=MI⋅R^⊤+t^
P ~ I = P I ⋅ R ⊤ + t \tilde{\mathcal{P}}^{I}={\mathcal{P}}^{I} \cdot R^{\top}+t P~I=PI⋅R⊤+t
其中 R ^ ∈ R d × d \hat{R} \in \mathbb{R}^{d ×d} R^∈Rd×d和 t ^ ∈ R 1 × d \hat{t} \in \mathbb{R}^{1 ×d} t^∈R1×d为学习到的潜在旋转矩阵和潜在平移向量, R R R和 t t t为显式对应项。
4.4.2 基于图的关联(GBA)
从对齐特征中学习自车与路边实例的关系,得到亲和矩阵 A t ∈ R N V × N ˉ 1 A_{t} \in \mathbb{R}^{N_{V} ×\bar{N}_{1}} At∈RNV×Nˉ1,公式为:
A t = G B A ( M ~ t V , S ~ t V , M ~ t I , S ~ t I ) A_{t}=G B A\left(\tilde{\mathcal{M}}_{t}^{V}, \tilde{\mathcal{S}}_{t}^{V}, \tilde{\mathcal{M}}_{t}^{I}, \tilde{\mathcal{S}}_{t}^{I}\right) At=GBA(M~tV,S~tV,M~tI,S~tI)
其中元素 a i , j ∈ A t a_{i, j} \in A_{t} ai,j∈At表示车辆侧第 i i i个实例与路边第 j j j个实例的相似度,值越接近1,越可能对应同一实例。
注意力矩阵计算为:
A ^ = ( N V W V ) ( N I W I ) T d + E W E \hat{A}=\frac{\left({\mathcal{N}}^{V} W^{V}\right)\left({\mathcal{N}}^{I} W^{I}\right)^{T}}{\sqrt{d}}+{\mathcal{E}} W^{E} A^=d(NVWV)(NIWI)T+EWE
其中 w v w^{v} wv、 W I W^{I} WI、 W E ∈ R d × d W^{E} \in \mathbb{R}^{d ×d} WE∈Rd×d为可学习的投影权重, A ^ \hat{A} A^为计算得到的注意力矩阵。
4.4.3 特征聚合
在亲和矩阵指导下,多智能体特征聚合为新的实例特征集 { M t R , S t R } \{M_{t}^{R}, S_{t}^{R}\} {MtR,StR},公式为:
M t , S t = A g g r ( A t , M ~ t V , S ~ t V , M ~ t I , S ~ t I ) {\mathcal{M}}_{t}, {\mathcal{S}}_{t}=Aggr\left(A_{t}, \tilde{\mathcal{M}}_{t}^{V}, \tilde{\mathcal{S}}_{t}^{V}, \tilde{\mathcal{M}}_{t}^{I}, \tilde{\mathcal{S}}_{t}^{I}\right) Mt,St=Aggr(At,M~tV,S~tV,M~tI,S~tI)
最终,两个前馈网络(FFN)分别从运动特征和解码出目标的位置、尺寸和运动状态,从语义特征中解码出类别,共同构成CoopTrack的输出。
4.5 训练过程
CoopTrack采用两阶段训练策略:
-
第一阶段,分别训练车辆侧和基础设施侧的端到端跟踪模型,损失函数为:
L stagel = λ b b x L b b x + λ c l s L c l s {\mathcal{L}}_{\text {stagel }}=\lambda_{b b x} {\mathcal{L}}_{b b x}+\lambda_{c l s} {\mathcal{L}}_{c l s} Lstagel =λbbxLbbx+λclsLcls
其中 λ b b x = 0.25 \lambda_{bbx}=0.25 λbbx=0.25, λ c l s = 2.0 \lambda_{cls}=2.0 λcls=2.0, L b b x {\mathcal{L}}_{bbx} Lbbx为L1损失, L c l s {\mathcal{L}}_{cls} Lcls为Focal Loss( α = 0.25 \alpha=0.25 α=0.25, γ = 2.0 \gamma=2.0 γ=2.0)。 -
第二阶段,在第一阶段预训练模型基础上,在协同真值和生成的关联标签监督下,训练端到端协同跟踪和关联,损失函数为:
L stage2 = λ b b x L b b x + λ c l s L c l s + λ asso L asso {\mathcal{L}}_{\text {stage2 }}=\lambda_{b b x} {\mathcal{L}}_{b b x}+\lambda_{c l s} {\mathcal{L}}_{c l s}+\lambda_{\text {asso }} {\mathcal{L}}_{\text {asso }} Lstage2 =λbbxLbbx+λclsLcls+λasso Lasso
其中 λ b b x = 0.25 \lambda_{bbx}=0.25 λbbx=0.25, λ c l s = 2.0 \lambda_{cls}=2.0 λcls=2.0, λ a s s o = 10.0 \lambda_{asso}=10.0 λasso=10.0, L a s s o {\mathcal{L}}_{asso} Lasso为Focal Loss( α = 0.5 \alpha=0.5 α=0.5, γ = 1.0 \gamma=1.0 γ=1.0)。
5.【实验结果】
5.1 数据集与实验设置
- 数据集:在V2X-Seq(车-路协同,100个动态场景,10Hz)和Griffin(空-地协同)数据集上评估,遵循官方数据分割。
- 实现细节:定义不同感知范围,采用BEVFormer检测器(ResNet50/101骨干),使用AdamW优化器(初始学习率 2 × 1 0 − 4 2 \times 10^{-4} 2×10−4),基于NVIDIA 3090 GPU实验。
5.2 与现有方法的比较
-
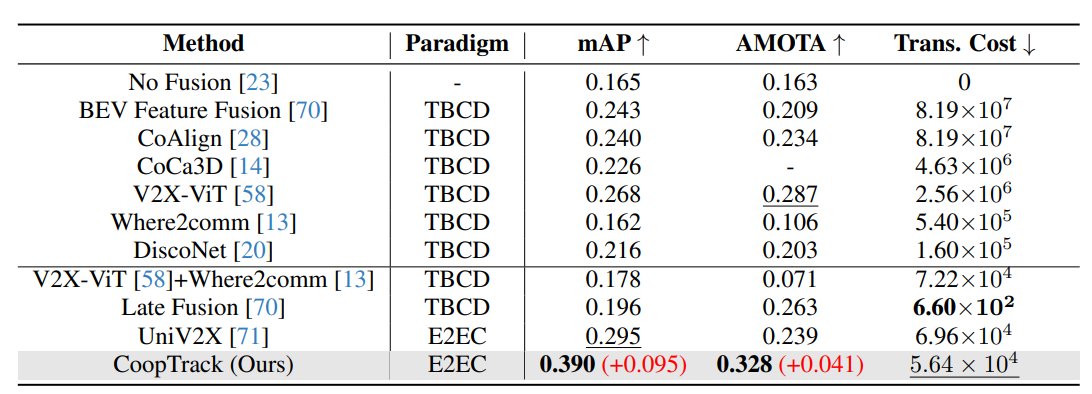
V2X-Seq:ResNet101骨干下,mAP达39.0%、AMOTA达32.8%,较V2X-ViT提升12.2%和4.1%,传输成本更低;10Hz数据上AMOTA提升10.7%。
-
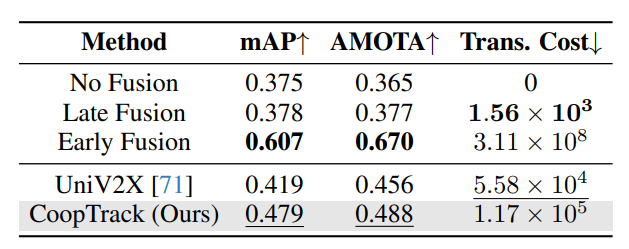
Griffin:mAP 47.9%、AMOTA 48.8%,较UniV2X提升6.0%和3.2%,验证跨场景适应性。
5.3 消融研究
-
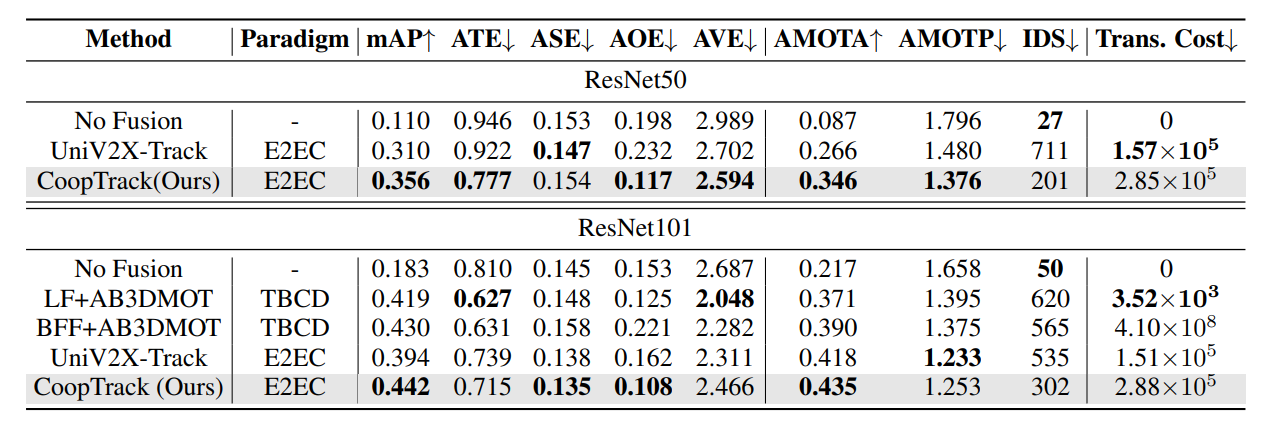
模块影响:pipeline、MDFE、CAA、GBA组合使用时,mAP 35.6%、AMOTA 34.6%,各模块单独添加均有提升,GBA可进一步优化关联性能。
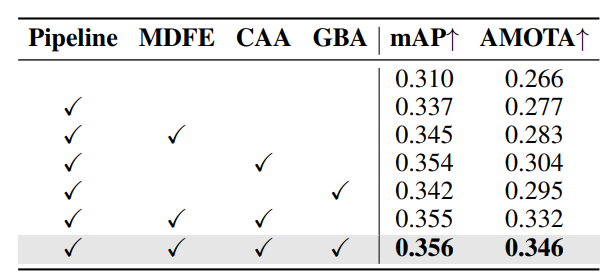
-
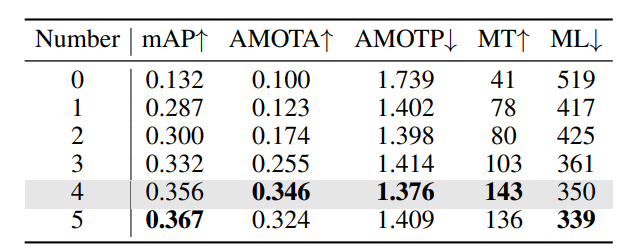
历史帧数量:4帧时性能最优(mAP 35.6%、AMOTA 34.6%),过多帧会导致性能饱和或下降。
6.【总结展望】
6.1 总结
本文提出CoopTrack,一种实例级全端到端合作跟踪框架,通过可学习实例关联与“解码后融合”流程,结合多维特征提取和跨智能体关联聚合模块,实现全面实例表示与自适应融合。在V2X-Seq和Griffin数据集上表现优异,刷新V2X-Seq的SOTA结果(mAP 39.0%、AMOTA 32.8%),优于现有方法。
6.2 展望
未来将优化复杂的训练过程,探索更高效训练方法;针对通信延迟、姿态误差等问题,开发先进时序建模与自适应补偿策略;拓展框架应用场景,验证其在更多合作任务及复杂环境中的表现。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)