【AI论文】UniWorld:用于统一视觉理解和生成的高分辨率语义编码器
摘要: 本文针对统一视觉语言模型在图像感知与操纵任务上的局限性,分析了GPT-4o-Image利用语义编码器(非传统VAE)的特征提取机制,并提出新型框架UniWorld。该框架结合多模态大语言模型(Qwen2.5-VL)与对比语义编码器(SigLIP),通过两阶段训练(语义对齐预训练+生成微调)实现高效图像理解与编辑。实验表明,UniWorld仅用1%的BAGEL数据量即在ImgEdit-Ben
摘要:尽管现有的统一模型在视觉语言理解和文本到图像生成方面表现出了强大的性能,但它们的模型在探索图像感知和操纵任务方面受到限制,而用户迫切希望这些任务能够得到广泛应用。 最近,OpenAI发布了强大的GPT-4o-Image模型,用于全面的图像感知和操纵,实现了表达能力并吸引了社区的兴趣。 通过在我们精心构建的实验中观察GPT-4o-Image的性能,我们推断GPT-4o-Image利用了语义编码器而不是VAE提取的特征,而VAE被认为是许多图像处理模型中的基本组件。 受到这些鼓舞人心的观察的启发,我们提出了一种统一的生成框架UniWorld,它基于强大的视觉语言模型和对比语义编码器提供的语义特征。 因此,我们仅使用1%的BAGEL数据构建了一个强大的统一模型,该模型在图像编辑基准测试中的表现始终优于BAGEL。 UniWorld还保持了具有竞争力的图像理解和生成能力,在多个图像感知任务中取得了出色的表现。 我们完全开源我们的模型,包括模型权重、训练和评估脚本以及数据集。Huggingface链接:Paper page,论文链接:2506.03147
研究背景和目的
研究背景
近年来,随着深度学习和多模态技术的快速发展,统一模型(Unified Models)在视觉语言理解和文本到图像生成领域取得了显著进展。这些模型通过联合优化架构,能够在多个基准测试上展现出强大的性能,涵盖了从图像理解到图像生成的各种任务。然而,尽管这些模型在视觉语言理解和文本生成方面表现出色,但在图像感知(Image Perception)和图像操纵(Image Manipulation)任务上仍存在局限性。
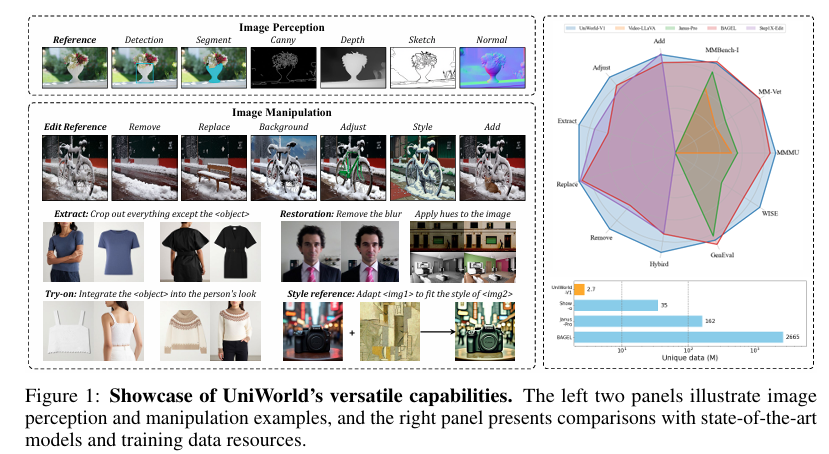
图像感知任务包括目标检测、图像分割、深度预测等,这些任务要求模型具备精确的像素级信息处理能力。而图像操纵任务则包括图像编辑、风格迁移、主体一致性生成等,这些任务需要模型在保持图像语义信息的同时,对图像进行精细的修改。传统的图像处理方法,如变分自编码器(VAEs),在图像生成和编辑任务中表现出色,但在处理需要高分辨率语义信息的任务时,其性能往往受到限制。
OpenAI发布的GPT-4o-Image模型在图像感知和操纵方面展示了卓越的能力,尤其是在综合图像感知和生成任务上取得了令人瞩目的成果。这一模型的成功激发了社区对统一视觉生成模型的新兴趣,尤其是关于其如何有效地融合视觉特征以支持复杂的图像任务。
研究目的
本研究的主要目的是探索并开发一种新的统一生成框架,该框架能够高效地处理图像感知和操纵任务,同时保持强大的图像理解和生成能力。具体而言,本研究旨在:
-
分析GPT-4o-Image的视觉特征提取方式:通过精心设计的实验,推断GPT-4o-Image在图像感知和操纵任务中可能采用的视觉特征提取机制,特别是其是否依赖于语义编码器而非传统的VAEs。
-
提出UniWorld模型:基于上述分析,提出一种基于高分辨率语义编码器的统一生成框架UniWorld,该框架结合强大的多模态大型语言模型和对比语义编码器,以支持复杂的图像感知和操纵任务。
-
验证模型性能:在多个图像理解和生成基准测试上验证UniWorld的性能,展示其在图像感知、图像生成和图像操纵任务上的优越性。
-
开源模型和数据:完全开源UniWorld模型,包括模型权重、训练和评估脚本以及数据集,以促进研究的可重复性和进一步探索。
研究方法
1. 实验观察与假设
本研究首先通过一系列精心设计的实验观察GPT-4o-Image在图像感知和操纵任务上的表现。特别是,通过局部编辑和去噪实验,推断GPT-4o-Image可能利用语义编码器提取的视觉特征,而非传统的VAEs特征。这些观察为后续模型设计提供了重要依据。
2. 模型架构设计
基于上述假设,本研究设计了UniWorld模型,该模型由以下几个关键组件构成:
- 视觉语言模型(VLM):采用预训练的Qwen2.5-VL-7B作为基础模块,用于提供高级语义信息。
- 对比语义编码器(SigLIP):采用SigLIP2-so400m/14作为低级图像特征控制信号,该编码器在对比学习中表现出色,能够捕捉图像的局部和全局信息。
- 多层感知机(MLP)连接器:用于将VLM和SigLIP的输出融合,作为文本分支的输入。
- 生成模块:采用Flow Matching技术,结合自回归理解模块,实现图像的生成和编辑。
3. 训练策略
UniWorld的训练分为两个阶段:
- 第一阶段:语义对齐预训练:专注于对齐VLM特征和FLUX文本分支特征,仅训练MLP映射层,其他参数保持冻结。
- 第二阶段:一致生成微调:加载第一阶段训练的权重,并解冻FLUX图像分支的所有可学习参数,同时保持文本分支参数冻结。
此外,本研究还采用了ZeRO-3EMA技术来优化训练过程中的权重平均,提高训练效率和稳定性。
4. 数据集与评估
本研究使用了多个公开数据集和内部收集的数据集进行训练和评估,包括图像感知、图像生成和图像编辑任务。评估指标涵盖了多个方面,如图像理解的准确性、图像生成的质量和多样性、图像编辑的精确性和一致性等。
研究结果
1. 图像感知与生成
UniWorld在图像感知和生成任务上表现出色。在多个图像理解基准测试上,UniWorld取得了与最先进模型相当甚至更好的性能。在图像生成任务上,UniWorld在GenEval和WISE等基准测试上取得了优异成绩,特别是在利用世界知识进行图像生成方面表现出色。
2. 图像编辑
UniWorld在图像编辑任务上同样表现出色。在ImgEdit-Bench等基准测试上,UniWorld在多个编辑类别中取得了最高分,包括属性调整、元素移除、对象提取、内容替换和混合编辑等。与BAGEL等先进模型相比,UniWorld在图像编辑任务上的性能更为接近GPT-4o-Image,展示了其在复杂图像操纵任务上的强大能力。
3. 训练效率与数据效率
值得注意的是,UniWorld仅使用了2.7M的训练数据就取得了如此优异的性能,这相较于其他需要大量数据训练的模型(如BAGEL使用了2665M数据)来说,显示了其极高的数据效率。这一成果得益于UniWorld采用的语义编码器架构和高效的训练策略。
研究局限
尽管UniWorld在多个方面取得了显著成果,但仍存在一些局限性:
-
指令泛化能力不足:由于训练数据有限且未对VLM进行微调,UniWorld需要特定的指令模板才能超越BAGEL等模型。这限制了其在更广泛指令集上的应用能力。
-
高分辨率输入限制:当前模型在处理高分辨率输入时仍存在挑战,特别是在绑定两个在现实世界中很少共现的对象时。这限制了其在某些需要高精度图像处理的应用场景中的表现。
-
参考区域敏感性不足:在ImgEdit-Bench和GEdit-Bench等基准测试上,UniWorld对参考区域的敏感性不足,这可能影响其在某些需要精确参考对齐的任务上的表现。
未来研究方向
针对上述局限性,未来的研究可以围绕以下几个方面展开:
-
增强指令泛化能力:通过收集更多样化的训练数据并对VLM进行微调,提高UniWorld在更广泛指令集上的泛化能力。这将有助于UniWorld在更多实际应用场景中发挥作用。
-
提升高分辨率处理能力:探索更高分辨率的语义编码器或采用VLM技术来增加输入图像的分辨率。例如,可以采用多尺度图像网格化技术来处理高分辨率图像,从而提高UniWorld在复杂图像处理任务上的性能。
-
优化参考区域敏感性:改进图像编辑任务中的参考区域检测和匹配算法,提高UniWorld对参考区域的敏感性。这将有助于UniWorld在需要精确参考对齐的任务上取得更好的表现。
-
探索更多应用场景:将UniWorld应用于更多实际场景中,如医学图像处理、遥感图像分析、虚拟现实和增强现实等。通过实际应用验证UniWorld的性能和稳定性,并不断优化模型以满足不同场景的需求。
-
结合其他先进技术:探索将UniWorld与其他先进技术(如强化学习、自监督学习、生成对抗网络等)相结合的可能性。通过结合多种技术优势,进一步提升UniWorld在图像感知和操纵任务上的性能和应用范围。
总之,本研究提出的UniWorld模型为统一视觉生成领域提供了新的思路和方法。通过深入分析GPT-4o-Image的视觉特征提取方式并设计高效的模型架构和训练策略,UniWorld在图像感知、生成和操纵任务上取得了显著成果。未来的研究将围绕增强指令泛化能力、提升高分辨率处理能力、优化参考区域敏感性等方面展开,以进一步推动统一视觉生成领域的发展和应用。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献228条内容
已为社区贡献228条内容

所有评论(0)