熬夜肝完!基于LangChain构建大模型智能体全攻略,附完整代码,跑通第一个Agent!
【假如换成研究生,按照5分钟阅览1篇摘要的速度,不眠不休需要451天。
一、导 言
读不完的文献、做不完的实验、写不完的论文——即便是“7-11”强度,也常有力不从心。与此同时,基于**大型语言模型(Large Language Model, LLM)**的科研助理正在改变节奏:它能在主流数据库范围内快速梳理海量论文、提炼最新进展,并围绕目标课题生成多组高潜力的实验配方与合成路线,形成“读—想—做”的加速闭环。
它首先是一线科研者的‘时间加速器’:
⦿文献分析:分分钟读完一篇文献,一天读完一个领域的文献,比人工快N倍,且可以“007”工作模式
⦿实验预测:虚拟筛选分子结构,提供实验优化方案、器件结构优化建议,试错时间大大降低。
更是研究范式演进的‘关键推手’:
⦿知识重构:由个体经验累积,过渡到领域知识图谱与可查询的因果/证据网络,支撑跨论文、跨数据库的统一检索与推断。
⦿逆向设计:从“经验先行、再逐步试错”,转向“目标属性约束下的候选生成 + 计算/实验闭环验证”,把试错集中到更有希望的空间。
最终,它将托起‘自我进化的实验室’雏形:
⦿AI代理协调自动化平台与实验机器人,按反馈实时更新实验计划与资源调度。
⦿从失败与负结果中系统挖掘规律,持续优化设计空间与先验。
⦿24小时运行的智能助手,进行风险预判、合规校验与设备编排,实现安全、高效与可追溯。
材料科学的‘人机协作时代’已降临——与其被浪潮裹挟,不如把它变成你的私人助理**。**
二、LLM是什么?
LLM可作为“材料智能助理”,在与文献检索、信息抽取、专用预测模型和验证流程集成时,辅助你更快理解论文、提出可验证的实验候选并提供决策参考。其核心基于Transformer等深度神经网络,通过对海量语料进行自回归预训练学习词元序列的条件分布,获得通用语言表征;经监督微调与人类反馈对齐后,并结合检索增强(RAG)与函数/工具调用,模型将语言生成扩展为知识访问、推理与流程编排等能力。需要强调的是,LLM输出并非权威结论,可靠性取决于数据来源、对齐策略、外部工具与验证闭环。
LLM****的发展
自然语言处理(NLP)是研究计算机理解与生成自然语言的学科与工程领域; LLM是当代NLP的主流基础模型范式**。NLP的发展及应用如图1所示。横轴(技术演进):人工规则(Handcrafted Rules)→ 机器学习(Machine Learning)→深度学习**(Deep Learning)→ 大语言模型(LLM);纵轴(任务类型):信息提取(Information Extraction)、材料发现(Materials Discovery)、自主设计(Autonomous Design)。
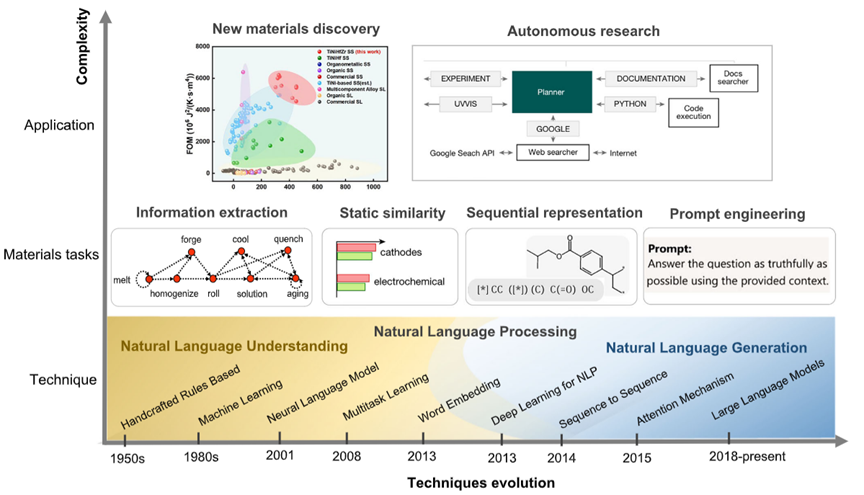
图1 自然语言处理(NLP)的发展及应用。
图片来源:npj Computational Materials | (2025) 11:79;https://doi.org/10.1038/s41524-025-01554-0。
🔹人工规则时代(1950s–1980s)
技术:依赖专家编写的语义/语法规则(如正则表达式匹配材料术语)。
任务局限:可完成格式化的实体识别与简单关系匹配(如化学式识别),但对复杂语境与跨句依赖无能为力,维护成本高、跨域迁移弱。
🔹机器学习时代(1980s–2010s)
技术:引入特征工程+统计模型。
任务升级:1)信息提取:在标注语料上完成化合物、性质、工艺步骤等序列标注与关系抽取。2)材料发现:基于词频/TF-IDF/主题分布等的相似性与检索,支持文献筛选与候选聚类,但语义理解有限。
局限:高维稀疏特征带来数据效率与泛化问题,强依赖人工标注与领域特征设计。
🔹深度学习时代(2010s)
技术:
- 词嵌入(Word Embedding):Word2Vec/GloVe将材料术语转为稠密向量;例如,在合金语境中,“Ti-6Al-4V”与“合金”语义邻近。
- **注意力机制(Attention)与序列模型:**在RNN/Seq2Seq中引入注意力以更好建模上下文;2017年Transformer将注意力推至主流。
·任务革新:1)信息提取:BiLSTM-CRF模型等能够有效地捕捉序列数据中的上下文信息和标签之间的依赖关系,识别出所需的信息。2)材料发现:用分布式表示进行相似性检索与聚类,早期对性质预测也有提升。
·局限:静态词向量难以处理多义词与领域语境差异(如“quench”在冶金与光谱中的不同含义)。
🔹大语言模型时代(2020s–至今)
技术:
- Transformer架构与注意力机制:以自注意力高效建模长程依赖,并通过改进的位置编码(如RoPE)、更长上下文窗口与检索式长程记忆,提升长文本处理与跨段关联能力(如合成步骤描述)。
- 大规模自监督预训练:基于自回归(GPT系)与/或掩码语言建模(BERT系)在海量无标注文本上学习词元条件分布,获得通用语言表征;经监督微调与人类反馈对齐(SFT/RLHF/DPO)后,配合检索增强(RAG)与工具调用,形成可用的任务通用能力。。
·任务全面升级:1)信息提取;2)材料发现与表征学习;3)生成式辅助设计(非完全自主)(具体参阅后文介绍)。
·领域适配的关键路径:基座模型(如BERT/GPT类)通过领域继续预训练(DAPT)、指令微调(含LoRA/PEFT)、高质量语料清洗与术语对齐,可显著提升材料领域表现;结合RAG接入专业数据库(如材料项目、专利/期刊)与工具/函数调用,实现检索问答、性质估计、结构解析与报告自动化。
为何不是数据库而是“语言大脑”?
数据库像“卡片柜”,LLM更像“能读论文、会联想的研究助理”。
🔹语义理解与跨表征对齐
·数据库依赖模式化输入与精确匹配(字段、主键、关键词)。
·LLM以上下文概率建模进行“语义对齐”:当你问“OLED器件效率”,它不仅检索“EQE/CE/PE”等显性术语,还能联想到“发光层PLQY、激子管理、刚性结构、载流子平衡、微腔效应”等隐含因素,并在跨文献叙述差异下保持概念一致性。
🔹面向非结构化知识的抽取与归纳
·大量材料知识埋在自由文本与图表(方法细节、异常样本、边界条件、失败经验)。
·LLM可以将自然语言、表格、图谱说明转写为可查询的结构化三元组或任务卡(谁-在何条件-得到何性质),形成“语义→结构”的桥梁。
🔹泛化与组合式推理
·传统规则在概念变体面前易失效(“淬火/急冷/quench”),“同义+跨域”扩展困难。
·LLM能在相邻语义空间内做组合式推理,如将“高PLQY+刚性骨架+良好能级匹配→更高EQE”的论证链拼接,并标注证据位置。
与传统AI区别
⦿传统ML(特征工程→模型):需要结构化、干净的数据表;强在“数值预测与控制变量清晰”的场景,如性能回归、工艺参数优化。
⦿LLM(语义建模→对齐/抽取/生成):*直接读原文与图表说明,实现术语消歧、关系抽取、证据对齐、初步方案生成。最佳形态是与检索系统、解析器、工具调用结合,而非单独使用。
为何契合材料研究?
⦿处理非结构化知识的“翻译器”:大部分材料知识(如合成方法、材料各种性能表征及结果)存储在自由文本中(而非标准化数据库),LLM是自然语言与结构化数据的翻译器。
⦿动态演化能力与快速对新知“对齐”:新论文发布后,LLM按需提取与引用,或轻量微调(Fine-tuning)/指令微调,即可更新模型认知。
三、LLM如何助力你的研究
——三大核心能力
把LLM当作“会读论文、会沟通、会编排工具的聪明助手”。它不是单独完成一切的魔法棒,但和专业软件、数据库、实验设备配合,能显著提速你的研究。下面是三块常见落地场景。
功能一:知识挖掘——(帮你更快看懂、看全、看准)
⪧ **参数抽取:**从论文正文、表格、图片里抓出实验条件(配比、温度、时间等),并把单位统一。要点是用“PDF解析+光学字符识别(OCR)+领域NLP”的流水线,LLM负责整合与表述,人机一起抽查确保可靠。
⪧ 知识图谱:把“结构—工艺—性能”的关系画成网络图,便于看规律、找空白。要点是用已有的材料词表和数据库做对齐,减少混淆。
⪧冲突识别:不同论文结论不一致时,先列出“可能冲突”的证据,再标注影响因素(材料纯度、测试方法不同等)。这是“提请注意”,不是下最终裁决。
功能二:智能实验设计(把“经验”变成可验证的方案)
⪧ 逆向设计:你给目标(比如更高稳定性),系统用“生成模型+性质预测器”给出候选分子/材料;LLM把约束(可合成、无毒等)说清楚,并解释筛选理由。结果需要用仿真或小批量实验闭环验证。
⪧ 工艺优化:用贝叶斯优化/实验设计方法提出下一组“最可能更好”的参数组合;LLM把不同方案的取舍讲明白,并把日志标准化,方便复现。
⪧ 跨域迁移:把别的领域的好经验转成“可测试的假设”。先评估相似度(成分、相图、扩散机制等),再小步试错,避免生搬硬套。
功能三:过程执行与协同(把复杂流程说人话、排好队)
LLM是“自然语言接口”。你用日常语言描述实验流程,它把话转成可执行的步骤,联动设备与系统。
⪧ 设备联动:在有实验室信息管理系统/电子实验记录本、机器人或设备应用程序接口(API)的实验室,LLM把“操作说明”翻译成机器能跑的脚本,并调用既有调度与安全互锁。核心是安全优先、先仿真后上机。
⪧ 实时监控:在线数据(传感器、谱图)主要由专用算法做异常检测;LLM负责把异常用通俗话解释,并给出应急标准操作规程(SOP)清单。
⪧ 资源优化:结合库存与机时安排,背后用求解器算最优排程;LLM帮你描述约束、看懂冲突、快速沟通变更。
▋ 应用举例
⦿MaterialsBERT(图2)花费60小时,从130,000摘要中提取出300,000材料信息记录。【假如换成研究生,按照5分钟阅览1篇摘要的速度,不眠不休需要451天。】
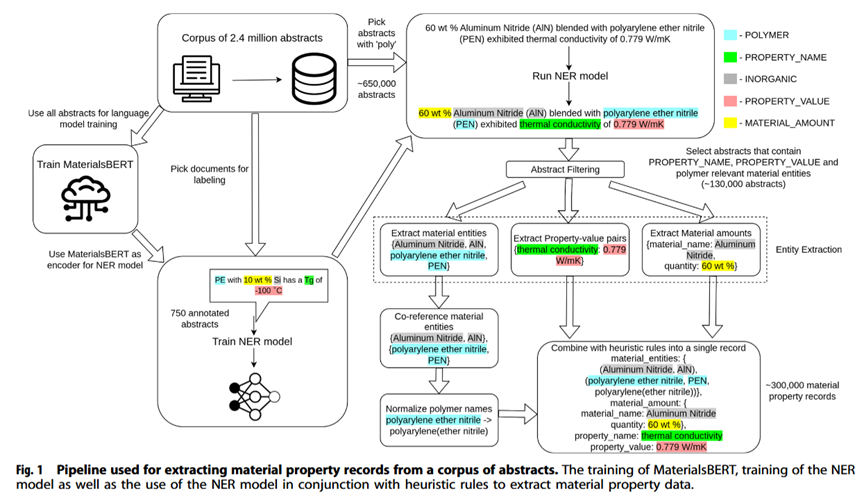
图2 MaterialsBERT用于提取材料性质的流程图。
图片来源:npj Computational Materials (2023) 9:52 ; https://doi.org/10.1038/s41524-023-01003-w
⦿北京科技大学提出了一种基于LLM的从海量历史文本知识中定量预测材料性能的端到端策略,该策略由材料自然语言编码器SteelBERT和多模态深度学习框架组成,以成分和工艺文本为输入,定量预测力学性能(图3)。其中,SteelBERT在包含约420万篇材料科学相关摘要和5.5万篇钢铁材料文献全文上预训练,将化学元素、制备加工工艺等钢铁知识的准确表示为上下文感知向量,通过深度学习框架成功预测了文献中新报道的18种不同钢种、不同工艺路线下的材料力学性能。(信息来源:npj Comput Mater 8, 102 (2022). https://doi.org/10.1038/s41524-022-00784-w;新材料大数据中心_需求服务合作成果_数据软件)
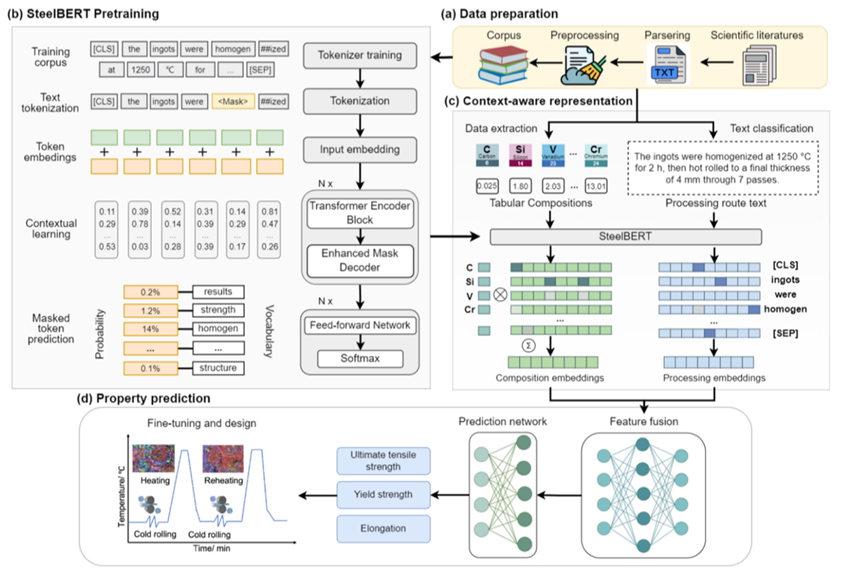
图3 基于SteelBERT的定量机械性能预测,包括数据准备(a)、SteelBERT预训练(b)、上下文感知表达(c)、性能预测与优化(d)。
⦿厦门大学汪骋教授等通过集成 AI (尤其是LLM) 与 机器人实验平台,创造了一种灵活自然的新型人机协作研究方式(AI Copilot)。它成功克服了传统自动化“不灵活”和“门槛高”的问题,让科学家能用自然语言沟通指挥实验。LLM将自然语言的实验描述映射为可执行的单元操作,包括温度控制、搅拌、液体和固体处理、过滤等。AI 成功合成了 13 种化合物,涵盖四大类无机材料,甚至意外发现全新材料家族,展示了 AI 增强机器人技术作为一个可推广且自适应的平台在材料创新方面的潜力。(信息来源:J. Am. Chem. Soc. 2025, 147, 26, 23014–23025; https://pubs.acs.org/doi/10.1021/jacs.5c05916)
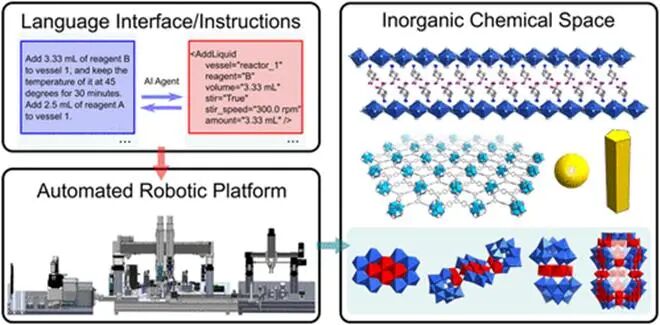
图4 AI + 机器人实验系统(AI Copilot +Chemical Robotic Explorer)用于材料发现的示意图。
图片来源:J. Am. Chem. Soc. 2025, 147, 26, 23014–23025; https://pubs.acs.org/doi/10.1021/jacs.5c05916。
⦿ 天津大学胡文平教授等开发了一个基于GPT-4的AI智能体,用于优化有机场效应晶体管(OFET)的设计与研究流程。通过结合LLM与机器学习算法,构建了一个能自动提取、分析文献数据并指导实验的系统。该系统使用GPT-4模型解析277篇OFET文献(含支持信息),提取实验参数;结合图像识别(GPT-4V)处理图表数据,DECIMER工具转换分子结构图为SMILES格式;设计了“人机协作”提示工程策略优化准确性,减少LLM幻觉问题;建立了包含709个OFET配置的结构化数据库(>10,000参数),耗时仅为人工的1/6。实现了三大应用:研究趋势追踪器(Trend Tracker)、性能预测器(Performance Predictor)、实验顾问(Lab Advisor,基于知识库的GPT-4助手,提供实验方案建议)。
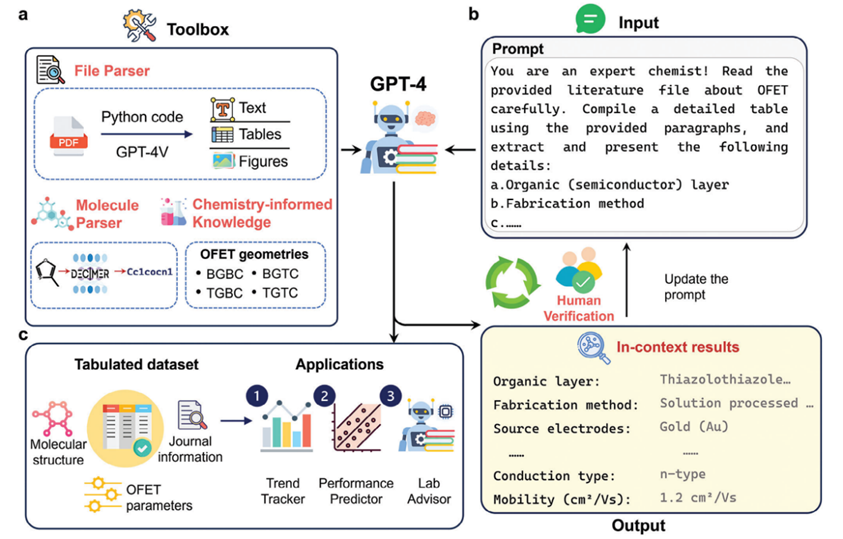
图5 基于LLM的OFET研究AI智能体架构示意图。
图片来源:Adv. Mater. 2024, 2405163;https://doi.org/10.1002/adma.202405163
四、LLM不是万能药
⦿核心局限:
- ·无法突破物理法则:
- 保守性约束:热力学、量子化学、扩散与传输定律等硬约束,LLM不会“自动守恒”。若无显式物理检查,可能给出违背守恒或量纲错误的建议。
- 量纲与单位:跨论文单位不一致常致数值误差,LLM对数值计算和单位换算的稳健性有限,需工具化校验。
- ·知识依赖陷阱(数据分布外问题):
- 训练-应用分布差异:LLM倾向于内插,面对分布外材料体系(新化学空间、新工艺窗口),容易“合理化编造”而非给出真实不确定性。
- 证据缺口:文献偏好正结果,负结果与失败条件缺失,导致建议向“发表偏差”方向漂移。
- ·创新束缚与局部最优
- 模式复刻:模型会强化“主流路线”,降低对少数派路径的探索概率。
- 优化窄化:仅靠LLM给出的“配方微调”可能停留在局部最优,需要与全局搜索(贝叶斯优化、进化算法、多臂匪徒)和物理先验结合。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献348条内容
已为社区贡献348条内容

所有评论(0)