(简)ViDoRAG:多模态的RAG工作(重点针对多模态混合检索)
我的理解是,不同的管道对pdf等document的处理方式不同,前者是提取文字,然后分为chunk,然后进行嵌入;我们通过对两种管道k值的大费周章的动态确定,就是为了在下一步骤量化地统一对“有关”的定义,从而协同地确定真正与query相关的嵌入。在此之前,相关工作主要有普通的基于文本的RAG和对单张图像进行理解和问答的VQA模型,但是前者无法充分考虑文档中的多模态内容。传统的方法是确定数量,可能会
一、文章目的与贡献
为了解决RAG领域中的图像与文本割裂开来的现象,文章提出了一个数据集和一个ViDoRAG框架,针对融合视觉的RAG工作。原文:[2502.18017] ViDoRAG:通过动态迭代推理代理进行可视化文档检索增强生成
在此之前,相关工作主要有普通的基于文本的RAG和对单张图像进行理解和问答的VQA模型,但是前者无法充分考虑文档中的多模态内容。我在最近提出的paperqa框架进行了尝试和解析,发现代码中对pdf进行处理和索引的时候,直接忽略了图像的内容。如果询问图像有关内容,它会给予文本中对图像的描述来回答,但是问到细节比如图像是什么颜色的之类时他们就无法回答了。

而后者只擅长处理单张的图像信息,不适用于RAG中对海量数据的索引。
二、ViDoRAG Framework
由于个人侧重点的原因,请允许我略过数据集部分,直接带来论文提出的框架。
1、多模态混合检索模块
这里提出了一种检索相关前k个page的方式。
首先,使用GMM模型的自适应去确定k的值,k值也就是检索的时候选取多少个page合适。传统的方法是确定数量,可能会按照经验去确定k的值。这显然是一个不太严谨的方法,当然,这里之所以把k变成动态的,还有更重要的原因,稍后再说。
我们假设query对应的document中的page相关度符合GMM分布:
![]()
也就是横轴是相似度,纵轴是概率密度。
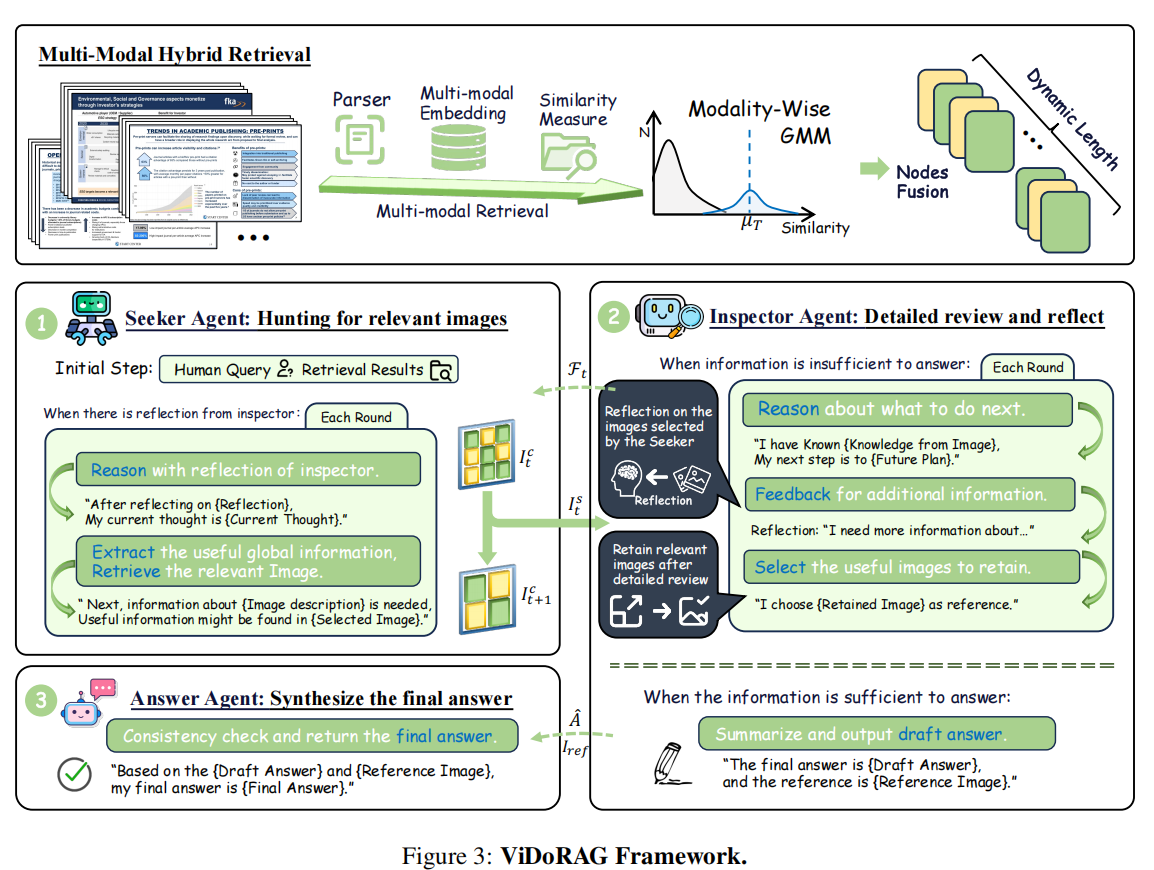
可以参考这张图最上方的图像。那么此时有未知参数,如何确定呢?我们采用EM算法,这里不过多解释。 最后确定下k的值:
![]()
这样以来我们就确定了最佳的K值。事实上,有两个k值,第一个是针对文本管道,第二个是针对视图管道。我的理解是,不同的管道对pdf等document的处理方式不同,前者是提取文字,然后分为chunk,然后进行嵌入;后者是针对可视化图片进行的嵌入,把每一页都视为了图片。两种管道嵌入方式不同,所以效果也不同。我们通过对两种管道k值的大费周章的动态确定,就是为了在下一步骤量化地统一对“有关”的定义,从而协同地确定真正与query相关的嵌入。
2.代理框架
我看了一下源代码,各个agent都是用Prompt工程调整的大模型,应该是负责推理阶段的配合。我主要是了解多模态混合的检索机制,所以这部分并未详细了解。
欢迎大家讨论和指正!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)