OPENHELIX:机器人操作的简短综述、实证分析和开源双-系统 VLA 模型(下)
25年5月来自西湖大学、浙大、西安交大和香港科大广州分校的论文“OPENHELIX: A Short Survey, Empirical Analysis, and Open-Source Dual-System VLA Model for Robotic Manipulation”。双-系统 VLA(视觉-语言-动作)架构已成为具身智能研究的热点,但目前尚缺乏足够的开源工作来进一步进行性能分析和
25年5月来自西湖大学、浙大、西安交大和香港科大广州分校的论文“OPENHELIX: A Short Survey, Empirical Analysis, and Open-Source Dual-System VLA Model for Robotic Manipulation”。
双-系统 VLA(视觉-语言-动作)架构已成为具身智能研究的热点,但目前尚缺乏足够的开源工作来进一步进行性能分析和优化。针对这一问题,本文将总结和比较现有双-系统架构的结构设计,并对现有双-系统架构的核心设计要素进行系统的实证评估,最终为后续探索提供一个低成本的开源模型。
。。。。。。继续。。。。。。
基于以上分析,采用提示调优来调整大型模型的输出,而不是直接微调 MLLM 本身。此外,引入一项辅助任务,以充分利用 MLLM 的视觉推理能力。这种方法可以生成更稳健的潜嵌入,有效地整合视觉和文本信息。其提出的双-系统VLA概述如图所示:
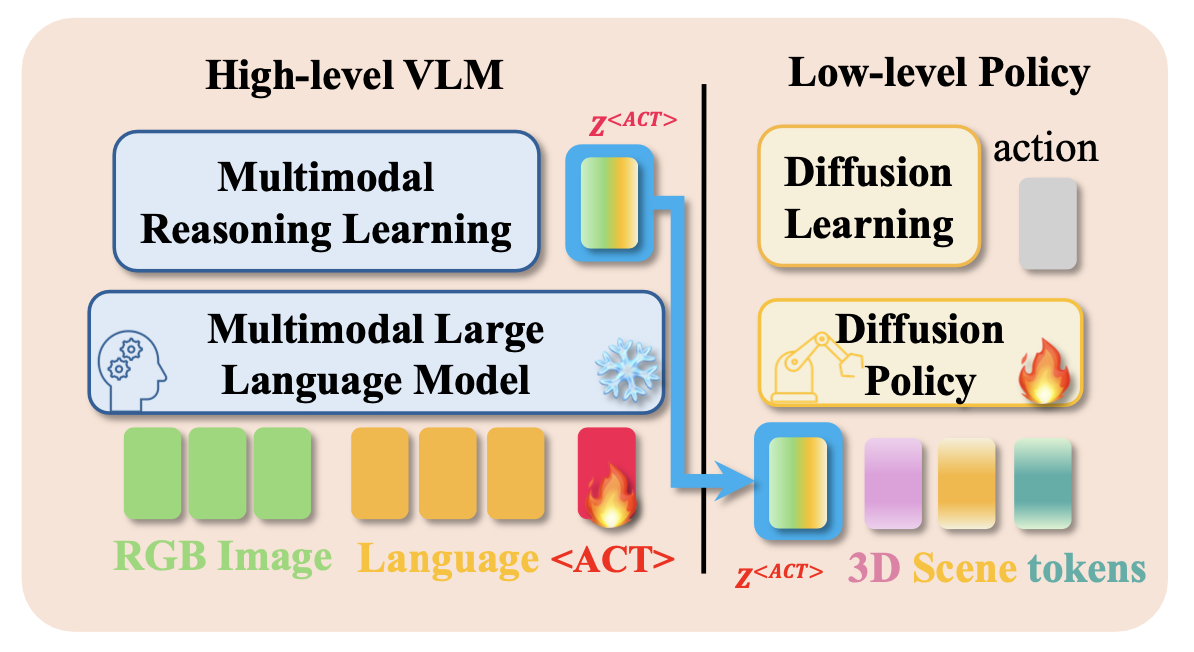
架构
网络。系统包含两个主要组件:一个预训练的 MLLM f_φ 和一个预训练的策略 π_θ,其参数分别为 φ 和 θ。MLLM 包含一个纯文本的大语言模型和一个视觉编码器,后者将图像投影到语言模型的嵌入空间中,从而实现对文本和视觉输入的多模态理解。预训练策略由一个视觉编码器和基于 Transformer 的扩散模型组成。该扩散模型使用多个交叉注意层,整合大量的条件信息,例如来自高级模型的 3D 场景表征、本体感受信息和条件/指令 tokens。在本研究中,利用 LLaVA [27] 作为高级 MLLM,并使用 3D Diffuser Actor 作为低级预训练扩散策略。值得注意的是,用线性层替换 3D Diffuser Actor 的文本编码器,将大型模型输出的潜嵌入维度与低级策略的输入维度对齐。
输入和输出。整个系统旨在模拟格式为 {l, (o_1, a_1), (o_2, a_2), …} 的演示轨迹,其中 l = {w_i } 表示长度为 N 且输入维度为 d 的任务特定语言指令,o_t 和 a_t 表示每个时间步 t 的视觉观察和相应的机器人动作。输入观察 o_t 由来自不同视点的两张 RGB-D 图像组成。输出动作 a_t 定义了末端执行器的姿态,该姿态分解为 3D 位置、旋转和夹持器状态(打开/关闭):a_t = {al_t, ar_t, ag_t∈{0,1}}。 MLLM f_φ 处理语言指令 l 和第三视角 RGB 图像 o′_t,输出用于低级策略的潜嵌入 z_t。低级预训练策略 π_θ 将时间步 t 的噪声轨迹 τi_t、扩散步长 i 以及来自环境观测 o_t、潜嵌入 z_t 和本体感觉 c_t 的条件信息作为输入,预测时间范围 T 内每个时间步 t 的动作轨迹 τ_t = (al_t:t+T, ar_t:t+T) 和二元状态 ag_t:t+T。
如图所示该双-系统 VLA 的细节: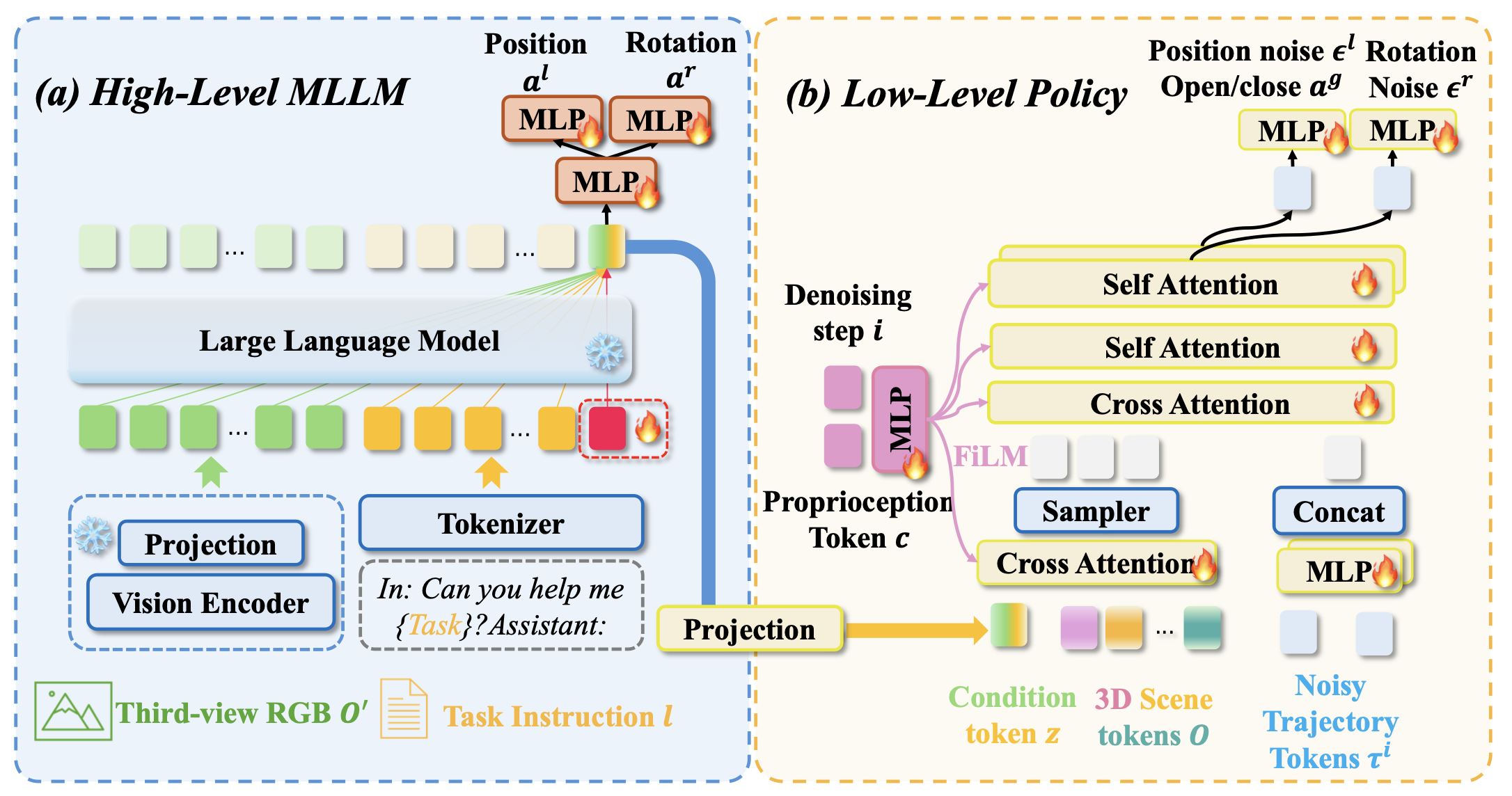
训练
提示调优。为了避免MLLM的性能下降,在语言指令l的末尾引入一个可学习的 token。新的指令 l′ 定义为 l′ = {l, }。在训练期间,MLLM的所有参数都被冻结;只更新可学习 token的嵌入。
多模态推理学习。正如之前讨论的那样,这些先前的方法并没有充分利用MLLM的视觉推理能力。具体来说,它们将大型MLLM模型的输出与CLIP文本编码器的输出对齐。使用纯文本信息来监督MLLM的微调会导致多模态推理能力的下降。因此,设计一个辅助任务来充分利用MLLM的多模态推理能力。这个任务非常简单,不需要额外的数据准备过程。可学习提示 token 的输出嵌入 z<ACT>_t = f_φ(o′, l′) 经过线性层传递,以预测动作轨迹 τ_t 和夹持器动作 ag_t。通过对此任务进行监督训练,确保大模型必须利用视觉输入信息,并且潜嵌入包含多模态信息的混合。损失函数定义如下:
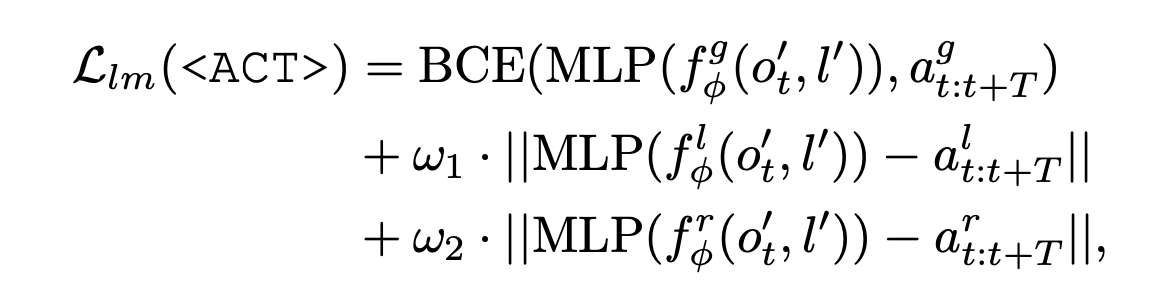
为了重建 3D 位置和 3D 旋转序列,应用 L1 损失函数。此外,用二元交叉熵损失函数 (BCE) 监督末端执行器的打开。
扩散学习。沿袭先前基于扩散的方法 [6, 11, 23],用动作去噪目标函数训练模型。训练期间,随机采样时间步长 t 和扩散步长 i,将噪声 ε = (εl , εr) 添加到真实轨迹 τ0_t。目标函数定义为:
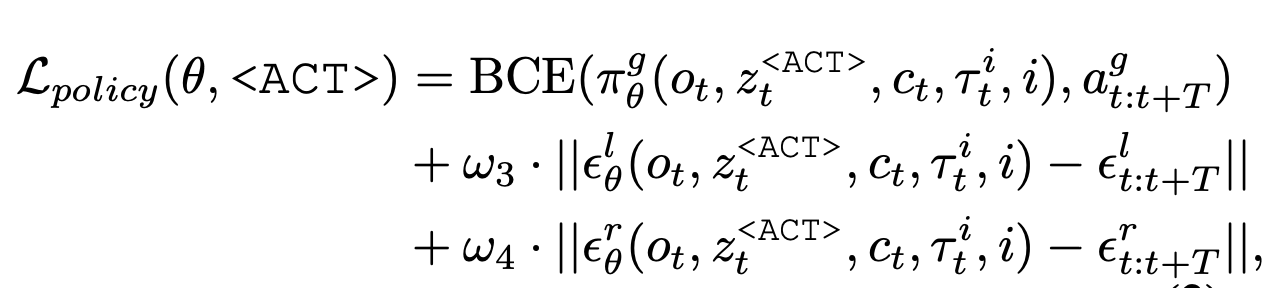
两阶段训练。采用两阶段训练方法来训练提出的对偶系统。在第一阶段,为了将 MLLM 生成的嵌入与预训练策略的特征空间进行初始对齐,冻结大型模型和低级策略的参数,仅训练提示层和投影层。在第二阶段,冻结大型模型,并解冻低级策略,同时对其进行微调,同时进行提示和投影。两个阶段的目标保持不变。两个阶段之间的唯一区别在于低级策略是否冻结。总而言之,损失函数包含两个部分,定义如下:
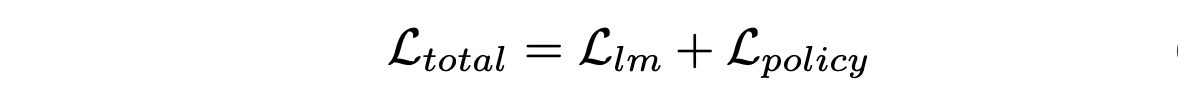
实现细节:分别使用 LLaVA-7B[15] 和 3D Diffuser Actor[11] 作为高级 MLLM 和低级策略模型。选择 3D Diffuser Actor 在 65,000 次迭代时的检查点作为预训练参数。训练期间,第一阶段(预对齐)进行 2,000 次迭代,第二阶段持续进行至 100,000 次迭代。投影是一个线性层,它将大型模型的输出维度从 4096 缩减到 512。手动向 LLava 的 token 化器添加一个 token,并冻结 MLLM 的所有参数,仅对新添加的 token 嵌入进行微调。其余实验和训练设置与 3D Diffuser Actor 一致。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献215条内容
已为社区贡献215条内容

所有评论(0)