AI Agent 学习笔记
AI Agent学习摘要 AI Agent是能自主分解并执行任务的智能体,应用如通过LLM搜索会议信息并生成日历。其核心架构包含:Global Action Repository(存储动作)、三类LLM模块(决策/执行/交互)及执行记忆,工作流程基于SOP文本逻辑,具备动作检索和失败回退机制。研究通过评估State/Action LLM的准确率验证性能,关注自动化流程设计与容错能力。
最近在学习ai agent的内容,我先介绍一下我的学习过程:查阅论文了解相关的定义和特性、应用场景、算法原理、设计理念、目前的弊端、未来拓展,横向技术对比(后面我会补上)。
一、定义与应用
论文一链接:AI Agents: Evolution, Architecture, and Real-World Applications
AI Agent 定义:一种能自主为用户或系统执行任务的智能体,可以分解大目标为小任务并规划执行。
应用例子:
让 LLM “帮我找 2023 年全球 AI 顶会的时间表并生成日历”, 一个 LLM Agent 会:
-
上网搜索(工具调用)
-
提取结果(信息处理)
-
生成 .ics 日历文件(执行任务)
-
发送给你
二、架构
论文二链接:Agent-S: LLM Agentic workflow to automate Standard Operating Procedures
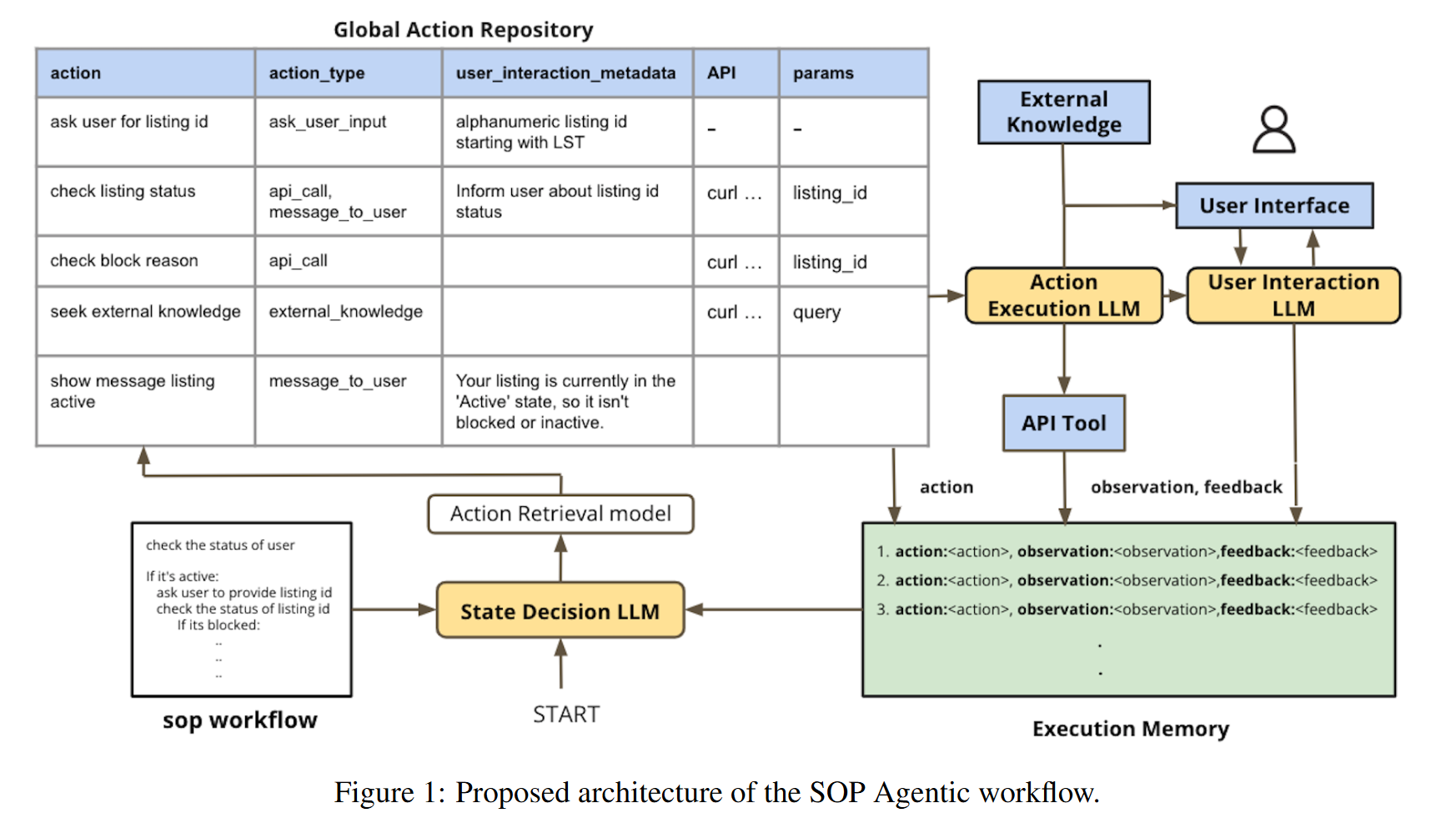
主要组件包括:
-
Global Action Repository (GAR):存储所有可能的动作(API 调用、用户交互、知识查询、消息输出)及其元数据。
-
三类 LLM 模块:
-
State Decision LLM:决定下一个动作(利用 SOP + 执行记忆)。
-
Action Execution LLM:根据动作类型执行 API 调用、生成用户提问、调用知识库等。
-
User Interaction LLM:处理用户输入,验证格式、提取实体、拼写纠正、生成确认回复。
-
Execution Memory:记录历史动作、观测结果(如 API 返回值或用户输入)、反馈(成功/失败)。
-
-
外部环境:包括 API 工具、用户界面、外部知识库(RAG)。
工作流程为:
-
SOP 被写成逻辑文本/树状流程。
-
State LLM 根据 SOP 和当前记忆,决定下一步。
-
Action LLM 具体执行动作(问用户、查 API、取知识库)。
-
用户或 API 的反馈被写入记忆,继续决策。
-
若失败(如 API 返回错误/用户输入不合法),LLM 会选择重试或回退步骤。
创新点为:
-
SOP:文本形式,类似有缩进的逻辑块
-
Action检索:用embedding+语义搜索匹配GAR中的动作
-
回退机制+防死循环机制:某动作重复两次仍失败,则终止并返回提示
三、评估
多维度评估框架
(source论文一 链接:AI Agents: Evolution, Architecture, and Real-World Applications)
| 评估维度 | 含义说明 | 示例指标 |
| 1. 任务完成效果(Task Completion Effectiveness) | 衡量智能体完成目标任务的准确度和质量 | 成功率、精确率、召回率、输出质量评分 |
| 2. 效率与资源利用(Efficiency & Resource Utilization) | 衡量执行任务所需的成本 | 模型调用次数、推理时间、API 成本、内存/CPU 占用 |
| 3. 鲁棒性与可靠性(Robustness & Reliability) | 测试在异常输入、噪声或失败情况下的表现 | 错误恢复率、稳定性、异常容忍度 |
| 4. 安全与价值对齐(Safety & Alignment) | 评估行为是否符合伦理、安全规范与人类意图 | 不良输出率、违规触发率、可信度评分 |
| 5. 交互质量(Interaction Quality) | 衡量与用户或其他智能体的交流自然度与连贯性 | 对话流畅度、用户满意度、协作成功率 |
| 6. 真实场景适用性(Real-World Applicability) | 衡量在真实环境中的泛化与可部署性 | 跨域迁移成功率、长期任务一致性、用户留存率 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)