LangChain数据库查询实战:三大方法助你快速上手!
文章介绍了使用LangChain框架操作数据库的三种方法:1)通过MCP适配器连接数据库,使用MultiServerMCPClient管理多服务器连接;2)使用LangChain的Tools工具创建SQL代理,通过few-shot提示提高查询准确性;3)直接让大模型生成SQL语句并执行。这三种方法各有优势,MCP方法效率较高,Tools方法可控性强,直接生成SQL方法灵活性高,开发者可根据实际需求
文章介绍了使用LangChain框架操作数据库的三种方法:1)通过MCP适配器连接数据库,使用MultiServerMCPClient管理多服务器连接;2)使用LangChain的Tools工具创建SQL代理,通过few-shot提示提高查询准确性;3)直接让大模型生成SQL语句并执行。这三种方法各有优势,MCP方法效率较高,Tools方法可控性强,直接生成SQL方法灵活性高,开发者可根据实际需求选择合适方案。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
LangChain是一个专为大语言模型设计的开放框架,围绕任务链(Chain)与内存模块(Memory)构建了核心架构。这两大组件是LangChain高效构建复杂语言应用的关键所在,使模型在多任务环境中得以应对任务管理、上下文维护、记忆存储等多种需求。
构建大模型智能应用的时候,往往需要对数据库进行查询,返回结果,如果自己写MCP客户端和Tools工具比较麻烦。如果基于LangChain框架的话,可以简化这种方法。本文就来演示一下,在LangChain框架下,如何使用MCP操作数据库以及如何使用Tools来访问数据库。
我这里假设你已经构建了MCP服务,或者调用的是公共的MCP服务。使用LangChain访问MCP来调用工具,现阶段主要是使用模型上下文协议(MCP)适配器来实现的。MCP适配器用于连接多个 MCP 服务器并加载 LangChain 兼容资源的客户端。此模块提供 MultiServerMCPClient 类,用于管理与多个 MCP 服务器的连接,并从中加载工具、提示和资源。
要使用MultiServerMCPClient需要先安装langchain_mcp_adapters模块:
pip install langchain-mcp-adapters -i https://pypi.tuna.tsinghua.edu.cn/simple # 使用清华源会提升速度
另一个重要的模块是langgraph.prebuilt。这个模块随langgraph模块的安装会自动安装。
pip install langgraph -i https://pypi.tuna.tsinghua.edu.cn/simple
这个模块是 LangGraph 库的核心组成部分,提供了一系列预构建的组件和工具,旨在简化复杂 AI 代理和工作流的开发过程。LangGraph 是 LangChain 生态的扩展框架,专注于构建有状态、多步骤的 AI 系统,通过状态图(StateGraph)管理节点和边,支持动态路由、循环和状态管理。该模块通过封装常见的代理逻辑、工具执行和状态管理功能,显著降低了开发者的编码负担,适合快速原型化和生产级应用。这里我们主要使用他的一个函数create_react_agent()。这个函数是用于构建基于 ReAct(思考-行动)模式 的智能代理(Agent)的核心函数,其作用是将大语言模型(LLM)与工具调用能力结合,实现动态任务处理。其中ReAct是一种结合推理和行动的代理架构。
使用示例代码如下:
from langchain_mcp_adapters.client import MultiServerMCPClient
# 配置我们自己构建的MCP服务或者公共的MCP地址
client = MultiServerMCPClient(
{
"math": {
"command": "python",
# Make sure to update to the full absolute path to your math_server.py file
"args": ["/path/to/math_server.py"],
"transport": "stdio",
},
"weather": {
# Make sure you start your weather server on port 8000
"url": "https://:8000/mcp",
"transport": "streamable_http",
},
"mcp-server-chart": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@antv/mcp-server-chart"
],
"transport": "stdio",
}
}
)
# 获取所有的工具列表
tools = await client.get_tools()
# 真实调用的时候传入大模型和工具列表构建一个agent
agent = create_react_agent(
model,
tools
)
# 通过invoke来实现工具的调用
result = await agent.ainvoke({
"messages": [...]
})
整体流程就是:
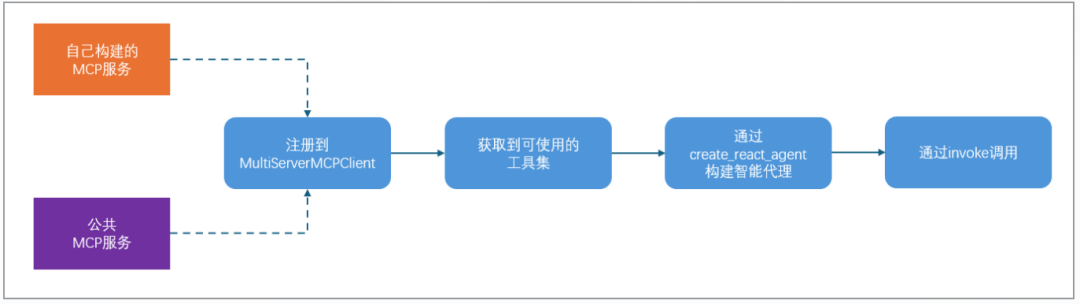
这里我有一个Postgresql数据库表,存储是某市的供地信息,使用MCP查询数据库,并返回结果,代码如下:
# 调用公开MCP工具----------------------
import asyncio
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.agents import create_openai_tools_agent
from langchain_core.messages import HumanMessage
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langchain_core.prompts import ChatPromptTemplate
model = ChatOpenAI(
streaming=True,
model='deepseek-chat',
openai_api_key=<你的API KEY>,
openai_api_base='https://api.deepseek.com',
max_tokens=1024,
temperature=0.7
)
async def mcp_main(query:str):
# 加载 MCP 配置
client = MultiServerMCPClient(
{
"postgres": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@modelcontextprotocol/server-postgres",
"postgresql://postgres:123456@localhost:5432/gtyzt"
],
"transport": "stdio",
}
}
)
tools = await client.get_tools()
agent = create_react_agent(
model,
tools
)
system_prefix = """
你是一个SQL语句生成专家。根据用户的问题和提供的数据库表结构信息,生成正确的SQL查询语句。
数据库元数据:
{schema}
生成SQL的规则:
1. 只生成SQL语句,不要添加任何解释或说明
2. 使用正确的表名和列名,与提供的结构一致,字段要加上中文别名
3. 确保SQL语法正确,适用于PostgreSQL数据库,geometry类型的字段要用ST_AsText(字段名)来获取
4. 如果有聚合操作,确保使用正确的聚合函数
5. 对于日期类型的条件,使用正确的日期格式
6. 如果需要排序,添加适当的ORDER BY子句
7. 查询结果要去除重复结果
"""
schema = """
"table_name": "gd",
"description": "供地数据表",
"columns":[
{"column_name": "ogc_fid","chinese_name": "标识码","data_type": "int"},
{"column_name": "wkb_geometry","chinese_name": "地理坐标信息","data_type": "geometry"},
{"column_name": "shape_len","chinese_name": "图形长度","data_type": "double"},
{"column_name": "shape_area","chinese_name": "图形面积","data_type": "double"},
{"column_name": "city","chinese_name": "大市","data_type": "varchar"},
{"column_name": "town","chinese_name": "区县(只到区县)","data_type": "varchar"},
{"column_name": "tdzl","chinese_name": "土地坐落(包括乡镇街道,道路)","data_type": "varchar"},
{"column_name": "xzqdm","chinese_name": "行政区代码","data_type": "varchar"},
{"column_name": "tdyt","chinese_name": "土地用途","data_type": "varchar"},
{"column_name": "crnx","chinese_name": "出让年限","data_type": "varchar"},
{"column_name": "gyfs","chinese_name": "供应方式","data_type": "varchar"},
]
"""
# 执行任务:访问网页并总结内容
result = await agent.ainvoke({
"messages": [
{"role":"system", "content":system_prefix.format(schema=schema)},
{"role":"user", "content":query}
]
})
print(result["messages"][-1].content)
return result["messages"][-1].content
if __name__ == "__main__":
query = "告诉我某市土地用途类型"
asyncio.run(mcp_main(query))
返回结果如下,可以看到结论清晰,并且如果数据库比较大的话,我实测速度上比我们自己让大模型去生成SQL,再执行是更快的,效率也更高。
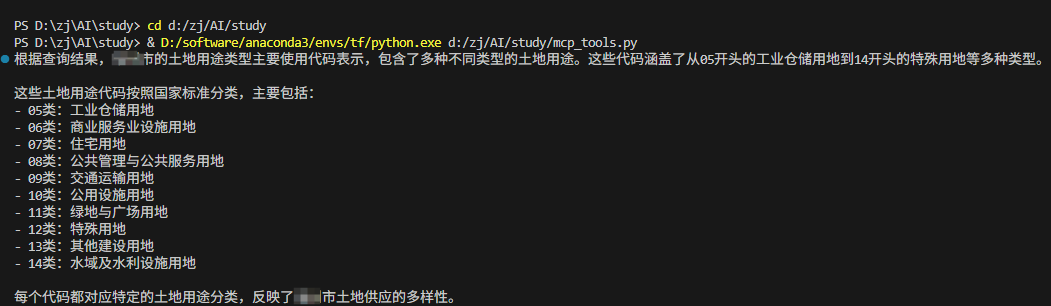
除了使用MCP,还有一种办法就是使用Tools来访问数据库,我们自己构建一个查询数据库的工具来进行查询并返回,本质上也和前面的MCP一样,构建了一个工具,一次性的返回查询结果。自己编写工具的最大好处就是比较可控。这里我使用langchain_community模块的create_sql_agent()函数。
首先,我们需要创建一个数据库连接;然后我们可以构建提示词,我这里使用了few-shot方法,给出了几个示例,这样的话,有利于提升大模型生成SQL的准确性并且速度更快,注意在使用few-shot的时候需要使用embedding模型,可以自己本地部署,也可以使用网上的模型。接下来根据提示词和大模型,调用create_sql_agent函数,构建一个sql代理agent。通过agent的invoke方法执行查询,并把这个流程封装成一个函数,作为tool暴露出来,供程序调用。主函数中,现在大模型上绑定这个tools工具,获取包含工具调用的初始响应,通过工具的invoke函数获取数据库查询结果,最后把结果传给大模型,得到最终的输出。
# text2sql工具,并以tool格式封装,查询结果可以通过大模型返回
from langchain.chains import create_sql_query_chain
from langchain_experimental.sql import SQLDatabaseChain
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
db = SQLDatabase.from_uri("postgresql://postgres:123456@localhost:5432/gtyzt")
model = ChatOpenAI(
streaming=True,
model='deepseek-chat',
openai_api_key=<你的APK KEY>,
openai_api_base='https://api.deepseek.com',
max_tokens=1024,
temperature=0.7
)
from langchain_community.agent_toolkits import create_sql_agent
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
from langchain_ollama import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
examples = [
{"input": "某某区供地地块数量是多少?", "query": "SELECT COUNT(*) FROM gd WHERE town like '某某区%';"},
{"input": "查询某某区供地信息","query":"""
SELECT DISTINCT
ogc_fid AS "标识码",
shape_len AS "图形长度",
shape_area AS "图形面积",
city AS "大市",
town AS "区县(只到区县)",
tdzl AS "土地坐落(包括乡镇街道,道路)",
xzqdm AS "行政区代码",
tdyt AS "土地用途",
crnx AS "出让年限",
gyfs AS "供应方式"
FROM gd
WHERE town like '某某区%'
"""}
]
embeddings = OllamaEmbeddings(model="bge-m3:567m")
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
embeddings,
FAISS,
k=5,
input_keys=["input"],
)
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotPromptTemplate,
MessagesPlaceholder,
PromptTemplate,
SystemMessagePromptTemplate,
)
system_prefix = """
你是一个SQL语句生成专家。根据用户的问题和提供的数据库表结构信息,生成正确的SQL查询语句。
数据库元数据:
{schema}
生成SQL的规则:
1. 只生成SQL语句,不要添加任何解释或说明
2. 使用正确的表名和列名,与提供的结构一致,字段要加上中文别名
3. 确保SQL语法正确,适用于PostgreSQL数据库,geometry类型的字段要用ST_AsText(字段名)来获取
4. 如果有聚合操作,确保使用正确的聚合函数
5. 对于日期类型的条件,使用正确的日期格式
6. 如果需要排序,添加适当的ORDER BY子句
7. 查询结果要去除重复结果
"""
schema = """
"table_name": "gd",
"description": "供地数据表",
"columns":[
{"column_name": "ogc_fid","chinese_name": "标识码","data_type": "int"},
{"column_name": "wkb_geometry","chinese_name": "地理坐标信息","data_type": "geometry"},
{"column_name": "shape_len","chinese_name": "图形长度","data_type": "double"},
{"column_name": "shape_area","chinese_name": "图形面积","data_type": "double"},
{"column_name": "city","chinese_name": "大市","data_type": "varchar"},
{"column_name": "town","chinese_name": "区县(只到区县)","data_type": "varchar"},
{"column_name": "tdzl","chinese_name": "土地坐落(包括乡镇街道,道路)","data_type": "varchar"},
{"column_name": "xzqdm","chinese_name": "行政区代码","data_type": "varchar"},
{"column_name": "tdyt","chinese_name": "土地用途","data_type": "varchar"},
{"column_name": "crnx","chinese_name": "出让年限","data_type": "varchar"},
{"column_name": "gyfs","chinese_name": "供应方式","data_type": "varchar"}
]
"""
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=PromptTemplate.from_template(
"User input: {input}\nSQL query: {query}"
),
input_variables=["input", "schema"],
prefix=system_prefix,
suffix="",
)
full_prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate(prompt=few_shot_prompt),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
]
)
agent = create_sql_agent(
llm=model,
db=db,
prompt=full_prompt,
verbose=True,
agent_type="openai-tools",
)
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_core.messages import ToolMessage
from langchain_core.messages import AIMessage
import os
import json
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
@tool(description="查询数据库")
def query_db(query: str) -> str:
"""
查询数据库
Args:
query: 用户问题
"""
result = agent.invoke({"input": query, "schema": schema})
return result
@tool(description="查询地理位置信息")
def query_map(query: str) -> str:
"""
查询地理位置信息
Args:
query: 用户问题
"""
result = agent.invoke({"input": query, "schema": schema})
print(result)
return result
if __name__ == "__main__":
llm_with_tools = model.bind_tools([query_db])
query = "告诉我某市土地用途类型"
messages = [HumanMessage(query)]
# 获取包含工具调用的初始响应
ai_msg = llm_with_tools.invoke(messages)
messages.append(ai_msg)
# 执行工具并获取结果
if ai_msg.tool_calls:
tool_result = query_db.invoke(ai_msg.tool_calls[0])
json_str = tool_result.content
json_obj = json.loads(json_str)
tool_msg = ToolMessage(
content=json_obj['output'],
tool_call_id=ai_msg.tool_calls[0]['id']
)
messages.append(tool_msg)
# 流式输出最终响应
for chunk in llm_with_tools.stream(messages):
if hasattr(chunk, 'content') and chunk.content:
print(chunk.content, end="", flush=True)
执行结果如下:
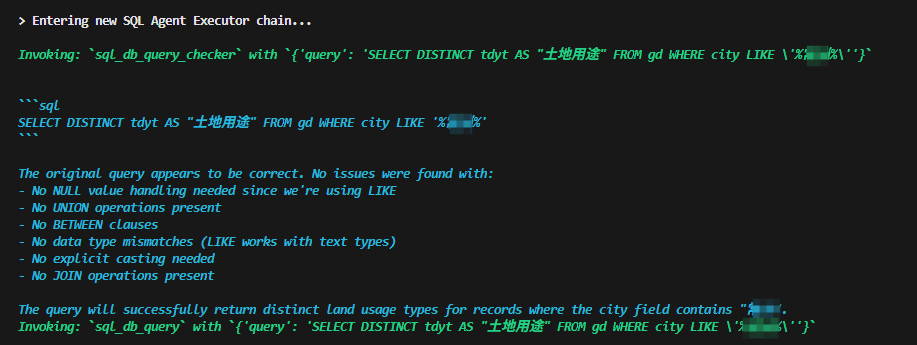
Finished chain.
根据数据库查询结果,某市的土地用途类型非常丰富,主要包括以下几大类:
🏭 工业用地
一类工业用地
二类工业用地
三类工业用地
🏢 商业服务业用地
商务金融用地
零售商业用地
旅馆用地
其他商服用地
其他商业服务业用地
… …
还有一种方法就是通过大模型生成SQL,再执行SQL。这种方法其实也是比较好的,定制化比较好,而且对于需要直接返回数据结果而不希望经过大模型“提炼”与“总结”的场景来说就比较有用了,因为不管是MCP还是tools工具调用,查询的结果都会经过大模型再过一边,得到的是比较“人性化”的返回结果,但如果这个接口就是需要返回某种格式的原始结果,那么用这种方式就会比较好了。
def generate_sql(query):
# 使用 invoke 方法调用链
input_data = {
"input": query,
"schema": schema
}
result = chain.invoke(input_data)
result = result.replace("```sql", "")
result = result.replace("```", "")
print(result)
return result
import psycopg2
import pandas as pd
def execute_query(sql):
try:
conn = psycopg2.connect(
dbname="gtyzt",
user="postgres",
password="123456",
host="localhost", # 例如'localhost'或者你的数据库服务器IP地址
port="5432" # PostgreSQL默认端口是5432
)
df = pd.read_sql(sql, conn)
conn.close()
return df
except Exception as e:
print(f"查询出错: {e}")
return None
def query_map(query:str) -> str:
'''
查询地图
'''
sql = generate_sql(query)
result = execute_query(sql)
return result.to_json(force_ascii=False,orient="records")
if __name__ == "__main__":
sql = generate_sql("查询某区供地信息")
result = execute_query(sql)
print(result.head(10).to_json(force_ascii=False,orient="records"))
通过这三种方式,基本可以完成基于大模型对数据库进行访问和查询了。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)