Hello-Agents 第四章 智能体经典范式构建
返回的response是一个可迭代的生成器,我们循环读取每个chunk中的新增的文本片段,并实时输出到终端,这样就达到了我们日常使用的一些网页聊天助手到效果了。在初始化方法__init__中,除了LLM_MODEL_ID,LLM_API_KEY,LLM_BASE_URL三个参数的初始化,还有一个LLM_TIMEOUT参数,这个是。,plan阶段会调用一次大语言模型,将问题分解,并制定出一个清晰、分
本章内容如下:

在4.1节我们实现了一个为"Hello Agents" 定制的LLM客户端,它用于调用任何兼容OpenAI接口的服务,并默认使用流式响应。
import os
from openai import OpenAI
from dotenv import load_dotenv
from typing import List, Dict
# 加载 .env 文件中的环境变量
load_dotenv()
class HelloAgentsLLM:
"""
为本书 "Hello Agents" 定制的LLM客户端。
它用于调用任何兼容OpenAI接口的服务,并默认使用流式响应。
"""
def __init__(self, model: str = None, apiKey: str = None, baseUrl: str = None, timeout: int = None):
"""
初始化客户端。优先使用传入参数,如果未提供,则从环境变量加载。
"""
self.model = model or os.getenv("LLM_MODEL_ID")
apiKey = apiKey or os.getenv("LLM_API_KEY")
baseUrl = baseUrl or os.getenv("LLM_BASE_URL")
timeout = timeout or int(os.getenv("LLM_TIMEOUT", 60))
if not all([self.model, apiKey, baseUrl]):
raise ValueError("模型ID、API密钥和服务地址必须被提供或在.env文件中定义。")
self.client = OpenAI(api_key=apiKey, base_url=baseUrl, timeout=timeout)
def think(self, messages: List[Dict[str, str]], temperature: float = 0) -> str:
"""
调用大语言模型进行思考,并返回其响应。
"""
print(f"🧠 正在调用 {self.model} 模型...")
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
stream=True,
)
# 处理流式响应
print("✅ 大语言模型响应成功:")
collected_content = []
for chunk in response:
content = chunk.choices[0].delta.content or ""
print(content, end="", flush=True)
collected_content.append(content)
print() # 在流式输出结束后换行
return "".join(collected_content)
except Exception as e:
print(f"❌ 调用LLM API时发生错误: {e}")
return None
# --- 客户端使用示例 ---
if __name__ == '__main__':
try:
llmClient = HelloAgentsLLM()
exampleMessages = [
{"role": "system", "content": "You are a helpful assistant that writes Python code."},
{"role": "user", "content": "写一个快速排序算法"}
]
print("--- 调用LLM ---")
responseText = llmClient.think(exampleMessages)
if responseText:
print("\n\n--- 完整模型响应 ---")
print(responseText)
except ValueError as e:
print(e)
>>>
--- 调用LLM ---
🧠 正在调用 xxxxxx 模型...
✅ 大语言模型响应成功:
快速排序是一种非常高效的排序算法...
在初始化方法__init__中,除了LLM_MODEL_ID,LLM_API_KEY,LLM_BASE_URL三个参数的初始化,还有一个LLM_TIMEOUT参数,这个是设置客户端与 API 服务之间 HTTP 请求的超时时间,如果我们不设置的话,默认是60秒。think方法用于调用大语言模型(LLM)进行推理并返回完整响应文本。具体实现我们是调用大语言模型的聊天补全接口,也就是self.client.chat.completions.create(...)方法,我们设置了模型名,消息输入列表(格式类似后面使用实例中的exampleMessages),温度(控制生成文本的随机性/创造性),并启用了流式输出模式(stream=True)。流式输出的作用是模型生成结果时,会逐字或逐词返回,而不是等整个回答生成完再一次性返回,这样用户体验更好(无需长时间等待)。返回的response是一个可迭代的生成器,我们循环读取每个chunk中的新增的文本片段,并实时输出到终端,这样就达到了我们日常使用的一些网页聊天助手到效果了。
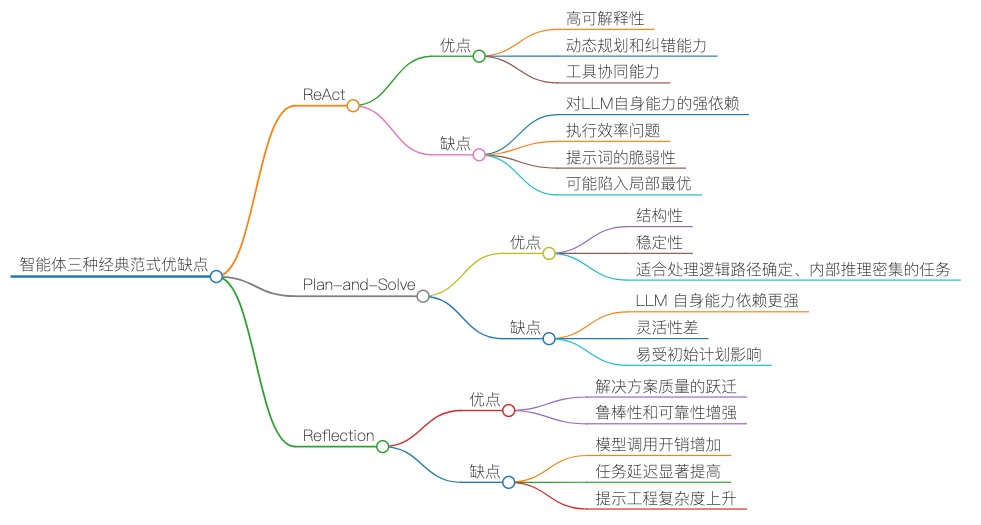
4.2到4.4节介绍了智能体的三种经典范式:ReAct, Plan-and-Solve, Reflection。
ReAct的关键在于不断重复Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,然后输出结果。Plan-and-Solve将任务处理分为两个阶段(先plan,再solve),plan阶段会调用一次大语言模型,将问题分解,并制定出一个清晰、分步骤的行动计划;solve阶段会严格按照计划中的步骤,逐一执行。Reflection会循环进行执行->反思->优化,直到反思阶段不再发现新的问题,或者达到预设的迭代次数上限。
本文内容来自DataWhale开源项目Hello-Agents.

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)