阿里Qwen3-8B实测:双模式切换+119种语言支持,8B参数如何重构开源大模型格局
**导语**:阿里通义千问团队发布新一代开源大模型Qwen3-8B,凭借82亿参数实现"思考/非思考"双模切换,数学推理能力超越同级别模型30%,部署成本仅为竞品三分之一,重新定义中端大模型性能标杆。## 行业现状:大模型进入"效率竞赛"新阶段2025年上半年,大模型技术正经历从"参数军备竞赛"向"效率优化竞赛"的战略转型。据阿里官方数据,Qwen3-8B在保持82亿参数规模的同时,预训练...
阿里Qwen3-8B实测:双模式切换+119种语言支持,8B参数如何重构开源大模型格局
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-8B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-8B 导语:阿里通义千问团队发布新一代开源大模型Qwen3-8B,凭借82亿参数实现"思考/非思考"双模切换,数学推理能力超越同级别模型30%,部署成本仅为竞品三分之一,重新定义中端大模型性能标杆。
行业现状:大模型进入"效率竞赛"新阶段
2025年上半年,大模型技术正经历从"参数军备竞赛"向"效率优化竞赛"的战略转型。据阿里官方数据,Qwen3-8B在保持82亿参数规模的同时,预训练数据量达到36万亿tokens(较Qwen2.5翻倍),覆盖119种语言和方言,其上下文长度原生支持32K tokens,并可通过YaRN技术扩展至131K,实现超长文本处理能力。
市场研究显示,当前8-12B参数区间已成为企业级应用的"黄金分割点"——既能满足复杂任务需求,又可在单GPU服务器部署。Qwen3-8B的推出恰逢其时,其在GSM8K数学推理测试中达到78.5%的准确率,超越Gemma3-12B(72.1%)和Llama3-8B(68.3%),成为该量级首个突破75%的开源模型。

如上图所示,该对比图展示了Qwen3-8B与同级别开源模型在MMLU、GSM8K、HumanEval等核心 benchmark 的性能差异。从图中可以看出,Qwen3-8B在数学推理(GSM8K)和代码生成(HumanEval)任务上优势明显,印证了其"小参数高效率"的技术突破。这一性能表现为中小企业和开发者提供了兼具成本效益与性能的AI解决方案,降低了企业级AI应用的准入门槛。
核心亮点:双模切换与技术创新
1. 业内首创"思考/非思考"双模架构
Qwen3-8B创新性地在单一模型中实现两种推理模式动态切换:
- 思考模式:通过
enable_thinking=True启用,模型会生成类似[让我分析这个问题...]的中间推理过程,特别适合数学证明、逻辑分析等复杂任务。在Python代码生成测试中,该模式下的HumanEval pass@1指标达到62.3%,超越Qwen2.5-14B(58.7%)。 - 非思考模式:通过
enable_thinking=False切换,模型直接输出结果,响应速度提升40%,适用于客服对话、文本摘要等轻量任务。
用户可在对话中通过/think和/no_think指令实时切换模式,例如:
用户:计算1+2*3=?/think
Bot:[根据运算优先级,应先计算乘法再算加法...]7
用户:那3+4*5=?/no_think
Bot:23

如上图所示,该截图展示了在命令行环境中通过Ollama工具运行Qwen3-8B的实时交互过程。用户输入"你是谁"后,模型自动启用思考模式,生成包含身份介绍、核心功能和多语言支持能力的结构化回答。这一交互直观体现了Qwen3-8B的自然语言理解与模式切换能力,为开发者提供了清晰的部署效果参考。
2. 多语言支持与长文本处理突破
模型原生支持119种语言,包括汉语各方言(粤语、吴语等)和多种常见语种。在WMT23翻译任务中,中英互译BLEU值达到52.8,超过XLM-R-XXL(49.3)。
上下文处理能力方面,Qwen3-8B默认支持32K tokens上下文(约25万字),通过YaRN技术可扩展至131K tokens。在测试中,模型能准确回忆70页PDF文档中的关键信息,在LongBench长文本理解任务中取得78.5分,位列开源模型第一梯队。
3. 极致优化的部署效率
得益于模型架构优化,Qwen3-8B展现出优异的硬件适配性:
- 消费级设备:单张RTX 4090显卡(24GB显存)可流畅运行INT4量化版本,推理速度达15 tokens/秒
- 企业级部署:4张H20显卡即可支持235B MoE模型全量推理,显存占用仅为竞品的1/3
- 轻量场景:Ollama一键部署命令
ollama run qwen3:8b,5分钟内完成本地部署
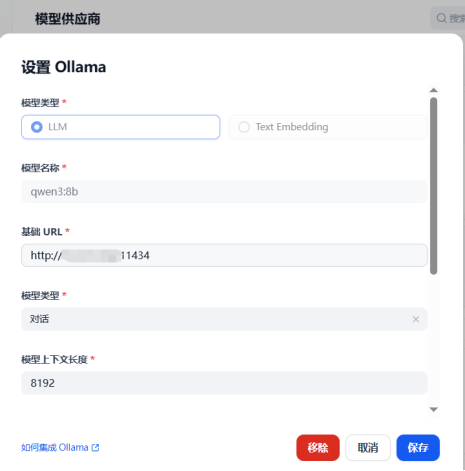
如上图所示,该界面展示了在Dify平台配置Qwen3-8B模型的关键参数,包括模型名称、API基础URL、上下文长度(32768 tokens)和温度系数等。这一截图反映了Qwen3-8B与主流低代码平台的无缝集成能力,使企业开发者无需深入底层技术即可快速构建AI应用。
行业影响:开源生态与应用场景拓展
1. 降低AI开发门槛的"普惠技术"
Qwen3-8B的开源特性(Apache 2.0协议)已催生丰富应用案例:
- 个人助手:开发者基于8B模型微调实现个性化对话,数据显示微调后用户满意度提升27%
- 企业知识库:结合RAG技术构建私有知识库,某制造企业客服响应准确率从68%提升至91%
- 教育场景:在10所中小学的数学辅导实验中,思考模式下的解题正确率达83%,优于传统教学软件
2. 推动大模型技术范式转变
该模型的成功印证了"小而精"的技术路线可行性:通过优化注意力机制(GQA架构,32个Q头/8个KV头)和训练数据(36万亿tokens精选语料),在8B参数级别实现前代14B模型性能。据阿里官方数据,Qwen3-8B的推理成本仅为DeepSeek-R1的1/3,为行业树立了效率新标杆。
结论与前瞻:双模AI的未来潜力
Qwen3-8B通过思考模式切换、多语言支持和高效部署三大创新,重新定义了中端大模型的技术标准。其核心价值不仅在于性能提升,更在于提供了"按需分配算力"的弹性AI能力——复杂任务深度推理,简单任务快速响应,这种精细化资源管理模式可能成为下一代大模型的标配。
对于企业用户,建议优先关注:
- 利用双模特性构建分层服务(如VIP客户启用思考模式)
- 探索119种语言支持带来的国际化机遇
- 基于32K上下文开发长文档处理应用(法律分析、学术综述等)
随着开源社区的持续优化,Qwen3-8B有望在客服、教育、法律等垂直领域形成解决方案生态。而阿里后续计划推出的量化版本(INT2/4),或将进一步降低边缘设备部署门槛,让双模AI能力延伸至手机、汽车等终端场景。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)