Hugging Face开源顶级模型:双模式推理+128K上下文,最强3B
Hugging Face开源30亿参数小模型SmolLM3,性能超越同类3B模型,支持6种语言和128K长文本处理。该模型采用双模式推理设计,开放了完整架构和训练细节,包括三阶段预训练策略(11.2万亿tokens数据)和创新的混合推理方法。通过分组查询注意力、NoPE技术等优化,在384块H100 GPU上训练24天完成。模型还进行了长上下文扩展和推理适应训练,最终通过APO对齐和模型合并技术保
Hugging Face开源顶级模型:双模式推理+128K上下文,最强3B
今天凌晨,全球著名大模型开放平台Hugging Face开源了,顶级小参数模型SmolLM3。
SmolLM3只有30亿参数,性能却大幅度超过了Llama-3.2-3B 、Qwen2.5-3B等同类开源模型。拥有128k上下文窗口,支持英语、法语、西班牙语、德语等6种语言。支持深度思考和非思考双推理模式,用户可以灵活切换。
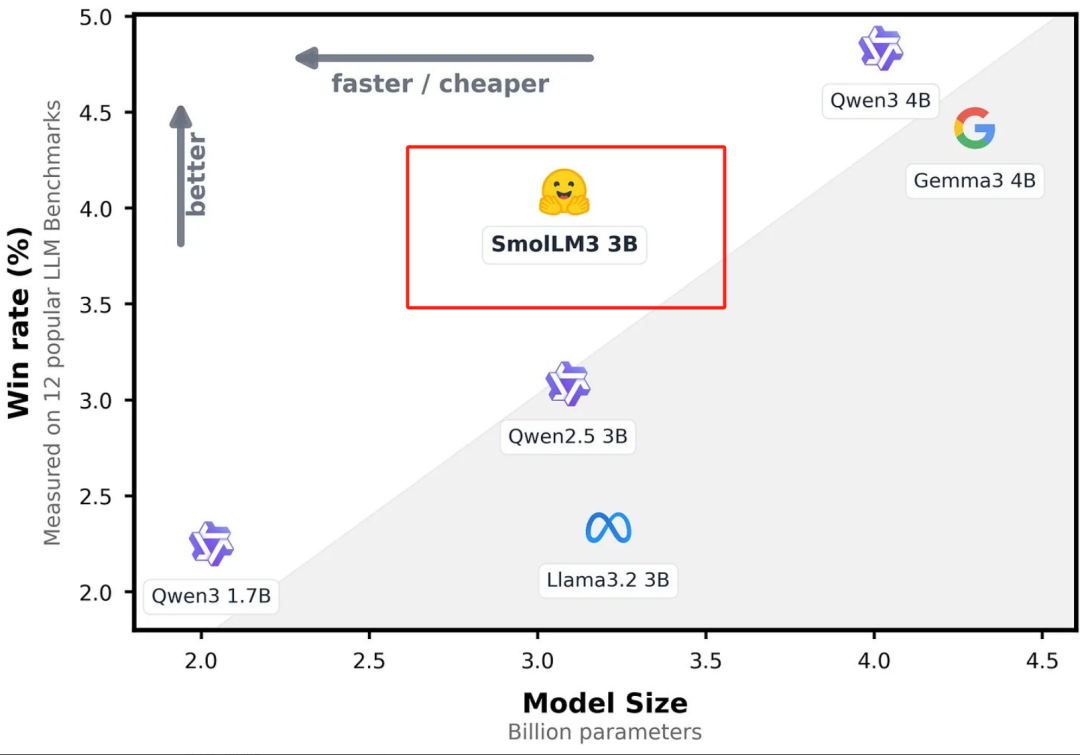
值得一提的是,SmolLM3已经把架构细节、数据混合方式、三阶段预训练以及构建混合推理模型的方法全部开放了,有助于开发人员深度研究或优化自己的模型。
基础模型:https://huggingface.co/HuggingFaceTB/SmolLM3-3B-Base
推理和指导模型:https://huggingface.co/HuggingFaceTB/SmolLM3-3B
Hugging Face的联合创始人Clement Delangue和Thomas Wolf都对该模型进行了强烈推荐,认为是3B领域的SOTA模型,也非常适合用于开源模型的研究。


SmolLM3****架构简单介绍
在架构方面,SmolLM3 采用了 transformer 解码器架构,与 SmolLM2 类似,基于 Llama进行了一些关键修改以提高效率和长上下文性能。使用了分组查询注意力,16 个注意力头共享 4 个查询,在保持全多头注意力性能的同时节省了推理时的内存。
训练中采用了文档内掩码,确保同一训练序列中不同文档的标记不会相互关注,有助于长上下文训练。还运用了 NoPE 技术,有选择地从每第 4 层移除旋转位置嵌入,改善长上下文性能而不影响短上下文能力。

训练配置方面,模型参数为 3.08B,初始化采用 N (0, std=0.02),有 36 层,Rope theta为50k,序列长度4096,批处理大小236万tokens,优化器为AdamW(eps=1e-8,beta1=0.8,beta2=0.95),峰值学习率 2e-4,梯度裁剪 1.0,权重衰减0.1。
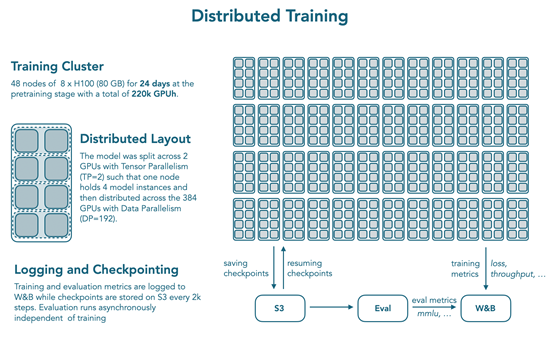
参考 OLMo 2,从嵌入层移除权重衰减以提高训练稳定性。训练使用 nanotron 框架,datatrove 进行数据处理,lighteval 进行评估,在384块H100 GPU 上训练了 24天,分布式训练设置为 48 个节点,每个节点8个H100(80 GB),模型通过张量并行(TP=2)分布在 2 个 GPU 上,一个节点容纳 4 个模型实例,再分布到 384 个节点。
训练数据和三阶段混合训练方法
数据混合和训练阶段遵循 SmolLM2 的多阶段方法,采用三阶段训练策略,在11.2 万亿 tokens 上训练,混合了网络、数学和代码数据,且比例不断变化。
阶段 1 为稳定阶段(0T→8T tokens),建立强大的通用能力,网络数据占85%(12%为多语言),包括FineWeb-Edu、DCLM、FineWeb2 和 FineWeb2-HQ;代码数据占 12%,包括The Stack v2(16 种编程语言)、StarCoder2 拉取请求、Jupyter 和 Kaggle 笔记本、GitHub 问题和 StackExchange;数学数据占3%,包括FineMath3 + 和 InfiWebMath3+。
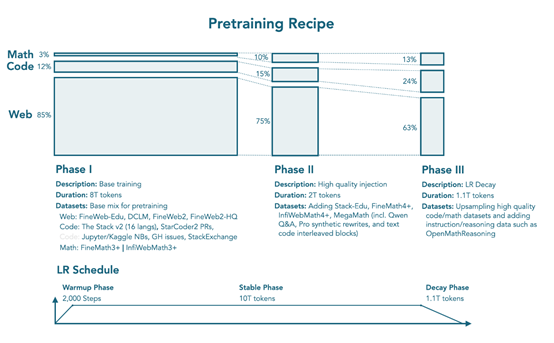
阶段 2 为稳定阶段(8T→10T tokens),引入更高质量的数学和代码数据集,同时保持良好的网络覆盖,网络数据占 75%(12% 为多语言),代码数据占15%(添加了 Stack-Edu),数学数据占 10%(引入了 FineMath4+、InfiWebMath4 + 和 MegaMath)。
阶段 3 为衰减阶段(10T→11.1T tokens),进一步增加数学和代码数据的采样,网络数据占 63%,代码数据占 24%(高质量代码数据的上采样),数学数据占13%,上采样数学数据并引入指令和推理数据集,如 OpenMathReasoning。
在中期训练中,进行了长上下文扩展和推理适应。长上下文扩展是在主要预训练后,额外训练 1000 亿 tokens 以扩展上下文长度,分两个阶段依次扩展上下文窗口,每个阶段500亿tokens,先从4k过渡到32k上下文,将 RoPE theta 增加到 150 万,然后从 32k 过渡到64k 上下文,将 RoPE theta 进一步增加到 500万,两个阶段都对数学、代码和推理数据进行了上采样。
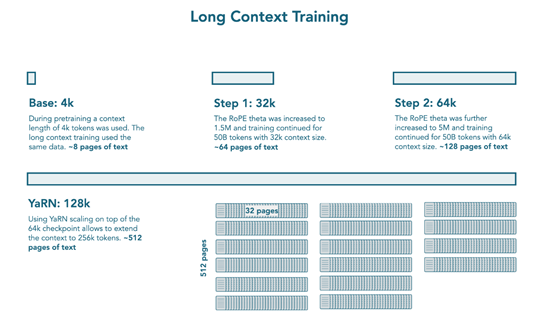
借鉴 Qwen2.5,使用 YARN 在训练上下文长度之外进行外推,推理时模型可处理高达 128k 的上下文(是 64k 训练长度的 2 倍扩展)。推理中期训练是在扩展模型上下文长度后,训练模型融入推理能力。中期训练数据集包含 350亿tokens,来自 Open Thought 的 OpenThoughts3-1.2M 和NVIDIA 的 Llama-Nemotron-Post-Training-Dataset-v1.1 的子集,使用 ChatML 聊天模板和包装打包,训练模型 4 个 epochs(约1400亿tokens),并将检查点用于后续的 SFT(监督微调)阶段。
后期训练中,构建了聊天模板,用户可通过在系统提示中包含/think和/no_think标志分别激活推理或非推理模式,在非推理模式下,会用空的思考块预填充模型的响应。
聊天模板还包含 XML 工具和 Python 工具两个不同的工具描述部分,提供了两种推理模式的默认系统消息以及包含日期、知识截止日期和当前推理模式的元数据部分,用户可通过在系统提示中使用/system_override标志排除元数据部分。
SFT和APO
SFT在推理中期训练阶段之后进行,该阶段在 1400 亿 tokens 的通用推理数据上训练模型,进而在数学、代码、通用推理、指令遵循、多语言和工具调用方面融合推理和非推理模式的能力。
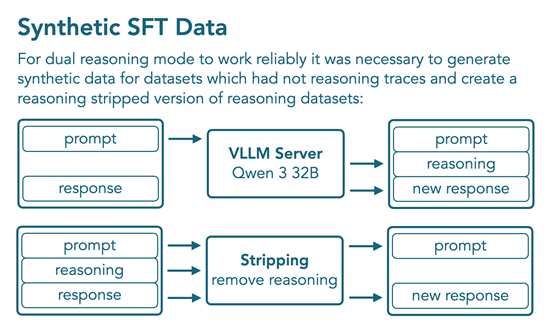
为解决某些领域缺乏包含推理轨迹的数据集的问题,通过在现有非推理数据集的提示下提示 Qwen3-32B 在推理模式下来生成合成数据。最终的 SFT数据集包含18亿tokens,其中 10 亿为非推理模式,8 亿为推理模式,包括12个非推理数据集和 10 个带有推理轨迹的数据集,使用 BFD打包训练 4 个 epochs(约 80 亿 tokens),对用户轮次和工具调用结果的损失进行掩码。
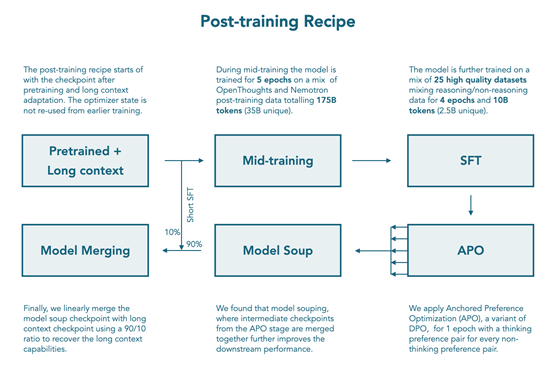
采用APO(锚定偏好优化)进行离策略模型对齐,这是直接偏好优化的一种变体,提供更稳定的优化目标。APO 步骤使用 Tulu3 偏好数据集(非推理模式)和新的合成偏好对(推理模式),合成偏好对由 Qwen3-32B 和 Qwen3-0.6B 生成。
由于在长上下文基准上观察到性能下降,采用模型合并来缓解使用 MergeKit 库,先将每个 APO 检查点创建一个模型 混合体,然后将模型混合体与具有强大长内容性能的中期训练检查点组合,APO 模型混合体和中期训练检查点的线性合并权重分别为 0.9 和 0.1,最终模型恢复了基础模型在高达 128k tokens 上下文上的 RULER 分数,并在广泛的任务中保持高性能。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献132条内容
已为社区贡献132条内容

所有评论(0)