DeepSeek实战--MaxKB(智能知识库 )部署配置
1 背景
前面我们手工实现过 RAG,其召回内容的准确性,依赖Embedding模型的效果,使用过程中发现了一些影响效果的痛点,比如检索精度不高、无法处理复杂文档、以及缺乏可解释性 等。
遇到的问题,有如下解法:
- 文本分割过于简单:深度学习模型、段落切分
- 检索器单一或薄弱:结合向量检索和全文检索。既能理解语义,又能精准匹配关键词
- 缺乏答案引用和溯源:答案会附带引用的原始文档片段、自行核对答案是否正确
- 提示工程薄弱:内置经过精心设计的系统提示,明确要求LLM“根据以下知识库内容回答”,并规范了回答格式
通常开源的 RAG 方案,大家听过比较多的是 RAGFlow,但我不太喜欢这款产品,因为其将文本转向量的过程真是太慢了。今天,使用另一款半开源的产品,那就是飞致云旗下的 MaxKB。所谓半开源就是可以学习使用,但不能用于商业。
2 环境准备
服务器:Ubuntu 24.04 LTS
docker:28.2.2
3 实战
Step1:部署
这款产品部署非常简单,可以直接 docker 拉起,也可以使用离线安装包进行部署。我采用的方式是在 linux 服务器上用 docker 拉起。命令为:
docker run -d --name=maxkb --restart=always -p 8081:8081 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb
根据自己实际的情况修改主机端口的映射。拉起后,可以看到这样一个容器。
Tips: 防火墙要允许8080端口通行
然后用浏览器访问 < 你的公网 IP>:8080 就可以打开登录页面了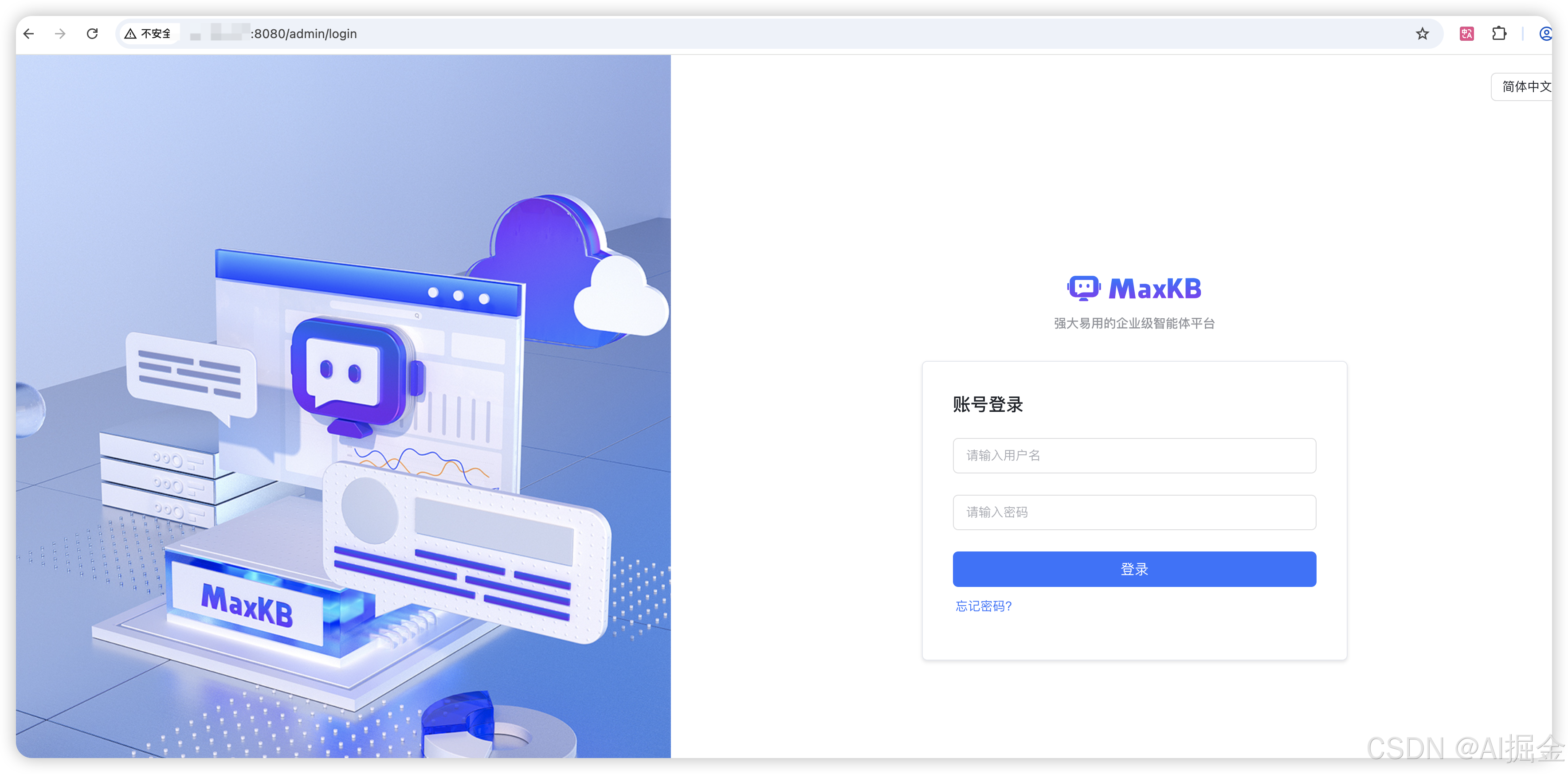
Step2:配置
默认的用户名密码为:
用户名: admin
密码: MaxKB@123…
1)先把模型都设置好,点击系统设置 - 模型设置,就可以添加模型了
2)这里的向量模型,我用了阿里云百炼的 text-embedding-v1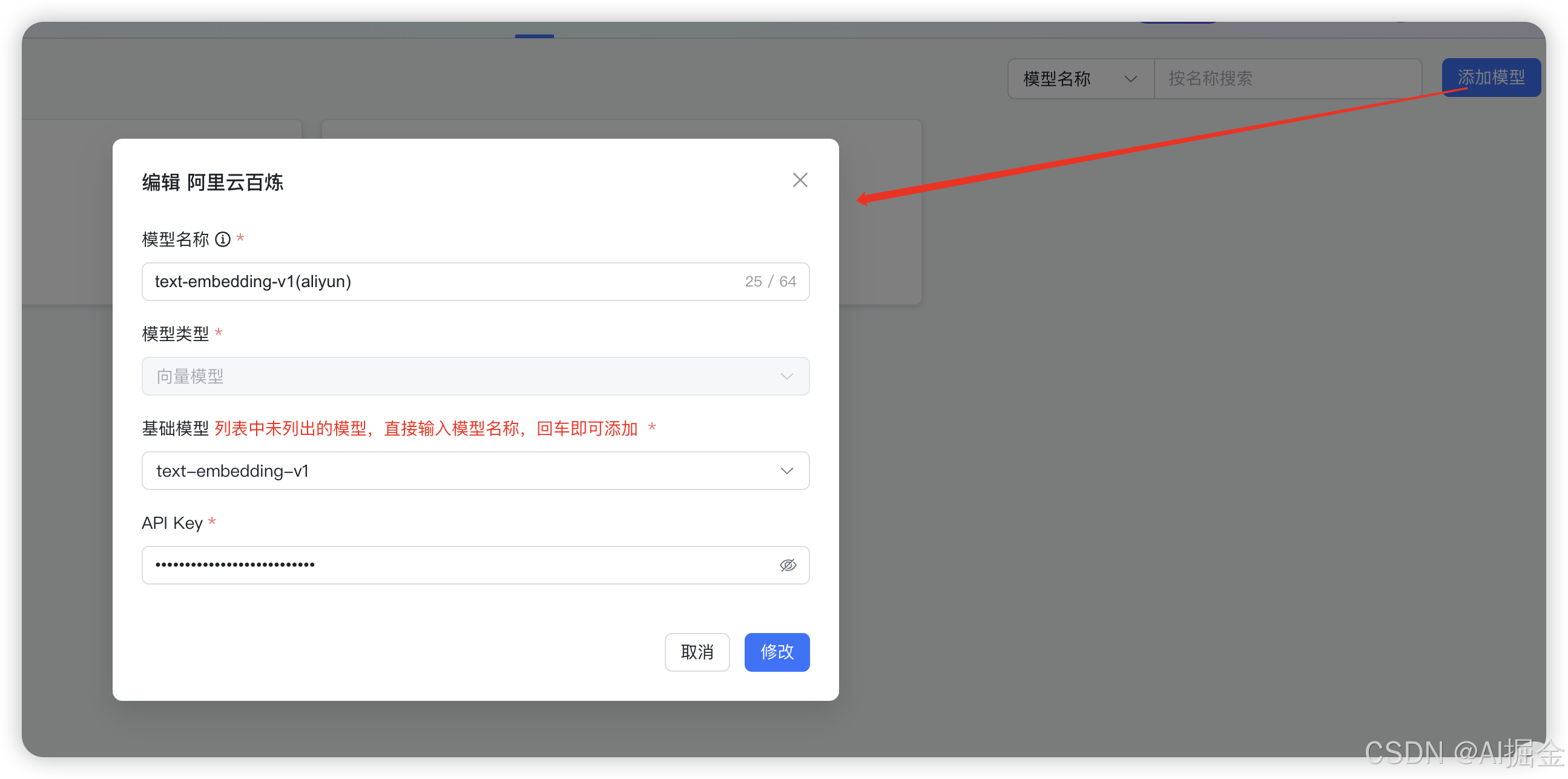
3)大语言模型,用DeepSeek-R1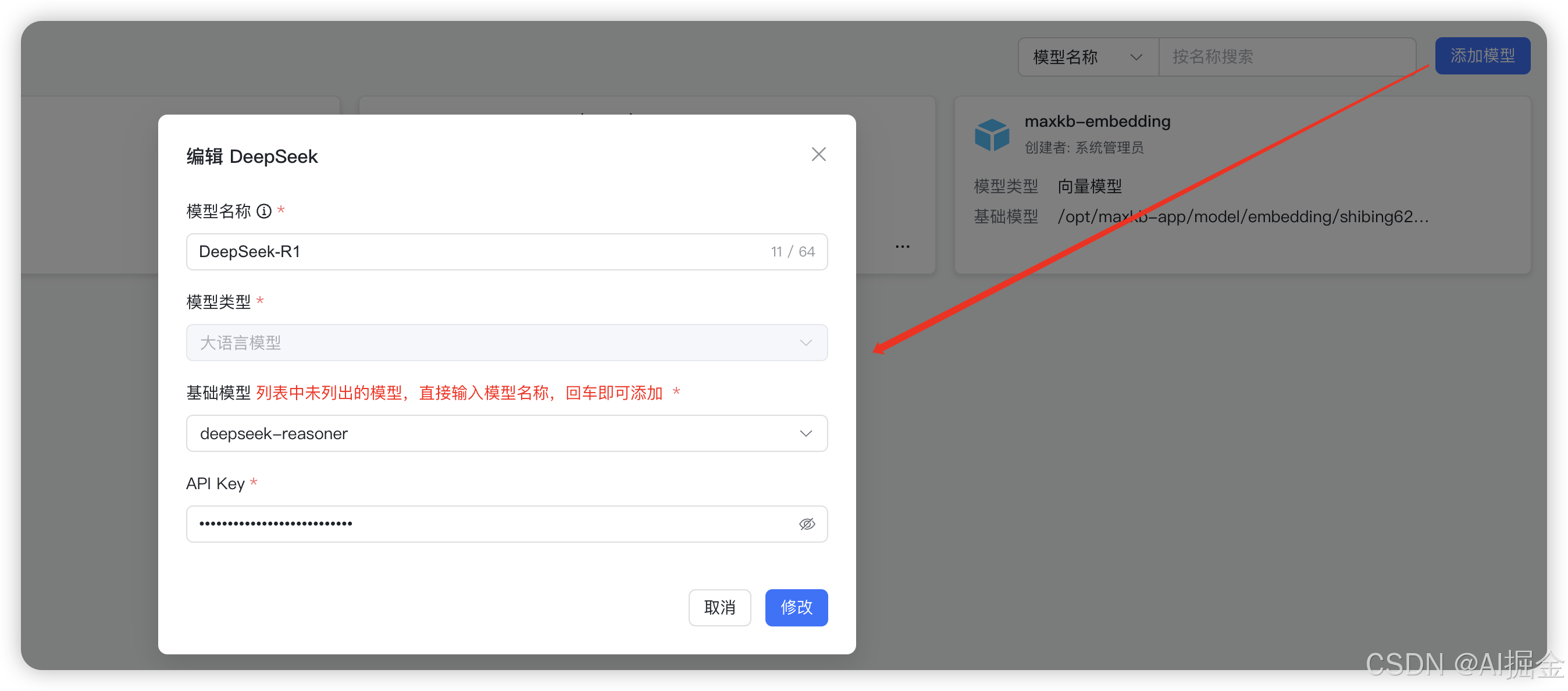
4 总结
1)部署MaxKB过程中,由于服务器配置太低(2核2G),安装完成后服务器直接拒绝服务了,然后换了一台(2核4G)服务器,完美解决
2)本文只讲了MaxKB怎么部署,下次给大家讲一下怎么用

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)