系列教程二|微调大模型Yi-1.5-6B-Chat
在命令行操作里,许多后续的指令都需要在项目的根目录下执行,只有进入到这个特定的目录,才能确保后续对项目文件和代码的操作是有效的。通过这一步,我们就为模型微调指定了正确的起点。Yi-1.5-6B-Chat 就是其中一款备受瞩目的模型,它基于 60 亿参数打造,在多种自然语言处理任务中表现出色,能够与用户进行高质量的对话交互,理解复杂的语义并给出精准回复。通过加载微调后的模型进行推理,我们能直接观察模
在人工智能飞速发展的当下,大语言模型已成为推动技术变革的关键力量。Yi-1.5-6B-Chat 就是其中一款备受瞩目的模型,它基于 60 亿参数打造,在多种自然语言处理任务中表现出色,能够与用户进行高质量的对话交互,理解复杂的语义并给出精准回复 。
但你是否想过,让这个强大的模型能更贴合特定场景需求呢?比如,更改它的自我身份认知,使其符合数据集的规定,同时还能保留原有的强大对话能力。这正是我们今天要探讨的内容。接下来,就请跟随我们的教程,一起在 BitaHub 社区开启对 Yi-1.5-6B-Chat 的微调之旅吧!
一.BitaHub平台使用
1.进入BitaHub官网,完成注册后点击右上角进入工作台。

2.在文件存储中创建文件系统,将需要的模型,数据集等存入其中。这里给出模型的下载地址:https://hf-mirror.com/01-ai/Yi-1.5-6B-Chat(可先将模型下载至本地,再上传至文件系统)
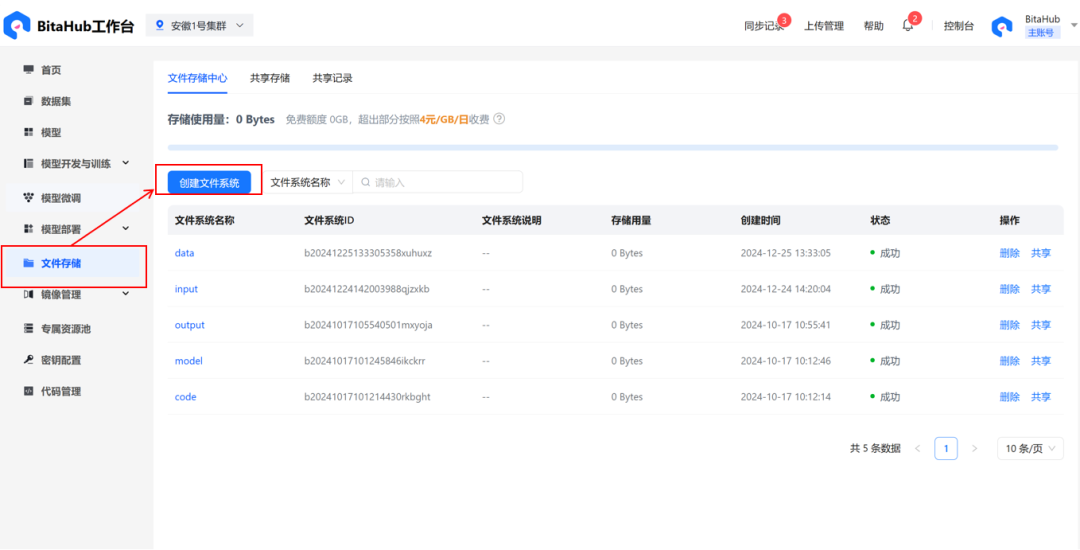
3.创建模型,从上一步创建的文件系统中选择本次训练所需要的模型。
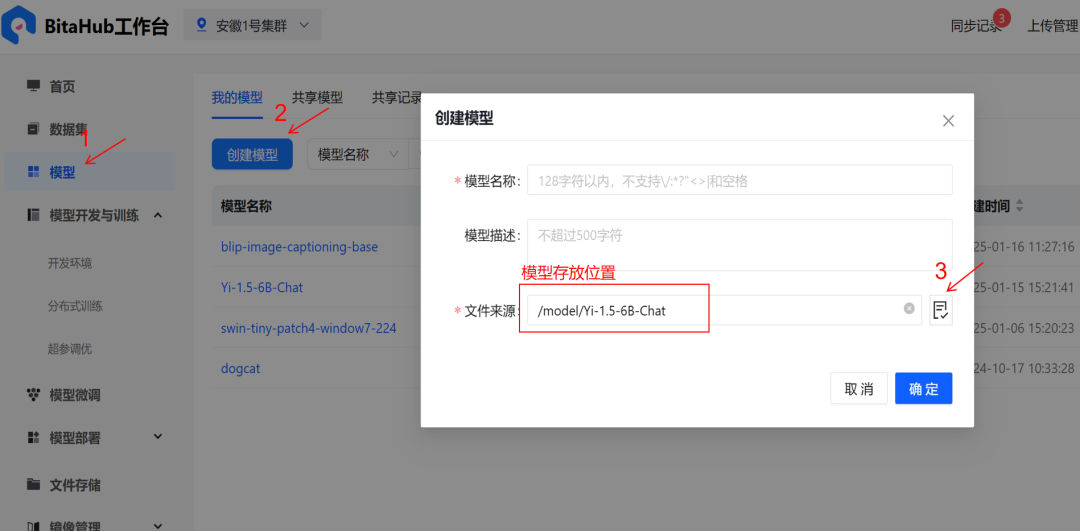
4.在「模型开发和训练」中,创建新的开发环境。
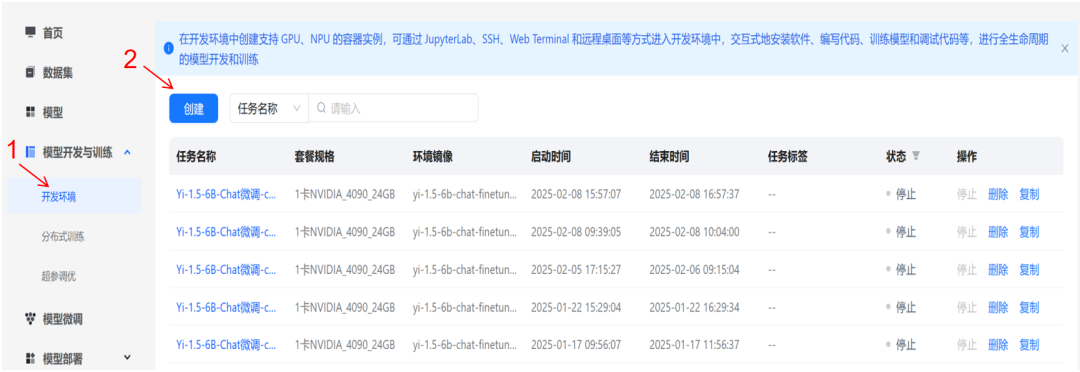
在「存储挂载」中点击模型,添加上面创建的模型;选择平台镜像。
选择 JupyterLab访问方式,单卡4090GPU套餐。
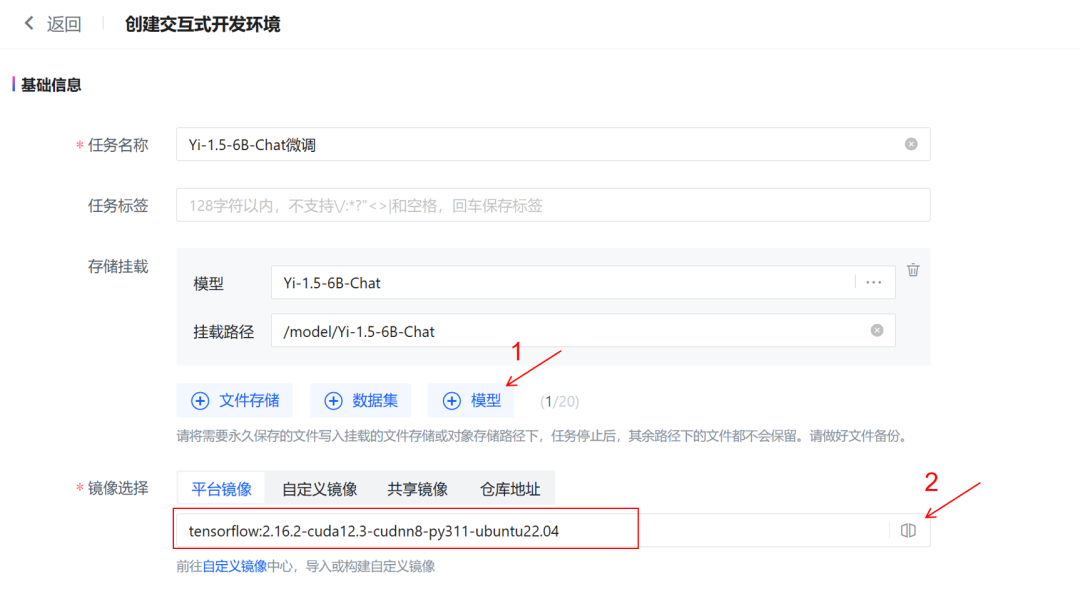
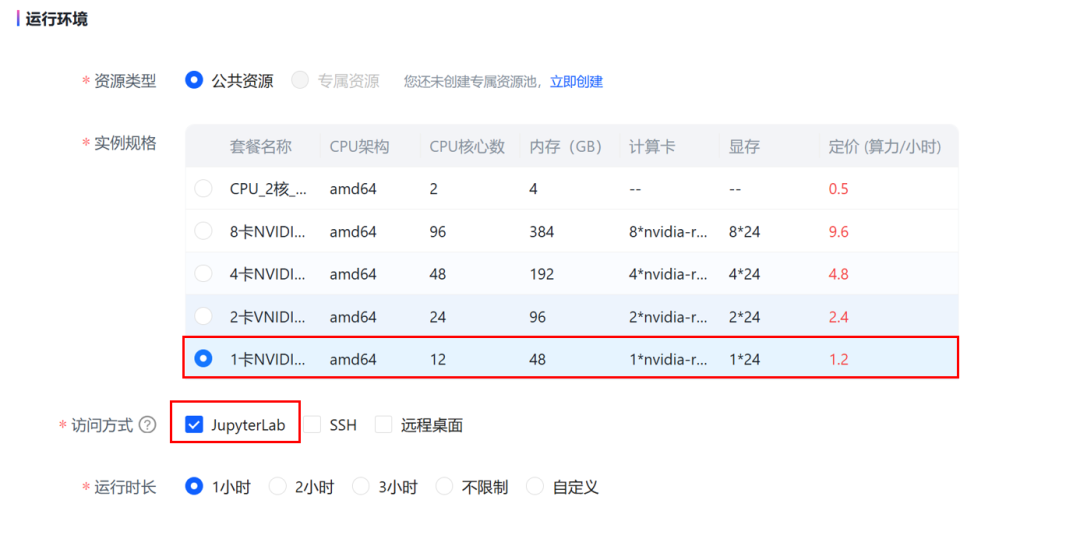
点击确认后,等待任务进入运行状态。
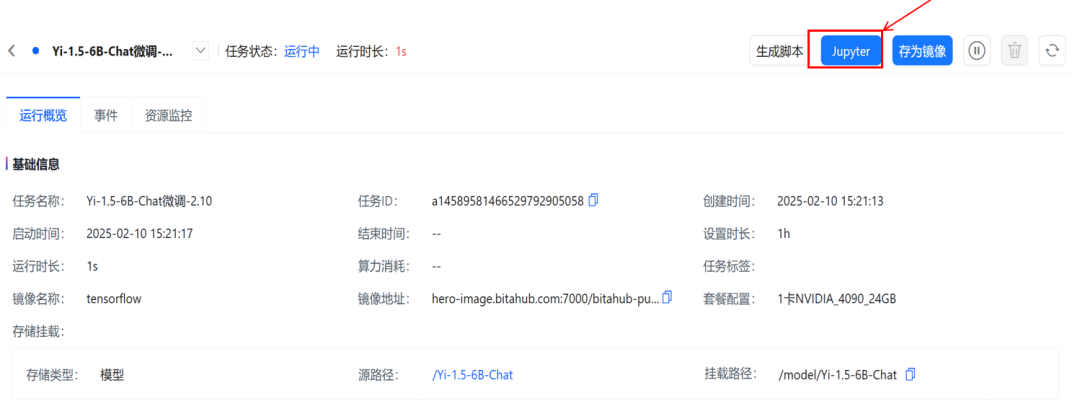
二.环境准备
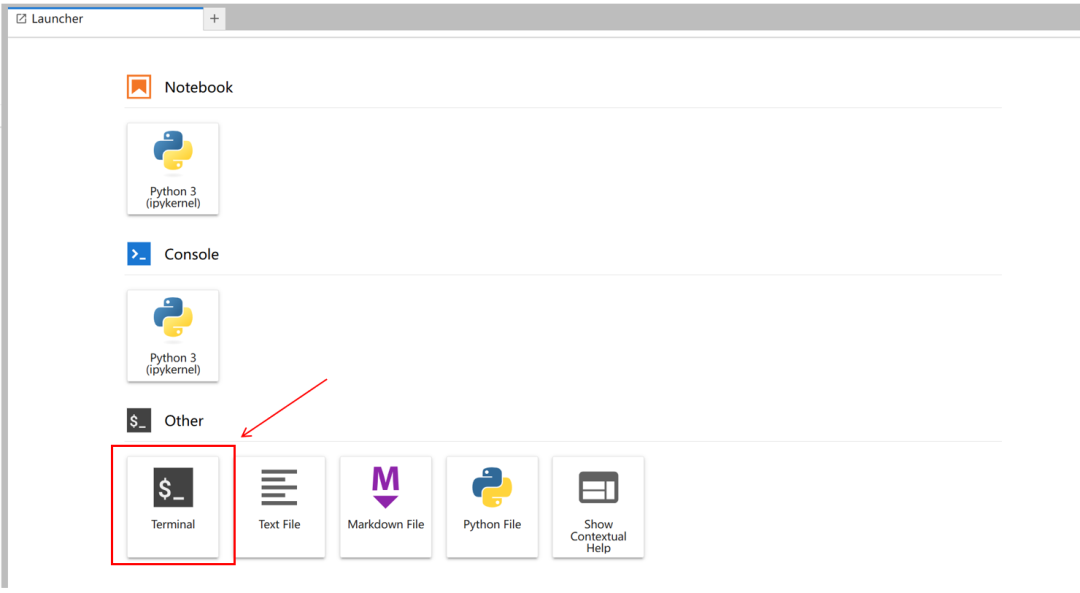
如下箭头所示,点击即可创建一个新的 Notebook 页面。

在正式微调之前,在代码块中执行以下命令,安装依赖的工具和库。
!pip3 install --upgrade pip!pip3 install bitsandbytes>=0.39.0
在微调 Yi - 1.5 - 6B - Chat 的流程里,LLaMA - Factory 项目提供了诸多有用的工具与资源,我们需要从 GitHub 仓库克隆 LLaMA - Factory 项目到本地。
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git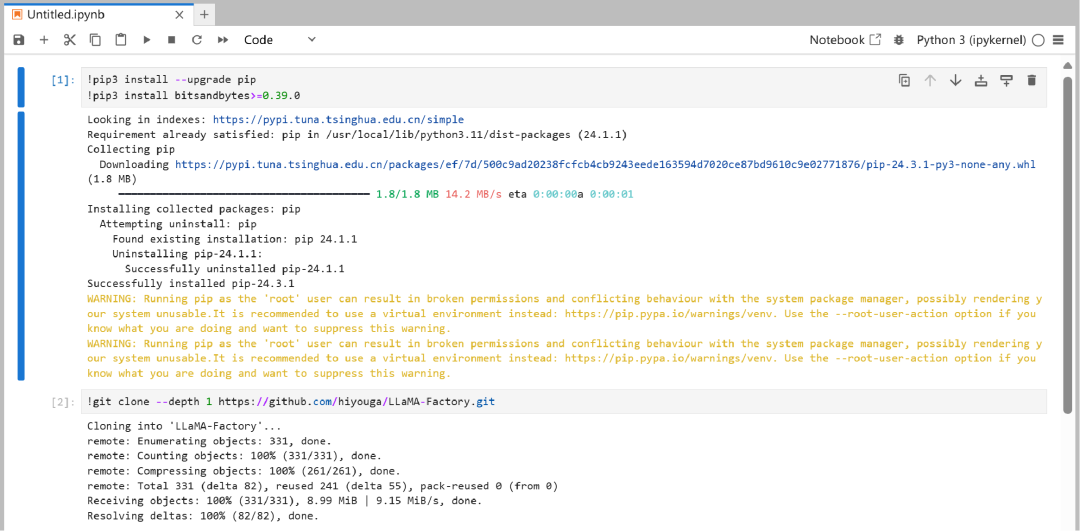
在前面成功克隆 LLaMA - Factory 项目到本地后,我们需要启动终端并执行以下两行命令。
cd LLaMA-Factorypip3 install -e ".[torch,metrics]"
运行 cd LLaMA - Factory 时,这行命令的作用是将当前的工作目录切换到刚刚克隆下来的 LLaMA - Factory 项目文件夹中。在命令行操作里,许多后续的指令都需要在项目的根目录下执行,只有进入到这个特定的目录,才能确保后续对项目文件和代码的操作是有效的。
pip3 install -e ".[torch,metrics]" 这一命令是为了安装 LLaMA - Factory 项目运行所需的依赖包。
三.微调过程
创建微调训练相关配置文件
到目前为止,我们已经完成了前期的环境搭建和依赖安装,接下来就要创建微调训练所需的配置文件。这一步至关重要,它决定了我们在微调过程中的各项参数设置,直接影响模型的训练效果。
1.在左侧的文件列表中,找到之前克隆的Llama - Factory文件夹。这是我们存放微调项目相关代码和文件的地方。
2.进入examples文件夹,然后找到train_qlora文件夹(这里一定要注意,不是train_lora文件夹)。在train_qlora文件夹下,已经为我们提供了一个名为llama3_lora_sft_awq.yaml的配置文件模板。
3.复制llama3_lora_sft_awq.yaml文件,然后在同一目录下,将复制后的文件重命名为yi_lora_sft_bitsandbytes.yaml。新的文件名更贴合我们对 Yi - 1.5 - 6B - Chat 模型的微调操作,方便后续区分和管理。
打开刚刚创建好的yi_lora_sft_bitsandbytes.yaml文件。在文件的第一行,你会看到model_name_or_path这个参数,它的作用是指定我们要微调的模型所在位置。(逐行对比其余内容,进行修改和补充)
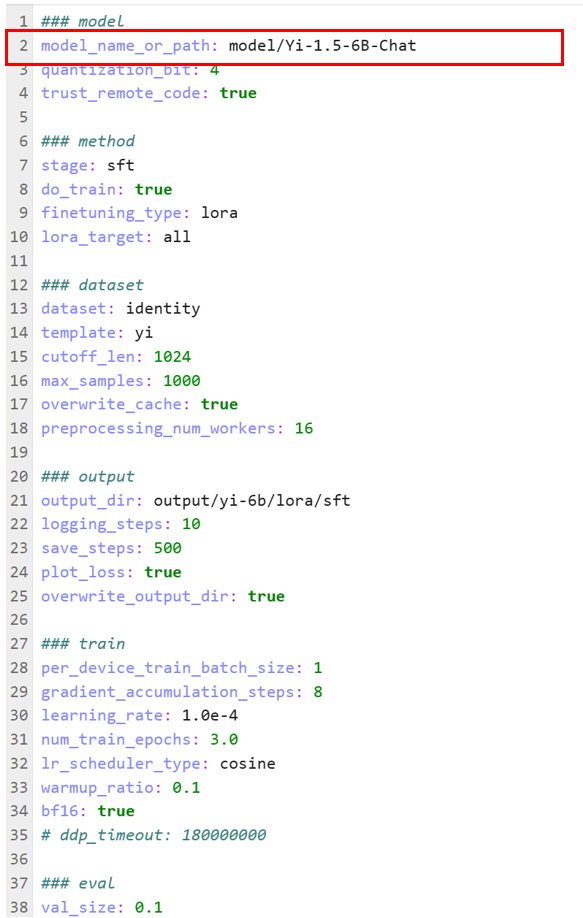
通过这一步,我们就为模型微调指定了正确的起点。完成这一设置后,距离成功微调模型又近了一步。从上面的配置文件中,我们了解到本次微调使用的数据集是 “identity”。这意味着当向模型询问 “你好你是谁” 时,模型会回复 “我叫 name 由 author 开发” 。

如果你想拥有一个独一无二、打上自己烙印的大模型,完全可以通过修改数据集来实现。目前我们使用的是identity.json文件作为数据集,你只需将文件中的{{name}}字段替换为你自己的名字,就能开启打造专属大模型的微调之旅。这样一来,当你完成微调并与模型交互时,它就会以你的名字来进行自我身份的介绍。
下面给出一段修改数据集代码示例:
import json# 定义替换的字符串replacements = {"{{name}}": "{{Yi}}","{{author}}": "{{零一万物}}"}# 读取JSON文件with open('identity.json', 'r', encoding='utf-8') as file:data = json.load(file)for item in data:for key in item:if isinstance(item[key], str):for old, new in replacements.items():item[key] = item[key].replace(old, new)# 将修改后的数据写回JSON文件with open('identity.json', 'w', encoding='utf-8') as file:json.dump(data, file, ensure_ascii=False, indent=4)print("替换完成")
当你在代码块运行看到输出 “替换完成” 的提示时,就表示已经成功修改了数据集,为模型的个性化微调做好了准备。

随后我们需要回到终端terminal,开启模型微调,在确认处于LLaMA - Factory目录后,输入启动微调脚本的命令:
llamafactory-cli train examples/train_qlora/yi_lora_sft_bitsandbytes.yaml
开始微调
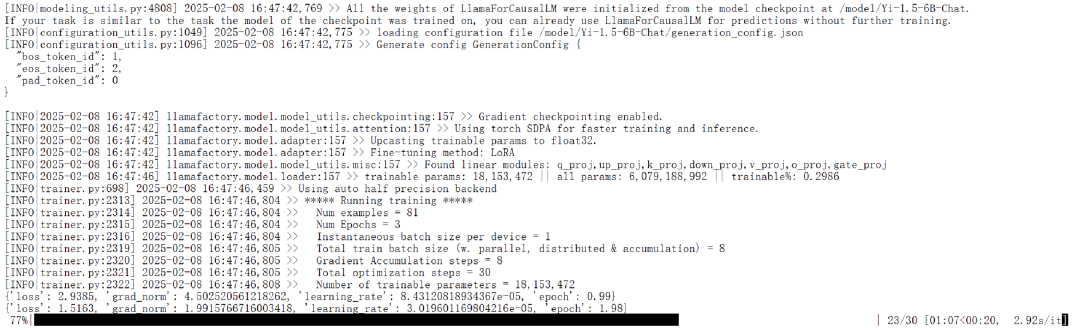
微调结束
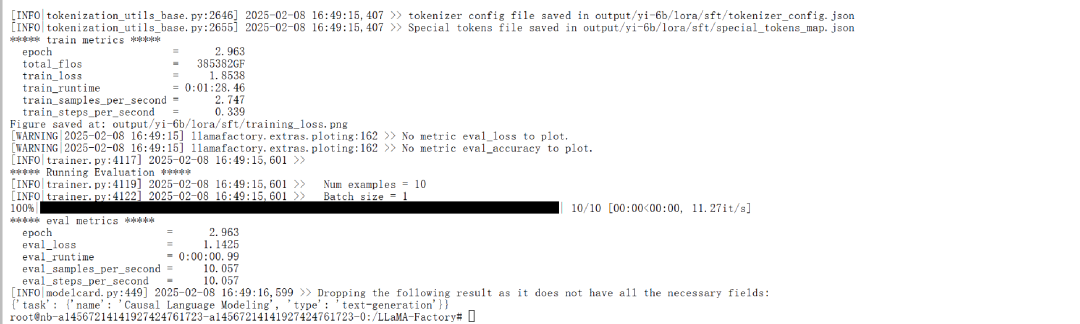
四.推理测试
通过加载微调后的模型进行推理,我们能直接观察模型在回答问题、生成文本等任务上的表现,从而判断模型自我认知的更改是否成功,以及对话能力是否依旧保持良好。这一步对于评估整个微调过程的成效至关重要。
1.找到配置文件模板:在之前克隆的Llama - Factory文件夹中,进入examples\inference目录。这里存放着与模型推理相关的配置文件,其中llama3_lora_sft.yaml可以作为我们测试的配置文件模板。
2.复制并重命名配置文件:为了适应对 Yi - 1.5 - 6B - Chat 模型的推理测试,我们需要复制llama3_lora_sft.yaml文件,并在同一目录下将其重命名为yi_lora_sft.yaml。新的文件名能够让我们清晰区分这是针对 Yi - 1.5 - 6B - Chat 模型微调后推理测试的专属配置文件。
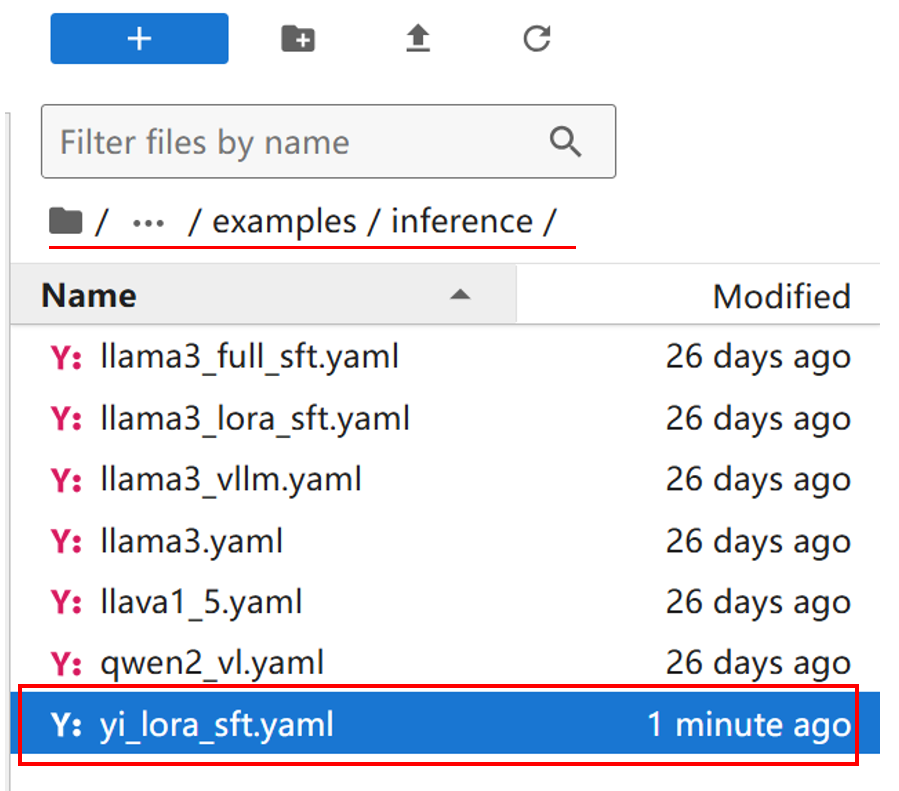
更改该文件中的内容并保存。

找到并打开之前进行模型微调操作的终端 Terminal,运行下面的推理命令。
llamafactory-cli chat examples/inference/yi_lora_sft.yaml在成功运行推理命令后,模型需要一些时间来完成加载,这期间请耐心等待。模型加载完成后,你就可以与它展开对话了。此时,你可以向模型提出一些问题,比如 “你好,你是谁” 。通过与模型的交互,你会发现模型的自我身份认知已经被成功更改。正如我们在微调过程中设置的那样,模型现在的自我身份认知与数据集中规定的样子一致。同时,在与模型的交流中,你还会惊喜地发现,模型并没有因为更改自我身份认知而丢失通用对话能力。

BitaHub社区更多模型及教程持续更新中,期待您的关注!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)