ACL’25 | 群体比较推理释放LLM-as-a-Judge 在评测中的scaling效果
我们的观察是高质量的评测通常涵盖对细节更深入的比较,而存在缺陷的推理往往只关注有限的细节,从而导致评测结论的过早收敛与不完整性。此外,我们的研究证明,高质量的CoT推理不仅能够提升多个评测基准上的评测可靠性,还能提高CoT蒸馏的效率,同时拓展了基于群体评测方法的应用范围。进行对比时,能够强调不同的细节,提供更全面的视角,促进更深入的推理。为解决这一挑战,我们在本文中提出了一种新颖的基于群体的比较评

来源:AI TIME 论道
本文共5300字,建议阅读5分钟
本文将详细介绍该算法的理论基础、实现步骤以及在降维任务中的具体应用。
作者:张启源,香港城市大学博士生

内容简介
LLM-as-a-Judge,基于生成中间的评测推理过程(CoT)从而得到判断,已成为广泛采用的自动评测方法。然而,由于CoT推理往往无法捕捉全面且深入的细节,导致评测结果不够完整,其可靠性因此受到限制。 现有方法通常依赖于多数投票或标准扩展(criteria expansion),但这些方法并不足以有效解决推理中存在的上述局限性。因此,我们提出了一种名为基于群体的比较评测(Crowd-based Comparative Evaluation,简称CCE)的新方法,通过引入额外的群体回复(crowd response)与待评测回复进行对比,从而揭示待评测回复中更深入且更全面的细节。这一过程有效地引导 LLM-as-a-Judge 输出更为详细的 CoT 推理。广泛的实验表明,我们的方法显著提高了评测的可靠性,在五个评测基准上平均提升了 6.7% 的准确率。此外,我们的方法还能生成更高质量的 CoT 推理,有助于进一步的 Judge 蒸馏,并无缝衔接地提升监督微调(SFT)的拒绝采样(rejection sampling)任务,我们称这种方法为 crowd rejection sampling,从而实现了更加高效的监督微调。进一步,我们分析验证了我们方法生成的 CoT 更加全面且质量更高,并且评测准确率会随测试时计算规模(test-time computation)的扩大而持续提高。
研究背景
由于人工评测成本高昂且难以扩展规模,LLM-as-a-Judge 已逐渐成为一种可扩展的自动评测框架。 给定一个任务指令以及对应候选回复(candidate responses),LLM-as-a-Judge 利用CoT推理,对回复的细节质量进行细致分析,并最终给出评测结果。尽管近年来引入 CoT 推理、设计专门的评分准则(rubrics)以及与合成对齐偏好的训练数据集等技术不断进步,但受限于持续存在的不足,人工评测仍被视为评价的黄金标准。这些不足包括评测时的偏见问题以及对误导性上下文的敏感,它们都严重削弱了自动评测的可靠性。这里,一个重要但被忽略的原因是,CoT 推理质量取决于模型是否能够全面地比较不同回复中的细节差异。我们的观察是高质量的评测通常涵盖对细节更深入的比较,而存在缺陷的推理往往只关注有限的细节,从而导致评测结论的过早收敛与不完整性。因此,如何提高大语言模型在评测推理的丰富性与全面性对于提升 LLM-as-a-Judge 评测质量至关重要。
目前,研究者普遍采用的两种策略试图解决这一问题:多数投票和标准扩展。多数投票策略以并行方式独立生成多个判断结果,再通过投票整合结果,本质上利用温度采样(temperature sampling)的随机性,鼓励模型进行更详尽的推理。然而,这种方法相对被动且计算开销较大。相比之下,标准扩展策略通过增加额外的评测维度,更主动地引导模型考虑更多方面。然而,这种方法缺乏对具体回复内容的感知,难以针对每个回复独特的细节进行适应性评测。举例来说,即便一个回复充满细致的洞察,仅仅增加“准确性”等标准,也难以促使 LLM 主动捕捉其推理中的独特细节。因此,这两种策略均无法有效地引导 LLM-as-a-Judge 持续产出细致且全面的 CoT 推理。这就引出了一个关键的研究问题:我们如何引导 LLM 在评测时进行更深入、更富细节的 CoT 推理?
研究动机
为解决这一挑战,我们在本文中提出了一种新颖的基于群体的比较评测方法(CCE),它可以让LLM-as-a-Judge 能够揭示更多有价值的细节,如图1所示。
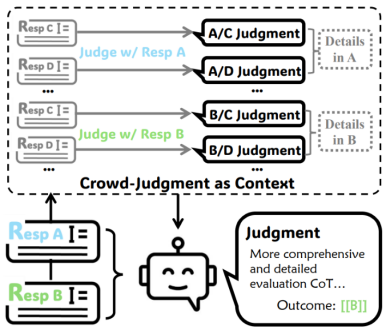
图1. 通过将候选回复 A/B 与群体回复(crowd responses)一同评测,得到的群体判断(crowd judgment)可作为上下文,用于丰富对 A/B 回复的评测,从而实现更加全面的推理判断。
我们的方法受到人类评测行为的启发:人类在评估候选对象时,不仅单独审视该对象,还会与其他对象进行对比,从而发现更多细微的洞察。群体回复在这一过程中充当了认知脚手架(cognitive scaffolding)的作用,强制评测模型遍历不同质量层级的回复特征,激发其对候选回复特征的深度理解。
基于这一原理,CCE首先收集一系列针对任务指令的备选回复,即群体回复,然后将每个候选回复与这些群体回复进行对比,生成多个群体判断。在此过程中,群体回复的多样性成为多个评测参照点,从不同维度揭示候选回复的更多细节。通过这种方式,CCE 能够促使 LLM-as-a-Judge 执行更全面且更深入的整体 CoT 推理判断。
方法介绍
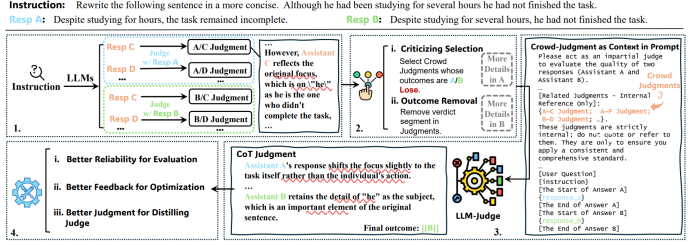
图2. 我们提出的基于群体的比较评测框架的流程示意图。
问题定义:假设任务指令为 ,由两个待测模型分别生成两个候选回复 { } ,普通的 LLM-as-a-Judge 基于一系列特定的评测标准 (如正确性、一致性等),通过推理对回复 和 做出判断 :
这里的目标是确保模型给出的判断 与人类评测高度一致。在两两比较场景中,这种一致性通常通过与人类标签相比的准确率来衡量。
群体回复与判断生成: 基于任务指令 ,我们首先利用LLM生成 个合成的群体回复{ }。为了提高这些回复的多样性,我们可以使用不同规模的LLM,从小模型(如Qwen2.5-0.5B-Instruct)到大模型(如Mistral-Nemo-Instruct-2407),并采用不同的温度参数。理论上,多样化的回复能覆盖更广泛的场景。当这些群体回复与候选回复 和 进行对比时,能够强调不同的细节,提供更全面的视角,促进更深入的推理。如图2所示,群体判断揭示了“he”的重要性,其中回复A巧妙地将动作主体“he”转换为对象“task”本身,从而违反了指令中关于改写但保持原意的要求。我们随后利用这一信息作为上下文强化后续的CoT推理。这种优势优于标准扩展,因为后者无法预先提示此类细节。 对于每个合成的群体回复 , 分别独立地产生两个群体判断和,通过分别将与 和 进行比较:
我们正式地收集了 2 个群体判断:
尽管每个单独判断可能无法完全捕捉候选回复的所有细节,但它们共同构成了丰富的证据池,展现 和 之间细微的差异。
群体判断选择与处理: 获得群体判断后 ,关键环节在于如何有效地选择和处理这些判断。随机选择既不稳定也非最优,我们因此提出了一种简单但有效的策略,称为批评性选择(Criticizing Selection)。具体而言,我们根据判断结果进行选择:对于 ,保留批评A(A失败)的判断;对 ,保留批评B(B失败)的判断。之后的实验证明,批评性判断往往包含对被批评回复更详细且信息丰富的分析。例如,评测可能明确指出回复如何混淆关键概念,并详细阐述定义错误和相关理论依据。我们也探讨了两种其他选择策略:赞扬性选择(Praising Selection)和平衡性选择(Balanced Selection)。然而,这两种策略的表现均不及批评性选择。赞扬性判断往往过于简单,可能仅声明“此答案正确”,缺乏进一步分析。此外,为减少群体判断中结果导向的偏差,我们引入了结果移除(Outcome Removal)技术,由LLM重写 以删除显式的结果部分,确保更为中立的评测。
选择和处理完成后,我们得到 。值得注意的是, 不仅包含对候选回复( )的判断,还包括对 自身的CoT推理。我们的初步研究表明移除这些关于 的CoT片段并不能提升表现,因此我们保留了这些部分,以保持方法的简单性。
上下文增强推理: 最终判断通过在任务指令 、标准 和处理后的群体判断 条件下评测回复 和 来获得:
值得一提的是,我们对生成的 进行蒸馏以训练一个更小的评测模型,实验证明其性能优于基于 蒸馏的评测模型,证实高质量的CoT推理能提升蒸馏效果。
扩展应用—Crowd拒绝采样在SFT中的应用: 本节展示了CCE的广泛适用性,以其在监督微调(SFT)中的拒绝采样任务为例。拒绝采样已被证明是有效的SFT增强技术。传统拒绝采样通常是通过两两比较选择最优回复,而CCE能够自然地适应多个候选回复的场景,我们称之为crowd rejection sampling。在两两比较任意两个候选回复时,我们有效利用额外的 个回复作为群体回复,从而确保更详细、更一致的判断。实验验证表明,这种crowd拒绝采样能够显著提升采样的可靠性和可解释性,最终改善微调模型的整体性能。
实验表现
在多种benchmarks上展现出显著的优势
我们采用了五个偏好评测基准来测试 LLM-as-a-Judge,包括 RewardBench、HelpSteer2、MTBench-Human、JudgeBench和 EvalBias。这些基准涵盖了广泛任务场景下的通用指令,并提供了多样化的候选回复,通过准确率指标衡量模型的评测表现,每个基准分别侧重于不同的评测维度。
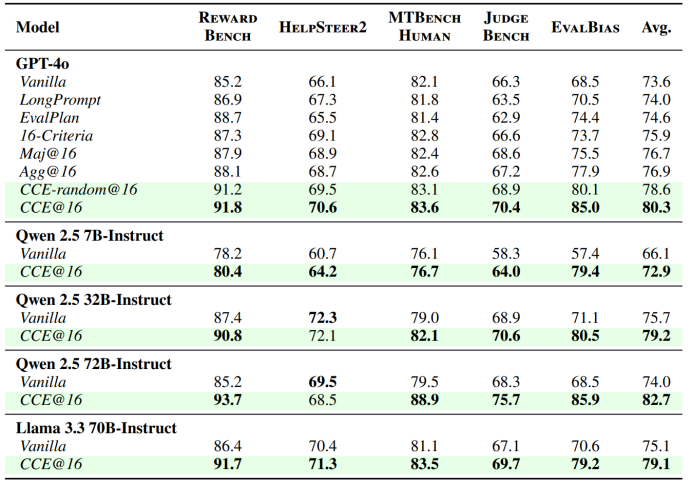
表1 LLM-as-a-Judge 在成对比较基准上的准确率表现。CCE能够在全部5个基准上稳定提升LLM-as-a-Judge的评测性能,尤其显著优于其他推理扩展策略(如maj@16)。表中最佳结果已用粗体标出。这里,CCE-random 表示随机选择群体判断的CCE变体。
我们在5个不同的LLM上验证了CCE方法的通用性,并与多个基线进行了比较。这些基线包括:
-
Vanilla:使用RewardBench设计的通用LLM-as-a-Judge提示进行评测;
-
Maj@16:对每个案例独立执行16次评测,最终以多数投票方式确定结果;
-
Agg@16:与多数投票不同,将16个独立评测结果反馈给LLM,由其汇总后再生成最终评测;
-
16-Criteria:在Prompt中加入16个具体的评测标准及其描述;
-
LongPrompt:明确要求LLM生成更长的CoT推理;
-
EvalPlan:首先针对待评测案例生成一个不受约束的评测计划,然后执行该计划得出最终判断。
蒸馏CoT以训练Judge模型
首先选取一个大规模偏好数据集,分别使用Vanilla LLM-as-a-Judge和CCE(均基于GPT-4o-as-a-Judge)对数据进行评测,生成两组对应的CoT推理结果。随后,我们分别将这两组CoT与原始偏好数据结合,构建出两套独立的训练数据集,用于微调规模更小的LLM作为Judge模型。最终训练出的Judge模型的表现清晰地反映了各自CoT的质量与有效性。
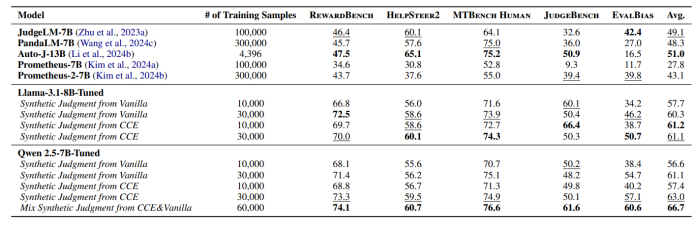
表2. 经过训练的小规模 LLM-as-a-Judge 在成对比较基准上的准确率表现。在相同的偏好数据对条件下,基于 CCE 方法合成判断训练的模型能够获得更可靠的评测结果。表中最佳结果以粗体标出,次佳结果以下划线标注。
表2表明,高质量的CoT能够实现更有效的蒸馏,从而显著提升小型Judge模型的评测性能。具体而言,基于CCE生成的CoT对小模型(例如Llama 3.1-8B 和 Qwen 2.5-7B)进行微调后,在全部五个评测基准上均获得了比Vanilla CoT更高的准确率。例如,利用CCE合成的CoT微调的Qwen 2.5-7B模型在RewardBench上达到了73.3%的准确率,显著超过了Vanilla基线1.9个百分点。此外,将Vanilla和CCE的合成CoT进行结合,进一步提高了模型表现,在RewardBench和EvalBias基准上的准确率分别达到74.1%和60.6%。这一结果说明,整合多样化的CoT能够进一步提高模型的准确性和泛化能力。
LLM-as-a-Judge在不同场景下可能会出现偏差,例如倾向于选择更冗长的答案,这一问题在规模较小的Judge模型中尤为突出。如表2所示,即使在超过10万条样本上进行微调,许多基线模型的表现仍难以超过50%的准确率,这突出体现了评测偏差问题的持久性。更高质量且更全面的CoT蒸馏则显著提高了小模型纠正偏差的能力。这些发现表明,模型的许多偏差并非源自对回复本身的理解不足,而是因为模型过于关注回复的局部细节,而未能进行整体评估。
在SFT拒绝采样中的有效性
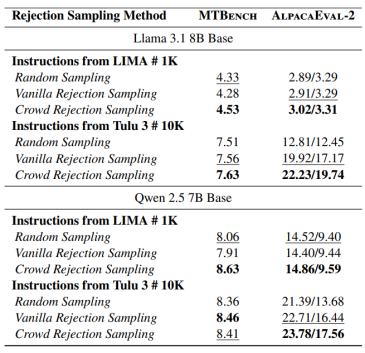
表3. SFT拒绝采样在指令遵循基准上的表现。使用CCE进行拒绝采样后微调的模型展现出了更优的生成性能。
如3所示,群体拒绝采样方法在1K和10K数据规模下均表现出了显著的有效性,在两种基础LLM模型上均稳定地提高了微调性能。与随机采样(Random Sampling)和传统拒绝采样(Vanilla Rejection Sampling)相比,CCE能够选出质量更高的回复,因而在MTBench和AlpacaEval-2等下游指令遵循基准中取得了稳定的性能提升。例如,在Llama 3.1-8B模型与TULU3-SFT指令下,使用CCE微调的模型在AlpacaEval-2上分别达到了22.23/19.74的表现,而Vanilla拒绝采样方法仅为19.92/17.17。这一结果进一步凸显了CCE在识别高质量训练样本上的可靠性。
整体而言,实验验证了CCE在三种关键通用场景中的灵活性与有效性。通过利用基于群体的上下文、扩展推理时的计算规模,以及策略性地引导CoT推理过程,CCE相比多个强大基线方法实现了持续稳定的性能提升。
评测过程中激发出Test-time Scaling的特征
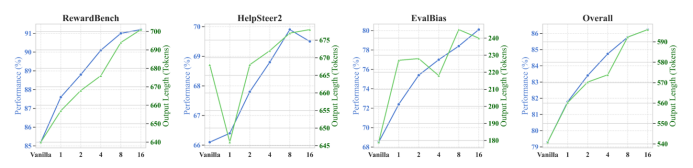
图3. 在上下文中扩展群体判断数量时的评测表现。随着群体判断数量的增加,模型的准确率和CoT推理的长度总体上均呈现上升趋势。
图3展示了我们关于扩展群体判断数量如何影响评测结果的分析。我们通过准确率和CoT的平均生成长度两个指标,对三个偏好评测基准在不同群体判断数量下的表现进行了测试,并取平均以进行整体评估。
如表4所示,当群体判断数量从0增加到16时,模型的评测性能和输出长度总体上均呈现上升趋势。RewardBench表现出了明显的持续增长趋势,而HelpSteer2在群体判断数量为2时出现短暂下降,随后恢复上升趋势。从所有基准的平均结果(最右侧子图)中也可以明确看出,增加群体判断的数量能够提升评测准确率并延长CoT的输出长度,这与已有test-time scaling研究中观察到的推理扩展效应相吻合。
CoT推理对比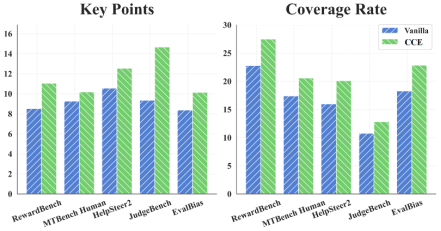
图4. CoT推理对比。在所有评测基准上,CCE方法生成的CoT推理始终具有更高的平均关键点数量和更高的细节覆盖率。
为了更直接地评估CCE生成的CoT是否比Vanilla LLM-as-a-Judge的CoT更加全面,我们进行了两项分析:关键点计数(Key Points Counting)与覆盖率(Coverage Rate)评估。首先,我们使用GPT-4o解析并总结每个CoT的内容,通过统计关键点数量来衡量CoT推理的完整性;其次,我们利用Bart-base的跨注意力机制量化CoT对候选回复细节的覆盖率,即评测CoT对候选回复细节分析的彻底程度。
如图4所示,在所有评测基准上,CCE方法在关键点数量与覆盖率两个指标上均显著优于Vanilla方法。更多的关键点意味着我们的CoT推理能够从更多角度审视文本内容,而更高的覆盖率则体现了更深入、更细致的分析能力。这些结果表明,相比Vanilla方法,CCE能够提供更深入且更全面的评测推理。
总结
在本研究中,我们从人类评测行为中汲取灵感,针对LLM-as-a-Judge在CoT推理中缺乏全面性与细节性的不足,提出了一种新颖的基于群体的比较评测框架。该框架通过丰富CoT推理过程,有效提高了评测的全面性和可靠性。相比传统的多数投票和标准扩展方法,我们的策略能够更高效地扩展推理规模。此外,我们的研究证明,高质量的CoT推理不仅能够提升多个评测基准上的评测可靠性,还能提高CoT蒸馏的效率,同时拓展了基于群体评测方法的应用范围。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)