LLM 模型架构核心对比:主流选型的结构特征与适用场景分析
大模型的性能表现,核心受制于模型架构、训练数据质量与规模、训练算法设计等关键因素。不过,当前行业内多数模型出于技术保密或商业隐私考量,并未公开训练数据、训练算法等核心信息,导致难以对其性能进行全面、深入的多维度对比。为简化研究问题、聚焦可量化的分析维度,本文将对比范围限定为**2025年以来的主流大语言模型(LLM)** ,且仅围绕“模型架构”这一公开可得、可系统拆解的核心要素展开对比分析。具体而
大模型的性能表现,核心受制于模型架构、训练数据质量与规模、训练算法设计等关键因素。不过,当前行业内多数模型出于技术保密或商业隐私考量,并未公开训练数据、训练算法等核心信息,导致难以对其性能进行全面、深入的多维度对比。
为简化研究问题、聚焦可量化的分析维度,本文将对比范围限定为2025年以来的主流大语言模型(LLM) ,且仅围绕“模型架构”这一公开可得、可系统拆解的核心要素展开对比分析。具体而言,本次架构对比将涵盖以下模型:
- DeepSeek V3/R1
- Kimi 2
- Llama 4
- Qwen3
- OLMo 2
- Gemma 3
- Mistral Small 3.1
- SmolLM3
一、DeepSeek V3/R1
严格来讲DeepSeek V3是2024年11月发布的,但由于其是在2025年1月DeepSeek R1发布后爆红的,因此文章也将其包含了进来。
正如,笔者之前在《【大语言模型演进史】三、DeepSeek系列模型》里对其技术报告的解读中强调的一样,DeepSeek V3在模型架构的两个主要改进是:
- 多头潜在注意力(multi-head latent attention,MLA)
- –> 优化注意力部分
- DeepSeekMoE(Mixture-of-Experts model,混合专家模型)
- –> 优化FFN部分
1.1 MLA
问题:
传统的注意力模块MHA,在进行KV cache的时候,特别是对于长上下文的场景下,存在内存占用大的问题。常见的解决方法,如Llama采用的方法,如下图所示,GQA(分组注意力,Grouped-query Attention)是通过共享KV向量,来减少需要需要缓存的信息(关于KV cache不了解的读者,可以参考我之前整理的Sebastian Raschka的文章《大模型推理时的KV cache介绍和实践》)。同时,GQA也在一定程度上减少了模型的计算,因为只需要计算更少的KV向量。但DeepSeek的研究人员们认为,GQA会对模型的效果产生一定的负面影响,因此提出了MLA。
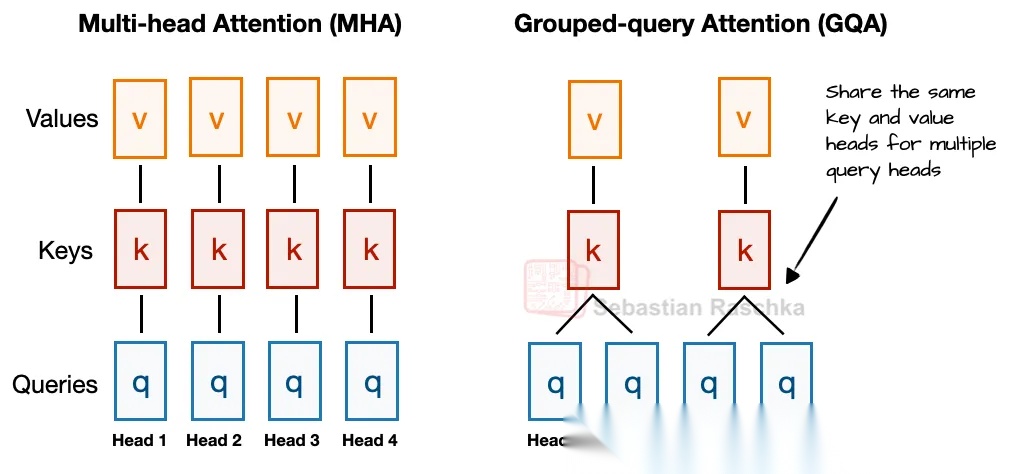
做法:
MLA通过对KV向量进行压缩(顺便一提,Q向量也会被压缩,但仅在训练时压缩),来降低内存占用。具体做法,如下图所示,将输入向量通过下映射矩阵进行压缩,并进行缓存,再通过上映射矩阵将压缩矩阵还原为KV向量。
需要强调一下,这里原博主进行一定的简化,DeepSeek的技术报告中,为了利用矩阵“吸收”的性质,包含了有RoPE和无RoPE的两个分量,两者处理略有不同。这里主要提到的是后者,指的是无RoPE的分量是怎么处理的。
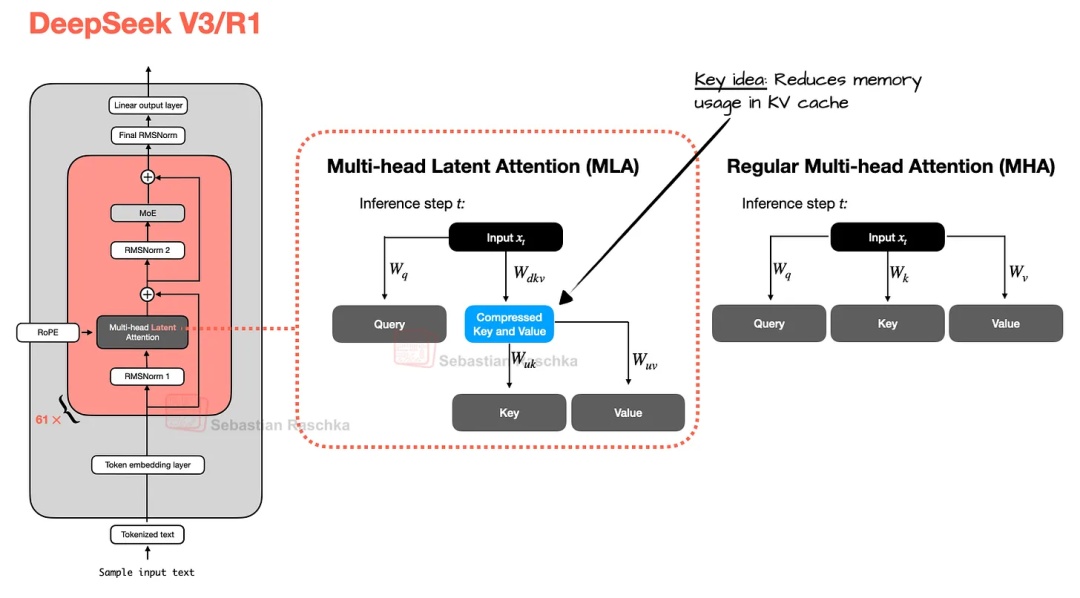
小结:
MLA通过向量压缩,减少了KV caceh的内存使用,同时在建模性能方面略微好于MHA。
1.2 DeepSeekMoE
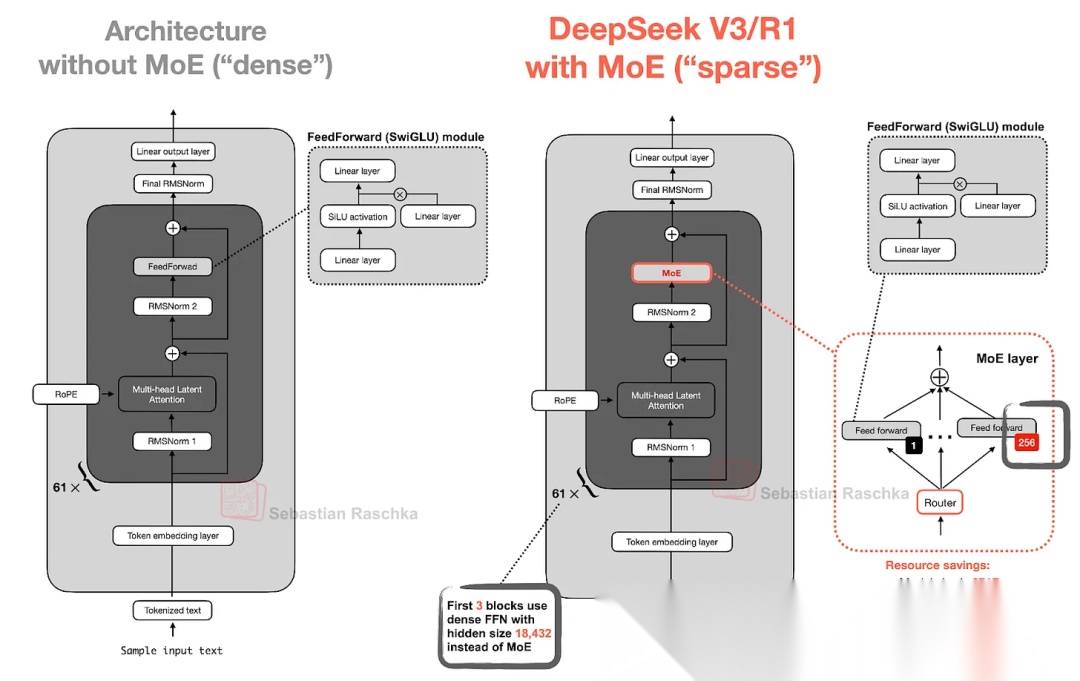
MoE的核心思想是用多个专家层替换Transformer块中的FFN(前馈层),其中,每个专家就是一个FFN。也就是说,使用了多个FFN替换了单个FFN。
如下图所示,通过使用多个FFN进行替换,可以增加模型参数,提升模型容量,意味着模型在训练过程中可以获取更多知识。同时,对每个token会通过一个类似“路由器”的模块,选择性地激活一小部分专家,以减少计算量。具体来讲,DeepSeek V3中一共有256个专家,每个token会激活1个共享专家和8个路由专家,激活参数量为37B(全量参数671B)。
由于每次只有少数专家处于活跃状态,MoE模块通常被称为稀疏的(sparse),与此相对的,全量参数激活的模块则称为稠密的(dense)。
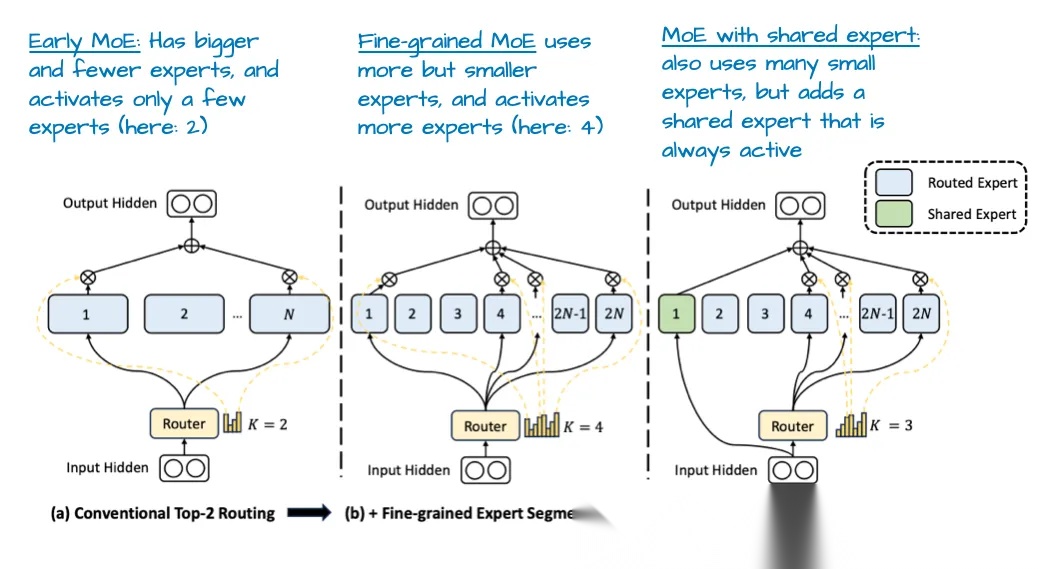
如下图所示,展示了MoE架构的改进过程,一个是,从少量参数量较大的专家到更多参数量小的细粒度专家,另一个是,引入了共享专家。引入共享专家的考虑,可能是由共享专家学习常见或重复的模式,而由其它路由专家学习更专业和细分的模式。
1.3 总结
DeepSeek-V3作为一个671B的模型,在发布时,就一举达到了开源模型的最佳效果。尽管模型参数量巨大,但由于MoE架构,每个只激活37B的参数,其推理时的效率反而对部分模型更高。
另外一个关键的改进,使用MLA取代了GQA,降低KV cache的内存占用,同时提升了模型建模能力。唯一的缺点是,MLA的实现相比GQA会稍显复杂一些。
二、Kimi 2
最近发布的Kimi 2引起了广泛的关注,能力表现很出色,如在编码能力上,能达到Claude和Gemini相当的水平。
K2的参数量达到了1T,激活参数量为32B,是当前开源LLM中参数量最大的。
K2的一个主要改进点是使用了Muon作为训练时的优化器,取代了AdamW。这也是Muon首次成功运用于如此大规模的LLM。博文关注在模型架构,故不进行过多介绍。
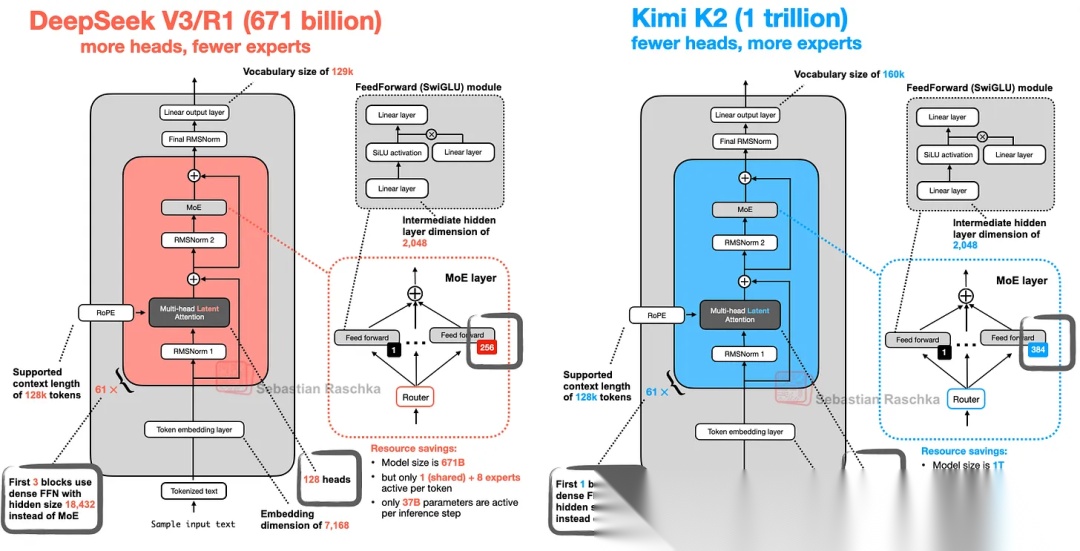
如下图所示,K2的模型架构基本上与DeepSeek V3相同,主要的区别是:
- K2在MoE中使用了更多的专家;
- K2在MLA中使用了更少的头;
- K2仅有第1个模块不是MoE架构,而DeepSeek V3是前3个模块。
三、Llama 4
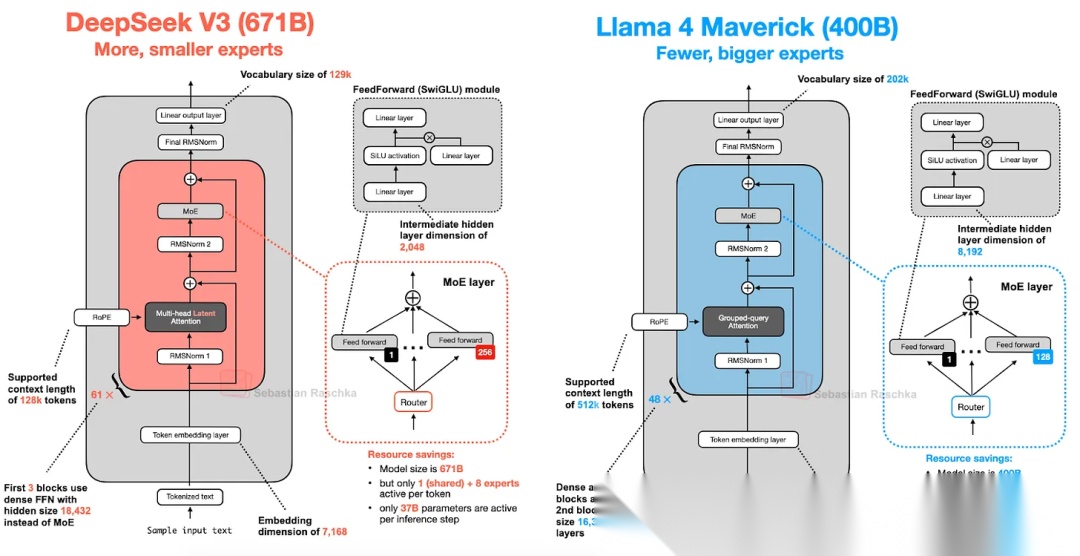
Llama 4 Maverick也采用了MoE的架构,其结构与DeepSeek V3也较为相似。如下图所示,Llama 4 Maverick的参数量为400B,激活参数量17B,二者架构上的主要区别是:
- Llama 4在注意力模块中使用GQA;
- Llama 4的专家数量更少且参数量更大,每次有1个共享专家和1个路由专家被激活;
- Llama 4在Transofrmer模块中交规使用MoE和Dense的FFN。
四、Qwen3
Qwen3提供了各种规模的模型,包括7个dense模型:0.6B、1.7B、4B、8B、14B 和 32B;2个MoE模型:30B-A3B 和 235B-A22B。
对比dense和MoE模型:
- MoE模型可以在提升模型容量的同时降低LLM的推理成本;
- dense模型更容易进行微调、部署和跨硬件的优化。
因此,Qwen3系列模型可以支持多种应用场景,dense模型用于鲁棒的、简单的和需要微调的场景,MoE模型用于大规模的高效部署。
4.1 Qwen3(dense)
Qwen3 0.6B适合在本地运行,它具有很高的token/sec的吞吐量和很低的内存占用,同时易于进行本地训练。
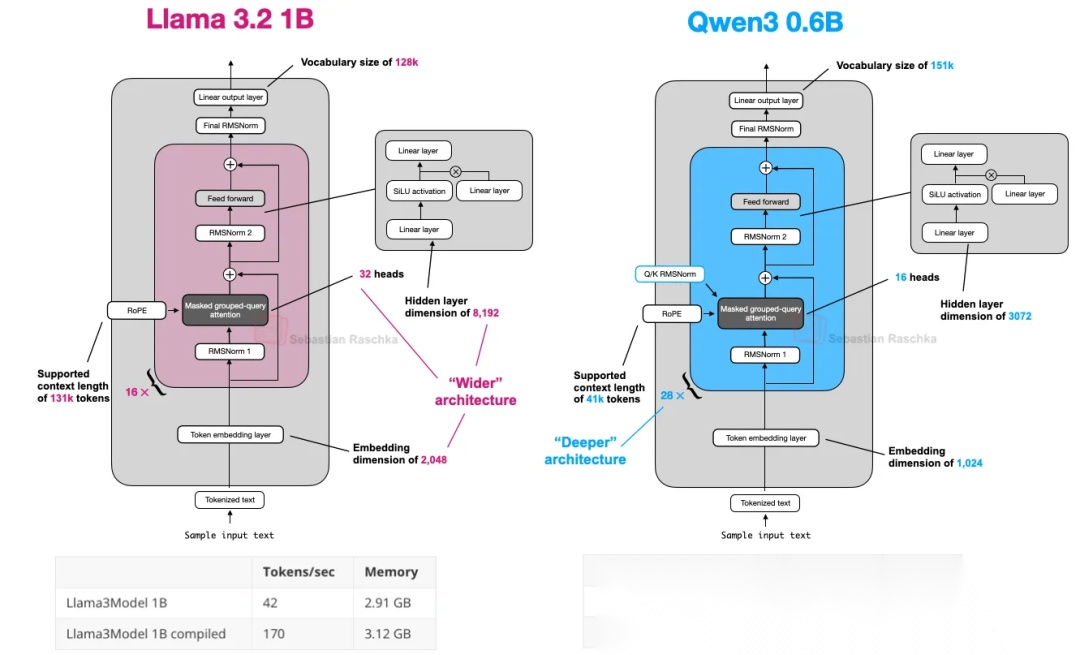
与同等规模的Llama 3.2 1B进行对比,如下图所示,二者的主要区别:
- Qwen3 0.6B在注意力模块中使用了Q/K RMSNorm;
- Qwen3 0.6B有更深(Deeper)的架构,有28个Transformer模块,而Llama 3.2 1B仅有16个;Llama 3.2 1B的模型会更宽(Wider),输入维度为2048,相比而言,Qwen3 0.6B为1024。
- Llama 3.2 1B由于其更少的Transformer模块数,推理速度会更快。
4.2 Qwen3(MoE)
Qwen3提供了两个MoE的模型,包括30B-A3B和235B-A22B。
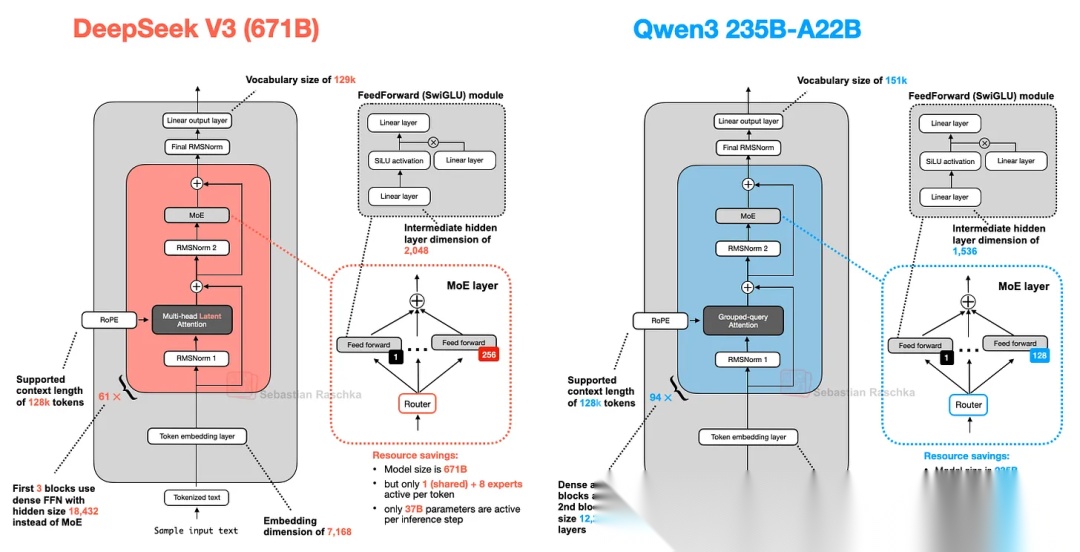
如下图所示,对比Qwen3 234B-A22B和DeepSeek V3的模型架构区别:
- Qwen3在注意力模块中使用GQA,而不是MLA;
- Qwen3不使用共享专家,仅有8个路由专家。根据Qwen3研发人员的介绍,是由于没有发现共享专家带来的收益,且担心其会对推理优化造成影响,因此将共享专家移除了;
- Qwen3和Llama 4类似,在Transofrmer模块中交替使用MoE和Dense的FFN。
五、OLMo 2
OLMo系列模型的主要特点是,公开了其训练数据和训练代码,并且有相对详细的技术报告。
OLMo模型虽然没有在LLM排行榜上达到位居前列的水平,但得益于其透明性,它是开发LLM的绝佳蓝图之一。
OLMo模型架构上的两个改进点:
- 调整了归一化层的位置;
- 使用了QK-Norm。
5.1 归一化层的位置调整
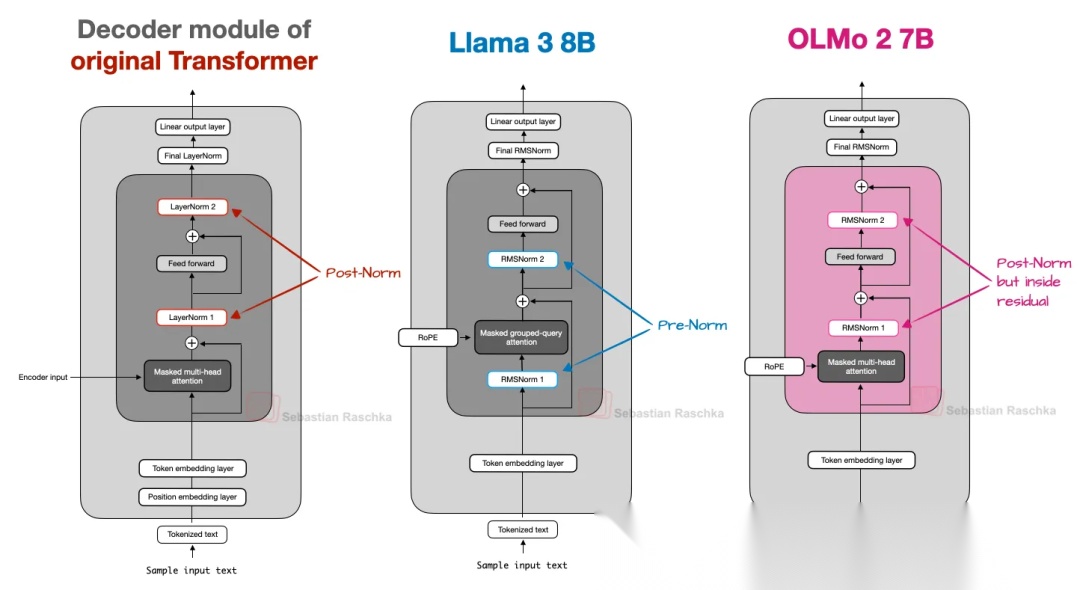
归一化层的位置,主要分为两类,Post-LN和Pre-Norm,如下图所示,
- Post-LN:原始的Transformer的两个归一化层位于注意力模块和FFN之后;
- Pre-LN:在Llama 3(包括上述的其它LLM架构中)中,归一化层位于注意力模块和FFN之前;
Pre-LN的广泛运用,来自于[参考资料:2],论文作者指出,Pre-LN在初始化时能产生表现更好的梯度,此外,Pre-LN在不进行学习率预热的情况下,也能表现良好,而学习预热是Post-LN的关键工具。
如下图所示,OLMo 2风格的Post-LN同样位于注意力模块和FFN之后,区别在于归一化层位于残差连接内部。这是因为,OLMo的研究人员认为这样有助于提升训练的稳定性。
5.2 QK-Norm
在Qwen3中已经使用了QK-Norm,这里补充一下QK-Norm的介绍和实现。
QK-Norm本质上就是额外的RMSNorm层,位于注意力模块内部,在应用RoPE前,对QK向量进行归一化。代码实现如下:
class GroupedQueryAttention(nn.Module):
def __init__(
self, d_in, num_heads, num_kv_groups,
head_dim=None, qk_norm=False, dtype=None
):
# ...
if qk_norm:
self.q_norm = RMSNorm(head_dim, eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
def forward(self, x, mask, cos, sin):
b, num_tokens, _ = x.shape
# Apply projections
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
# ...
# Optional normalization
if self.q_norm:
queries = self.q_norm(queries)
if self.k_norm:
keys = self.k_norm(keys)
# Apply RoPE
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)
# Expand K and V to match number of heads
keys = keys.repeat_interleave(self.group_size, dim=1)
values = values.repeat_interleave(self.group_size, dim=1)
# Attention
attn_scores = queries @ keys.transpose(2, 3)
# ...
5.3 总结
OLMo 2架构的不同之处,主要在于RMSNorm的位置:
- 在注意力模块和FFN之后,位于残差连接内部的RMSNorm;
- 在注意力模块内部的,QK-Norm。
这两者共同帮助稳定训练损失。
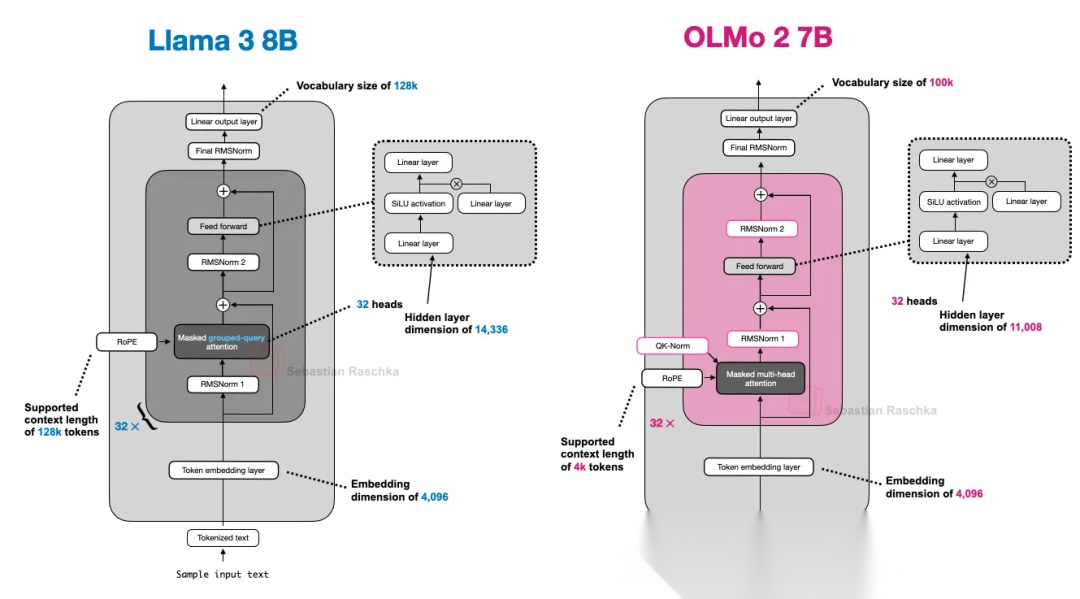
如下图所示,对比Llama 3 8B和OLMo 2 7B,两个主要区别:
- 上述提到的归一化层的位置调整;
- OLMo 2 7B没有使用GQA外。
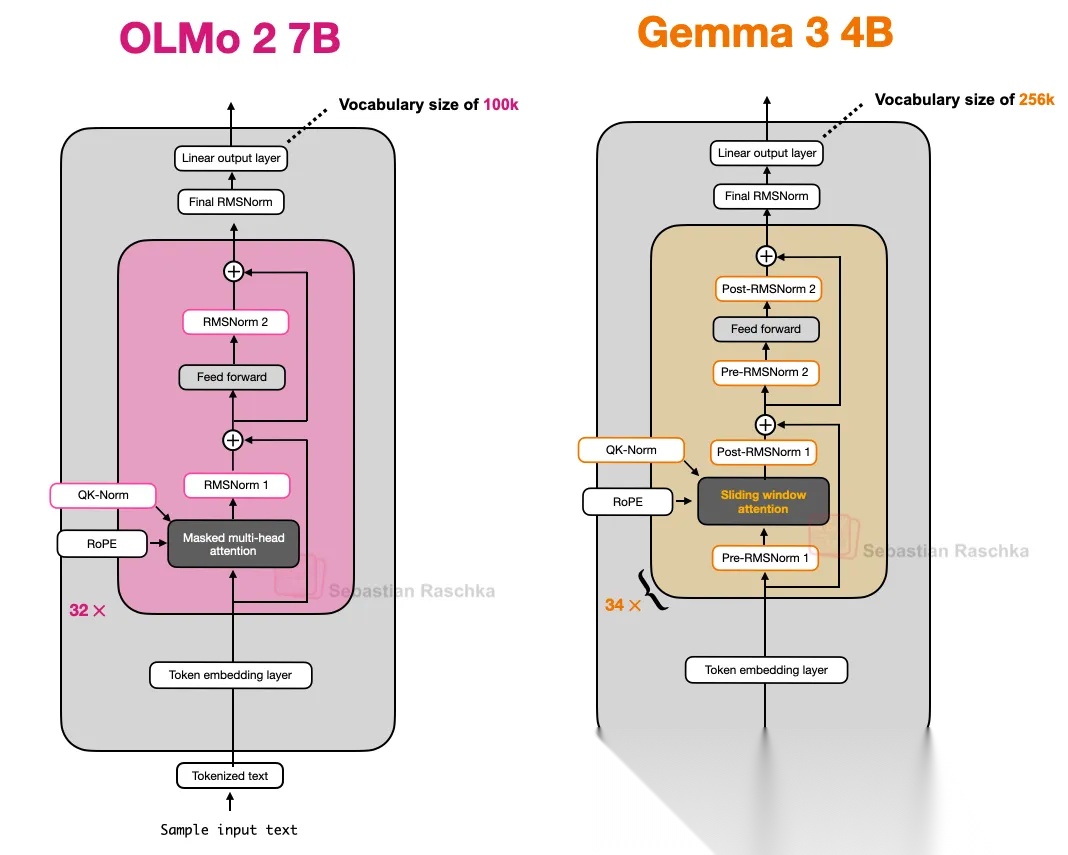
六、Gemma 3
Google发布的Gemma 3 27B模型,相比之前提到的模型架构,有两个不一样的地方:
- 使用了滑动窗口注意力来降低计算成本;
- 调整了归一化层的位置。
6.1 滑动窗口注意力
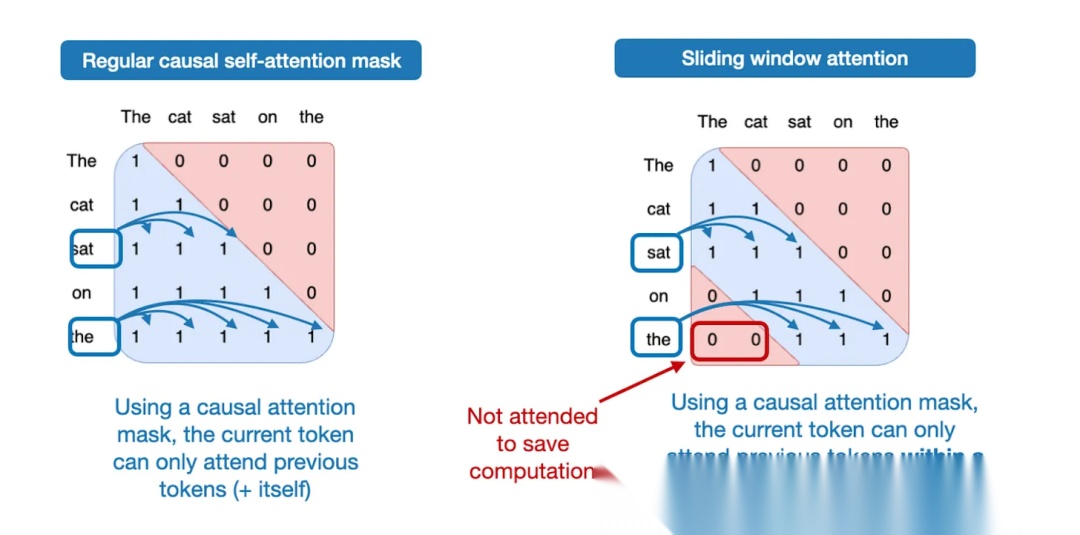
如下图所示,对比一下,常规注意力和滑动窗口注意力:
- 常规注意力:每个token都可以访问所有的其它token,如考虑因果注意力,则仅能访问之前的所有token,也可称为全局注意力机制;
- 滑动窗口注意力:相比之下,则是局部注意力机制,限制了当前token可以访问的其所在位置周围上下文的大小。
在Gemma 3中采用了5:1的比例,结合了滑动窗口和全局注意力,每有5个滑动窗口注意力层,会有1个完整的常规注意力层。其中,滑动窗口的大小为1024,使模型更加注重高效、局部的计算。根据Gemma 3的研究者的消融研究,滑动窗口注意力机制对建模性能的影响很小。
6.2 归一化层的位置调整
Gemma 3的归一化层的放置,同时结合了Pre-Norm和Post-Norm:
- Gemma 3应用的Pre-Norm与GPT-2等其它LLM架构相同,位于注意力层和FFN前;
- Gemma 3应用的Post-Norm与OLMo 2相同。
一般来讲,适度的额外的规范化不会对模型的建模能力造成损害,最多会增加一些运算量,而从LLM整体来看,RMSNorm的计算量占比是非常小的。
6.3 Gemma 3n
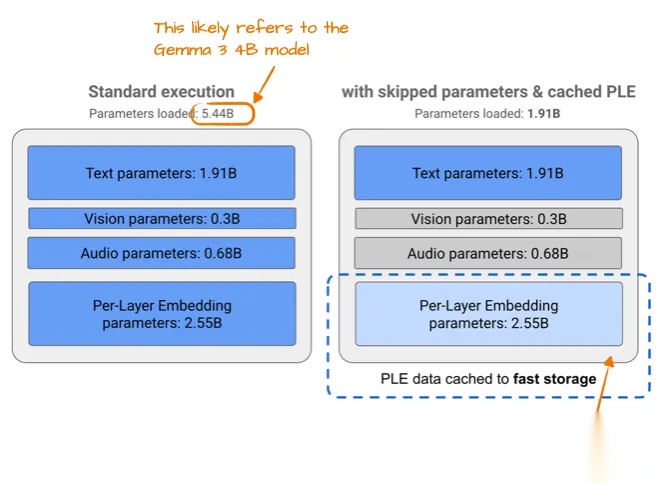
在Gemma 3发布后的几个月,Google分布了Gemma 3n,是一个针对在移动设备进行优化的模型。
Gemma 3n使用了PLE参数层(Per-Layer Embedding),核心的想法是,仅在GPU中保存模型参数的一个子集,在需要的时候,再将其它的参数加载进来(具体实现,从图中也较难理解,建议感兴趣的读者去看原博客或论文)。
另一个优化技巧称为MatFormer(Matryoshka Transformer),核心思想是,Gemma 3n架构被设计成可以切分成更小的、可独立使用的模型。每个切片后的模型都被训练成可独立运行,在推理时,可仅选择需要的部分运行(我理解有点类似模型融合的想法,大的模型是由多个小模型采用bagging融合而来)。
七、Mistral Small 3.1
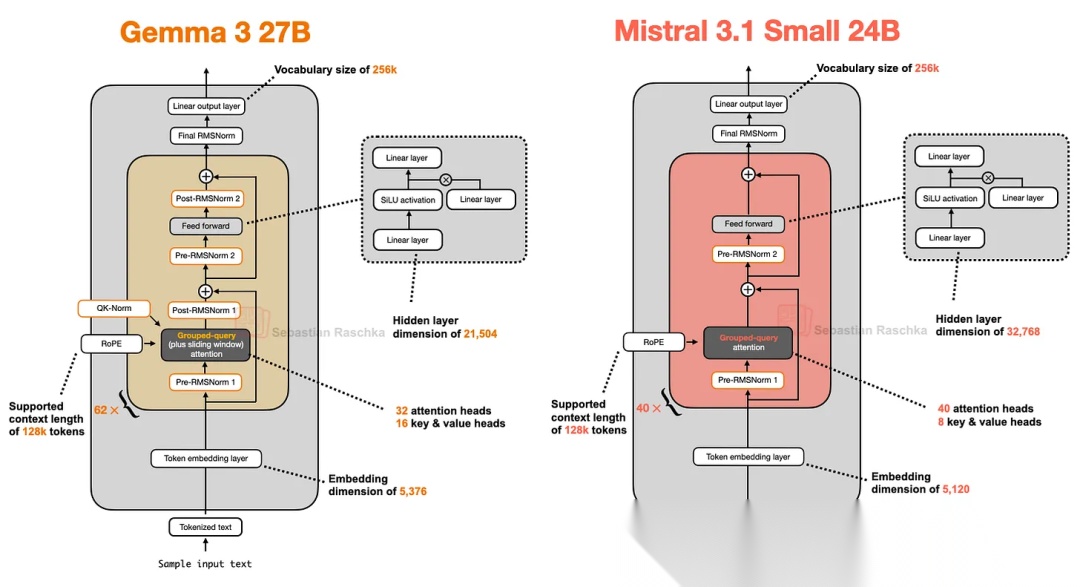
Mistral Small 3.1 24B与Gemma 3相比,如图所示,模型结构的差异如下,
- Mistral Small 3.1 24B仅使用了Pre-Norm,没有Post-Norm和QK-Norm;
- 使用了标准的GQA,没有使用滑动窗口注意力;
- Transformer的层数较少40 vs 62;
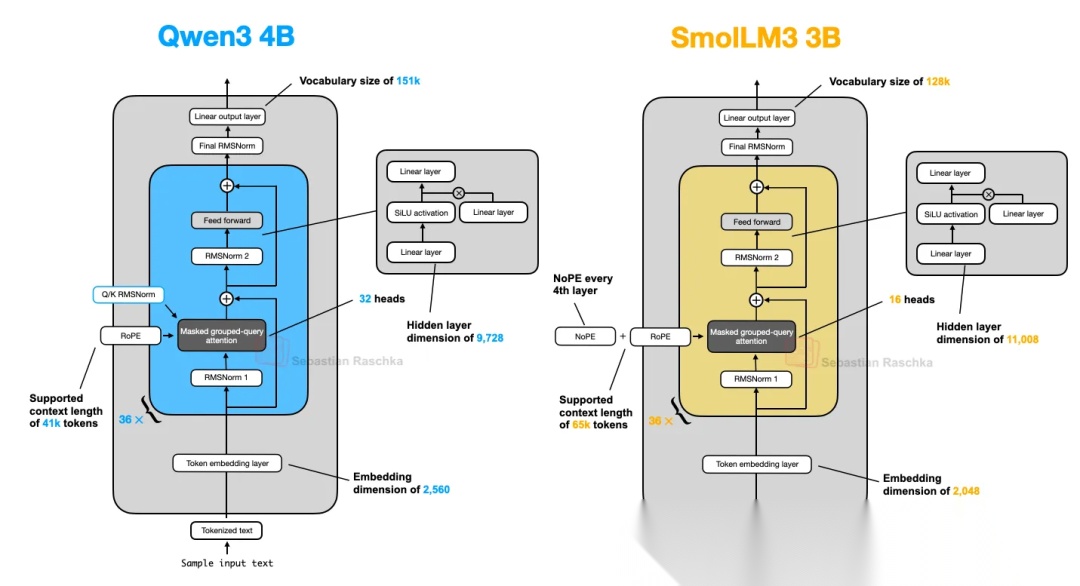
八、SmolLM3
SmolLM3 3B与Qwen3 4B的对比,如图所示,
- SmolLM3的一个主要的不同点,在于使用了NoPE(No Positional Embeddings,无位置编码)。
8.1 NoPE
NoPE来自[参考资料:3],目的是去除显式的位置信息的注入(也就是去除位置编码)。在基于Transformer的LLM中,位置编码可以分为两类,一类是绝对位置编码,通过添加一个额外的位置嵌入层实现;另一个类是相对位置编码,如RoPE。
在NoPE中,不添加任何的位置信息,但模型仍然知道token的顺序,这得益于因果注意力掩码(causal attention mask),它避免了token看到未来的token信息,因此,位置t的token只能看到位置≤t的token,从而保留了自回归顺序。
所以,尽管NoPE没有显式添加位置信息,但模型仍然学到了隐式的位置信息(需要查看原始的论文[参考资料:3]才能比较好的理解)。同时,SmolLM3的研究人员认为,NoPE具有更好的长度泛化能力。
回到上述的模型架构图,可以发现SmolLM3,并不是完全舍弃了RoPE,而是每4层应用一次NoPE。其实我们可以在DeepSeek V3的架构中也可以发现相似的应用,DeepSeek V3的做法是在每一层中都同时应用了NoPE+RoPE(详细可查看之前的文章《【大语言模型演进史】三、DeepSeek系列模型》)。
总结和未来计划
感谢Sebastian Raschka的《The big LLM Architecture Comparison》,让我们对当前主流的开源LLM的架构有了一个总体的认识。
但同时,在整理的过程中,我也发现,为了保证文章的可读性,作者进行了较多的简化,这也会导致如果读者仅参考该博文,得到的信息会不太完整。
后续,还是需要继续对主流几个大模型的架构的技术报告和开源代码进行学习和整理:
- DeepSeek V3/R1
- Qwen3
参考资料
- The Big LLM Architecture Comparison,链接
- On Layer Normalization in the Transformer Architecture,链接
进史】三、DeepSeek系列模型》)。
总结和未来计划
感谢Sebastian Raschka的《The big LLM Architecture Comparison》,让我们对当前主流的开源LLM的架构有了一个总体的认识。
但同时,在整理的过程中,我也发现,为了保证文章的可读性,作者进行了较多的简化,这也会导致如果读者仅参考该博文,得到的信息会不太完整。
后续,还是需要继续对主流几个大模型的架构的技术报告和开源代码进行学习和整理:
- DeepSeek V3/R1
- Qwen3
参考资料
- The Big LLM Architecture Comparison,链接
- On Layer Normalization in the Transformer Architecture,链接
- The Impact of Positional Encoding on Length Generalization in Transformers,链接
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献291条内容
已为社区贡献291条内容

所有评论(0)