第1篇:写入原理总览:一篇文章看懂TongSearch数据写入的全过程
讲解TongSearch索引写入原理-分析
目录
2. 协调节点接收请求(Coordinating Node)
引言
TongSearch是一个用来搜索数据的神器。但其实,数据的写入同样复杂且至关重要。
如果没有一个高效、可靠、可扩展的写入体系,TongSearch根本无法支撑如今各种实时日志分析、指标监控、智能搜索场景。
那么问题来了:
一条数据从客户端发出去,到真正写入 TongSearch并且可以被检索,中间到底经历了多少步骤?每个环节又是怎么运作的?
本篇,我们就用一篇文章,带你从整体上、一步步、看懂 TongSearch写入原理的完整流程。
为什么要了解写入原理?
理解 TongSearch写入原理,可以帮助你:
-
设计更合理的索引结构(避免写入瓶颈)
-
调优写入性能(比如批量写入、减少冲突)
-
排查写入异常(比如 translog 满了、flush 失败)
-
理解一致性保障机制(primary/replica同步)
-
为后续深入源码打下基础
写入数据的整体流程
TongSearch写入过程,像是一次「通过代理发快递」,经历了「接单 → 路由 → 主分片 → Lucene写入 → 副本同步」一整套完整链路。
客户端
↓
Rest API/Transport 请求
↓
协调节点(Coordinating Node)
↓
分片路由(找到主分片 Primary)
↓
主分片执行写入
├── 写入 Translog
└── 写入内存 Buffer
↓
写 Lucene 文档
↓
刷新(Refresh,数据可见)
↓
同步到副本分片(Replica)
↓
返回响应给客户端
每一个步骤,都是 TongSearch高性能写入的关键。下面我们详细看每一环。
详细步骤拆解
1. 客户端发起写入请求
用户通过 REST API(HTTP)或者 Transport(Java API)向集群发起写入,比如:
POST /index_name/_doc
{
"title": "写入原理揭秘",
"content": "一条数据是怎么写入ES的?"
}
通常你用的是 Index API 或者 Bulk API。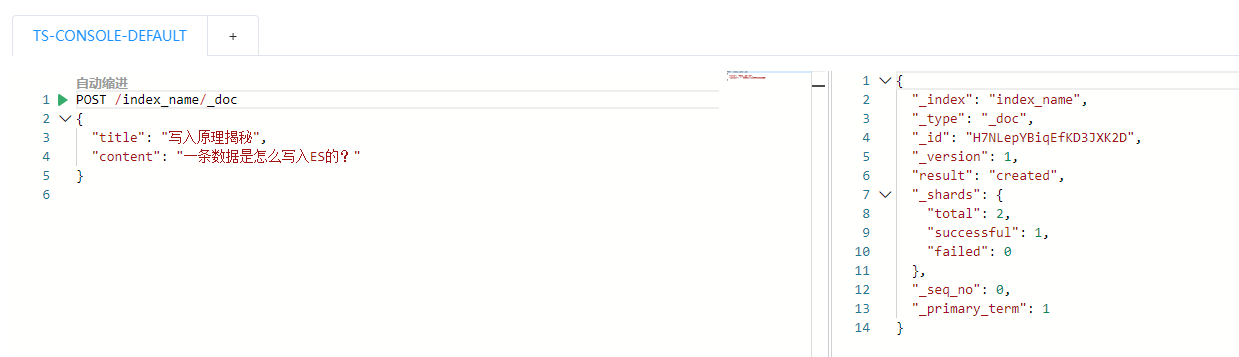
2. 协调节点接收请求(Coordinating Node)
协调节点负责接收请求,它并不一定是数据实际写入的节点。它的主要职责是:
-
解析请求
-
找到目标索引
-
决定路由到哪个分片
-
将请求分发给对应的分片
注意: 协调节点可以是任意节点,甚至数据节点(data node)本身也能兼任。
3. 路由到主分片(Primary Shard)
通过一套一致性哈希算法,Elasticsearch 根据文档的 ID,计算出应该写入哪个分片(shard)。
然后找到**主分片(Primary Shard)**所在的节点,发起写入。
如果是 Bulk 请求,可能会被拆分成多个 shard 级请求并行处理。
4. 主分片处理写入(Primary Shard)
主分片拿到写入请求后,开始实际执行写入动作,主要包括两步:
a) 写入 Translog(事务日志)
-
先把请求记录到 Translog(写磁盘,追加日志)
-
确保数据不丢(即使系统崩溃,可以用 Translog 恢复)
b) 写入内存索引(Buffer)
-
再把文档写到内存中的数据结构里(Lucene内存索引 Buffer)
-
此时,数据尚不可被搜索到!
5. Lucene 层处理
TongSearch底层使用 Lucene 作为真正的存储和搜索引擎。
在写入流程中:
-
将 JSON 文档解析为 Lucene 的
Document对象 -
将字段分析(分词、标准化)
-
更新倒排索引(Inverted Index)
这一步是真正让数据「落地」的核心操作,但它一开始只是存在内存中。
6. 刷新(Refresh)让数据可见
写完后,数据并不会立刻可搜索。
TongSearch需要通过refresh机制,把内存中的数据刷到一个新的 segment 中,才变成可搜索状态。
-
默认每 1 秒自动 refresh 一次(可调)
-
也可以手动调用
refreshAPI
refresh 本质上是生成一个新的 Lucene reader,使得新增数据对搜索查询可见。
7. 同步到副本分片(Replica Shard)
主分片写成功后,会同步副本分片:
-
把写入请求转发给副本节点
-
副本节点重复同样的写入操作
-
等所有副本确认写成功,协调节点才返回成功响应给客户端
这保证了写入的高可用性和数据一致性。
如果副本节点失败,Elasticsearch 会自动重试或降级处理。
8. 返回响应给客户端
当主分片和所有必要副本写入成功,协调节点就向客户端返回 201 Created 或 200 OK。
至此,一次完整的写入请求才真正完成!
写入过程中还有哪些关键机制?
除了上述主线流程,写入过程中还涉及一堆重要机制,后面我们可以逐一展开:
-
写入重试(Primary分片切换时自动重发)
-
乐观锁版本控制(防止写冲突)
-
bulk优化(批量写入提升吞吐)
-
backpressure控制(写入流量控制)
-
Translog回滚恢复
-
Flush和Segment Merge
这些机制共同保证了 TongSearch在面对高并发、大规模写入时依然能稳定可靠地运作。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)