「大模型学习」(4)0基础学强化学习PPO与大模型中的应用
强化学习基础和PPO和RHLF
一、强化学习是在干啥?
想象你是一个在玩一个新游戏的玩家,你不知道怎么做才最好,只能靠“试试看”,如果做对了有奖励,做错了被惩罚。你想通过不断尝试,学会一套最好的行为方式,让自己得分最高(或更安全、赢得游戏)。
-
强化学习的核心组成部分(5个要素)
名称 说明 Agent(智能体) 学习和决策的主体,例如一个机器人或游戏玩家。 Environment(环境) 智能体交互的外部世界,比如迷宫、棋盘、市场等。 State(状态)s 环境当前的情况或描述,比如棋盘的布局、机器人的位置等。 Action(动作)a 智能体可以执行的操作,比如向左移动、跳跃、购买股票等。 Reward(奖励)r 智能体每次行动后环境返回的分数,表示好坏。例如赢一局得+1,输得-1。 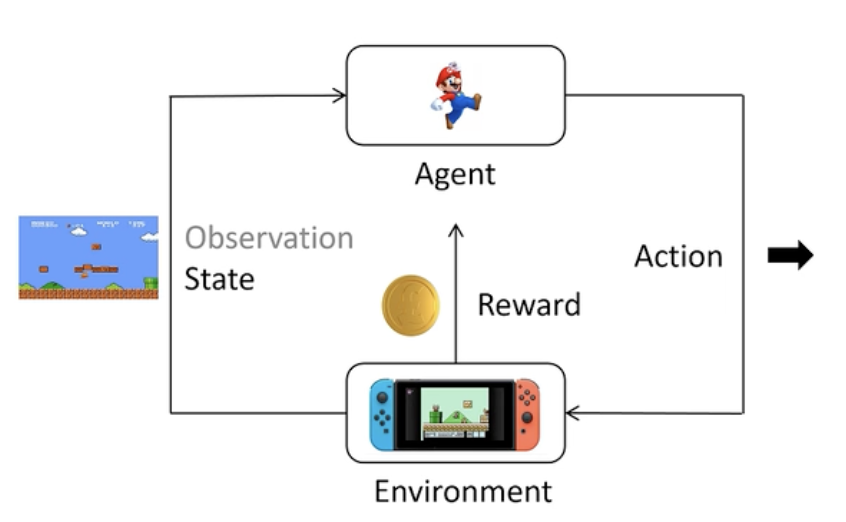
-
我们通过玩游戏来举例子,从上图来进行演示,强化学习是一种让智能体(agent)通过与环境交互、不断试错来学习决策策略的方法。agent 就像是玩家(马里奥),它在游戏中根据当前的状态选择动作,环境则根据这个动作返回新的状态(state)和奖励(reward)。agent 的目标是不断尝试,逐步学会一种策略,使它在游戏中获得尽可能高的累计奖励。这个过程就像玩家不断练习游戏技巧,从失败中学习,最终掌握通关的方法。
-
交互过程(马尔可夫决策过程)
根据上述有关马里奥游戏的讲解,我们可以将强化学习建模成一个马尔可夫决策过程(Markov Decision Process, MDP),在时间步 ttt:
- Agent 观察当前状态 sts_tst
- Agent 选择动作 ata_tat
- 环境根据动作给出新状态 st+1s_{t+1}st+1 和奖励 rtr_trt
- Agent 更新策略(或值函数)以更好地决策
- 重复上述步骤直到终止
-
强化学习的目标是什么?
-
智能体(Agent)通过与环境交互,学习一个策略 π(a∣s)\pi(a|s)π(a∣s),使得获得的长期累计奖励最大。
即:
maxπEπ[∑t=0∞γtrt] \max_\pi \mathbb{E}_{\pi} \left[ \sum_{t=0}^\infty \gamma^t r_t \right] πmaxEπ[t=0∑∞γtrt]
其中:
- π(a∣s)\pi(a|s)π(a∣s):策略函数,给定状态下选择动作的概率;
- rtr_trt:在 t 时刻获得的奖励;
- γ∈[0,1]\gamma \in [0,1]γ∈[0,1]:折扣因子,用来平衡“现在奖励”与“将来奖励”,现在的点附近的奖励对rrr的影响最大,将来的奖励对现在有一定的衰减。
二、如何让长期累计奖励最大
我们这里讲三种方法,基于值的方法,基于策略的方法与两者结合的方法。
-
🤖 基于值的方法(value-based):想象你在迷宫里,每个格子都可以向上、下、左、右走,你不知道哪条路最好。于是给每个格子每个方向打个分数,这个分数表示你走这步之后未来可能会得到多少奖励。然后你每次都选分数最高的方向走,这就是 基于值的方法(value-based)。
-
- 对应到算法上:这个“分数”就是 Q(s,a)Q(s, a)Q(s,a),表示“在状态 s 选择动作 a 的预期得分”;
-
- 最常见的算法叫 Q-learning 或 DQN。
-
- 如果你可以无穷多种选择(比如控制机器人的转向角度是 0.1° ~ 359.9°),是一个连续的值,那就说明:每一个动作都要打分?那也太复杂了!
- 🤖基于策略的方法(policy-based): 不用每次都去算值了,我直接学一套行为习惯:在不同情况怎么行动比较好。比如你学到了: 路口看到红灯就刹车; 前方没有车就加速;看到绿灯就直行。
这就是一套策略,它告诉你:在某种情境下,做什么动作是最靠谱的。这就是 基于策略的方法(policy-based),直接学一个策略函数 π(a∣s)\pi(a|s)π(a∣s),输入是状态,输出是动作(可以是概率分布)
-
🤖结合两种方法 Actor-Critic:你可能想如果我既想学一套风格,又想有个“参谋”帮我打分,岂不是更好?这就是 Actor-Critic 方法:
-
- Actor:负责做决定(策略);
-
- Critic:负责打分、判断这决定好不好(值函数);
-
- 两者互相配合,走得更稳、学得更快,这类方法的代表就是我们后面要讲的 PPO算法。
📘 1.基于值的方法(Value-Based)
✅ 代表算法:
- Q-Learning
- Deep Q-Network(DQN)
- SARSA
🌟 核心思路:
学习一个动作价值函数 Q(s,a)Q(s,a)Q(s,a),表示在状态 sss 下采取动作 aaa 后,未来能够获得的总期望奖励:
Q(s,a)=E[∑t=0∞γtrt∣s0=s,a0=a] Q(s,a) = \mathbb{E} \left[ \sum_{t=0}^\infty \gamma^t r_t \mid s_0=s, a_0=a \right] Q(s,a)=E[t=0∑∞γtrt∣s0=s,a0=a]
策略是间接获得的:
- π(s)=argmaxaQ(s,a)\pi(s) = \arg\max_a Q(s,a)π(s)=argmaxaQ(s,a)
也就是说:动作就是“价值最大的动作”,在价值迭代算法中,只进行一轮的策略评估,然后直接根据更新后的价值进行策略评估。
🔁 Q-Learning 更新公式(表格法):
Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)] Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a'} Q(s',a') - Q(s,a) \right] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
- α\alphaα:学习率
- γ\gammaγ:折扣因子
🧠 缺点:
- 动作空间太大/连续时难以处理;
- 策略不易直接优化(无法表达概率策略);
- 训练不稳定(如 DQN 时 Q 函数易发散);
📗 2.基于策略的方法(Policy-Based)
✅ 代表算法:
- REINFORCE(策略梯度)
- PPO(Proximal Policy Optimization)
- TRPO(Trust Region Policy Optimization)
🌟 核心思路:
直接建模策略函数 πθ(a∣s)\pi_\theta(a|s)πθ(a∣s),目标是最大化累计期望回报:
J(θ)=Eπθ[∑t=0Trt] J(\theta) = \mathbb{E}_{\pi_\theta} \left[ \sum_{t=0}^{T} r_t \right] J(θ)=Eπθ[t=0∑Trt]
🔧 策略梯度定理:
∇θJ(θ)=E[∇θlogπθ(at∣st)⋅A^t] \nabla_\theta J(\theta) = \mathbb{E} \left[ \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot \hat{A}_t \right] ∇θJ(θ)=E[∇θlogπθ(at∣st)⋅A^t]
- 用样本估计这个梯度,再通过优化器(如 Adam)优化参数 θ。
🧠 优点:
- 可直接用于连续动作空间(如机器人控制);
- 可学习随机策略,适合不确定性强的任务;
- 容易和深度学习结合,输出策略分布;
😕 缺点:
- 收敛慢;
- 高方差(策略梯度估计);
- 易陷入局部最优;
🔀 3.Actor-Critic:融合两者优点
✅ 代表算法:
- A2C(Advantage Actor Critic)
- A3C(异步)
- PPO(可视为 actor-critic 的一个变种)
🎬 思想:
将策略函数和值函数结合:
- Actor:输出策略 πθ(a∣s)\pi_\theta(a|s)πθ(a∣s),选择动作
- Critic:输出状态值 Vπ(s)V^\pi(s)Vπ(s),评价动作好坏
用值函数提供的优势函数 A(s,a)A(s,a)A(s,a) 来指导策略优化,减少方差,提高收敛速度。
三、PPO算法
PPO 的核心公式讲解
PPO 的优化目标函数为:
LCLIP(θ)=Et[min(rt(θ)A^t, clip(rt(θ),1−ϵ,1+ϵ)A^t)] L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \ \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right] LCLIP(θ)=Et[min(rt(θ)A^t, clip(rt(θ),1−ϵ,1+ϵ)A^t)]
下面,我们一个一个解释:
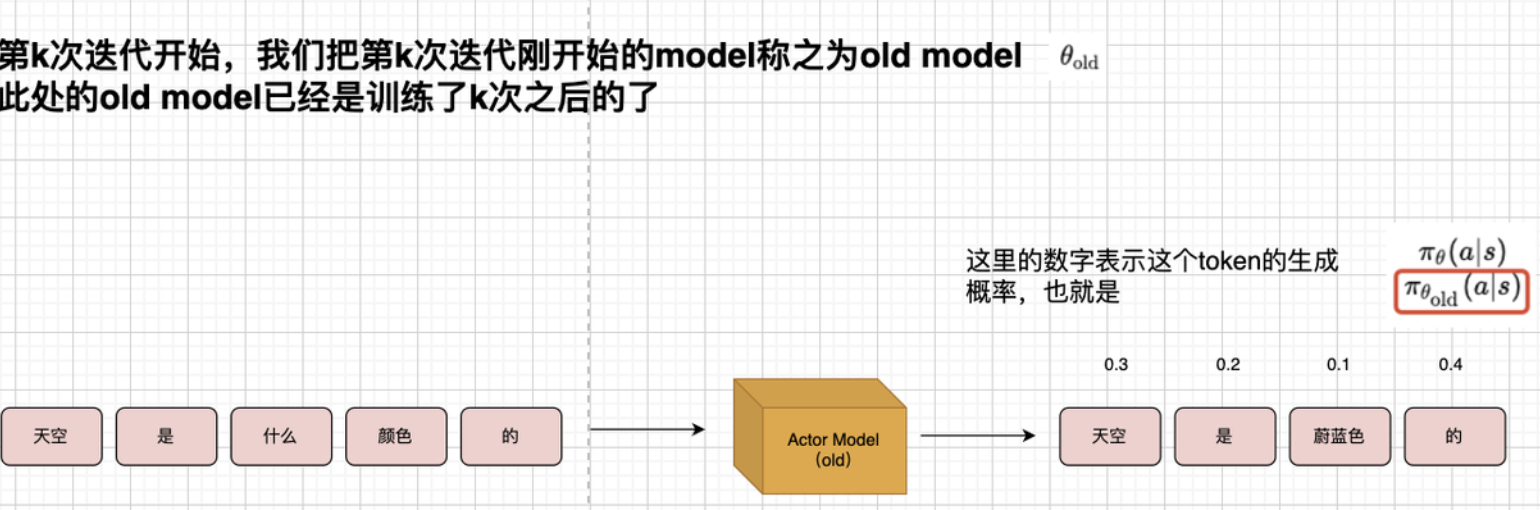
1. 什么是 rt(θ)r_t(\theta)rt(θ)?
这是新旧策略的比值:
rt(θ)=πθ(at∣st)πθold(at∣st) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st)
- πθ\pi_{\theta}πθ:当前的策略参数;
- πθold\pi_{\theta_{old}}πθold:之前的策略参数;
- ata_tat:在时间 t 做出的动作;
- sts_tst:当前状态。
这个比值告诉我们:新策略比旧策略更倾向于选择动作 ata_tat 的程度。
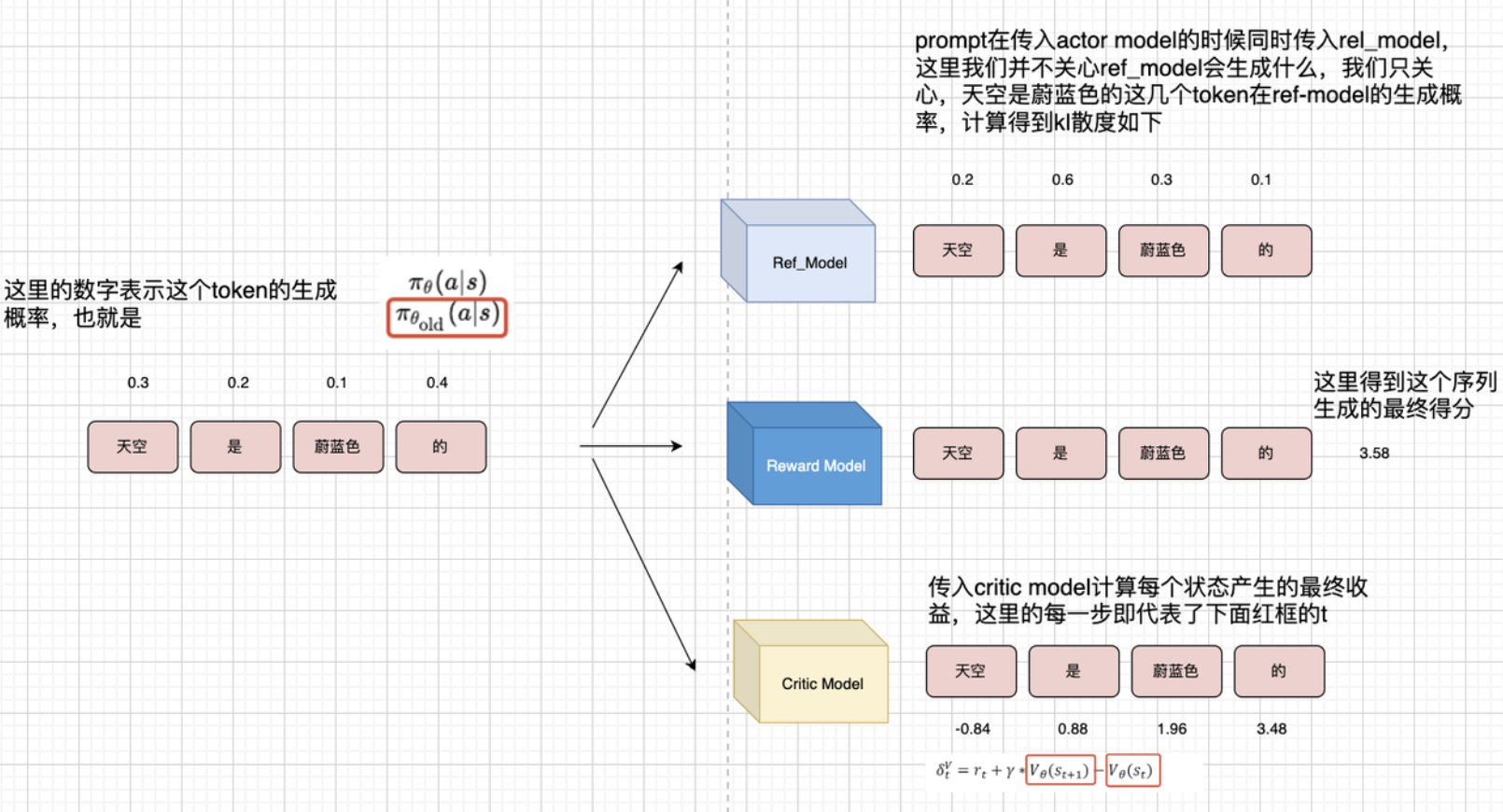
2. 什么是 A^t\hat{A}_tA^t?
这是优势函数(Advantage),表示某个动作比平均水平好多少:
A^t=Q(st,at)−V(st) \hat{A}_t = Q(s_t, a_t) - V(s_t) A^t=Q(st,at)−V(st)
-
如果 A^t>0\hat{A}_t > 0A^t>0,说明这个动作是个好动作;
-
如果 A^t<0\hat{A}_t < 0A^t<0,说明这个动作是个坏动作。
-
V(st)V(s_t)V(st)是回报的期望
-
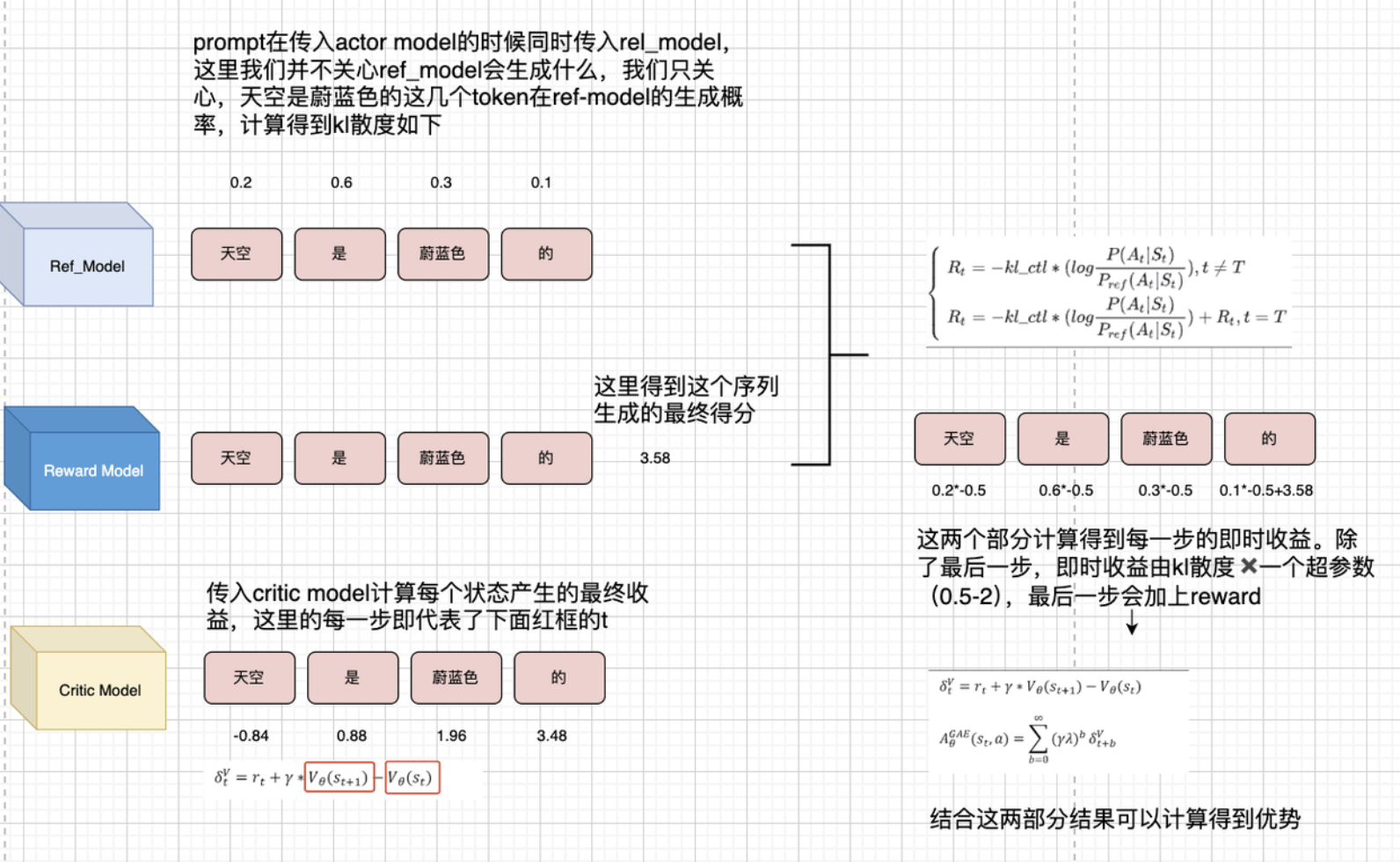
- 但是,这样我们需要训练两个函数,因此有GAE,Generalized Advantage Estimation,广义优势估计方法,GAE 是策略梯度中用于估计 Advantage 的方法。
-
- Qπ(s,a)Q^\pi(s,a)Qπ(s,a) 和 Vπ(s)V^\pi(s)Vπ(s) 都是关于未来长期回报的期望,它们在环境中不是直接可观测的、只能通过采样估计,且估计误差大。
GAE,Generalized Advantage Estimation,广义优势估计方法
-
一步 Advantage 的近似(TD 误差):
我们不能直接得到 Aπ(s,a)A^\pi(s,a)Aπ(s,a),所以尝试用 TD 误差来近似:
δt=rt+γV(st+1)−V(st) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)
这个就是我们说的一步 TD 误差,也可以写成:
δt≈At \delta_t \approx A_t δt≈At
但这个只利用了一步信息,可能方差大,我们希望更稳定的估计,所以考虑多步回报:
-
-
- 1-step TD advantage:
A^t(1)=δt \hat{A}_t^{(1)} = \delta_t A^t(1)=δt
-
-
-
- 2-step TD advantage:
A^t(2)=δt+γδt+1 \hat{A}_t^{(2)} = \delta_t + \gamma \delta_{t+1} A^t(2)=δt+γδt+1
-
-
-
- 3-step TD advantage:
A^t(3)=δt+γδt+1+γ2δt+2 \hat{A}_t^{(3)} = \delta_t + \gamma \delta_{t+1} + \gamma^2 \delta_{t+2} A^t(3)=δt+γδt+1+γ2δt+2
-
-
-
- k-step TD Advantage:
A^t(k)=∑l=0k−1γlδt+l \hat{A}_t^{(k)} = \sum_{l=0}^{k-1} \gamma^l \delta_{t+l} A^t(k)=l=0∑k−1γlδt+l
这个越多步,越接近蒙特卡洛估计(低偏差,高方差)。
将所有这些不同步数的 Advantage 用指数衰减加权求和:
-
A^tGAE(γ,λ)=∑l=0∞(γλ)lδt+l \hat{A}_t^{\text{GAE}(\gamma, \lambda)} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} A^tGAE(γ,λ)=l=0∑∞(γλ)lδt+l
-
注意:这里的衰减因子是 γλ\gamma \lambdaγλ,其中:
- γ\gammaγ:未来奖励的折扣因子
- λ\lambdaλ:控制偏差/方差的因子(越接近1越偏向多步)
这个估计叫广义优势估计(Generalized Advantage Estimation)。
3. 为什么要用 clip 函数?
clip 是为了防止策略更新太大:
clip(rt,1−ϵ,1+ϵ) \text{clip}(r_t, 1 - \epsilon, 1 + \epsilon) clip(rt,1−ϵ,1+ϵ)
比如说设 ϵ=0.2\epsilon = 0.2ϵ=0.2,那么策略的更新只能在 [0.8,1.2][0.8, 1.2][0.8,1.2] 范围内,超过这个范围就被“剪掉”了。
举例:
- 如果 A^t>0\hat{A}_t > 0A^t>0,策略会鼓励增加 rtr_trt,但最多只能涨到 1.2;
- 如果 A^t<0\hat{A}_t < 0A^t<0,策略会压低 rtr_trt,但不能低于 0.8。
这就是 PPO 的“近端”本质。
🌟 PPO 训练流程(简洁版)
- 初始化策略 πθ\pi_{\theta}πθ 和值函数 VϕV_{\phi}Vϕ
- 用旧策略与环境交互,收集一批数据 (st,at,rt,st+1)(s_t, a_t, r_t, s_{t+1})(st,at,rt,st+1)
- 估算优势值 A^t\hat{A}_tA^t
- 构造 PPO 的目标函数并优化策略
- 更新值函数 VϕV_{\phi}Vϕ
- 将新策略设为旧策略,重复第 2 步
三、PPO与RHLF
PPO(Proximal Policy Optimization,近端策略优化)是目前强化学习中最常用、最稳定、效果最好的策略梯度方法之一,尤其在大模型(如ChatGPT、GPT-4 等语言模型)的训练中被广泛应用,用于强化学习微调(Reinforcement Learning from Human Feedback,简称 RLHF)的阶段。
我们一共需要四个模型:
| 序号 | 模型名称 | 模型作用 | 输入 | 输出 |
|---|---|---|---|---|
| 1️⃣ | 基准模型(Initial Model) | 预训练语言模型,用作起点或对照参考 | 用户 Prompt | 回答文本 |
| 2️⃣ | 训练模型(SFT Model) | 通过人类标注数据进行监督微调,提高模型对齐能力,不能和基准模型相差太大 | 用户 Prompt | 高质量回答文本 |
| 3️⃣ | 奖励模型(Reward Model,RM) | 评估多个回答的优劣,用人类偏好训练得到 | 用户 Prompt + 回答文本(多个) | 奖励分数(实数,如 1.5、-0.7) |
| 4️⃣ | 状态价值模型(Value Model) | 估计当前策略在给定状态下的期望长期回报,用于计算 Advantage | 状态(如 Prompt + 回答) | 状态值估计 V(s)V(s)V(s),标量也是一个分数 |
RLHF 训练流程详解
📌 第 1 步:监督微调(Supervised Fine-Tuning, SFT)
- 目的:利用高质量人类数据让模型学会“合理地回答问题”
- 输入:Prompt(提问)+ 优质回答(人工标注)
- 训练目标:最小化交叉熵损失,提升回答质量
- 输出:SFT 模型,作为初始策略(Actor)
📌 第 2 步:奖励模型训练(Training the Reward Model)
-
目的:学习如何比较多个回答的优劣(对齐人类偏好)
-
数据:Prompt + 多个回答 + 人类偏好标签(如哪个更好)
-
损失函数:排序损失(Pairwise loss):
L=−log(erpreferrederpreferred+erother) L = -\log \left( \frac{e^{r_{\text{preferred}}}}{e^{r_{\text{preferred}}} + e^{r_{\text{other}}}} \right) L=−log(erpreferred+erothererpreferred)
-
输出:训练好的奖励模型 RM,输入回答可输出一个分数
📌 第 3 步:强化学习优化(如 PPO)
-
目的:用奖励模型指导 SFT 策略,使其产生更对齐人类偏好的回答
-
步骤:
-
1.用当前策略模型(Actor)生成回答
2.奖励模型对回答打分(得分为 rrr)3.状态价值模型估值 V(s)V(s)V(s)
4.计算 Advantage(如用 GAE):
At=rt+γV(st+1)−V(st) A_t = r_t + \gamma V(s_{t+1}) - V(s_t) At=rt+γV(st+1)−V(st)
- 使用 PPO 策略梯度优化目标更新策略
-
损失函数(PPO Clip):
LPPO=Et[min(rt(θ)At, clip(rt(θ),1−ϵ,1+ϵ)At)] L^{\text{PPO}} = \mathbb{E}_t \left[ \min\left( r_t(\theta) A_t, \ \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) A_t \right) \right] LPPO=Et[min(rt(θ)At, clip(rt(θ),1−ϵ,1+ϵ)At)]
其中,rt(θ)=πθ(at∣st)πθold(at∣st)r_t(\theta) = \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)}rt(θ)=πθold(at∣st)πθ(at∣st),对比与我们之前提到的基准模型
-
输出:强化学习后的模型,称为 RLHF 模型(策略优化后)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)