假设驱动药物发现的LLM代理群
药物发现仍然是一个艰巨的挑战:超过90%的候选分子在临床评估中失败,每种获批疗法的开发成本通常超过十亿美元。从基因组学到化学库和临床记录的分散数据流阻碍了连贯的机制洞察,并减缓了进展。同时,大型语言模型擅长推理和工具集成,但缺乏受监管、假设驱动工作流程所需的模块化专业化和迭代记忆。我们引入了PharmaSwarm,这是一个统一的多代理框架,协调专门化的LLM“代理”来提出、验证和完善新型药物靶点和
Kevin Song 4,2{ }^{4,2}4,2, Andrew Trotter 1{ }^{1}1, Jake Y. Chen, PhD 1,2{ }^{1,2}1,2
1{ }^{1}1 阿拉巴马大学伯明翰分校系统药理学AI研究中心
2{ }^{2}2 阿拉巴马大学伯明翰分校生物医学工程系
2025年4月28日
摘要
药物发现仍然是一个艰巨的挑战:超过90%的候选分子在临床评估中失败,每种获批疗法的开发成本通常超过十亿美元。从基因组学到化学库和临床记录的分散数据流阻碍了连贯的机制洞察,并减缓了进展。同时,大型语言模型擅长推理和工具集成,但缺乏受监管、假设驱动工作流程所需的模块化专业化和迭代记忆。我们引入了PharmaSwarm,这是一个统一的多代理框架,协调专门化的LLM“代理”来提出、验证和完善新型药物靶点和先导化合物的假设。每个代理访问专用功能——自动基因组和表达分析;策划的生物医学知识图谱;通路富集和网络模拟;可解释的结合亲和力预测——而一个中央评估LLM根据生物学合理性、新颖性、计算机模拟效能和安全性持续对提案进行排名。共享记忆层捕获经过验证的见解并随时间微调底层子模型,从而产生一个自我改进的系统。PharmaSwarm可在低代码平台或基于Kubernetes的微服务上部署,支持文献驱动的发现、组学导向的目标识别和市场知情的再利用。我们还描述了一个严格的四层验证管道,涵盖回顾性基准测试、独立计算试验、实验测试和专家用户研究,以确保透明度、可重复性和实际影响。通过作为AI副驾驶,PharmaSwarm可以加速转化研究,并比传统管道更高效地提供高可信度的假设。
*通讯作者: kmsong@uab.edu
# 1 引言
药物开发以其高淘汰率和惊人的成本而闻名。超过90%的候选分子在临床评估期间失败,导致每种批准的治疗平均花费10亿至20亿美元 [1]。这些失败反映了将基因组、化学和临床数据整合为连贯机制假设的能力存在差距。传统管道孤立处理每种数据类型,导致反馈循环延迟并错失跨领域协同的机会 [2]。
像GPT-4和Gemini 2.5 Pro这样的大型语言模型已经展示了文本理解、推理和与外部工具集成方面的显著能力 [3, 4]。然而,单模型部署缺乏受监管生物医学工作流程所需的专长、记忆保留和机制严谨性。最近的研究表明,多代理LLM系统在从逆合成化学 [5] 到自主实验室协议生成 [6] 和生态预测 [7] 的任务中可以超越单一模型。这些系统利用异构推理策略和迭代反馈,在探索广阔假设空间方面更有效 [8,9][8,9][8,9]。
基于这些进步,我们引入了PharmaSwarm,这是一个竞争性、可解释且不断进化的LLM代理群,专为假设驱动的药物发现量身定制。PharmaSwarm统一了多模态数据摄取、机制模拟和透明决策。中央评估LLM对提案进行排名和批评,而共享知识存储中的图形更新和向量嵌入使连续学习和子模型微调成为可能。本文描述了总体架构(第2节)、迭代群工作流(第3节)、说明性用例(第4节)和拟议的验证策略(第5节)。我们在最后讨论了部署考虑因素和未来扩展(第6节)。
2 系统架构
PharmaSwarm设计为三层架构,每一层处理一组特定的责任,但紧密集成以确保无缝的数据流和迭代优化。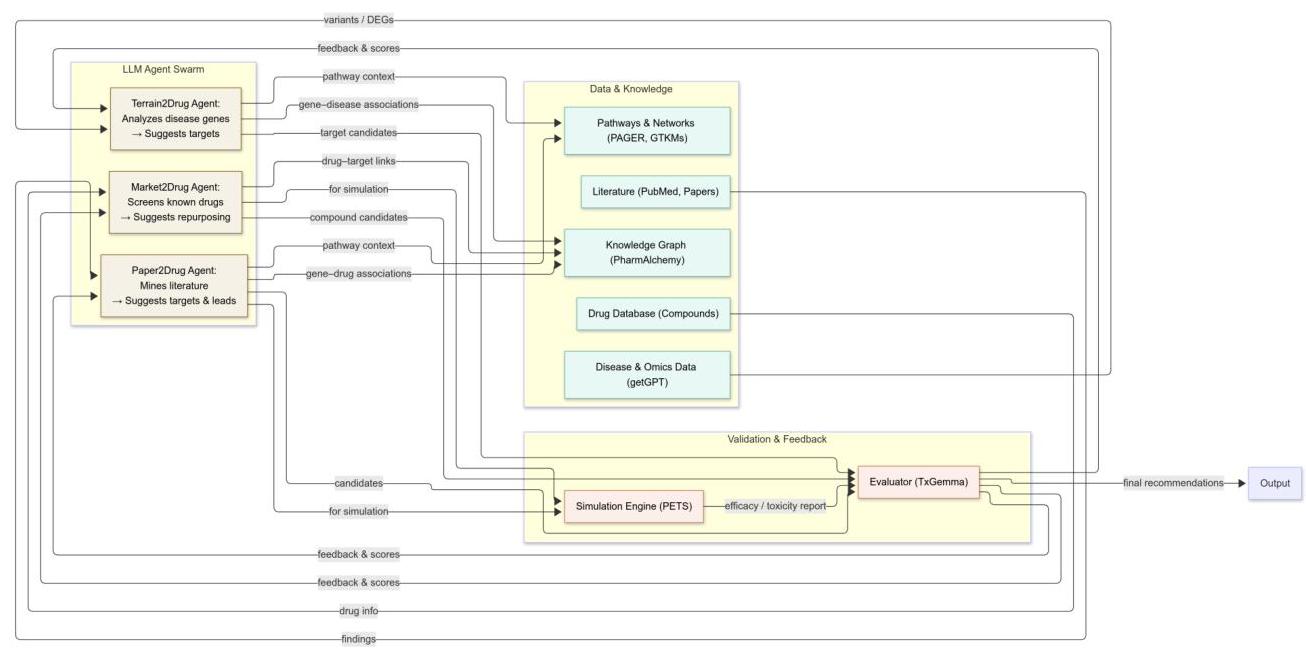
图1:LLM代理群架构。一个模块化、基于代理的管道整合了异构生物医学知识——通路和网络数据库、文献语料库、统一的知识图谱和化合物库——并通过三个专门的LLM代理(Terrain2Drug、Market2Drug和Paper2Drug)提出疾病靶点和候选化合物。提案通过计算机药理学模拟(PETS)和功效/毒性评分由专门的评估者进行评估,双向反馈循环不断丰富共享知识库和后续代理输出,通过迭代优化生成可解释的治疗假设。
数据与知识层
PharmaSwarm的基础建立在全面摄取和预处理各种生物医学数据之上。getGPT模块通过与Gene Expression Omnibus以及Open Targets和OpenTarget Genetics API接口提取疾病相关遗传变异、差异表达基因(DEGs)和药物靶点的G.E.T列表,检索已知药物靶点、全基因组关联研究(GWAS)位点、精细映射变异和基因特征关联得分。并行管道查询Gene Expression Omnibus (GEO)以获取转录组数据集,执行标准化和差异表达分析。科学文献通过PubMed和bioRxiv API收集,其中标题-摘要对和开放获取全文被解析以供下游LLM摘要和基因集策划。化学和药理学知识来源于ChEMBL、DrugBank和PharmAlchemy知识库(即药物-基因-疾病的“数据库之数据库”),而通路背景由KEGG和Reactome REST服务提供。
PAGER API提供基于网络的基因集及其富集得分,GeneTerrain Knowledge Maps (GTKMs)呈现遗传相互作用和表达网络的空间拓扑结构,并在验证与评估层可视化模拟结果中的脱靶和靶标效应。
LLM代理群层
PharmaSwarm的核心是三个专门的代理,每个代理都作为容器化的微服务实现,并可访问共享知识库:
- Terrain2Drug代理专注于组学驱动的发现。它接受来自getGPT和PAGER的种子基因列表,将其投影到原始GTKMs上,并通过图拓扑算法识别高度网络中心节点。这些中心节点成为候选目标,通路富集统计数据指导优先级。
-
- Paper2Drug代理进行自动化文献挖掘。使用LLM模板提示,它从文本中提取明确和隐含的目标-化合物关系,然后通过PharmAlchemy知识图的多跳遍历来验证这些关系,以确保机制一致性。
-
- Market2Drug代理综合市场和社区情报。它将法规公告(如FDA通知)、临床试验注册更新、金融API(如Bloomberg)和社会媒体情绪(Twitter、Reddit)流式传输到语义嵌入中。这些信号标记具有新兴临床相关性的化合物,然后与化学相似性得分和网络影响预测交叉匹配。
每个代理维护一个本地提示历史缓冲区,并访问共享嵌入存储(通过向量数据库)以捕捉代理间知识并避免冗余探索。
- Market2Drug代理综合市场和社区情报。它将法规公告(如FDA通知)、临床试验注册更新、金融API(如Bloomberg)和社会媒体情绪(Twitter、Reddit)流式传输到语义嵌入中。这些信号标记具有新兴临床相关性的化合物,然后与化学相似性得分和网络影响预测交叉匹配。
验证与评估层
一旦代理提出目标或化合物,验证与评估层量化其机制合理性和安全性:
- 药理学效能和毒性模拟(PETS)引擎在组织特异性蛋白质-蛋白质相互作用网络上执行化合物扰动的多尺度网络传播,以生成标准化的效能和毒性分数 [18]。
-
- 可解释结合亲和力图(iBAM)模块采用ESM2蛋白嵌入和ChemBERTa分子嵌入之间的交叉注意力架构,不仅生成亲和力估计值,还生成无结构的残基-化学亚结构注意力图,用于透明的SAR分析和先导优化(图2)。
-
- 中央评估器是一个由TxGemma驱动的LLM实例,它接收代理提案、模拟输出和结合图 [10]。它应用多标准评分规则——数据支持、机制一致性、新颖性、安全边际和可解释性——并生成针对每个代理的可操作反馈,完成迭代优化的闭环。
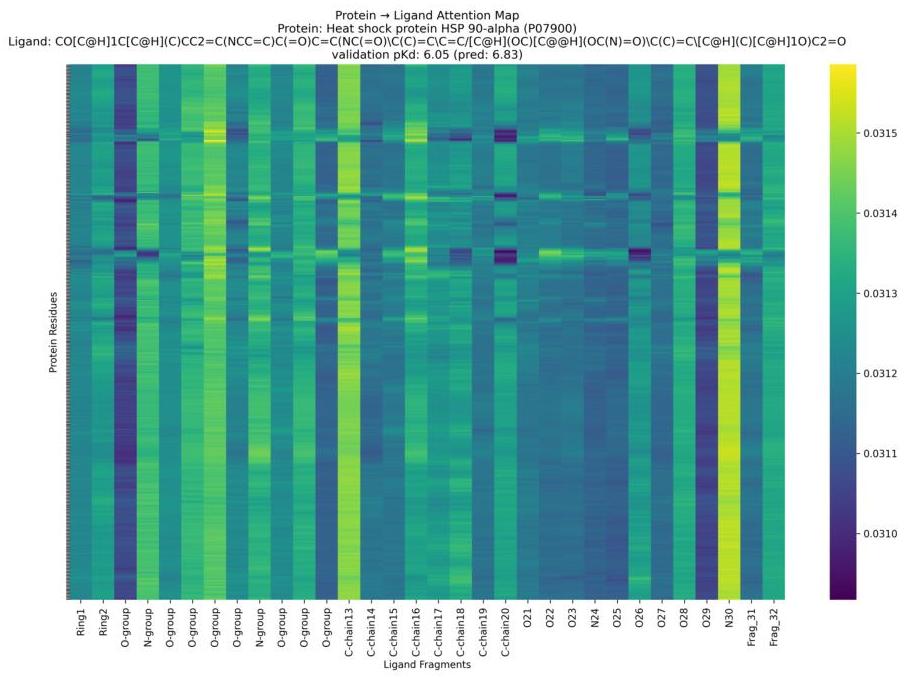
图2:HSP90-alpha-配体复合物的iBAM。该热图可视化了HSP90-alpha(UniProt ID P07900)的蛋白残基与候选配体(显示为Morgan指纹片段)的亚结构之间的交叉注意力权重。较暖(黄色)区域对应较高的注意力,突显驱动预测结合亲和力的关键残基-亚结构相互作用。这里,预测的pKd为6.83,而实验测定的pKd为6.05。通过提供模型如何“聚焦”特定蛋白-配体接触的清晰、可解释视图,iBAM为引导理性药物设计和促进基于结构的药物发现中的定向先导优化提供了有价值的工具。
编排与部署
PharmaSwarm的各层通过灵活的工作流引擎或容器平台编排:
- 低代码平台:n8n、Apache Airflow或Prefect用于可视DAG构建、内置重试逻辑和监控仪表板。
-
- Kubernetes微服务:Argo Workflows或Kubeflow Pipelines用于可扩展的云原生执行,利用Helm图表进行可重复部署和Istio进行安全的服务网格通信。
-
- CI/CD集成:GitOps管道确保更新的代理代码或模型权重自动重新部署,通过Canary发布和A/B测试验证系统性能改进。
3 迭代群工作流
PharmaSwarm作为一个闭环、迭代过程运行,其中用户输入、基于代理的假设生成、机制验证和评估反馈推动持续优化。在每次循环开始时,最终用户指定感兴趣的疾病或生物背景,并可能施加约束条件,例如首选目标类别、化合物库或可接受的安全阈值。编排器——在n8n工作流引擎或作为Kubernetes原生微服务上实现——然后调用getGPT和PAGER以检索和排名相关的遗传变异和表达特征,生成带有相关统计注释的种子基因列表。
同时,编排器并行启动三个代理服务。Terrain2Drug代理消费种子列表,并将其投影到GeneTerrain Knowledge Maps上以识别高度网络中心节点。Paper2Drug代理向PubMed和bioRxiv提交文献检索查询,使用LLM驱动提取提出基于近期出版物的目标-化合物对。Market2Drug代理摄入法规公告、临床试验更新、财经新闻提要和社会媒体信号,计算化学相似性和网络影响得分以突出再利用候选物。所有服务间通信通过消息队列处理,确保异步可扩展性,每个代理将其原始提案——目标或化合物——记录到共享内存存储中。
一旦收集到初始假设,验证和评估层就会参与其中。PETS模拟引擎接收候选化合物以模拟组织特异性蛋白质相互作用网络的计算机扰动,生成标准化的效能和毒性指标。同时,可解释结合亲和力模块计算基于注意力的结合图和pKd\mathrm{pK}_{\mathrm{d}}pKd估计值,适用于每个目标-配体对。
所有模拟输出,连同回溯元数据链接到图遍历、文献引用和输入数据版本,汇总给中央评估LLM。此评估器应用多标准评分规则——评估经验支持、机制一致性、相对于现有知识的新颖性、预测的安全边际和人类可读的可解释性——并为每个假设分配综合评分。
详细反馈以结构化提示的形式制定,然后路由回各个代理。例如,Terrain2Drug代理可能会被指示降低低可药性枢纽的优先级或探索替代网络模块;Paper2Drug代理可能会收到关于细化搜索词以关注激酶抑制剂的指导;Market2Drug代理可能会被指示纳入额外的社会媒体情绪过滤器。代理相应地更新其内部提示历史和启发式方法,编排器启动下一次迭代。
循环继续,直到满足收敛标准——例如达到最大迭代次数、顶级评分的最小改进阈值或搜索空间耗尽。工作流通过导出最终优先排序的目标和化合物列表结束,包括交互式的回溯报告、模拟仪表板和结合图,以支持专家决策和下游实验验证。
4 示例用例场景
Paper2Drug. 在Paper2Drug场景中,PharmaSwarm代理执行端到端文献挖掘,直接从科学出版物中揭示新的目标-化合物假设。首先,编排器向PubMed和bioRxiv发出API调用,检索摘要和,当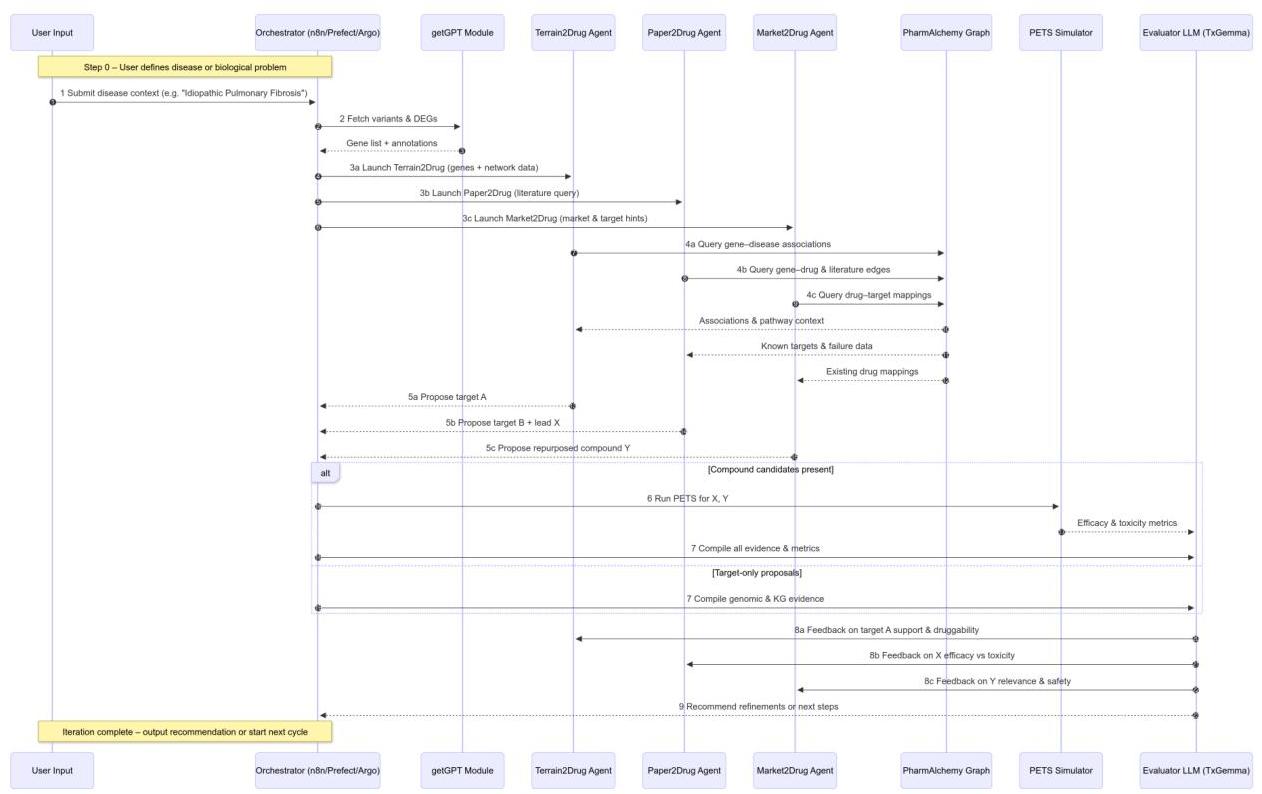
图3:迭代工作流和示例场景。PharmaSwarm工作流以假设生成和优化的迭代周期进行。在这里,我们描述一个典型的周期,然后说明它在三个示例场景(Paper2Drug、Terrain2Drug和Market2Drug)中的表现,这对应于群体可以采取的不同初始策略。该图概述了群体工作流在一个给定疾病输入的迭代中的简化交互序列。
可用时,开放访问全文。然后,Paper2Drug代理在GPT-4或Gemini中应用链式思维提示协议,要求模型识别药物-目标对的明确提及,以及暗示新相互作用的隐式机制线索——例如通路调节或表型救援实验。提取的候选对标注有元数据(出版DOI、句子索引、置信度评分),并传递给PharmAlchemy进行基于图的交叉验证:多跳遍历确认所提议的目标是否通过已知可药通路连接到疾病节点,以及类似的支架-目标对是否有先例。有前途的候选对象被转发到PETS模拟引擎,其中计算机扰动评估效能(通路逆转)和脱靶毒性。最后,代理编制结合注意力图,突出解释预测亲和力的残基-亚结构对齐,并组装回溯报告,将每个假设链接到具体出版物、图路径和模拟指标。这条端到端管道将非结构化文本转化为机制基础的、可实验验证的药物假设。
Terrain2Drug. Terrain2Drug利用患者衍生的组学揭示高影响调控枢纽及其调节剂。从GEO的批量RNA-seq数据集或TCGA的单细胞配置文件开始,编排器通过既定管道(例如批量的DESeq2、单细胞的Seurat)标准化原始计数,并计算相对于相关对照的差异表达。所得基因列表被投影到GeneTerrain Knowledge Maps上,这些地图将表达变化渲染为组织特异性蛋白质-蛋白质相互作用网络中的地形升高。高峰——具有高倍数变化和中心性的基因——被标记为候选调控因子。接下来,代理查询KEGG、Reactome和PAGER API以执行过度表示和拓扑感知富集,识别驱动疾病表型的通路和上游节点。PharmAlchemy遍历将这些枢纽映射到具有已知或预测结合概况的化合物。每对枢纽-化合物进行PETS模拟,评估网络弹性和PK/PD动力学,以及结合亲和力注意力映射。验证后的对存储在共享内存中,这更新了TxGemma子模型,锐化其启发式方法以供后续循环使用。这种迭代过程以数据驱动、机制透明的方式优化目标选择和化合物优化。
Market2Drug. Market2Drug整合真实世界情报以优先考虑从现有药典中再利用的机会。编排器流式传输结构化和非结构化市场信号:通过OpenFDA API的FDA批准公告、ClinicalTrials.gov的临床试验注册更新、Bloomberg或Refinitiv的财务数据,以及Twitter和Reddit(如r/medicine、r/pharmacology子版块)上的社交媒体讨论。专门的LLM管道将这些异构输入转换为标准化的情绪和相关性评分,识别正在获得吸引力或面临安全警报的化合物。同时,代理使用ChemBERTa嵌入计算与批准药物库的化学相似性指标,并将顶级候选物提交给PETS进行网络影响模拟。PharmAlchemy图查询验证再利用候选物与疾病背景之间的机制联系,确保每个推荐都基于生物学合理性。然后将社交媒体情绪和监管标志与效能和毒性评分相结合,以按综合“临床可操作性”指标对化合物进行排名。最终的
优先列表反映了科学严谨性和市场准备情况,使得Market2Drug特别适合快速转化和现实世界的验证。
5 验证策略
建立对PharmaSwarm输出的信心需要一个严格的四层验证管道,从历史重建到现实世界的专家反馈,每一步都用标准化指标进行评估。
第一层:回顾性基准测试
我们首先使用当时可用的数据——GWAS摘要、表达数据集、文献语料库和化合物库——重构经典发现案例(例如特发性肺纤维化、三阴性乳腺癌)。以“冻结”模式运行PharmaSwarm(不进行后续微调),我们将其前K个目标和化合物排名与临床“事实”进行比较。通过Recall@K和Precision@K对已知先导物进行量化,通过Kendall’s Tau与实际验证顺序的相关性进行量化,并通过MAP(Mean Average Precision)跨适应症进行量化。通过引导置信区间评估相对基线方法(例如单代理LLM或标准网络再利用)的显著性。
第二层:前瞻性计算机评估
第一层的新假设接受独立的计算测试。我们进行盲对接和目标分子对接(AutoDock Vina、Glide)以获取结合能并验证姿态,随后进行短(50-100 ns)分子动力学模拟以评估复合物稳定性(均方根偏差、氢键占有率)。使用pkCSM或ADMETlab生成预测的ADMET概况,并在替代PPI网络上重新运行PETS模拟以验证效能和毒性得分的稳健性。最后,我们通过PharmaSwarm预测的pKdp K_{d}pKd和效能指标与对接亲和力(Pearson’s rrr)、MD稳定性及已知药物标签ADMET标志进行相关性分析,提供定量验证。
第三层:实验评估
顶级候选人进入实验室检测阶段,其中结合亲和力(Kd)\left(K_{d}\right)(Kd)通过SPR或ITC测量,细胞表型筛选得出IC50IC_{50}IC50值和通路特异性读数(例如报告子检测)。使用受体或激酶面板(Cerep、DiscoverX)分析脱靶活性,而在小鼠模型(纤维化、异种移植)中的体内初步研究评估药代动力学、疗效生物标志物和安全性终点。预先定义的通过/不通过标准——例如Kd<100nM,IC50<1μMK_{d}<100 \mathrm{nM}, IC_{50}<1 \mu \mathrm{M}Kd<100nM,IC50<1μM和可接受的治疗指数——确定命中率和进展。
第四层:专家用户研究
为了衡量实用性,我们让药物化学家、药理学家和转化生物学家在PharmaSwarm指导和传统工作流程之间进行定时比较。参与者在每种方法下生成并记录前N个假设。我们跟踪假设生成时间,收集专家对机制合理性和新颖性的评分(Likert量表),并在前后调查决策信心。成对测试(例如Wilcoxon符号秩检验)量化速度、质量和信心的改进。
6 讨论与未来方向
PharmaSwarm展示了模块化、多代理方法如何将多样化的数据模式、机制模拟和可解释的人工智能整合到单一、连贯的管道中。通过容器化每个代理并通过低代码平台或Kubernetes原生框架编排工作流,系统实现了可重复性和弹性可扩展性——从单个工作站到高性能云计算集群。每一步的详细来源跟踪解决了监管和审计要求,确保每个建议都有可追溯的证据:知识图遍历、文献引用、模拟日志和结合注意力图。
尽管如此,仍存在几个挑战和机会。首先,输入数据的质量和完整性极大地影响假设生成;在摄取阶段整合数据质量指标和不确定性量化将提高鲁棒性。其次,虽然共享内存启用连续学习,但必须通过有针对性的微调计划和检查点策略管理模型漂移和灾难性遗忘。第三,联邦学习可以将PharmaSwarm扩展到私有或专有数据集——允许多个机构在不共享原始数据的情况下协作改进子模型。第四,新兴的功能基因组学检测方法——如CRISPR筛选和单细胞多组学——将提供更高分辨率的细胞类型特异性靶点和药物反应见解。第五,实时摄取预印本、临床试验更新和监管通知将使系统与最新发展保持一致,增强其在快速演变领域的响应能力,如肿瘤学或传染病。
展望未来,整合临床结果预测模块——在电子健康记录队列或试验结果上训练——可以关闭从计算机假设生成到患者影响的循环,实现端到端人工智能驱动的转化研究。嵌入人机环评审界面和视觉分析将促进领域专家中的采用,平衡自动化建议与专家判断。最后,通过对不断发展的黄金标准数据集进行严格基准测试和参与社区挑战将推动持续改进和透明度。
7 结论
PharmaSwarm展示了一个新颖、有竞争力的LLM代理群,它统一了异构的生物医学数据、机制模拟引擎和可解释的机器学习,形成一个不断进化的假设驱动药物发现框架。其分层架构——跨越数据摄取、专门代理推理和严格验证——提供了一条从原始数据到优先目标和化合物的透明且可审计的路径。通过结合回顾性和前瞻性验证策略、灵活的部署选项和共享的验证见解,PharmaSwarm不仅加速了可操作假设的生成,还能随着时间的推移适应新知识和新兴技术。随着转化管道越来越依赖AI辅助,PharmaSwarm为多代理系统如何在下一代治疗药物的追求中提供科学严谨性、监管合规性和实际影响提供了蓝图。
参考文献
[1] Waring MJ, Arrowsmith J, Leach AR, et al. 四大制药公司药物候选物流失分析。Nature Reviews Drug Discovery. 2015;14(7):475-486.
[2] Pushpakom S, Iorio F, Eyers PA, et al. 药物再利用:进展、挑战和建议。Nature Reviews Drug Discovery. 2019;18:41-58.
[3] OpenAI. GPT-4 技术报告。arXiv:2303.08774. 2023.
[4] Bommasani R, Hudson D, Adeli E, et al. 基础模型的机会与风险。arXiv:2108.07258. 2021.
[5] Segler MHS, Preuss M, Waller M. 使用深度神经网络和符号AI规划化学合成。Nature. 2020;555:604-610.
[6] Pompe N, et al. 使用多代理LLM系统的自主实验室规划。Nature Communications. 2023;14:2345.
[7] Nguyen T, et al. 基于代理的语言模型气候建模。Geophysical Research Letters. 2023;50(10):e2022GL100123.
[8] Li X, Gan Z, Carin L. 超越单代理LLM:多代理LLM交互综述。arXiv:2211.00845. 2022.
[9] Wang Y, Jiang L, Zhou M, Smith NA. 评估大型语言模型中的多代理协作。Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). 2023:2334-2346.
[10] Wang E, Schmidgall S, Jaeger PF, Zhang F, Pilgrim R, Matias Y, Barral J, Fleet D, Azizi S. TxGemma:高效的治疗性LLM。arXiv:2504.06196. 2025.
[11] Ochoa D, Hercules A, Carmona M, et al. Open Targets平台:重新想象药物靶点识别。Nucleic Acids Research. 2023;51(D1):D1305-D1316.
[12] Edgar R, Domrachev M, Lash AE. Gene Expression Omnibus:NCBI基因表达和杂交阵列数据存储库。Nucleic Acids Research. 2002;30(1):207-210.
[13] Gaulton A, Hersey A, Nowotka M, et al. 2017年的ChEMBL数据库。Nucleic Acids Research. 2017;45(D1):D945-D954.
[14] Wishart DS, et al. DrugBank 5.0:2018年对DrugBank数据库的重大更新。Nucleic Acids Research. 2018;46(D1):D1074-D1082.
[15] Sosa DN, Derry A, Guo M, Wei E, Brinton C, Altman RB. 一种基于文献的知识图嵌入方法,用于识别罕见病中的药物再利用机会。Pacific Symposium on Biocomputing. 2020:589-600.
[16] Kanehisa M, Goto S. KEGG:京都基因与基因组百科全书。Nucleic Acids Research. 2000;28(1):27-30.
[17] Jassal B, Matthews L, Viteri G, et al. Reactome通路知识库。Nucleic Acids Research. 2020;48(D1):D498-D503.
[18] Song K, Chen JY. 使用PETS进行精确药物再利用的整合多尺度网络模拟。bioRxiv. 2025.
[19] Rives A, Meier J, Sercu T, et al. 生物结构和功能从2.5亿个蛋白序列的无监督学习规模中浮现。Proceedings of the National Academy of Sciences. 2021;118(15):e2016239118.
[20] Chithrananda S, Grand G, Ramsundar B. ChemBERTa:大规模自监督预训练用于分子性质预测。arXiv:1910.06725. 2022.
[21] Apache Airflow. 2017. https://airflow.apache.org/
[22] Prefect. 2023. https://www.prefect.io/
[23] Di Tommaso P, et al. Nextflow实现可重复的计算工作流。Nature Biotechnology. 2017;35(4):316-319.
[24] Köster J, Rahmann S. Snakemake——可扩展的生物信息学工作流引擎。Bioinformatics. 2012;28(19):2520-2522.
[25] Kubeflow Pipelines. 2023. https://www.kubeflow.org/
[26] Argo Workflows. 2024. https://argoproj.github.io/argo-workflows/
[27] n8n. 2024. https://n8n.io/
参考论文:https://arxiv.org/pdf/2504.17967

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)