多查询注意力(MQA):让大模型推理飞起来的秘密武器
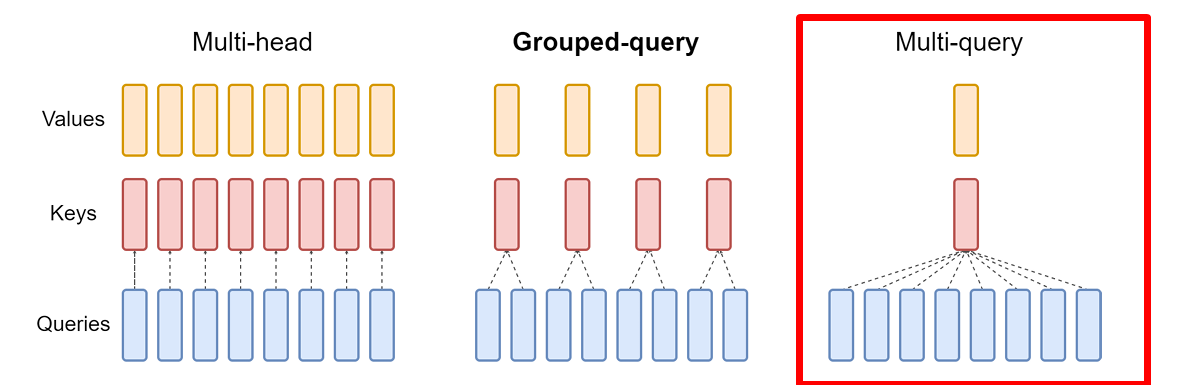
在了解MQA之前,我们先简单回顾一下Transformer模型中的多头注意力机制(MHA)。MHA是让模型能够同时关注输入序列中不同位置信息的关键技术,它通过多个"注意力头"来捕捉不同的语义关系。而MQA则是MHA的一个精简版本:它保留了多个查询(query)头,但所有查询头共享同一个键(key)和值(value)头。这个看似简单的改动,却带来了惊人的性能提升!MQA代表了大模型高效推理的重要方向
大家好!今天我们要聊一个让大语言模型"跑得更快"的黑科技——多查询注意力(Multi-Query Attention, MQA)。如果你曾经好奇为什么最新的大模型能在手机上流畅运行,或者为什么AI应用响应越来越快,MQA很可能就是幕后功臣之一!
什么是MQA?
在了解MQA之前,我们先简单回顾一下Transformer模型中的多头注意力机制(MHA)。MHA是让模型能够同时关注输入序列中不同位置信息的关键技术,它通过多个"注意力头"来捕捉不同的语义关系。
而MQA则是MHA的一个精简版本:它保留了多个查询(query)头,但所有查询头共享同一个键(key)和值(value)头。 这个看似简单的改动,却带来了惊人的性能提升!
为什么MQA如此重要?
想象一下你在组织一场大型会议:
- 在标准MHA中,每位参会者(查询头)都有自己的记录员(键和值头)来记录会议内容
- 而在MQA中,所有参会者共享同一位记录员
这样做的好处显而易见:需要培训和管理的记录员数量大大减少,会议组织更加高效!
具体来说,MQA带来了三大核心优势:
1️⃣ 内存占用大幅降低
在大模型推理过程中,系统需要缓存之前所有token的key和value,这被称为KV缓存。对于拥有数十亿参数的模型,KV缓存可能占用数GB的显存!
而MQA通过共享key和value,将KV缓存大小减少了5-10倍。这意味着:
- 更长的上下文窗口
- 更多的并发请求
- 在消费级GPU上运行更大的模型
2️⃣ 推理速度显著提升
减少KV缓存不仅节省内存,还大幅提升了推理速度。实验表明,MQA可以在几乎不损失质量的情况下,将生成速度提高2-3倍。
这对于需要实时响应的应用场景(如聊天机器人、实时翻译)至关重要。想象一下,以前需要3秒生成的回复,现在只需1秒多,用户体验的提升是质的飞跃!
3️⃣ 部署成本大幅降低
对于企业来说,MQA意味着:
- 可以使用更便宜的GPU部署模型
- 单台服务器可以服务更多用户
- 降低云服务成本
这使得大模型技术能够更广泛地应用于实际业务场景,而不仅限于拥有顶级硬件的科技巨头。
代码实现
以下是PyTorch实现的Multi-Query Attention:
import torch
import torch.nn as nn
import time
class MultiQueryAttention(nn.Module):
def __init__(self, d_model, num_heads):
"""
多查询注意力(MQA)实现
参数:
d_model: 模型维度(如512)
num_heads: 注意力头数(如8)
"""
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
# 核心设计:查询投影保持多头,键值投影为单头
self.q_proj = nn.Linear(d_model, d_model) # [d_model, d_model]
self.k_proj = nn.Linear(d_model, self.head_dim) # [d_model, head_dim]
self.v_proj = nn.Linear(d_model, self.head_dim) # [d_model, head_dim]
self.out_proj = nn.Linear(d_model, d_model) # 输出投影
def forward(self, x, mask=None):
"""
前向传播
输入:
x: 输入张量 [batch_size, seq_len, d_model]
mask: 可选掩码 [batch_size, seq_len]
返回:
注意力输出 [batch_size, seq_len, d_model]
"""
B, L, _ = x.shape # 批大小,序列长度
# 1. 投影操作
Q = self.q_proj(x).view(B, L, self.num_heads, self.head_dim) # [B, L, H, D]
K = self.k_proj(x).unsqueeze(2) # [B, L, 1, D] (关键:单头键)
V = self.v_proj(x).unsqueeze(2) # [B, L, 1, D] (关键:单头值)
# 2. 注意力计算(利用广播机制)
# Q: [B, L, H, D] -> K: [B, L, 1, D] -> 点积: [B, H, L, L]
attn_scores = torch.einsum("blhd,bkhd->bhlk", Q, K) / (self.head_dim ** 0.5)
# 3. 掩码处理
if mask is not None:
# 扩展掩码维度以匹配注意力分数
mask = mask.unsqueeze(1).unsqueeze(1) # [B, 1, 1, L]
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 4. 注意力权重和输出
attn_weights = torch.softmax(attn_scores, dim=-1)
output = torch.einsum("bhlk,bkhd->blhd", attn_weights, V) # [B, L, H, D]
# 5. 合并多头输出
return self.out_proj(output.reshape(B, L, -1))
# ===================== 调用示例 =====================
if __name__ == "__main__":
# 配置参数
d_model = 512
num_heads = 8
batch_size = 4
seq_len = 1024 # 长序列测试
# 创建MQA模块
mqa = MultiQueryAttention(d_model, num_heads)
# 模拟输入数据(随机初始化)
x = torch.randn(batch_size, seq_len, d_model)
mask = torch.ones(batch_size, seq_len) # 全1掩码(无遮挡)
# 预热GPU
for _ in range(3):
_ = mqa(x, mask)
# 性能测试
start_time = time.time()
for _ in range(10): # 10次运行取平均
output = mqa(x, mask)
elapsed = (time.time() - start_time) / 10
# 输出结果
print(f"输入形状: {x.shape}")
print(f"输出形状: {output.shape}")
print(f"MQA处理时间: {elapsed * 1000:.2f} ms (序列长度={seq_len})")
# 与传统多头注意力(MHA)的显存对比
print("\n内存占用对比:")
print(f"MQA参数数量: {sum(p.numel() for p in mqa.parameters()) / 1e6:.2f} M")
# 模拟KV缓存(推理场景)
def get_kv_cache_size(module):
"""计算KV缓存大小(模拟1000 token上下文)"""
# 获取第一层权重
k_weight = module.k_proj.weight
v_weight = module.v_proj.weight
# 计算缓存大小(假设float32)
cache_size = (k_weight.shape[0] + v_weight.shape[0]) * 1000 * 4 / 1e6
return cache_size
print(f"MQA KV缓存大小: {get_kv_cache_size(mqa):.2f} MB (1000 tokens)")
# 传统MHA的KV缓存估算(对比)
mha_kv_size = (d_model * 2) * 1000 * 4 * num_heads / 1e6
print(f"传统MHA KV缓存大小: {mha_kv_size:.2f} MB (1000 tokens)")
输出结果: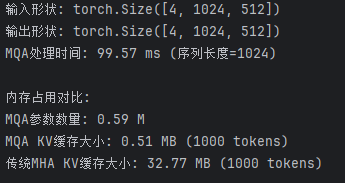
优点与缺点
优点
-
降低内存带宽和键值缓存大小:MQA显著减少了KV缓存的内存占用,这对于长序列处理和大模型推理特别重要。
-
计算效率提高:通过共享键和值投影,MQA大幅降低了计算复杂度,加速了模型推理过程。
-
增强上下文理解能力:多个查询头可以捕捉不同方面的信息,同时共享的键值提供了统一的上下文表示。
-
可扩展性:MQA在大型模型中表现良好,能够有效处理长序列数据,提高了模型的可扩展性。
-
加速推理:特别在自回归解码过程中,由于KV缓存大幅减少,生成token的速度显著提升。
缺点
-
潜在的表达能力损失:共享键和值投影可能会限制模型的表达能力,因为不同头之间无法学习到独立的键值表示。
-
性能下降:尽管计算效率提高,但在某些任务上,模型质量可能会有所下降,需要权衡速度和精度。
-
模型容量降低:与标准多头注意力相比,MQA的模型容量和质量较低,这可能影响复杂任务的性能。
-
适用场景限制:MQA更适合推理阶段的优化,在训练阶段可能不如标准多头注意力表现好,特别是在需要高度表达能力的任务上。
与GQA的比较
值得注意的是,Grouped-Query Attention (GQA)是MQA的一个扩展,论文链接:https://arxiv.org/pdf/2305.13245,它将查询头分组,每组共享一组键值,是多头注意力和多查询注意力之间的折中方案。 GQA在保持MQA大部分效率优势的同时,减少了性能下降的问题,成为当前许多大型语言模型(如LLaMA-2)的选择。
总之,Multi-Query Attention是一种在保持合理性能的同时显著提高推理效率的技术,特别适合需要快速响应的应用场景,但在选择使用MQA时需要权衡模型性能和计算效率。
MQA vs GQA:技术演进
细心的读者可能听说过分组查询注意力(Grouped Query Attention, GQA),它是MQA和MHA之间的一种折中方案。
- MHA:每个查询头都有独立的键值头(质量最高,速度最慢)
- GQA:将查询头分组,每组共享键值头(质量与速度的平衡)
- MQA:所有查询头共享同一键值头(速度最快,质量略低)
研究表明,MQA通常能达到MHA 95%以上的性能,但速度提升显著,因此在许多实际应用中成为首选。
使用Multi-Query Attention的模型
确认使用MQA的模型
-
Falcon系列模型:Falcon-7B、Falcon-40B等模型明确采用了Multi-Query Attention技术,这显著提高了其推理速度。
-
Google PaLM:作为Google开发的大规模语言模型,PaLM使用了MQA技术来优化其推理性能。
-
StarCoder:这款由BigCode开发的代码生成模型也采用了Multi-Query Attention机制。

MQA与相关技术的区别
需要注意的是,有些模型使用的是MQA的变种而非纯粹的MQA:
-
LLaMA2系列:LLaMA2的34B和70B大模型版本采用的是Grouped Multi-Query Attention(GQA),而7B和13B小模型版本则使用标准的Multi-Head Attention(MHA)。
-
GQA与MQA的关系:Grouped-Query Attention可以看作是MQA和标准MHA之间的折中方案,它将查询头分组,每组共享一组键值对。

结语
MQA代表了大模型高效推理的重要方向——在保持模型能力的同时,大幅降低计算和内存需求。随着AI技术向移动端和边缘设备扩展,这类优化技术将变得越来越重要。
下次当你体验一个反应迅速的大模型应用时,不妨想想背后可能正是MQA这样的技术在默默发力。技术的进步往往不在于惊天动地的变革,而在于这些精巧的优化积累。
你对MQA技术有什么看法?欢迎在评论区分享你的见解!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)