OpenCV背景减除法实战与参数优化
在计算机视觉和视频监控领域,背景减除法是一种常用的视觉运动检测技术,旨在从视频序列中分离出前景目标,通常是为了检测移动对象。它的基本原理是基于背景模型的建立和更新,通过当前帧与背景模型的差异来识别前景物体。背景减除法不仅在视频监控中广泛应用,也服务于交通监控、人机交互、智能视频分析等多种场景。

简介:背景减除法用于检测视频监控中的动态目标,OpenCV提供了多种算法,其中BackgroundSubtractorMOG2是基于自适应混合高斯模型的常用算法。本文介绍该算法的原理和在Visual Studio中使用OpenCV3库的实现步骤,包括关键参数的调整,以帮助开发者在不同场景下实现最佳的动态目标检测效果。 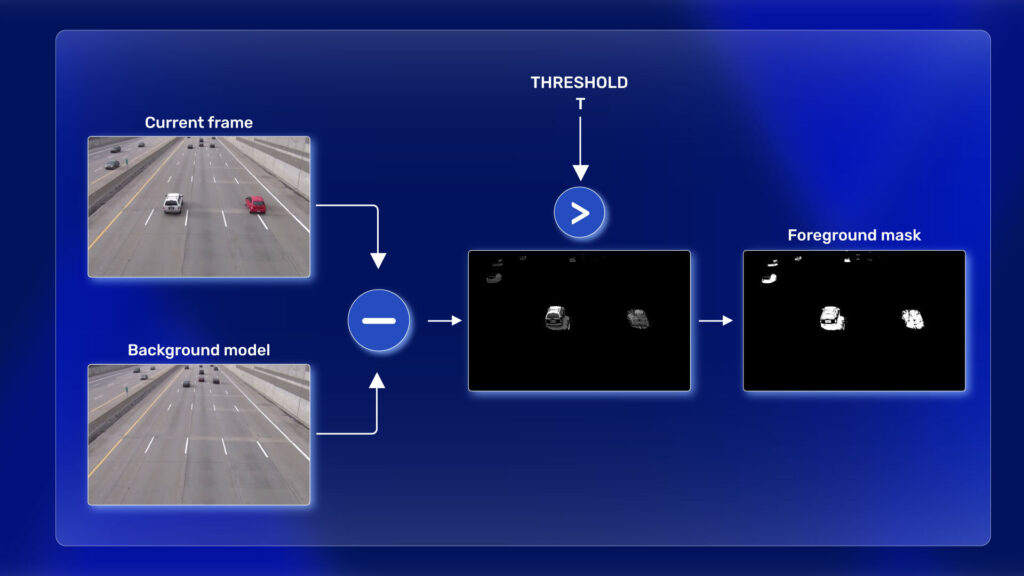
1. 背景减除法介绍
在计算机视觉和视频监控领域,背景减除法是一种常用的视觉运动检测技术,旨在从视频序列中分离出前景目标,通常是为了检测移动对象。它的基本原理是基于背景模型的建立和更新,通过当前帧与背景模型的差异来识别前景物体。背景减除法不仅在视频监控中广泛应用,也服务于交通监控、人机交互、智能视频分析等多种场景。
1.1 背景减除法的基本概念
背景减除法,简而言之,就是利用视频帧与背景模型的差异来识别前景目标。它基于一个前提假设:视频中的背景是相对静态的,而前景活动是动态变化的。因此,算法首先需要对背景进行建模,然后每一帧通过与背景模型相减,凸显出前景的变化区域,即为检测到的动态对象。
1.2 背景减除法的应用场景
该技术的应用范围非常广泛,其中包括但不限于:
- 视频监控系统 :监控摄像头中常用来检测异常行为,比如监控区域内有人徘徊或物体被移动。
- 交通监控 :通过识别车辆和行人的运动,可以用于交通流量统计、事故检测等。
- 人机交互 :背景减除技术在游戏和虚拟现实领域中可以用来检测用户的动作,作为输入设备的一部分。
- 智能视频分析 :如用于零售业人流分析、智慧城市中的交通流量监控等。
在本章中,我们对背景减除法进行了初步介绍,并概述了它的基本概念和应用场景,接下来的章节将会详细探讨 BackgroundSubtractorMOG2 算法的原理及应用。
2. BackgroundSubtractorMOG2算法原理
2.1 背景减除法的概念和应用
2.1.1 背景减除法的基本概念
背景减除法是一种用于视频监控系统中动态目标检测的常用技术。其基本原理是假设背景是静态的,通过计算当前视频帧与背景模型的差异,从而分割出前景中的运动目标。为了实现这一目标,需要构建一个准确的背景模型,并能够实时地进行更新,以适应场景中的背景变化,如天气、光照条件的变化等。
背景减除法的核心在于背景模型的建立和维护。这一模型需要能够适应场景中的长期变化,同时对于短暂的、非背景的变化(例如树叶摆动、水面波纹等)有足够的鲁棒性。在动态目标检测中,一旦目标被分割出来,后续的步骤包括目标跟踪、行为分析和异常事件检测等都将基于这一分割结果进行。
2.1.2 背景减除法的应用场景
背景减除法广泛应用于监控视频分析、交通流量监测、视频会议系统以及交互式媒体等领域。例如,在智能交通系统中,通过对车辆的检测与跟踪,可以实现对交通流量的分析和统计;在零售行业,通过分析顾客在商店中的行为模式,可以优化店面布局和营销策略;在安全监控领域,通过检测异常行为和快速响应,可以大大提高安全防范效率。
随着技术的发展,背景减除法也在不断地被优化和改进。例如,基于深度学习的背景减除方法已经开始应用于更复杂场景下的目标检测,并且取得了显著的效果。尽管如此,传统的背景减除法仍然在许多实时系统中占有重要的地位,特别是对于那些计算资源有限的环境。
2.2 BackgroundSubtractorMOG2算法原理
2.2.1 MOG2算法的特点和优势
MOG2(Mixture of Gaussians 2)算法是BackgroundSubtractorMOG2类的核心算法,它使用高斯混合模型(Gaussian Mixture Models,GMM)来维护背景模型。MOG2算法的主要优势在于它对噪声和光照变化的鲁棒性,以及能够处理多个运动目标的能力。相比于旧版本的MOG算法,MOG2算法主要改进在于对模型更新机制的优化,提高了处理速度和减少了内存消耗。
MOG2算法能够自动地根据视频帧的特性确定背景中的像素点是静态的还是动态的,并根据像素点的统计特性(如颜色、亮度)来分配和更新高斯分布。一旦确定某像素点为背景点,就会在背景模型中为该点建立一个或多个高斯分布;当像素点被检测为前景时,算法会更新或替换掉相应的高斯分布。这种机制使得MOG2算法在动态场景中有很好的适应性。
2.2.2 MOG2算法的工作流程和原理
MOG2算法的工作流程大致可以分为背景模型的初始化、背景更新以及前景和背景的分割三个主要步骤。
-
背景模型初始化 :算法开始时,会从序列的第一帧图像中提取背景信息,初始化高斯分布。这一阶段对于后续的分割结果至关重要,好的初始化能够减少后续计算量并提高检测准确性。
-
背景更新 :随着视频序列的进行,背景模型会不断更新以适应场景中的变化。MOG2算法采用了一种智能的更新机制,只有当像素点在一段时间内保持为背景时,才会用新的值来更新背景模型。此外,算法还会调整各个高斯分布的权重,以反映背景点出现的概率。
-
前景和背景分割 :最后,MOG2算法根据背景模型来判断当前帧的像素点属于前景还是背景。对于每个像素点,算法会计算其与背景模型中高斯分布的相似度。如果某个像素点与所有的背景高斯分布都不匹配,则判定为前景。
这个过程可以利用OpenCV库中的BackgroundSubtractorMOG2类来实现。在下一章节,我们将详细介绍如何在OpenCV中应用和配置BackgroundSubtractorMOG2类。
3. OpenCV3库集成与使用
3.1 OpenCV3库的安装和配置
3.1.1 OpenCV3库的安装步骤
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库,提供了丰富的图像处理和视频分析功能。集成和使用OpenCV3库是进行视频处理和背景减除的第一步。以下是安装OpenCV3库的步骤:
- 环境准备 :确保系统已经安装了C++编译器以及支持C++11标准的库,如g++(Linux环境下)或Visual Studio(Windows环境下)。
-
下载OpenCV3源码 :访问OpenCV官方网站下载OpenCV3的源码包,或者使用版本控制系统如Git克隆仓库。
-
安装依赖库 :根据操作系统,安装OpenCV所依赖的库,例如在Ubuntu系统上可能需要安装
build-essential,cmake,libgtk2.0-dev,pkg-config,libavcodec-dev,libavformat-dev,libswscale-dev等。 -
配置OpenCV :使用CMake配置OpenCV。创建一个构建目录,在该目录下运行
cmake并指定OpenCV源码路径。 -
编译安装 :在构建目录下执行
make命令开始编译。编译完成后,使用make install将OpenCV安装到系统路径下。
3.1.2 OpenCV3库的配置和使用
配置完成后,可以使用C++或Python调用OpenCV库进行编程。以下是一个简单的示例,展示如何使用OpenCV3库读取和显示一张图片:
#include <opencv2/opencv.hpp>
int main(int argc, char** argv) {
// 加载图片
cv::Mat image = cv::imread("path/to/image.jpg");
// 显示图片
cv::imshow("Display window", image);
// 等待按键操作
cv::waitKey(0);
return 0;
}
在使用OpenCV进行开发时,需要熟悉其核心数据结构 cv::Mat ,该结构用于存储图像和其他矩阵数据。同时,要掌握其丰富的模块功能,例如图像处理( imgproc )、视频分析( video )和机器学习( ml )等。
3.2 OpenCV3库中的BackgroundSubtractorMOG2类
3.2.1 BackgroundSubtractorMOG2类的使用方法
BackgroundSubtractorMOG2 类是OpenCV库中实现的基于高斯混合模型的背景减除方法。在视频流处理中,该类可以有效地分离前景目标。以下是使用 BackgroundSubtractorMOG2 类的基本方法:
-
创建背景减除器对象 :使用
cv::createBackgroundSubtractorMOG2函数创建背景减除器对象,并可以传入参数进行初始化。 -
更新背景模型 :对于视频流的每一帧,使用
apply函数更新背景模型并获取前景掩码。 -
获取前景图像 :通过
apply函数返回的掩码,可以进一步提取前景图像,进行目标检测、跟踪等操作。
示例代码如下:
cv::Ptr<cv::BackgroundSubtractorMOG2> pMOG2 = cv::createBackgroundSubtractorMOG2();
cv::Mat frame, fgMask;
// 读取视频帧
while (true) {
cap >> frame;
if (frame.empty())
break;
// 更新背景模型并获取前景掩码
pMOG2->apply(frame, fgMask);
// 显示前景掩码
cv::imshow("Frame", frame);
cv::imshow("FG Mask", fgMask);
cv::waitKey(30);
}
3.2.2 BackgroundSubtractorMOG2类的参数设置
BackgroundSubtractorMOG2 类提供了多个参数,以优化背景减除的效果。主要参数包括:
history:用于指定背景模型更新的历史帧数,数值越大,背景模型对环境变化的适应越慢。nmixtures:指定用于背景混合的高斯分布数量,增加这个值可以获得更精细的背景建模。backgroundRatio:定义更新背景模型的阈值,用于定义何为“背景”。
通过调整这些参数,可以根据具体应用场景来优化背景减除算法的效果。代码示例中展示了一个简单的循环,用于读取视频帧并应用背景减除,但在实际应用中可能需要根据视频流的特征以及背景复杂程度调整相关参数。
4. 背景减除实现步骤
4.1 背景减除的基本步骤
4.1.1 视频读取和处理
在进行背景减除之前,首先需要读取视频或者实时摄像头捕获的帧。在OpenCV中, VideoCapture 类可以用来读取视频文件或摄像头数据。下面是一个简单的示例代码,展示了如何使用OpenCV读取视频,并显示每一帧。
import cv2
# 打开视频文件或摄像头
cap = cv2.VideoCapture('video.mp4')
# 检查视频是否打开成功
if not cap.isOpened():
print("Error: Could not open video.")
exit()
while True:
# 逐帧捕获视频
ret, frame = cap.read()
# 如果正确读取帧,ret为True
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
# 显示当前帧
cv2.imshow('Frame', frame)
# 按 'q' 键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放VideoCapture对象
cap.release()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
在这段代码中, cap.read() 用于读取视频的下一帧。如果帧读取成功, ret 将会是 True ,并且当前帧会存储在变量 frame 中。 cv2.imshow() 函数用于显示帧,而 cv2.waitKey() 函数则创建一个等待时间,等待用户按键,这样可以让程序在按下 ‘q’ 键之前持续运行。
4.1.2 背景模型的建立和更新
接下来,我们需要建立一个背景模型,以便后续进行减除操作。 BackgroundSubtractorMOG2 类是OpenCV中用于背景减除的一个非常有用的类,它能够自动更新背景模型,并且适应场景中的背景变化。
import cv2
# 创建 BackgroundSubtractorMOG2 对象
backSub = cv2.createBackgroundSubtractorMOG2()
cap = cv2.VideoCapture('video.mp4')
while True:
ret, frame = cap.read()
if not ret:
break
# 应用背景减除算法
fgMask = backSub.apply(frame)
# 显示原视频帧和前景掩码
cv2.imshow('Frame', frame)
cv2.imshow('FG Mask', fgMask)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
在这段代码中, backSub.apply() 函数应用于每一帧,返回的 fgMask 就是前景掩码,其中前景像素会被标记为白色,背景像素会被标记为黑色。这样,视频中移动的物体就可以被检测出来。
4.2 背景减除的实际应用
4.2.1 实现动态目标的检测
动态目标检测是通过背景减除模型识别视频中移动物体的过程。这种技术在视频监控、交通流量统计、人机交互等领域中非常有用。在OpenCV中,通过 BackgroundSubtractorMOG2 类的 apply 方法,我们可以得到每一帧的前景掩码,从而实现动态目标的检测。
import cv2
# 创建 BackgroundSubtractorMOG2 对象
backSub = cv2.createBackgroundSubtractorMOG2()
cap = cv2.VideoCapture('video.mp4')
while True:
ret, frame = cap.read()
if not ret:
break
# 应用背景减除算法
fgMask = backSub.apply(frame)
# 获取轮廓信息
contours, _ = cv2.findContours(fgMask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if cv2.contourArea(contour) > 500: # 过滤掉较小的轮廓
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示原视频帧和检测到的目标
cv2.imshow('Frame', frame)
cv2.imshow('FG Mask', fgMask)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
在这个示例中,使用 cv2.findContours 函数从前景掩码中提取出轮廓信息。通过 cv2.contourArea 函数对轮廓面积进行过滤,只保留面积大于500的轮廓,这通常意味着检测到了一个较大的移动物体。然后使用 cv2.boundingRect 函数计算轮廓的边界框,并使用 cv2.rectangle 函数在原视频帧上绘制边界框,以此实现目标的检测。
4.2.2 实现动态目标的跟踪
在动态目标检测之后,通常还需要对检测到的目标进行跟踪。这可以通过多种方法实现,例如使用卡尔曼滤波器、光流法或者基于深度学习的目标跟踪技术。这里我们以简单的目标跟踪为例,展示如何在OpenCV中实现。
import cv2
# 创建 BackgroundSubtractorMOG2 对象
backSub = cv2.createBackgroundSubtractorMOG2()
cap = cv2.VideoCapture('video.mp4')
# 初始化变量
トラッキング対象 = None
トラックの座標 = None
while True:
ret, frame = cap.read()
if not ret:
break
fgMask = backSub.apply(frame)
contours, _ = cv2.findContours(fgMask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if cv2.contourArea(contour) > 500:
x, y, w, h = cv2.boundingRect(contour)
if notトラックの座標 orトラックの座標[0] != x orトラックの座標[1] != y:
トラックの座標 = (x, y)
トラッキング対象 = contour
# 在检测到新的目标后,在下一帧中进行跟踪
ifトラックの座標:
x, y =トラックの座標
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 目标跟踪逻辑
# ...
cv2.imshow('Frame', frame)
cv2.imshow('FG Mask', fgMask)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
在这段代码中,我们跟踪了视频中最大的移动物体,并在每一帧中绘制了边界框。实际应用中,可以利用 トラッキング対象 变量中的轮廓信息来进一步跟踪目标的移动,例如通过跟踪质心位置的变化来实现。对于复杂的跟踪任务,可以考虑使用专门的跟踪算法或者深度学习模型。
5. 关键参数调整技巧和动态目标检测
5.1 关键参数的调整和优化
5.1.1 参数调整的原则和方法
在使用BackgroundSubtractorMOG2算法时,正确地调整参数对于实现高质量的背景减除至关重要。关键参数的调整应该遵循以下原则和方法:
-
最小和最大历史帧数 :这些参数决定了算法用于建立背景模型的历史帧数。最小历史帧数过低可能导致背景模型不够稳定,而最大历史帧数过高可能导致对动态背景的适应性差。通常情况下,最小历史帧数设置为50,最大历史帧数设置为150。
-
阴影检测 :MOG2算法可以通过设置阴影检测参数来区分阴影和前景目标。设置阴影检测参数为
true可以减少误检,但可能会增加计算复杂度。 -
学习速率 :这个参数决定了背景模型更新的速度。学习速率高,背景模型更新快;但过高的学习速率可能导致背景模型对实际背景的拟合不好。
参数的调整通常需要多次试验和错误。在实际应用中,根据视频的具体环境和动态目标的特性来调整参数是非常重要的。
5.1.2 参数优化的实例和效果
下面是一个参数调整的示例代码,用于展示如何在OpenCV中使用MOG2算法并进行参数调整:
import cv2
# 创建MOG2背景减除器实例
backSub = cv2.createBackgroundSubtractorMOG2(history=100, varThreshold=30, detectShadows=True)
# 打开视频文件
cap = cv2.VideoCapture('path_to_video.mp4')
while True:
ret, frame = cap.read()
if not ret:
break
# 应用背景减除
fgMask = backSub.apply(frame)
# 使用一些形态学操作来改进前景掩膜
fgMask = cv2.medianBlur(fgMask, 5)
# 显示结果
cv2.imshow('Frame', frame)
cv2.imshow('FG Mask', fgMask)
key = cv2.waitKey(30)
if key == 27: # 按下ESC键退出
break
cap.release()
cv2.destroyAllWindows()
在这个例子中, history 参数被设置为100,表示历史帧的最大数量。 varThreshold 参数被设置为30,这是一个控制更新阈值的参数,用于决定哪些像素被认为是前景。 detectShadows 设置为 True ,表示算法将尝试检测并标记阴影。
5.2 动态目标的检测和处理
5.2.1 动态目标检测的原理和方法
动态目标检测是计算机视觉领域的一个基础任务,它涉及到从图像序列中识别出移动的物体。在背景减除技术中,动态目标检测的基本原理是通过背景模型和当前帧之间的差异来确定前景物体的位置。检测方法主要包括:
- 阈值处理 :通过对背景减除得到的前景掩膜应用阈值处理,可以更好地分离出目标物体。
- 形态学处理 :使用形态学操作(如开运算和闭运算)可以去除噪点和填补目标内部的小空洞,提高目标的连通性。
- 轮廓检测 :通过寻找前景掩膜中连通区域的轮廓,可以提取出独立的目标物体。
5.2.2 动态目标处理的实例和效果
以下是一个动态目标处理的示例,它展示了如何使用OpenCV对检测到的动态目标进行进一步的处理:
# 继续使用上一段代码的环境
# 寻找前景掩膜中的轮廓
contours, _ = cv2.findContours(fgMask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
# 计算轮廓的边界框
(x, y, w, h) = cv2.boundingRect(contour)
# 绘制边界框
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示处理后的视频帧
cv2.imshow('Frame with Bounding Boxes', frame)
# 等待用户按键操作,结束程序
cv2.waitKey(0)
在这个代码片段中,我们通过 cv2.findContours 函数来寻找前景掩膜中的轮廓,并对每个轮廓计算边界框,然后在原始视频帧上绘制这些边界框。这可以帮助我们可视化视频中检测到的动态目标。
请注意,示例代码中没有涉及所有可能的参数调整和动态目标处理方法,实际应用时可能需要更复杂的技术和算法来优化结果。
简介:背景减除法用于检测视频监控中的动态目标,OpenCV提供了多种算法,其中BackgroundSubtractorMOG2是基于自适应混合高斯模型的常用算法。本文介绍该算法的原理和在Visual Studio中使用OpenCV3库的实现步骤,包括关键参数的调整,以帮助开发者在不同场景下实现最佳的动态目标检测效果。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)