微软:基于特征树合成LLM代码数据集
如何生成多样且复杂的代码指令数据,以提升大语言模型(LLM)在代码理解和生成任务中的性能?论文提出了一个基于特征树的代码合成框架,能够生成多样且复杂的指令数据,并训练了EpiCoder模型,该模型在多个函数级和文件级代码生成基准测试中达到了同类模型中的最先进性能。

📖标题:EpiCoder: Encompassing Diversity and Complexity in Code Generation
🌐来源:arXiv, 2501.04694
🌟摘要
🔸有效的指令调优对于优化代码LLM、使模型行为与用户期望保持一致以及提高现实世界应用程序中的模型性能是必不可少的。然而,大多数现有方法都集中在代码片段上,这些代码片段仅限于特定的功能和刚性结构,限制了合成数据的复杂性和多样性。
🔸为了解决这些局限性,我们引入了一种受抽象语法树(AST)启发的基于特征树的合成框架。与捕获代码句法结构的AST不同,我们的框架对代码元素之间的语义关系进行建模,从而生成更细微和多样化的数据。特征树由原始数据构建,并迭代细化,以增加提取特征的数量和多样性。这个过程可以识别代码中更复杂的模式和关系。通过对深度和广度可控的子树进行采样,我们的框架允许对生成代码的复杂性进行精确调整,支持从简单的函数级操作到复杂的多文件场景的各种任务。
🔸我们对广泛使用的基础模型进行了微调,以创建EpiCoder系列,在多个基准测试中在功能和文件级别实现了最先进的性能。值得注意的是,实证证据表明,我们的方法在合成高度复杂的存储库级代码数据方面显示出巨大的潜力。进一步的分析通过软件工程原理和LLM作为判断方法严格评估数据复杂性和多样性,阐明了这种方法的优点。
🛎️文章简介
🔸研究问题:如何生成多样且复杂的代码指令数据,以提升大语言模型(LLM)在代码理解和生成任务中的性能?
🔸主要贡献:论文提出了一个基于特征树的代码合成框架,能够生成多样且复杂的指令数据,并训练了EpiCoder模型,该模型在多个函数级和文件级代码生成基准测试中达到了同类模型中的最先进性能。
📝重点思路
🔸特征树提取:从种子数据中提取特征,并使用层次聚类生成树结构,捕捉代码元素之间的语义关系。
🔸特征树演化:通过迭代扩展特征树的深度和广度,增强数据的多样性和覆盖范围。
🔸基于特征树的代码生成:利用演化后的特征树生成具有不同复杂度的代码指令数据,通过调整子树的深度和广度来控制生成数据的复杂度。
🔸数据合成与模型训练:合成了433k条指令数据,并训练了EpiCoder系列模型,包括Qwen2.5-Coder-7B-Base和DeepSeek-Coder-6.7B-Base。
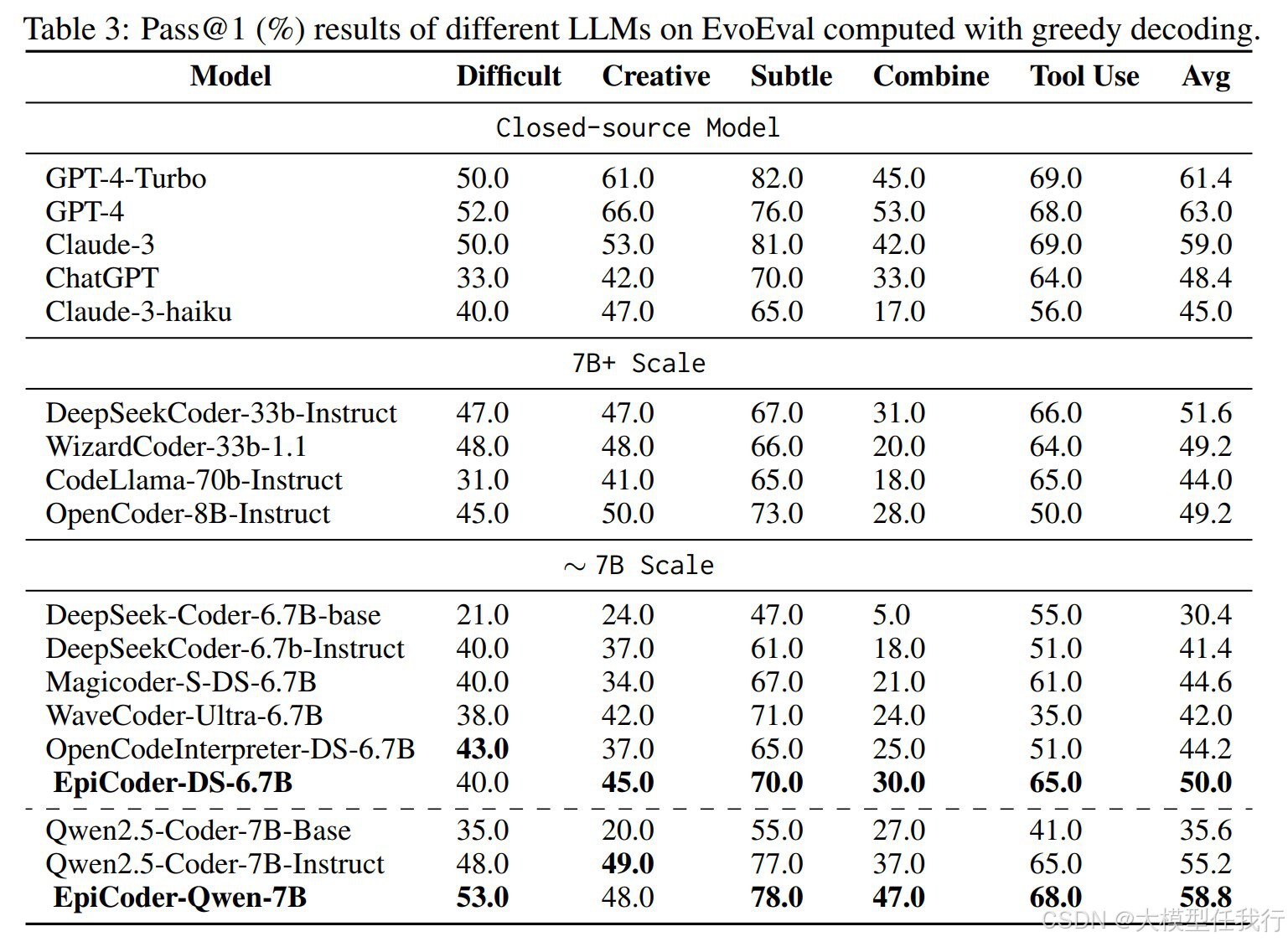
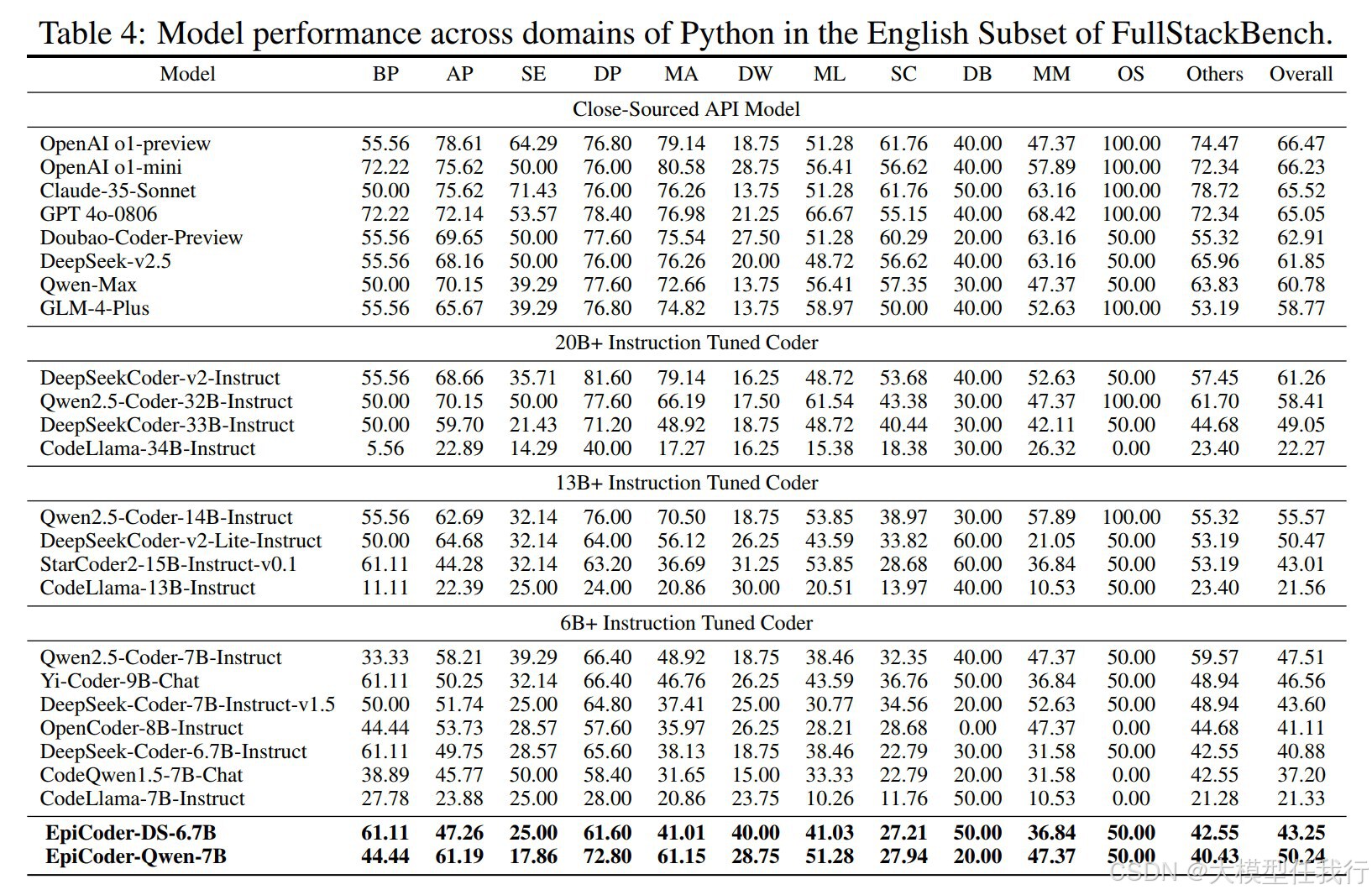
🔸实验验证:在多个函数级和文件级基准测试中验证了模型的性能,并展示了模型在处理复杂编程问题上的能力。
🔎分析总结
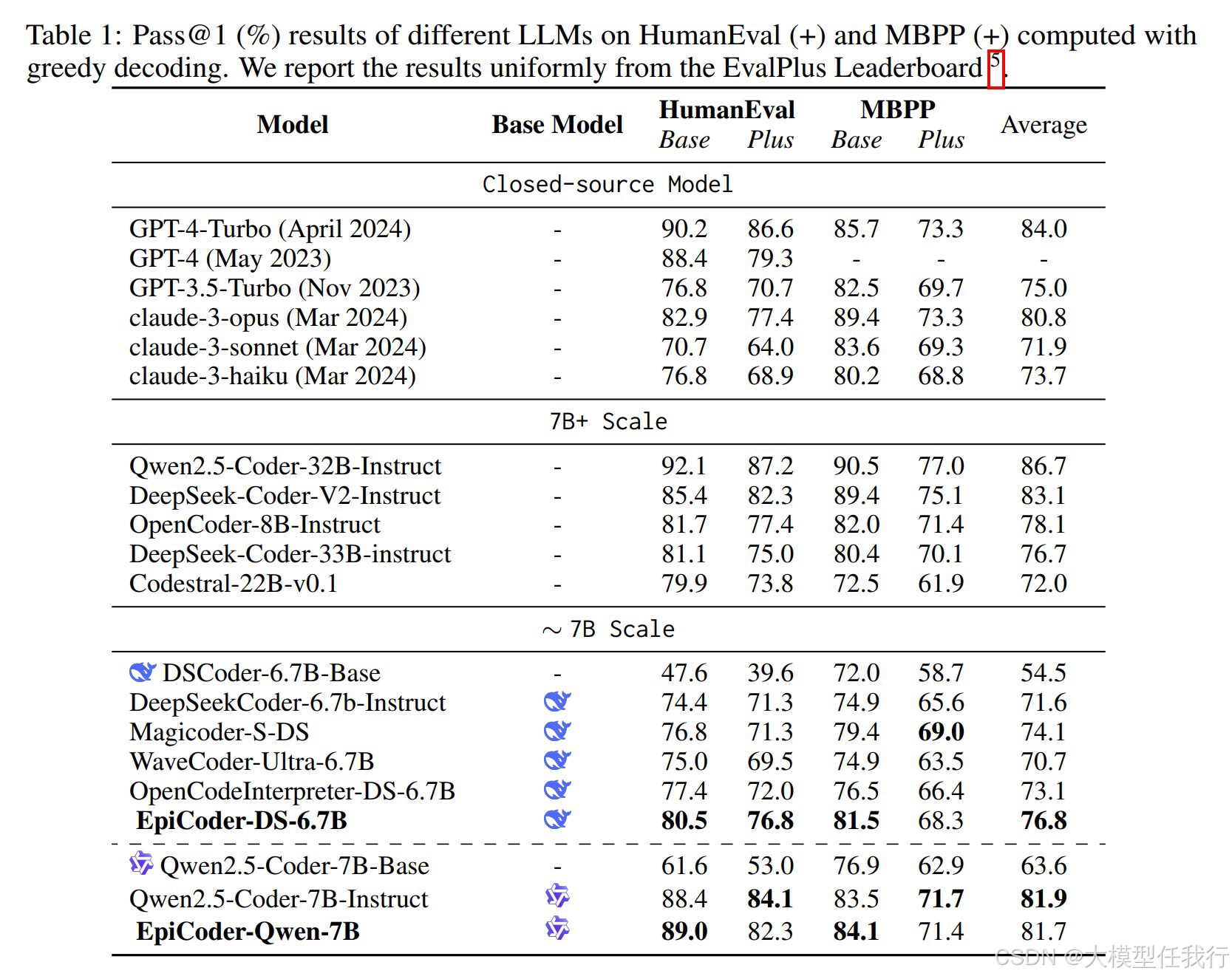
🔸函数级代码生成:EpiCoder-Qwen-7B在五个函数级代码生成基准测试中达到了同类模型中的最先进平均性能,展示了其在处理高复杂度编程场景中的能力。
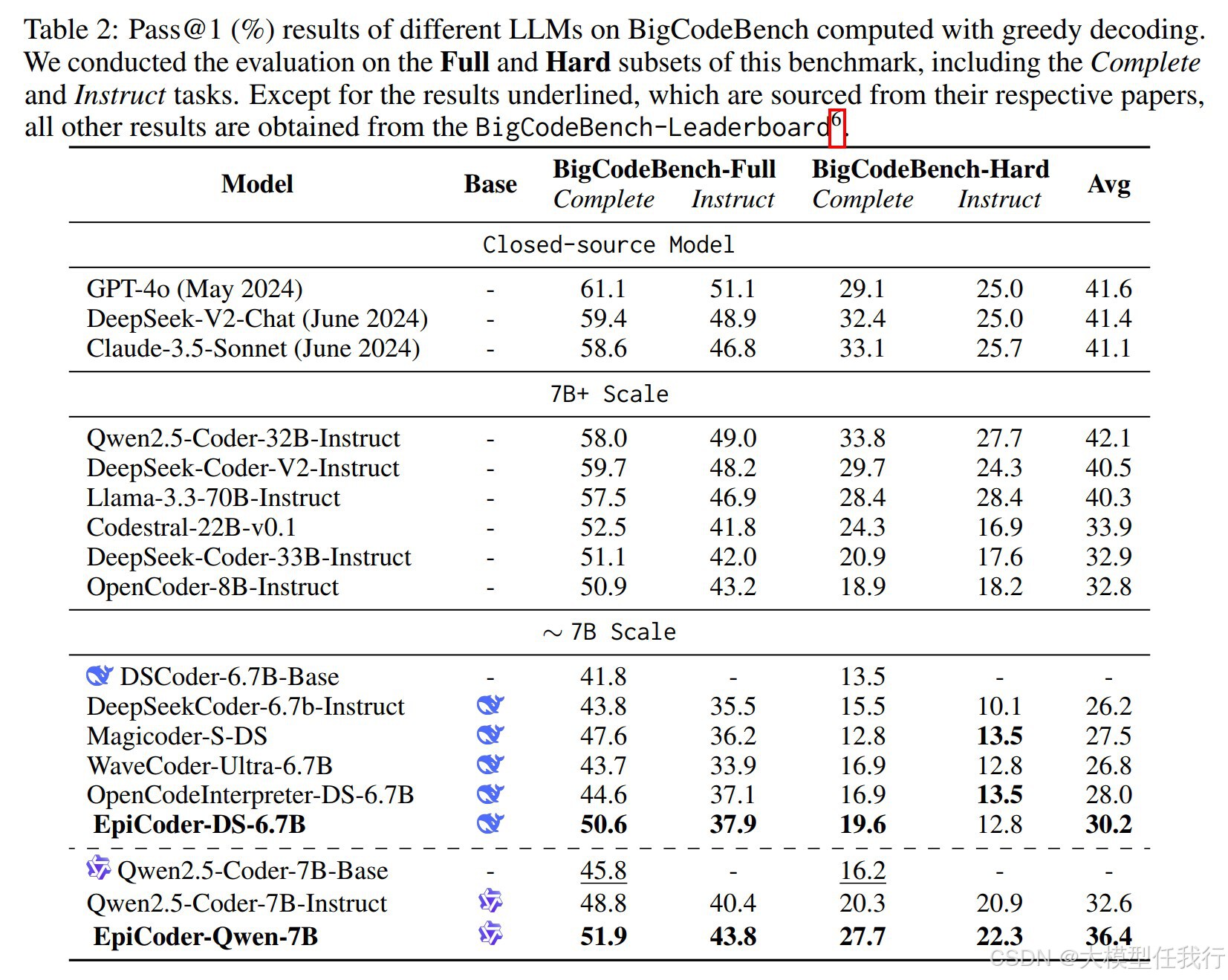
🔸文件级代码生成:在XFileDep基准测试中,使用多文件数据训练的LLM表现出优越的性能,证明了其在处理跨文件依赖问题上的能力。
🔸数据多样性与复杂性:通过特征树的方法,生成的代码数据在多样性和复杂性上具有显著优势,能够更好地模拟真实世界的编程场景。
🔸潜在的大规模代码库生成:该方法展示了在生成复杂代码库数据方面的潜力,能够生成包含超过50个文件的代码库。
💡个人观点
论文的核心在于将代码内在的特征以树结构存储,并通过树的演化来合成复杂代码指令。
🧩附录



火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献305条内容
已为社区贡献305条内容

所有评论(0)