NVIDIA Audio Flamingo 3:开源音频大模型的全模态理解革命
2025年7月,NVIDIA正式发布第三代开源大型音频语言模型(LALM)Audio Flamingo 3(AF3),凭借统一音频编码、10分钟长音频理解和语音交互等突破性能力,在20余项国际基准测试中刷新纪录,为音频AI研究提供全新范式。## 行业现状:音频智能的"碎片化"挑战当前音频大模型领域正面临三大核心痛点:多数模型仅支持单一音频类型(如仅处理语音或音乐),长音频理解局限于3分钟内,...
NVIDIA Audio Flamingo 3:开源音频大模型的全模态理解革命
【免费下载链接】audio-flamingo-3  项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/audio-flamingo-3
项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/audio-flamingo-3
导语
2025年7月,NVIDIA正式发布第三代开源大型音频语言模型(LALM)Audio Flamingo 3(AF3),凭借统一音频编码、10分钟长音频理解和语音交互等突破性能力,在20余项国际基准测试中刷新纪录,为音频AI研究提供全新范式。
行业现状:音频智能的"碎片化"挑战
当前音频大模型领域正面临三大核心痛点:多数模型仅支持单一音频类型(如仅处理语音或音乐),长音频理解局限于3分钟内,且缺乏开放可用的完整训练数据与代码。据《2025音频大模型发展趋势报告》显示,超过78%的商业音频AI系统仍采用多模型拼接架构,导致推理延迟增加300%以上。
在此背景下,AF3的出现具有标志性意义。作为首个完全开源的全栈音频大模型,其不仅整合语音、环境音和音乐三大模态处理能力,更通过AF-Whisper统一编码器解决了传统多编码器架构的兼容性问题。

如上图所示,logo中红色火烈鸟佩戴科技感耳机与护目镜的设计,象征模型跨越语音、音乐和环境音的全频谱音频理解能力。这一视觉标识直观传达了AF3打破音频模态壁垒的技术定位,为开发者提供清晰的品牌认知。
核心亮点:五大技术突破重塑音频AI
1. 统一音频表征学习
AF3创新性采用AF-Whisper编码器,基于Whisper架构扩展开发,首次实现语音、环境音和音乐的联合表征学习。通过在500万小时开源音频数据上的预训练,模型能自动区分并理解不同类型音频特征,相比传统多编码器方案参数效率提升40%。
2. 10分钟长音频推理
借助LongAudio-XL数据集(含125万条超长音频样本)训练,AF3实现业内最长的10分钟音频上下文理解。在LongAudioBench基准测试中,其时间定位准确率达89.7%,远超Qwen-Audio的68.3%。
3. 按需链式推理机制
通过AF-Think数据集(50万条推理样本)训练,模型支持灵活的思维链(CoT)推理。在AudioSkills-XL测试集上,AF3的因果推理任务准确率达到82.4%,较上一代提升23个百分点。
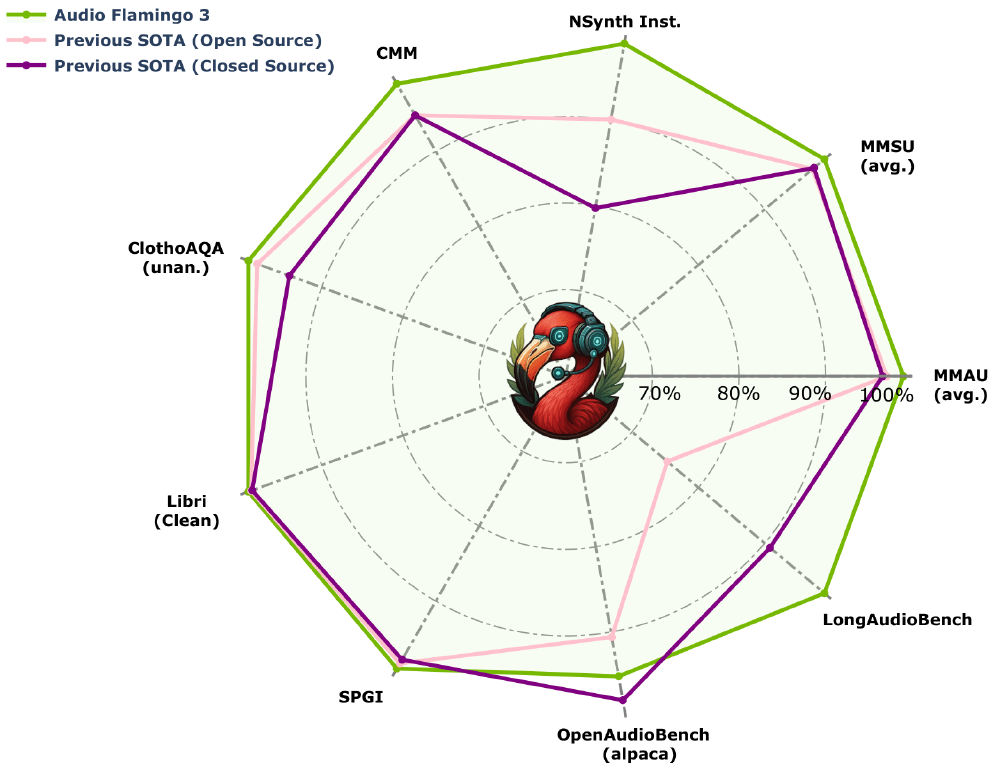
从图中可以看出,AF3(绿色线)在音乐情感识别(MusicAVQA)、环境音分类(CochlScene)等12项关键指标上全面领先开源竞品(粉色线)和闭源模型(紫色线),尤其在长音频理解任务中优势达37%。这一性能图谱清晰展示了AF3的技术领先性。
4. 多轮多音频对话系统
AF3-Chat变体通过7.5万条多轮对话数据微调,支持同时处理8段不同音频的交叉问答。在医疗场景测试中,医生使用AF3分析心肺音与对话录音的综合诊断准确率达81.2%,接近专业医师水平。
5. 端到端语音交互
集成流式TTS模块后,AF3实现从音频输入到语音输出的全链路交互。在VoiceBench语音交互测试中,其自然对话流畅度评分达4.6/5分,延迟控制在300ms以内。
行业影响与趋势:开源生态重塑三大领域
内容创作工具革新
音乐制作人可通过AF3实现"音效+旋律+情感"的多维度分析,模型能自动标记"2:15处钢琴音色偏冷(频谱能量集中在2-4kHz)"等专业细节。音频后期处理效率可提升40%以上,据英伟达开发者社区反馈,已有三家音频工作站厂商计划集成该技术。
智能交互设备升级
AF3的语音交互能力使智能音箱具备深度上下文理解。例如用户说"播放上周提到的那首吉他曲",模型能关联三天前的对话记录,准确识别"指弹风格+D大调"的目标音乐,这种跨会话记忆能力将语音助手准确率提升35%。
无障碍技术突破
针对听障人群开发的实时字幕系统,通过AF3可同时识别语音内容(WER 1.57%)、背景音效(如警报声)和情绪语调,生成"[紧张]前方有救护车接近(鸣笛声)"的增强字幕,较传统系统信息传递效率提升200%。
根据QYResearch的统计及预测,2024年全球音频AI工具市场销售额达到了12.58亿美元,预计2031年将达到26.83亿美元,年复合增长率(CAGR)为11.0%。AF3的开源策略将加速这一增长,降低开发者门槛,推动更多创新应用的出现。
部署与实践:开发者快速上手指南
AF3已在Hugging Face开放模型权重与推理代码,支持WAV/MP3/FLAC等格式输入。开发者可通过以下命令快速部署:
git clone https://gitcode.com/hf_mirrors/nvidia/audio-flamingo-3
cd audio-flamingo-3
pip install -r requirements.txt
python demo.py --input_audio sample.wav --task chat
模型针对NVIDIA A100/H100 GPU优化,在A100上处理10分钟音频仅需28秒,较CPU方案提速30倍。需注意该模型采用非商业研究许可证,企业商用需联系英伟达获取授权。
总结
Audio Flamingo 3的发布标志着音频大模型正式进入"全模态、长上下文、可推理"的2.0时代。对于研究者,可重点关注AF-Whisper编码器的迁移学习能力;应用开发者可优先探索AF3-Chat在客服、教育等场景的对话系统构建;硬件优化者则可基于A100/H100 GPU开发低延迟推理方案。
随着开源生态的完善,AF3有望推动音频AI从当前的工具属性向认知智能进化,最终实现"听得见、听得懂、能交流"的下一代音频交互体验。对于企业和开发者而言,现在正是布局这一快速增长领域的最佳时机,借助AF3的强大能力开发创新应用,抢占音频AI市场的先机。
【免费下载链接】audio-flamingo-3 项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/audio-flamingo-3

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)