手写MNIST数字识别 底层实现
这篇文章从零开始实现了一个MNIST手写数字识别的神经网络模型。首先介绍了分类问题中使用的softmax函数及其数值稳定性改进方法,然后详细讲解了神经网络的结构设计,包括卷积层、ReLU激活函数、池化层和全连接层的作用原理。文章提供了完整的代码实现,包括数据预处理、网络结构定义和可视化展示MNIST数据集。通过实例说明了如何构建一个包含两层卷积和全连接层的CNN模型,并解释了各层参数设置的原因。最
mnist已经写了很多遍了,这次再全部从零底层实现一遍,顺便附上具体原理
数字识别就是个分类问题,神经网络可以用于回归任务和分类任务,回归问题用恒等函数,分类问题用softmax函数。
什么是softmax函数:
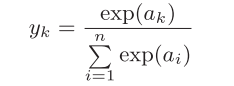
这个函数就是,我们代码实现
def softmax(x):
"""
计算softmax函数
"""
return np.exp(x) / np.sum(np.exp(x), axis=0)
正常输出
print(softmax(np.array([1, 2, 3])))
[0.09003057 0.24472847 0.66524096]
print(softmax(np.array([1010, 2000, 3000])))
我们试一试大数运行函数输出
[nan nan nan]
上面的softmax函数的实现虽然正确描述了式子,但在计算机的运算
上有一定的缺陷。这个缺陷就是溢出问题。softmax函数的实现中要进行指
数函数的运算,但是此时指数函数的值很容易变得非常大。比如,e^10的值
会超过20000,e^100会变成一个后面有40多个0的超大值,
e^1000的结果会返回一个表示无穷大的inf。如果在这些超大值之间进行除法运算,结果会出现“不确定”的情况
我们可以改进函数,通过减去输入信号中的最大值(上例中的c),我们发现原
本为nan(not a number,不确定)的地方,现在被正确计算了。
def softmax(x):
"""
计算softmax函数,解决溢出问题
"""
x = x - np.max(x)
exp_x = np.exp(x)
return exp_x / np.sum(exp_x)
print(softmax(np.array([1010, 1000, 990])))
最终得到正常结果
[9.99954600e-01 4.53978686e-05 2.06106005e-09]
softmax函数的输出是0.0到1.0之间的实数。并且,softmax
函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正
因为有了这个性质,我们才可以把softmax函数的输出解释为‘概率’
输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输
出层的神经元数量一般设定为类别的数量。比如,对于某个输入图像,预测
是图中的数字0到9中的哪一个的问题(10类别分类问题),
所以我们将输出层的神经元设定为10个
介绍完神经网络的结构之后,现在我们来试着解决实际问题。这里我们
来进行手写数字图像的分类。假设学习已经全部结束,我们使用学习到的参
数,先实现神经网络的“推理处理”。这个推理处理也称为神经网络的前向
传播(forward propagation)。
MNIST数据集
这里使用的数据集是MNIST手写数字图像集。MNIST是机器学习领域
最有名的数据集之一,被应用于从简单的实验到发表的论文研究等各种场合。
实际上,在阅读图像识别或机器学习的论文时,MNIST数据集经常作为实
验用的数据出现。
MNIST数据集是由0到9的数字图像构成的。训练图像有6万张,
测试图像有1万张,这些图像可以用于学习和推理。MNIST数据集的一般
使用方法是,先用训练图像进行学习,再用学习到的模型度量能在多大程度
上对测试图像进行正确的分类
NIST的图像数据是28像素 × 28像素的灰度图像(1通道),各个像素
的取值在0到255之间。每个图像数据都相应地标有“7”“2”“1”等标签
了解上面的知识差不多可以直接手写实现了
代码实现
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 数据预处理:归一化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载训练集和测试集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 加载训练集和测试集的DataLoader,每次加载64个样本,train_loader的shuffle参数设为True表示每次迭代时都打乱数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
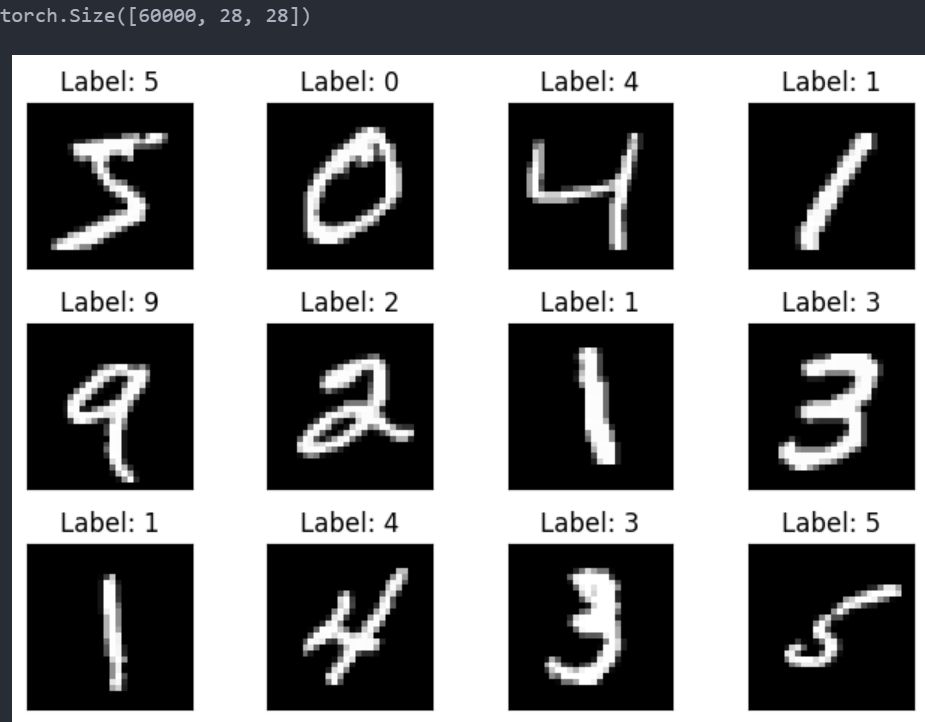
展示MNIST数据集
# 查看shape和图片
from matplotlib import pyplot as plt
print(train_dataset.train_data.shape)
fig=plt.figure()
for i in range(12):
# 创建一个 3×4 的网格,共 12 个子图
plt.subplot(3,4,i+1)
# 自动调整子图之间的间距和边距
plt.tight_layout()
# 显示图片 ,'gray' 表示灰度图
plt.imshow(train_dataset.train_data[i], cmap='gray')
# 不显示x,y刻度
plt.xticks([])
plt.yticks([])
# 设置标题
plt.title(f'Label: {train_dataset.train_labels[i]}')
# 显示图片
plt.show()
定义神经网络
了解这个神经网络的组成
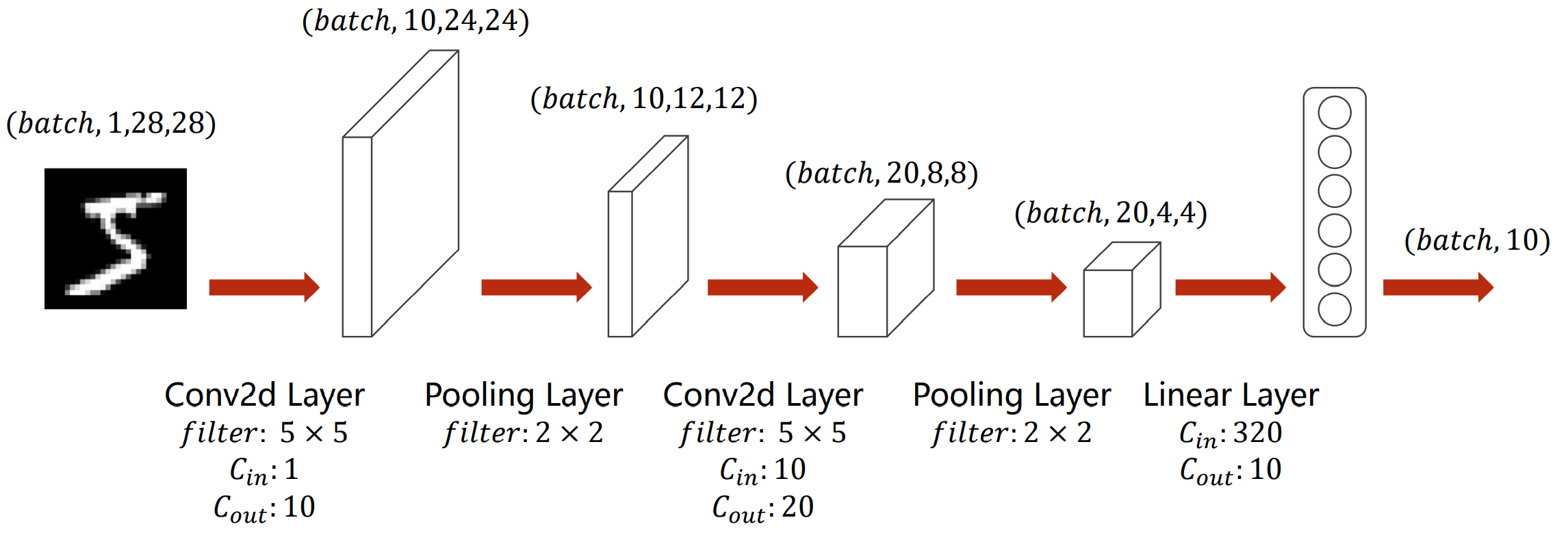
1.首先用到了一个二维卷积层,卷积原理如图
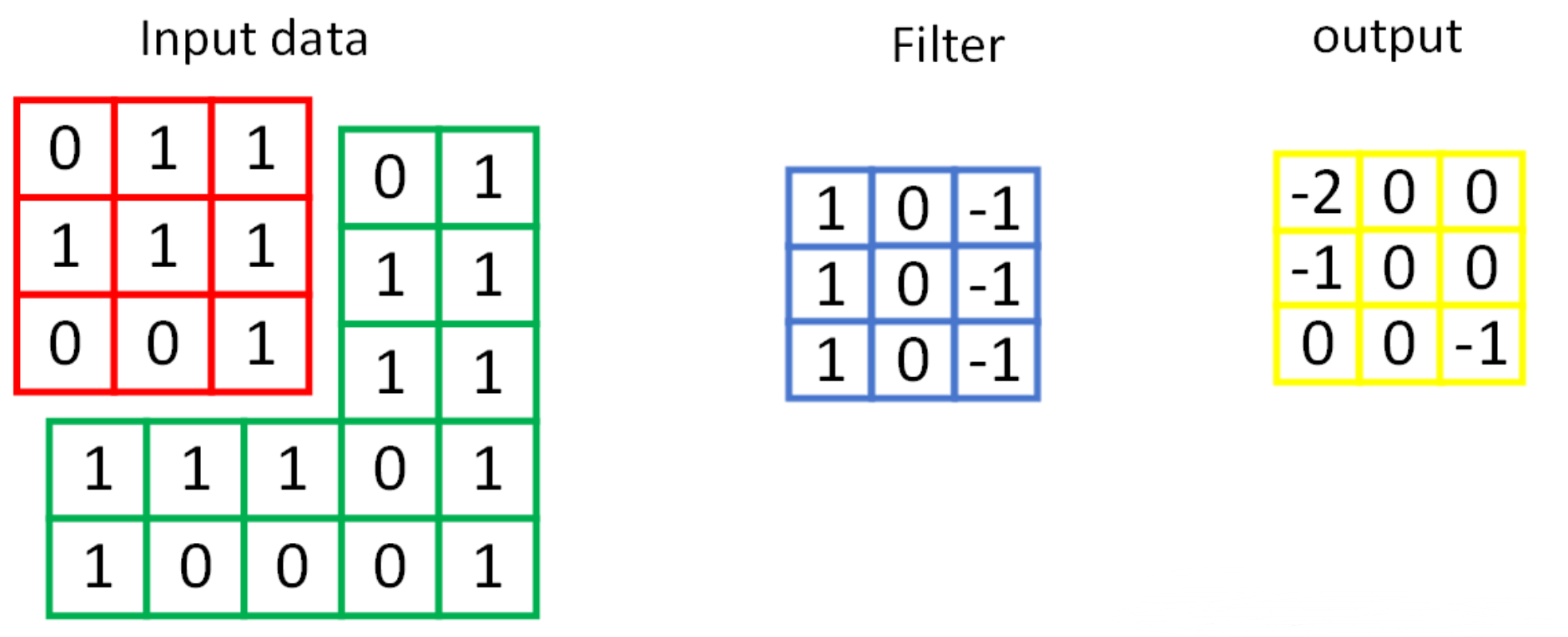
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
参数:in_channels:输入通道out_channels:输出通道kernel_size:卷积核大小stride:步长padding:填充
2.激活层使用ReLU激活函数。
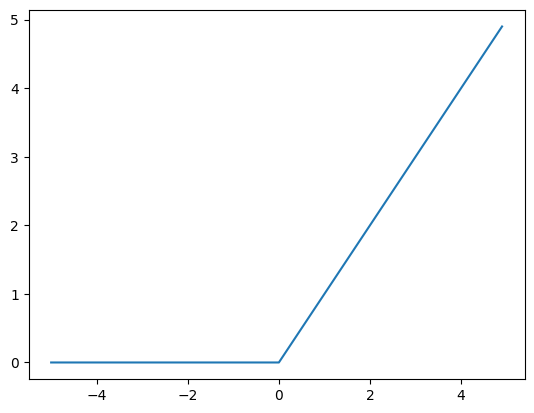
torch.nn.ReLU()
要手动实现也是很简单
def ReLU(x):
return np.maximum(0, x)
3 池化层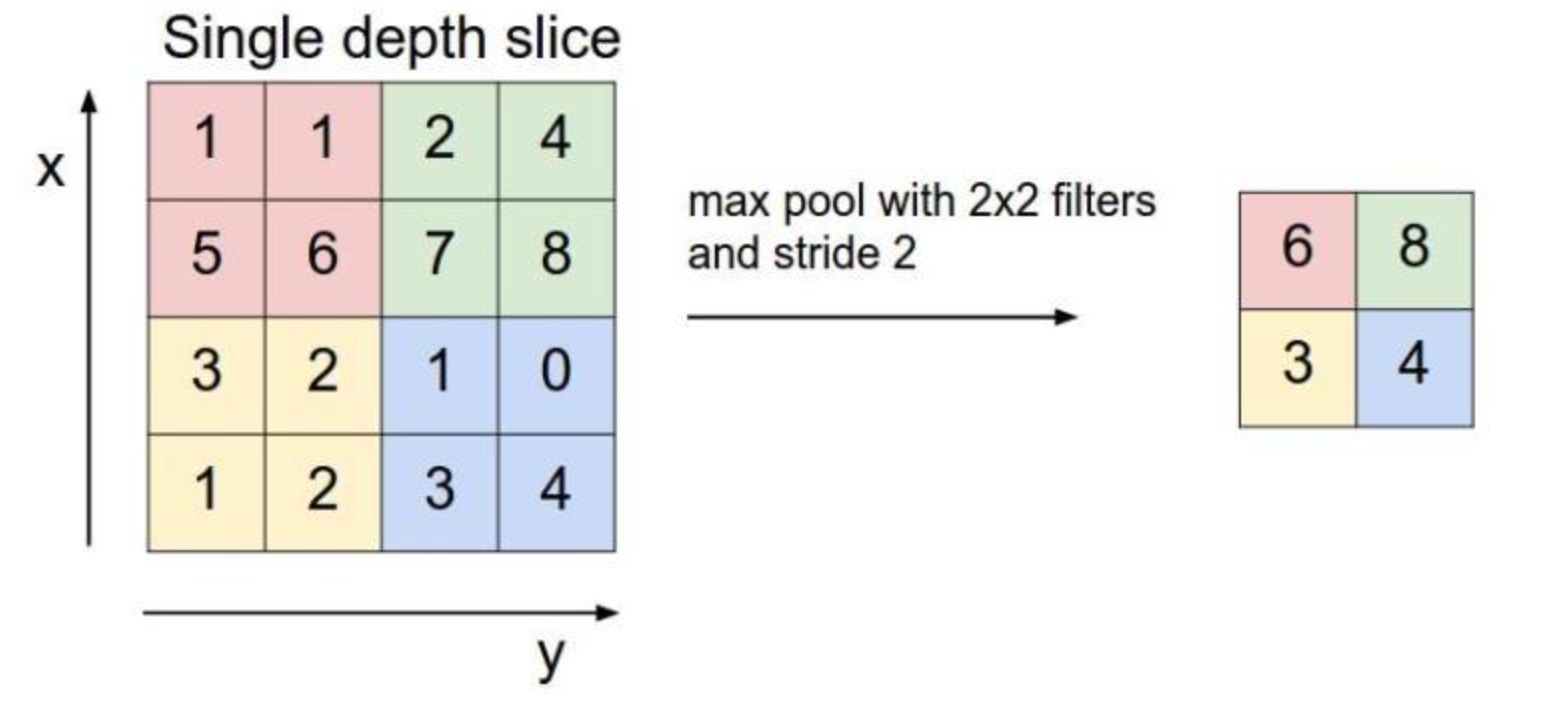
池化原理
torch.nn.MaxPool2d(input, kernel_size, stride, padding)
这些参数上文已经说明
4 全连接层
self.fc1 = nn.Linear(64 * 7 * 7, 128)self.fc2 = nn.Linear(128, 10)
作用
维度转换:从空间特征到分类决策
输入处理:
卷积层输出的四维张量 (B, C, W, H)(批大小、通道数、宽、高)通过 view 或 flatten 操作被展平为二维张量 (B, CWH),即将空间和通道信息合并为一维特征向量。
例如:若卷积层输出为 (64, 128, 7, 7),展平后为 (64, 128 * 7 * 7=6272)。
输出映射:
全连接层通过权重矩阵将高维特征映射到目标维度(如分类类别数)。例如,输入 6272 维特征可通过全连接层输出 (64, 10)(10分类任务)。
好的,我们已经了解了大概的结构组成
接下来我们根据结构图来实现代码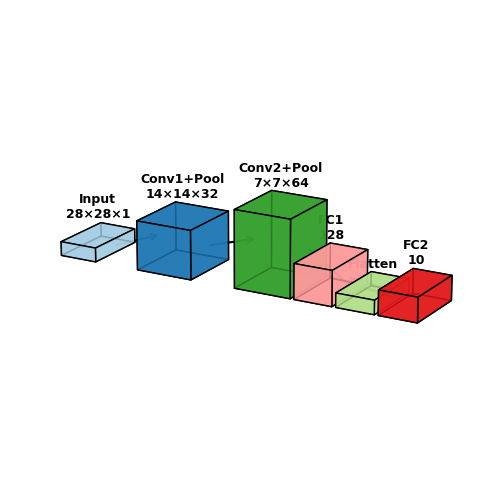
神经网络的代码实现
import torch.nn as nn
import torch.nn.functional as F
# 定义一个简单的卷积神经网络(CNN),用于图像分类
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 第一层卷积:输入通道 1(灰度图),输出通道 32,卷积核大小 5x5,padding=2 保持尺寸不变
self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)
# 第二层卷积:输入通道 32,输出通道 64,卷积核大小 5x5,同样 padding=2
self.conv2 = nn.Conv2d(32, 64, kernel_size=5, padding=2)
# 最大池化层,窗口大小 2x2,相当于下采样一半
self.pool = nn.MaxPool2d(2)
# 全连接层 1:输入 64*7*7 个特征,输出 128 个神经元
self.fc1 = nn.Linear(64 * 7 * 7, 128)
# 全连接层 2:输入 128,输出 10(对应 10 个类别,比如 MNIST)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 第一次卷积 -> ReLU 激活 -> 池化
x = F.relu(self.pool(self.conv1(x)))
# 第二次卷积 -> ReLU 激活 -> 池化
x = F.relu(self.pool(self.conv2(x)))
# 将特征图展平成一维向量,方便送入全连接层
x = x.view(-1, 64 * 7 * 7) # -1 表示自动计算 batch size
# 第一个全连接层 + ReLU
x = F.relu(self.fc1(x))
# 第二个全连接层,输出 10 类
x = self.fc2(x)
return x
# 实例化模型
model = CNN()
定义损失函数和优化器
使用交叉熵损失函数和Adam优化器:
import torch.optim as optim
# 交叉熵损失函数用于分类问题
criterion = nn.CrossEntropyLoss()
# Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
- 模型训练
定义训练过程:
from tqdm import tqdm # 用于显示进度条
def train_model(model, train_loader, optimizer, criterion, epochs=10):
"""
训练模型函数
参数:
model: 神经网络模型
train_loader: 训练数据 DataLoader
optimizer: 优化器 (如 Adam, SGD)
criterion: 损失函数 (如 CrossEntropyLoss)
epochs: 训练轮数
"""
model.train() # 设置为训练模式(启用 dropout、BN 等)
for epoch in range(epochs): # 外层循环:共训练 epochs 轮
running_loss = 0.0 # 记录一个 epoch 内的累计 loss
# tqdm 用于显示进度条,每个 batch 迭代时会实时刷新
progress_bar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{epochs}", leave=False)
for images, labels in progress_bar:
# 梯度清零(防止梯度累积)
optimizer.zero_grad()
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 累加损失,用于 epoch 统计
running_loss += loss.item()
# tqdm 实时显示当前 batch 的 loss
progress_bar.set_postfix({"Batch Loss": f"{loss.item():.4f}"})
# 一个 epoch 结束后,计算平均损失
avg_loss = running_loss / len(train_loader)
print(f"Epoch [{epoch+1}/{epochs}] - Average Loss: {avg_loss:.4f}")
- 模型测试
定义测试过程并计算准确率:
def test_model(model, test_loader):
"""
测试模型函数
参数:
model: 已训练好的神经网络模型
test_loader: 测试数据 DataLoader
"""
model.eval() # 设置为评估模式(关闭 dropout、BN 等)
correct = 0 # 预测正确的样本数
total = 0 # 总样本数
# 测试时不需要计算梯度,节省显存和加速
with torch.no_grad():
# tqdm 进度条显示测试进度
for images, labels in tqdm(test_loader, desc="Testing", leave=False):
# 前向传播
outputs = model(images)
# 取概率最大的类别作为预测结果
_, predicted = torch.max(outputs.data, 1)
# 累加总数和正确数
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算总体准确率
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
- 开始训练与测试
运行训练和测试:
if __name__ == "__main__":
train_model(model, train_loader,optimizer,criterion,epochs=10)
test_model(model, test_loader)
输出
Epoch [1/10] - Average Loss: 0.0391
Epoch [2/10] - Average Loss: 0.0239
Epoch [3/10] - Average Loss: 0.0176
Epoch [4/10] - Average Loss: 0.0134
Epoch [5/10] - Average Loss: 0.0105
Epoch [6/10] - Average Loss: 0.0102
Epoch [7/10] - Average Loss: 0.0085
Epoch [8/10] - Average Loss: 0.0069
Epoch [9/10] - Average Loss: 0.0058
Epoch [10/10] - Average Loss: 0.0084
Test Accuracy: 99.19%
进行预测
import torch
from torchvision import transforms
from PIL import Image
def predict_image(model, image_path, class_names, transform=None, device="cpu"):
model.eval() # 评估模式
model.to(device) # 移动到指定设备
# 打开图片
image = Image.open(image_path).convert("L") # 转灰度 (1 通道),如果是彩色就改成 "RGB"
# 预处理
if transform is not None:
image = transform(image)
else:
# 默认 transform: 转 tensor + 标准化
image = transforms.ToTensor()(image)
# 增加 batch 维度: [1, C, H, W]
image = image.unsqueeze(0).to(device)
with torch.no_grad():
# 输出预测结果 tensor
outputs = model(image)
# softmax 归一化
probs = torch.softmax(outputs, dim=1).cpu().numpy() # 转成 NumPy
print(f"Probabilities: {probs.round(3)}") # 打印并保留3位小数
_, predicted = torch.max(outputs, 1) # 获取预测类别索引
predicted_class = class_names[predicted.item()]
print(f"Predicted Class: {predicted_class}")
return predicted_class
# 定义类别
class_names = [str(i) for i in range(10)] # 如果是MNIST: 0~9
# 单张图片预测
predict_image(model, "../3.jpg", class_names, transform, device="cuda")
输出结果
Probabilities: [[0.001 0.047 0.027 0.831 0.002 0.049 0.002 0.026 0.009 0.006]]
Predicted Class: 3

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 48
48 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)