chatgpt模型详解系列--gpt1
chatgpt系列1--GPT-1
前言
2022年11月30日,OpenAI发布了一款具有多种能力的通用大模型ChatGPT,开启了人工智能新时代的序幕。ChatGPT不仅可以生成文本、回答问题、摘要、翻译,还可以与用户进行自然和流畅的对话,根据用户的输入创造出各种有趣和有创意的内容。
本文将深入浅出的介绍ChatGPT的技术原理,为读者揭开这一大模型的神秘面纱。
由于ChatGPT是基于Transformer,如果对Transformer不太了解,可以先阅读本账号先前的文章。本系列文章会从GPT-1 到GPT-4介绍gpt的演变历程,以及基本原理。点个关注不迷路。
一、GPT发展历史——从GPT-1到GPT-4
OpenAI GPT系列模型在短短五年内,不断地改进和创新,涉及模型结构、参数量、训练数据、优化技术等多个方面。表1-1展示了每个GPT模型的具体细节。
| 模型 | 参数量 | 主要改进 | 发布时间 |
|---|---|---|---|
| GPT-1 | 1.17亿 | 使用Transformer的解码器作为模型结构,使用标准语言模型作为预训练目标,使用预训练+微调的方式解决下游任务 | 2018年6月 |
| GPT-2 | 15亿 | 扩大了模型规模和训练数据,使用WebText数据集进行预训练,使用零样本或少样本学习来解决下游任务 | 2019年2月 |
| GPT-3 | 1750亿 | 进一步扩大了模型规模和训练数据,使用Common Crawl数据集进行预训练,使用不同规模的模型来适应不同复杂度的下游任务 | 2020年5月 |
| ChatGPT | 1750亿 | 在GPT-3.5的基础上,使用人类反馈强化学习训练,使用人类标注师撰写的问答数据进行预训练,使用奖励模型来优化回答质量 | 2022年11月 |
| GPT-4 | 未知(官方未公布) | 进一步扩大了模型规模和训练数据,使用更高效的计算和通信优化技术,使用更多样化和多语言的数据源进行预训练 | 2023年3月 |
二、GPT-1技术原理
GPT-1 是一种生成式预训练语言模型,2018年6月由OpenAI 在Improving Language Understanding by Generative Pre-Training这篇论文中提出。该模型的训练分为两个阶段:第一阶段是无监督地用语言模型进行预训练,第二阶段是有监督地用微调的方法解决下游任务。GPT-1 在文本分类、文本蕴含、语义相似度、问答等多个下游任务上都有很好的表现,经过微调后的 GPT-1 系列模型的性能甚至超过了当时专门针对这些任务训练的最先进的模型。
2.1 GPT-1模型结构
GPT-1模型的结构是基于 Transformer 的解码器部分,它只使用了一种注意力机制,即掩码多头注意力。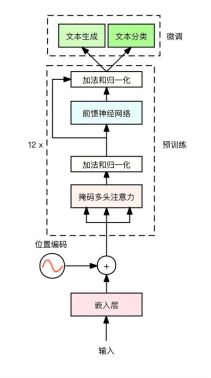
Transformer 是一种用于机器翻译的序列到序列模型,它由编码器和解码器两部分组成。编码器负责提取源语言的语义特征,解码器负责提取目标语言的语义特征,并生成对应的译文。GPT-1是一种用于单序列文本生成的模型,它只保留了Transformer 的解码器部分,而且只使用了掩码多头注意力这种机制。
GPT-1是一种基于Transformer解码器的模型,它使用了掩码多头注意力和前馈神经网络两种层,并且增加了网络的规模。它的层数从原来的6层增加到了12层,注意力的维度从原来的512增加到了768,注意力的头数从原来的8个增加到了12个,前馈层的隐层维度从原来的2048增加到了3072,总参数达到了1.5亿。
除了上面提到的,GPT-1和Transformer还有以下三点差异。
- GPT-1是一种单向的语言模型,它只利用上文来预测当前位置的值。为了实现这一点,GPT-1采用了掩码多头注意力,它可以屏蔽掉下文的信息。
- Transforme需要对输入的词嵌入加入位置嵌入,以便捕获文本的位置信息。Transformer使用了正弦和余弦函数来计算位置嵌入,而GPT-1则使用了一种不同的方法。GPT-1的位置嵌入是随机初始化的,并且可以在训练过程中进行更新,这使得它更像词向量。
- GPT-1的训练分为两个阶段:预训练和微调。在预训练阶段,GPT-1模型学习文本的语义向量;在微调阶段,GPT-1模型根据具体任务进行调整,以解决下游任务。
接下来,我们将具体介绍GPT-1的预训练和微调(Fine-tuning)过程。预训练是指在大规模的无标注文本上训练语言模型,以学习通用的语言知识。微调是指在特定的有标注数据上对预训练模型进行微调,以适应不同的下游任务,如文本分类、情感分析、问答等。
2.2 第一阶段:无监督预训练
GPT-1模型的预训练采用了标准的语言模型,即根据上文来预测当前的词。它的目标函数如下。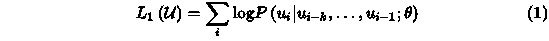
其中,k是窗口大小,θ是模型参数。
GPT-1模型由12个Transformer模块组成,每个Transformer模块只包含解码器中的掩码多头注意力和后面的前馈层,它们的计算公式如下所示。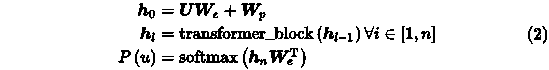
其中U=(u-k,…u-1) 是当前单词u的上文单词向量,We 是词向量矩阵(词的 Embedding 矩阵), Wp是 position embedding,n是 Transformer 层数。
2.3 第二阶段:有监督微调
为了适应下游任务,GPT-1模型需要对其网络结构进行一些修改,如下图的微调部分。假设有一个带有标签的数据集C,其中,词的序列为u1,u2,u3…标签为 y。词序列首先输入到预训练好的GPT-1模型中,经过最后一层Transformer后得到输出hl,然后输入到下游任务的线性层中,得到最终的预测输出,如下所示。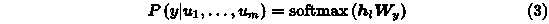
其中,Wy是线性层的参数。这时,目标函数为如下形式。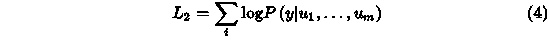
这个目标函数与预训练阶段的目标函数L1相结合,得到最终的目标函数。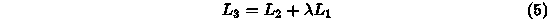
其中,λ是一个超参数,用来控制两个目标函数的权重。
为了适应GPT-1模型结构,不同的下游任务需要对输入进行一些转换,如下图所示。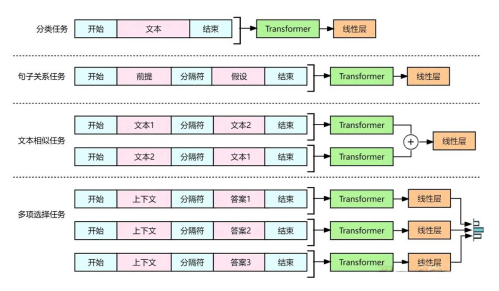
- 分类任务。我们只需要在输入序列的前后分别加上开始(Start)和结束(Extract)标记,表示这是一个分类任务的输入。
- 句子关系任务。我们除了需要加上开始和结束标记外,在两个句子之间还需要加上分隔符(Delim),表示这是一个句子关系任务的输入。
- 文本相似性任务。我们与句子关系任务类似,不过需要生成两个文本的表示,分别用开始和结束标记包围,然后用分隔符隔开,表示这是一个文本相似性任务的输入。
- 多项选择任务。我们可以把这个任务看作是文本相似性任务的扩展,只不过我们需要生成多个文本的表示,每个文本都用开始和结束标记包围,然后用分隔符隔开,表示这是一个多项选择任务的输入。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)