论文翻译DAMO-YOLO : A Report on Real-Time Object Detection Design DAMO-YOLO:实时物体检测设计报告
近年来,研究人员开发的物体检测方法取得了巨大进展[1,9,11,23,24,27,33]。当业界追求具有实时约束的高性能物体检测方法时,研究人员专注于设计具有高效网络架构[4,16,17,29,30]和高级训练阶段[10,17,21,26,31]的单阶段检测器[1,22 - 24,26]。特别是YOLOv5/6/7[18,32,34]、YOLOX[9]和PP-YOLOE[38]在COCO上实现了显
摘要
在本报告中,我们提出了一种快速准确的物体检测方法,称为DAMO-YOLO,它比最先进的YOLO系列具有更高的性能。DAMO-YOLO在YOLO的基础上扩展了一些新技术,包括神经结构搜索(NAS)、高效的Reparameterized Generalized-FPN (RepGFPN)、具有AlignedOTA标签分配的轻量级封头和蒸馏增强。在低延迟和高性能的约束下,我们利用最大熵原理指导的MAE-NAS方法来搜索我们的检测骨干,生成具有空间金字塔池和焦点模块的类ResNet /类CSP结构。在颈部和头部的设计上,我们遵循“大颈部,小头部”的原则。引入加速后融合的广义FPN构建检测器颈部,并采用高效的层聚合网络(ELAN)和重参数化对其CSPNet进行升级。然后,我们研究了检测器头部大小对检测性能的影响,发现只有一个任务投影层的重颈部会产生更好的结果。此外,为了解决标签分配中的不对齐问题,提出了AlignedOTA算法。并引入了一种蒸馏模式,将性能提高到更高的水平。基于这些新技术,我们构建了一套不同规模的模型,以满足不同场景的需求。对于一般工业要求,我们建议DAMO-YOLO-T/S/M/L。它们可以在COCO上实现43.6/47.7/50.2/51.9 map,在T4 GPU上的延迟分别为2.78/3.83/5.62/7.95 ms。此外,对于计算能力有限的边缘设备,我们还提出了DAMO-YOLO-Ns/Nm/Nl轻量级模型。它们可以在COCO上实现32.3/38.2/40.5 map,在X86-CPU上的延迟为4.08/5.05/6.69 ms。我们提出的通用模型和轻量化模型在各自的应用场景中都优于其他YOLO系列模型。代码可在https://github.com/tinyvision/damo-yolo上获得。
1. 简介
近年来,研究人员开发的物体检测方法取得了巨大进展[1,9,11,23,24,27,33]。当业界追求具有实时约束的高性能物体检测方法时,研究人员专注于设计具有高效网络架构[4,16,17,29,30]和高级训练阶段[10,17,21,26,31]的单阶段检测器[1,22 - 24,26]。特别是YOLOv5/6/7[18,32,34]、YOLOX[9]和PP-YOLOE[38]在COCO上实现了显著的AP-Latency权衡,使得YOLO系列物体检测方法在业界得到广泛应用。
虽然物体检测已经取得了很大的进步,但仍然有新的技术可以引入,以进一步提高性能。首先,网络结构在物体检测中起着关键作用。Darknet在YOLO历史的早期阶段占据主导地位[1,9,24 - 26,32]。最近,一些研究人员研究了其他有效的检测器网络,即YOLOv6[18]和YOLOv7[34]。然而,这些网络仍然是手工设计的。由于神经结构搜索(NAS)的发展,通过NAS技术发现了许多检测友好的网络结构[4,16,30],这些结构比以前手工设计的网络显示出很大的优势。因此,我们利用NAS技术,为我们的DAMOYOLO导入了MAE-NAS[30]1。MAE-NAS是一种启发式的、不需要训练的神经结构搜索方法,不依赖于超网络,可用于不同规模的骨干网络归档。它可以使用空间金字塔池和焦点模块生成类似ResNet / CSP的结构。
其次,检测器在高级语义特征和低级空间特征之间学习到足够的融合信息是至关重要的,这使得检测器颈部成为整个框架的重要组成部分。颈部的重要性在其他著作中也有讨论[10,17,31,36]。特征金字塔网络(FPN)[10]已被证明是融合多尺度特征的有效方法。广义FPN (GFPN)[17]通过一种新颖的蜂群融合改进了FPN。在DAMO-YOLO中,我们设计了一个Reparameterized Generized FPN(RepGFPN)。该算法基于GFPN,但涉及到加速后融合、高效层聚合网络(ELAN)和重参数化。
为了在延迟和性能之间取得平衡,我们进行了一系列实验来验证检测器的颈部和头部的重要性,发现“大颈部,小头部”会带来更好的性能。因此,我们在之前的YOLO系列作品[1,9,24 - 26,32,38]中丢弃检测器头部,只留下一个任务投影层。保存的计算被移动到颈部部分。除了任务投影模块,头部中没有其他训练层,所以我们将检测器头部命名为ZeroHead。再加上我们的RepGFPN, ZeroHead实现了最先进的性能,我们相信这将为其他研究人员带来一些见解。
此外,OTA[8]、TOOD[7]等动态标签分配方式也受到广泛好评,相对于静态标签分配[43]有了显著的改进。然而,在这些工作中,不对准问题仍然没有得到解决。我们提出了一个更好的解决方案AlignOTA来平衡分类和回归的重要性,可以部分解决这个问题。
最后,知识蒸馏(Knowledge Distillation, KD)被证明可以有效地通过对大模型的监督来提升小模型。这项技术完全符合实时物体检测的设计。然而,在YOLO系列上应用KD有时不能取得显著的改善,因为超参数难以优化,特征携带太多的噪声。在我们的DAMO-YOLO中,我们首先在所有尺寸的模型上,特别是在小型模型上,使蒸馏再次伟大。
如图1所示,通过上述改进,我们提出了一系列通用和轻量级模型,这些模型大大超出了目前的技术水平。
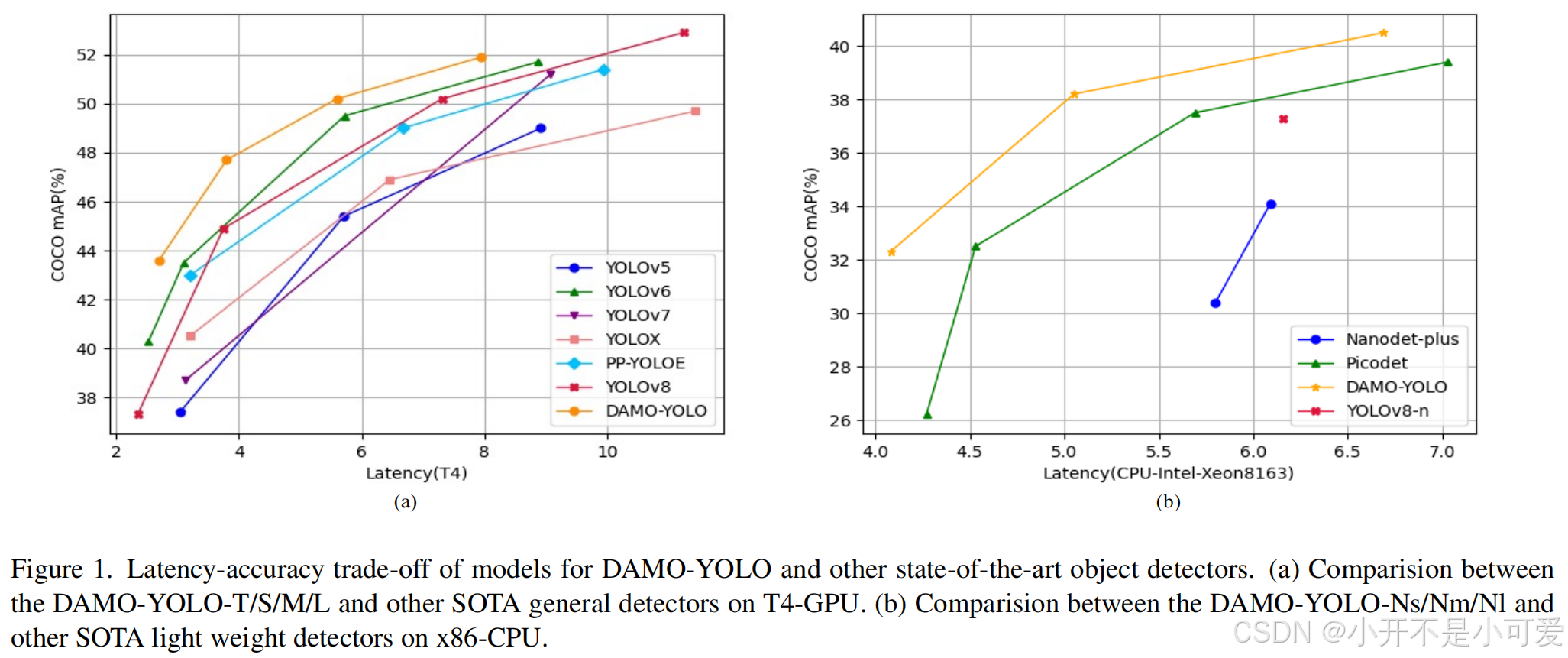
图1. DAMO-YOLO和其他最先进的目标探测器的延迟-精度权衡模型。(a) DAMO-YOLO-T/S/M/L与其他SOTA通用探测器在T4-GPU上的比较。(b) DAMO-YOLO-Ns/Nm/Nl与其他SOTA轻量探测器在x86-CPU上的比较。
1. 本文提出了一种新的探测器DAMO-YOLO,它是在YOLO的基础上扩展而来的,但增加了更多的新技术,包括MAE-NAS主干网、RepGFPN颈部、ZeroHead、AliignedOTA和蒸馏增强。
2. DAMO-YOLO在普通和轻量级类别的公共COCO数据集上优于最先进的检测器(例如YOLO系列)。
3. 在DAMO-YOLO(微型/小型/中型)中提供了一套不同规模的模型,以支持不同的部署。代码和预训练模型发布在https://github.com/tinyvision/damoyolo上,支持ONNX和TensorRT。
2. DAMO-YOLO
在本节中,我们详细介绍了DAMOYOLO的每个模块,包括神经结构搜索(NAS)主干、高效的Reparameterized Generized FPN (RepGFPN)颈部、ZeroHead、AliignedOTA标签分配和蒸馏增强。DAMO-YOLO的整体框架如图3所示。
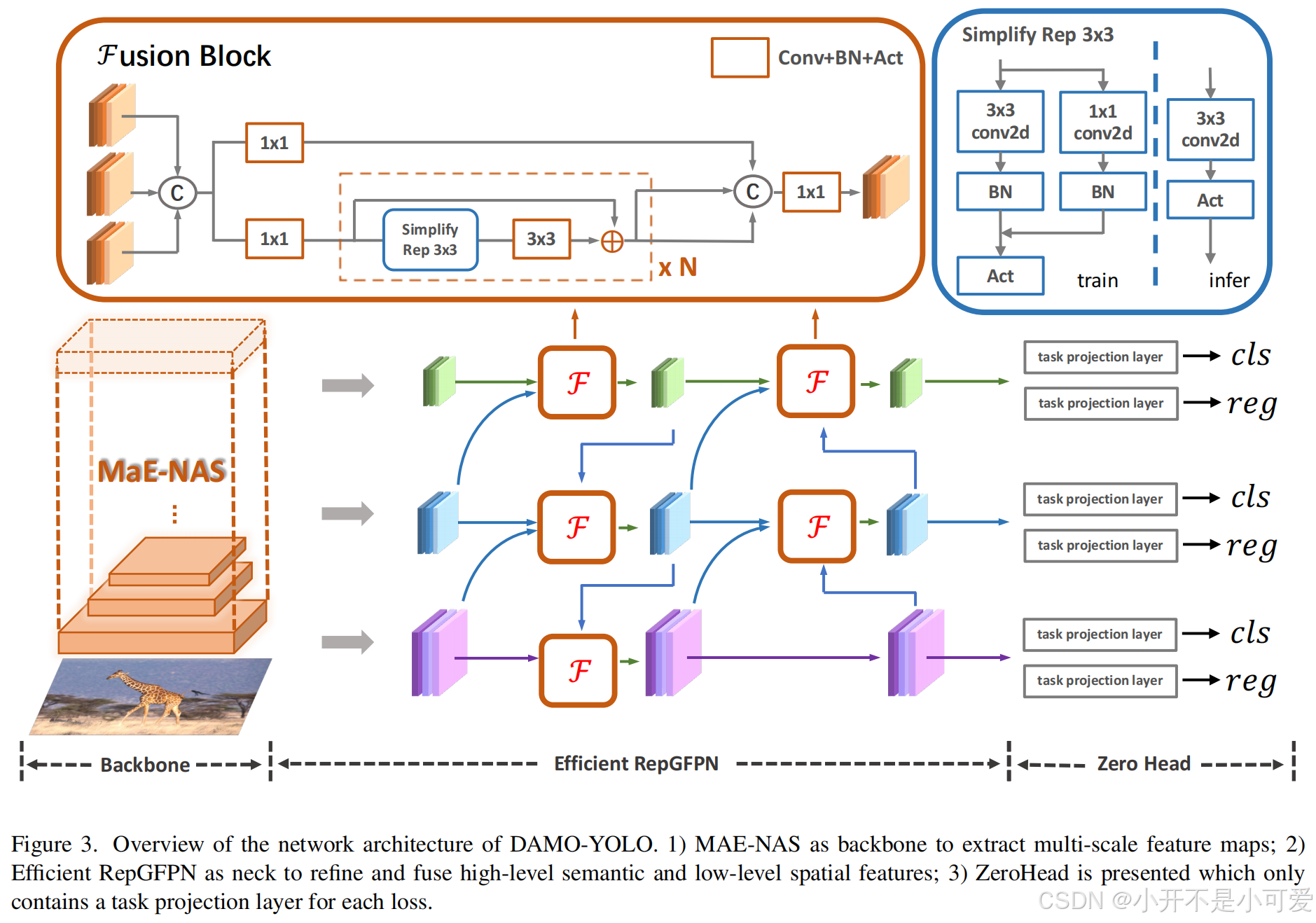
图3. DAMO-YOLO网络架构概述。1)以MAE-NAS为主干提取多尺度特征图;2)以高效的RepGFPN为瓶颈,提炼和融合高级语义和低级空间特征;3)提出了ZeroHead算法,每个损失只包含一个任务投影层。
2.1. MAE-NAS主干
以前,在实时场景中,设计师依赖于的故障和延迟之间的关系并不一定是一致的。为了提高模型在工业部署中的实际性能,DAMO-YOLO在设计过程中优先考虑了延迟-MAP曲线。Flops-mAP曲线作为评估模型性能的简单方法。然而,模型
基于这一设计原则,我们使用MAE-NAS[30]来获得不同延迟预算下的最优网络。MAE-NAS构建了一个基于信息论的替代代理,在不需要训练的情况下对初始化的网络进行排序。因此,搜索过程只需要几个小时,这比训练成本低得多。MAE-NAS提供了几个基本的搜索块,如Mob-Block、Res-Block和CSP-Block,如图2所示。Mobblock是MobileNetV3 [14] block的变体,Res-block来源于ResNet [12], CSP-block来源于CSPNet[35]。完整支持的块列表可以在MAE-NAS存储库中找到2。
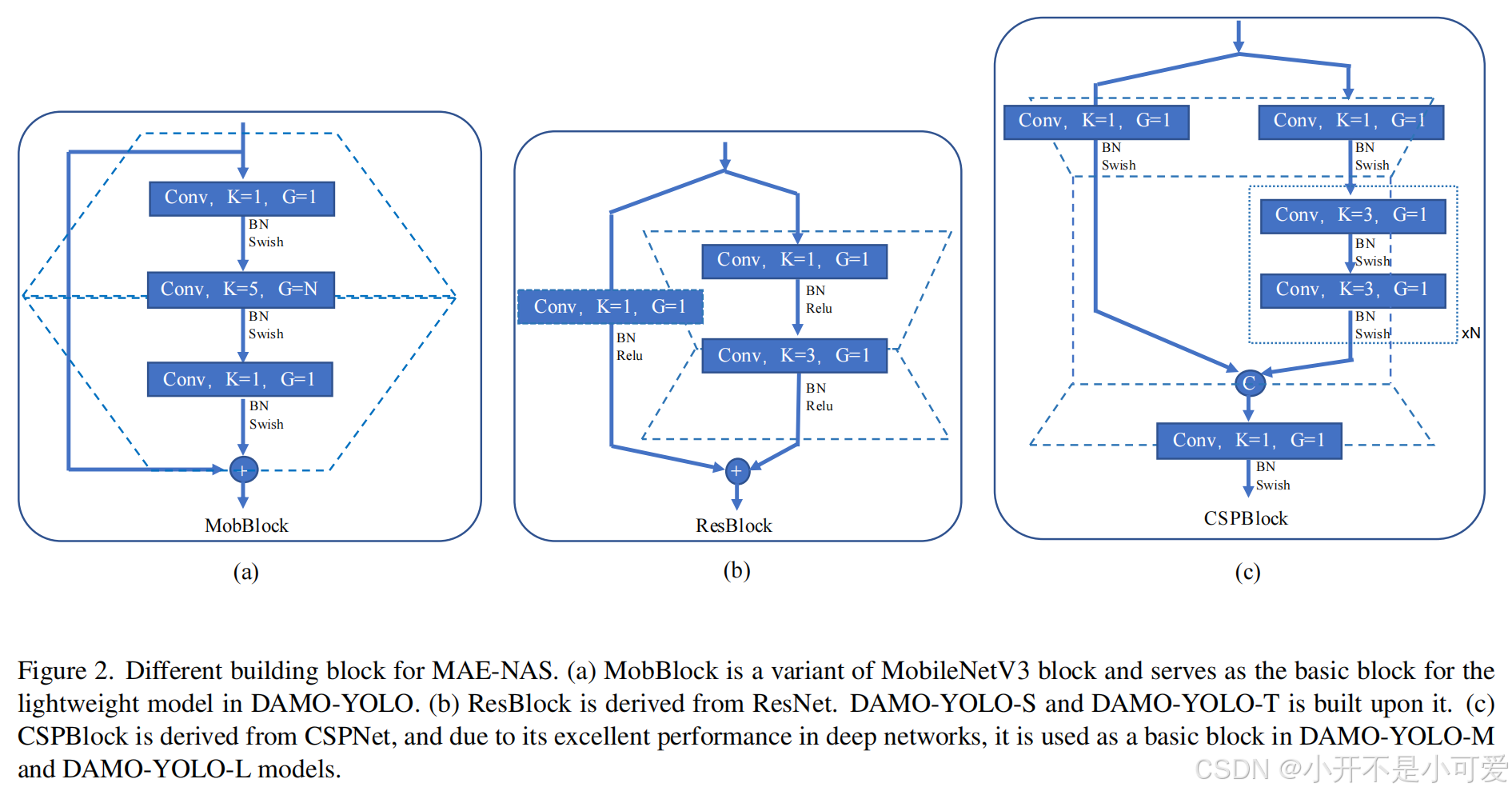
图2. MAE-NAS的不同构建块。(a) MobBlock是MobileNetV3 block的一个变体,是DAMO-YOLO中轻量级模型的基本块。(b) ResBlock来源于ResNet。DAMO-YOLO-S和DAMO-YOLO-T是建立在它之上的。(c) CSPBlock来源于CSPNet,由于其在深度网络中的优异性能,被用作DAMO-YOLO-M和DAMO-YOLO-L模型的基本块。
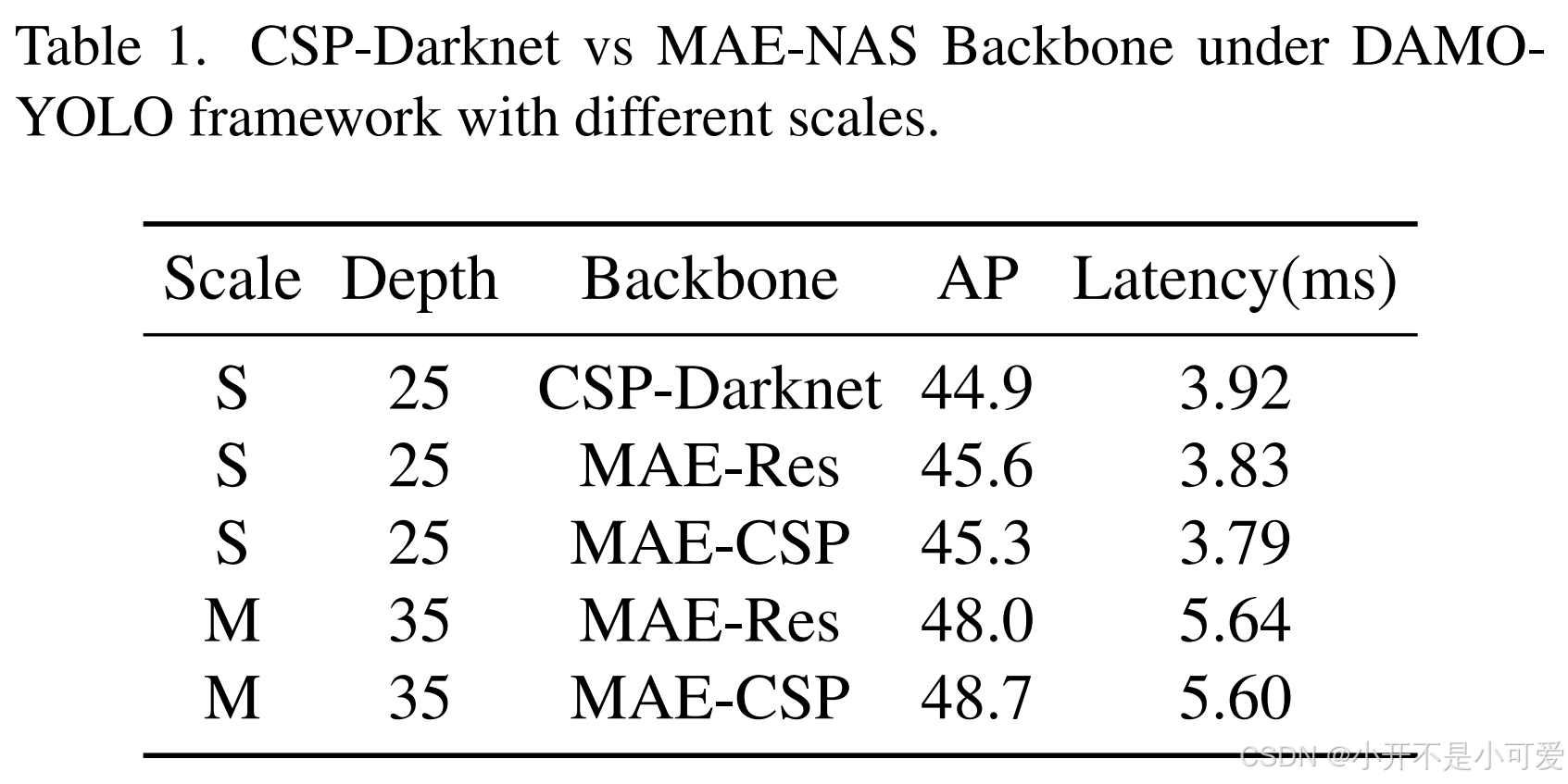
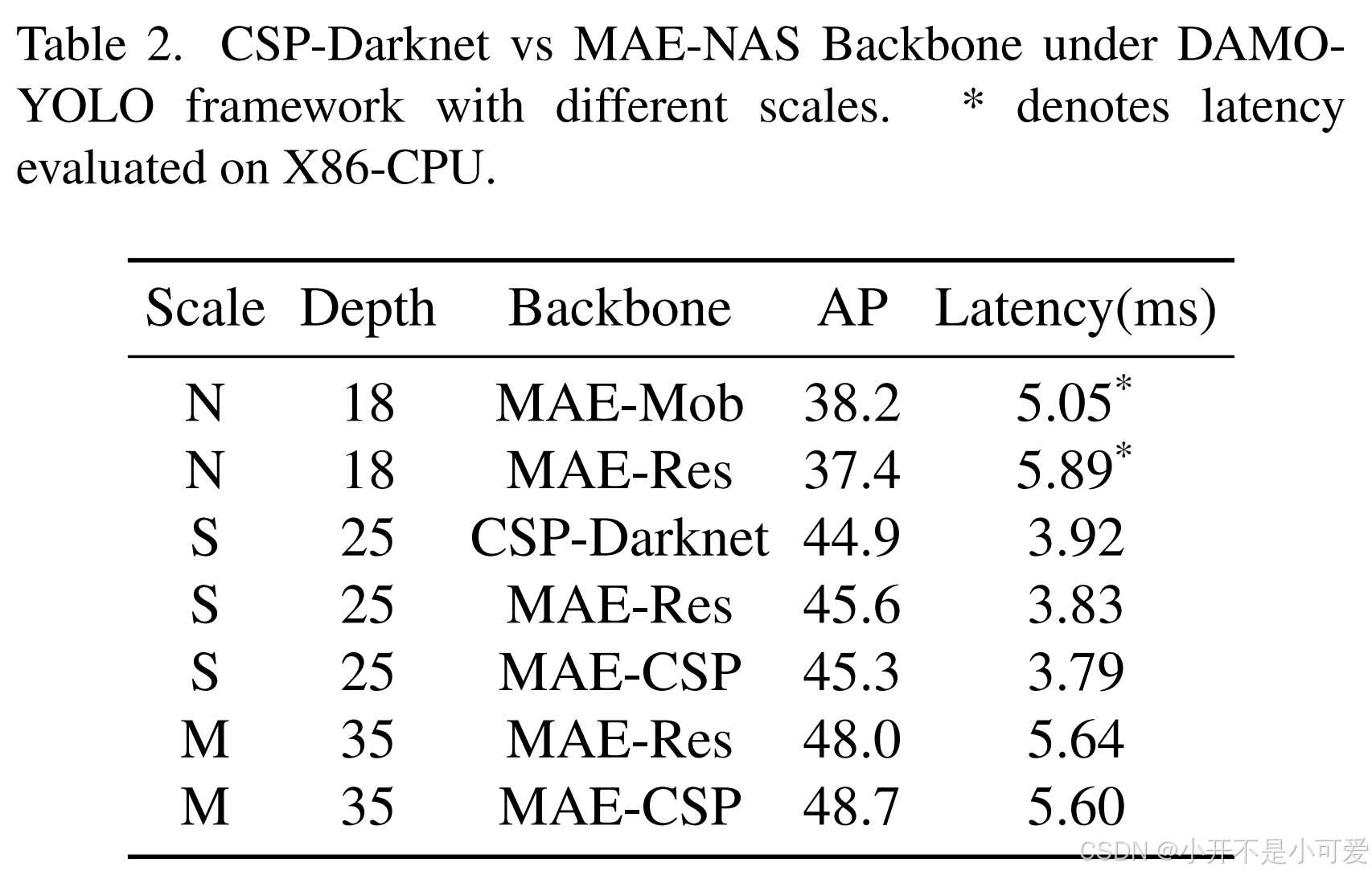
我们发现,在不同尺度的模型中应用不同类型的块可以实现更好的实时推理权衡。在不同规模的DAMO-YOLO下,CSPDarknet与我们的MAE-NAS骨干网的性能比较见表1。表中“MAE-Res”表示在MAE-NAS骨干网中应用Res-block,“MAE-CSP”表示在MAE-NAS骨干网中应用CSPblock。此外,“S”(小)和“M”(中)代表不同的骨干规模。如表1所示,MAE-NAS技术得到的MAE-CSP无论在速度还是精度上都优于人工设计的CSP-Darknet,体现了MAE-NAS技术的优越性。此外,我们可以从表1中观察到,在较小的模型上使用Res-block可以实现比CSP-block更好的性能和速度之间的权衡,而在更大和更深的网络上使用CSP-block可以显著优于Resblock。因此,我们在“T”(Tiny)和“S”模型中使用“MAE-Res”,在“M”和“L”模型中使用“MAE-CSP”。
表1. DAMOYOLO框架下不同规模的CSP-Darknet与MAE-NAS骨干网。
当处理只有有限的计算能力或GPU不可用的场景时,拥有满足严格计算和速度要求的模型至关重要。为了解决这个问题,我们使用Mob-Block设计了一系列轻量级模型。Mob-block源自MobleNetV3[14],可以显著减少模型计算量,并且对CPU设备友好。
2.2. 高效的RepGFPN
特征金字塔网络旨在聚合从主干提取的不同分辨率特征,这已被证明是物体检测的关键和有效部分[10,31,36]。传统的FPN[10]引入了自顶向下的路径来融合多尺度特征。考虑到单向信息流的限制,PAFPN[36]增加了一个额外的自下而上的路径聚合网络,但计算成本较高。BiFPN[31]删除只有一条输入边的节点,并在同一层上从原始输入添加跳链。在[17]中,提出了广义FPN (GFPN)作为颈部,实现了SOTA的性能,因为它可以充分交换高层语义信息和低层空间信息。在GFPN中,多尺度特征融合在前一层和当前层的水平特征中。更重要的是,的跨层连接提供了更有效的信息传输,可以扩展到更深的网络。在现代YOLO系列模型上直接用GFPN代替修改后的PANet,可以获得更高的精度。然而,基于GFPN的模型的延迟比基于改进PANet的模型要高得多。通过分析GFPN的结构,其原因可以归结为:1)不同尺度的特征映射共用相同的通道维数;2)融合后的操作不能满足实时检测模型的要求;3)基于卷积的跨尺度特征融合效率不高。
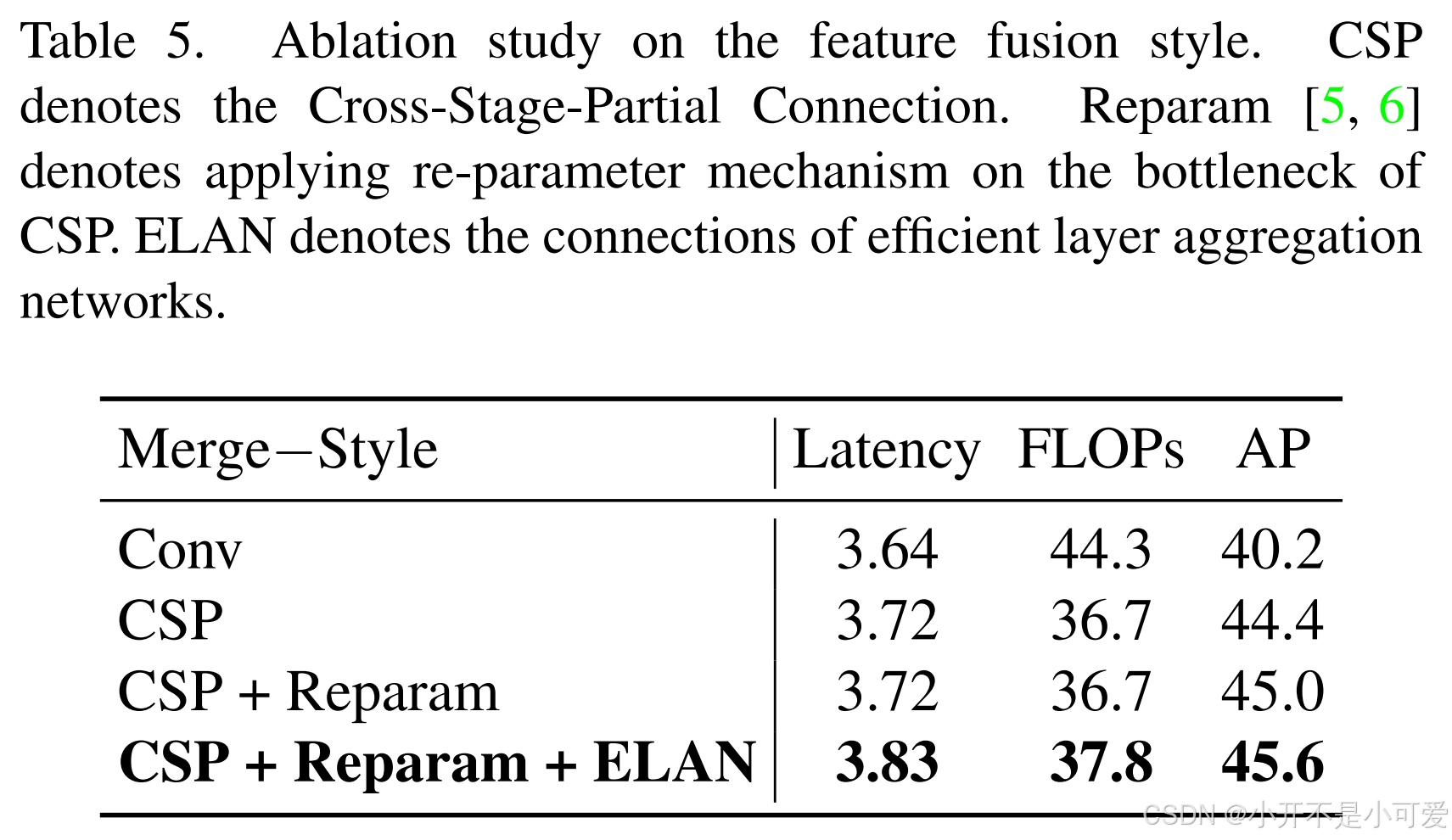
基于GFPN,我们提出了一种新的Efficient-RepGFPN来满足实时物体检测的设计,主要包括以下几点见解:1)由于不同尺度特征映射的FLOPs差异较大,在计算成本有限的约束下,难以控制每个尺度特征映射共享的通道的相同维度。因此,在我们颈部的特征融合中,我们采用了不同通道尺寸的不同比例特征映射的设置。相同和不同通道的性能以及颈部深度和宽度权衡带来的精度优势进行了比较,表3显示了结果。我们可以看到,通过灵活地控制不同尺度的通道数量,我们可以获得比在所有尺度上共享相同通道更高的精度。当深度等于3,宽度等于(96,192,384)时,获得最佳性能。2) GFPN通过蜂群融合增强了特征交互,但也带来了大量额外的上采样和下采样算子。这些上采样和下采样算子的好处进行了比较,结果如表4所示。我们可以看到,额外的上采样算子导致延迟增加0.6ms,而精度提高仅为0.3mAP,远远低于额外的下采样算子的好处。因此,在实时检测的约束下,我们去掉了后融合中额外的上采样操作。3)在特征融合块中,我们首先用CSPNet代替原来基于3x3- convolutional的特征融合,得到4.2 mAP增益。随后,我们通过引入重参数化机制和高效层聚合网络(ELAN)[34]的连接对CSPNet进行了升级。在不增加额外的计算负担的情况下,实现了更高的精度。对比结果如表5所示。
表3. 消融术对颈部深度和宽度的研究。“深度”为融合块瓶颈上的重复次数。“宽度”表示特征映射的通道尺寸。
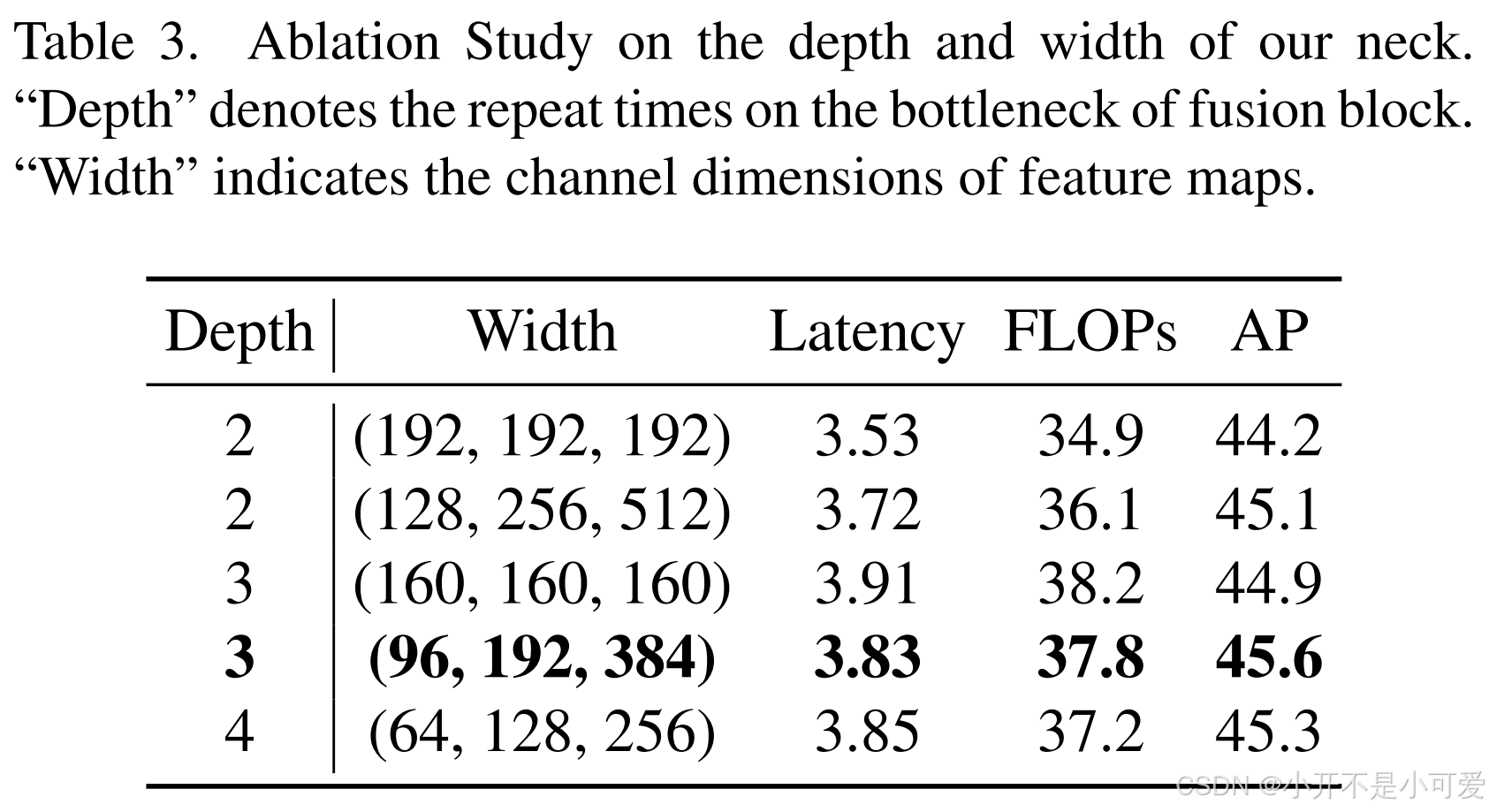
表4. 后融合连接的消融研究。![]() 和
和![]() 分别表示上采样和下采样操作。
分别表示上采样和下采样操作。
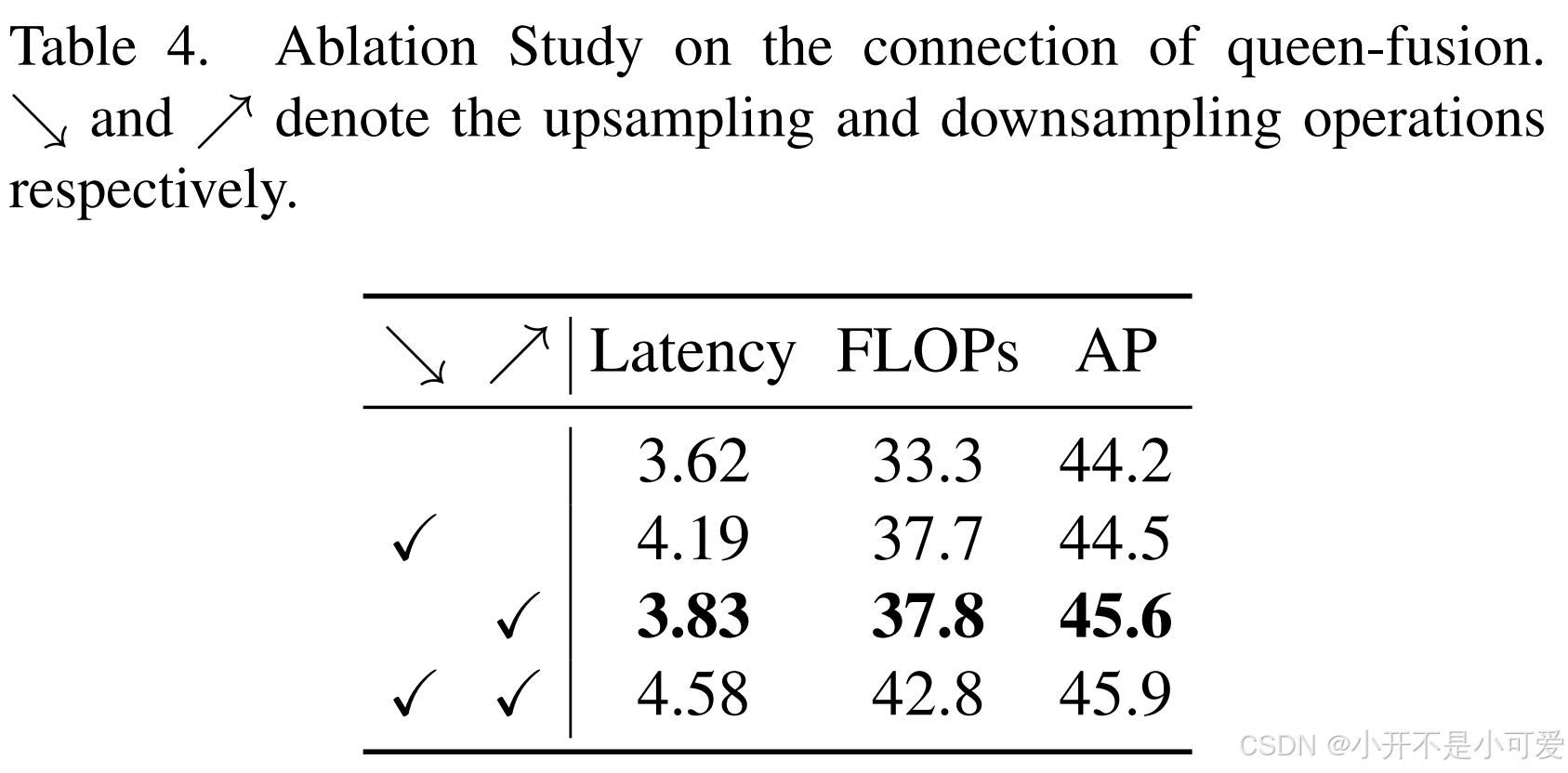
表5. 特征融合型烧蚀研究。CSP表示跨阶段部分连接。Reparam[5,6]是指在CSP瓶颈上应用重参数机制。ELAN表示有效层聚合网络的连接。
2.3. ZeroHead和AlignOTA
在最近的物体检测进展中,解耦头被广泛使用[9,18,38]。使用解耦的头部,这些模型实现更高的AP,同时延迟显着增加。为了权衡延迟和性能,我们进行了一系列实验来平衡颈部和头部的重要性,结果如表6所示。从实验中我们发现,“大脖子,小脑袋”会带来更好的性能。因此,我们在之前的作品[9,18,38]中放弃解耦的头部,只留下一个任务投影层,即一个用于分类的线性层和一个用于回归的线性层。我们将我们的大脑命名为ZeroHead,因为我们的大脑中没有其他训练层。ZeroHead可以最大程度地节省重型RepGFPN颈部的计算。值得注意的是,ZeroHead本质上可以看作是一个耦合的磁头,这与其他作品中解耦的磁头有很大的不同[9,18,32,38]。在头部后的损失中,在GFocal[20]之后,我们使用质量焦损失(QFL)进行分类监督,并使用分布焦损失(DFL)和GIOU损失进行回归监督。QFL鼓励学习分类和本地化质量的联合表示。DFL通过将其位置建模为一般分布,提供了更多信息和精确的边界框估计。提出的DAMO-YOLO的训练损失公式为:
![]()
表6. RepGFPN与ZeroHead的平衡研究。

除了头部和损失之外,标签分配是检测器训练过程中的一个重要组成部分,它负责将分类和回归目标分配给预定义的锚点。最近,OTA[8]和ood[7]等动态标签分配方法得到了广泛的好评,并且与静态[7]相比取得了显著的改进。动态标签分配方法根据预测值与真实值之间的分配成本来分配标签,如OTA[8]。虽然在损失中分类与回归的一致性被广泛研究[7,20],但是在标签分配中分类与回归的一致性在目前的工作中很少被提及。分类和回归的不一致是静态分配方法中的一个常见问题。虽然动态赋值可以缓解这一问题,但由于分类损失和回归损失(如CrossEntropy和IoU Loss[40])的不平衡,这一问题仍然存在。为了解决这一问题,我们将焦损[22]引入到分类成本中,并使用预测和真实值盒的IoU作为软标签,其公式为:
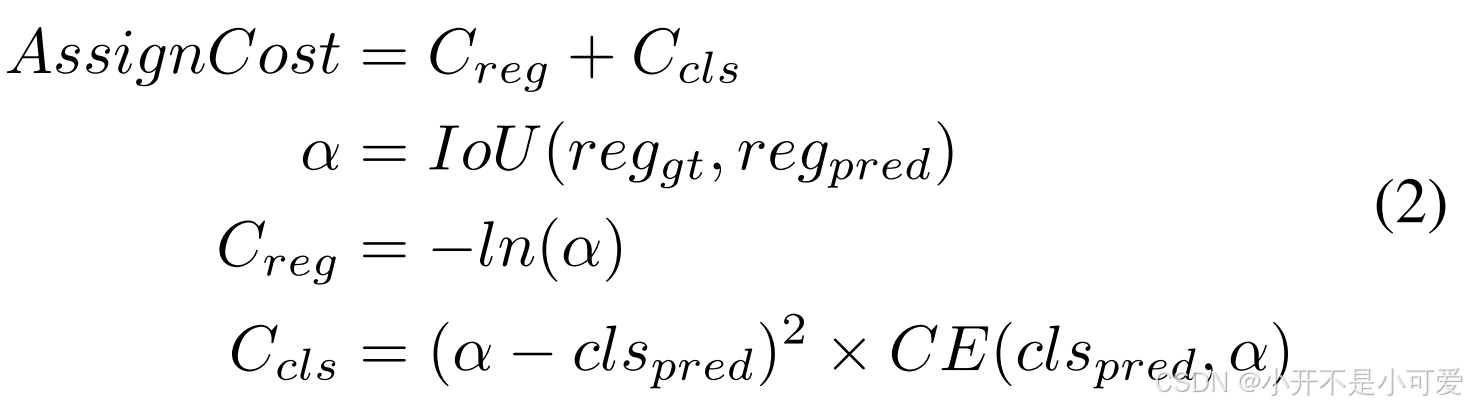
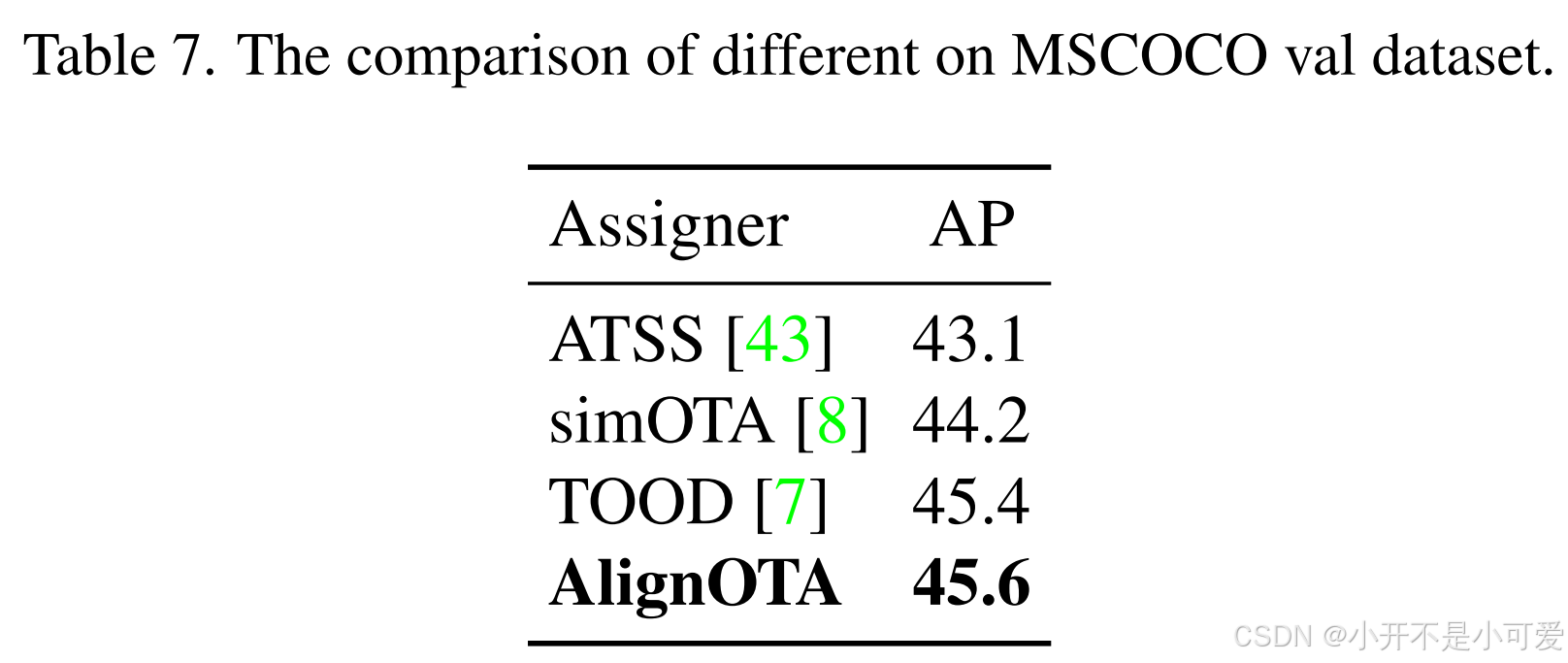
有了这个公式,我们就可以为每个目标选择分类和回归对齐的样本。除了对齐的分配成本外,根据OTA[8],我们从全局角度形成对齐的分配成本的解。我们将标签分配命名为AlignOTA。标签分配方法的比较见表7。我们可以看到AlignOTA优于所有其他标签分配方法。
表7. 不同数据集在MSCOCO值上的比较。
2.4. 蒸馏强化
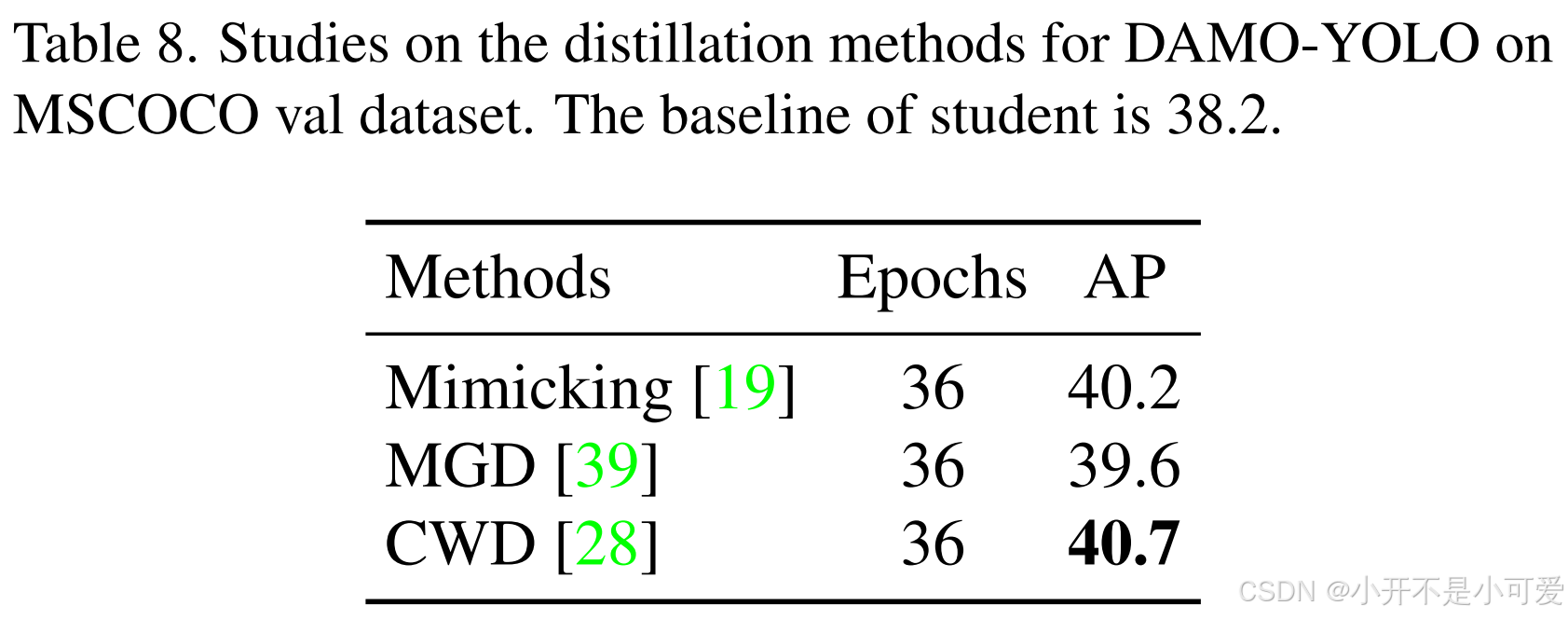
知识蒸馏(KD)[13]是进一步提高口袋大小模型性能的有效方法。然而,在YOLO系列上应用KD有时不能取得显著的改善,因为超参数难以优化,特征携带太多的噪声。在DAMO-YOLO中,我们首先在所有尺寸的模型上,特别是在小尺寸上,使蒸馏再次伟大。我们采用基于特征的精馏来传递暗知识,可以在中间特征映射[15]中同时提取识别和定位信息。我们进行了快速验证实验,以选择合适的达摩- yolo蒸馏方法。结果如表8所示。我们得出结论,CWD更适合我们的模型,而MGD比miming更糟糕,因为复杂的超参数使其不够通用。
表8. 基于MSCOCO数据集的DAMO-YOLO精馏方法研究。学生的基线为38.2。
我们提出的蒸馏策略分为两个阶段:1)教师在强镶嵌域上对第一阶段(284个epoch)的学生进行蒸馏。面对具有挑战性的增强数据分布,学生可以在老师的指导下进一步顺利地提取信息。2)在第二阶段(16次),学生在没有镶嵌域的情况下进行自己的演奏。我们在这个阶段不采用蒸馏的原因是,在这么短的时间内,当老师想把学生拉到一个陌生的领域(即没有马赛克的领域)时,老师的经验会损害学生的表现。长期蒸馏可以减轻损害,但代价高昂。所以我们选择权衡,让学生独立。
在达摩- yolo,蒸馏配备了两个先进的增强功能:1)对齐模块。一方面,它是一个线性投影层,使学生的特征与教师的特征具有相同的分辨率(C,H,W)。另一方面,强迫学生近似教师特征直接导致与自适应特征和学生特征相比收益较小,削弱了真实值差异带来的影响。减去平均值后,各通道的标准差作为KL损耗中的温度系数。
此外,为了更好地利用蒸馏,我们提出了两个关键的观察结果。一个是蒸馏和任务丢失之间的平衡。如图4所示,当我们更关注蒸馏(权重=10)时,学生中的分类损失收敛缓慢,从而产生负面影响。因此,小的损失重量3(重量=0.5)对于在蒸馏和分级之间取得平衡是必要的。另一种是探测器的浅头。研究发现,适当减小头部深度有利于颈部特征的提取。原因是当最终输出和蒸馏特征图之间的差距更近时,蒸馏可以更好地影响决策。
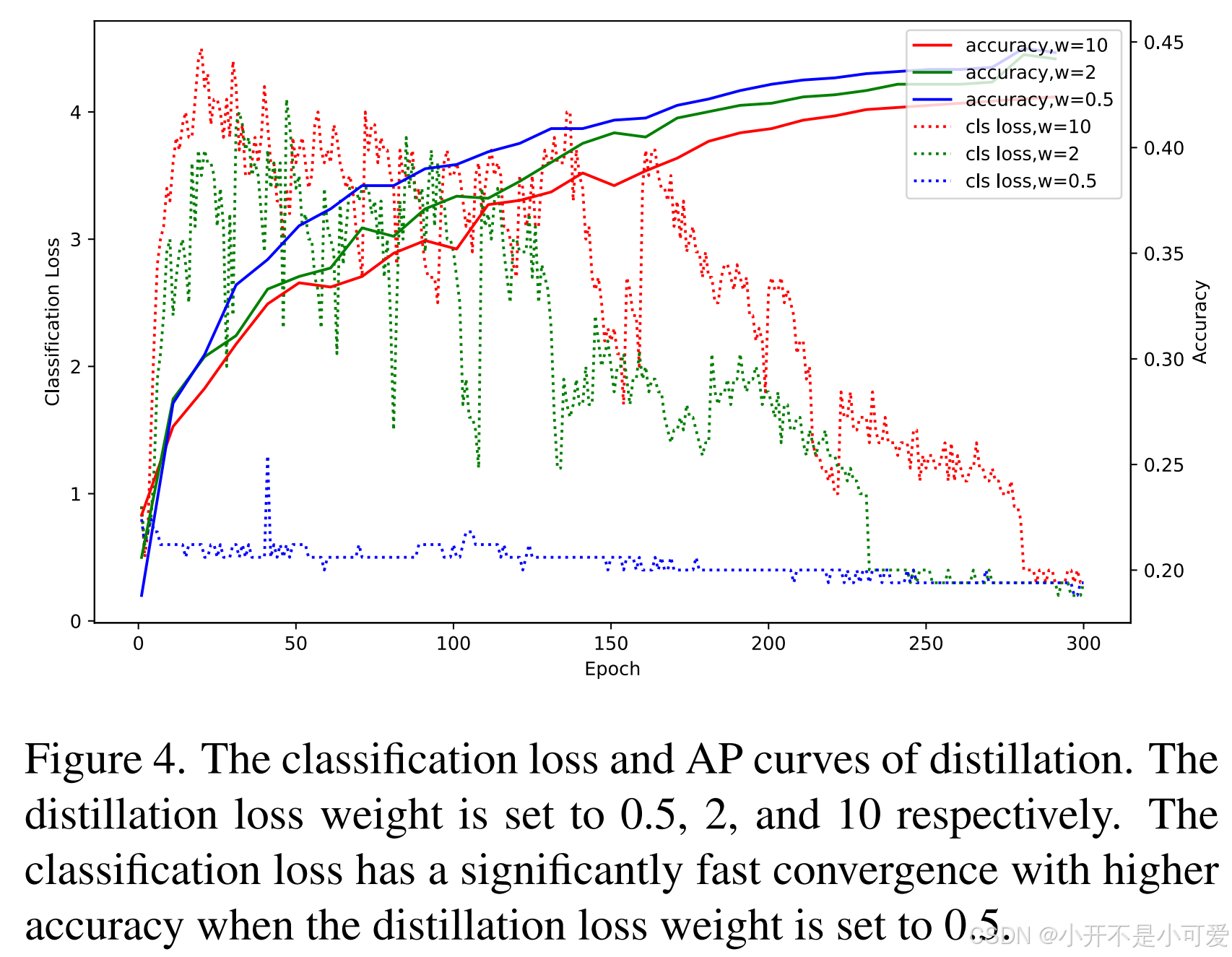
图4. 蒸馏的分级损失和AP曲线。蒸馏损失重量分别设置为0.5、2和10。当蒸馏损失权重为0.5时,分类损失收敛速度明显快,精度较高。
在实践中,我们使用DAMO-YOLO-S作为老师蒸馏DAMO-YOLO-T, DAMO-YOLO-M作为老师蒸馏DAMO-YOLO-S, DAMO-YOLO-L作为老师蒸馏DAMO-YOLO-M, DAMO-YOLO-L自行蒸馏。
2.5. 通用级DAMO-YOLO模型
在本节中,我们将介绍General Class DAMOYOLO模型,该模型已经在多个大型数据集上进行了训练,包括COCO、Objects365和OpenImage。我们的模型包含了几项改进,可以实现高精度和泛化。首先,我们通过创建统一的标签空间进行过滤,解决了不同数据集之间重叠类别造成的歧意,例如“鼠标”,它可以指COCO/Objects365中的计算机鼠标和OpenImage中的啮齿动物。这将原来的945个类别(80个来自COCO, 365个来自Objects365, 500个来自OpenImage)减少到701[42]。其次,我们提出了一种多项式平滑然后加权抽样的方法来解决数据集大小的不平衡,这种不平衡通常会导致对较大数据集的批量抽样偏差。
最后,我们实现了一个类感知采样方法来解决Objects365和OpenImage数据集中的长尾效应问题。这将为包含较少数据点的类别的图像分配更大的采样权重。
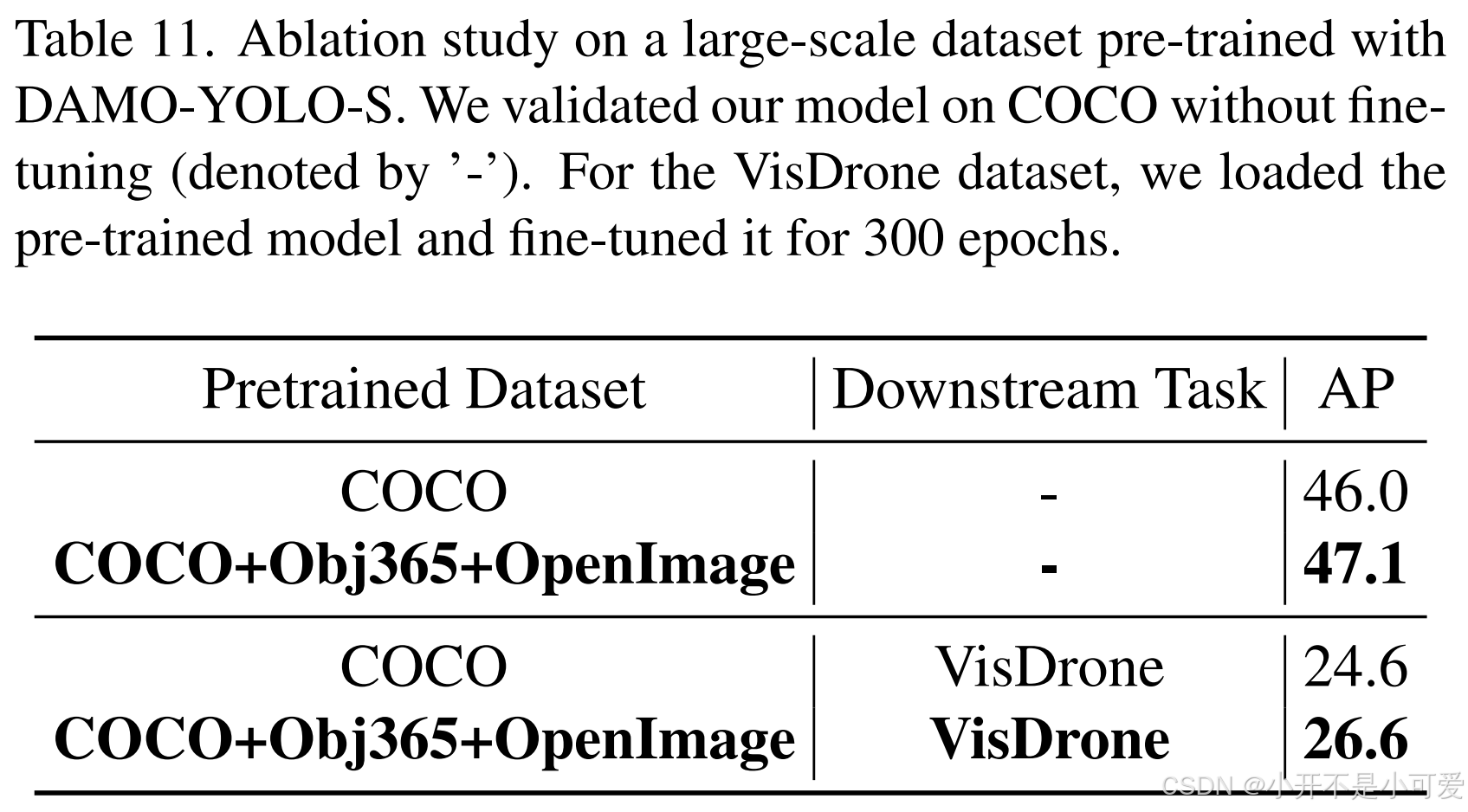
通过改进我们的模型,我们在大规模数据集上训练了DAMO-YOLOS,与COCO上的DAMO-YOLOS基线相比,mAP提高了1.1%。此外,这个预训练的模型可以对下游任务进行微调。我们将其应用于VisDrone数据集300个epoch,获得了26.6%的mAP,超过了在COCO上预训练的模型的性能。这些结果突出了大规模数据集训练的优势及其为模型提供的鲁棒性。结果见表11。
表10. 与MSCOCO验证集上最先进的轻重量探测器的比较。延迟是我们在Intel-8163 CPU上用OpenVINO测试的,其他结果来自相应的论文。
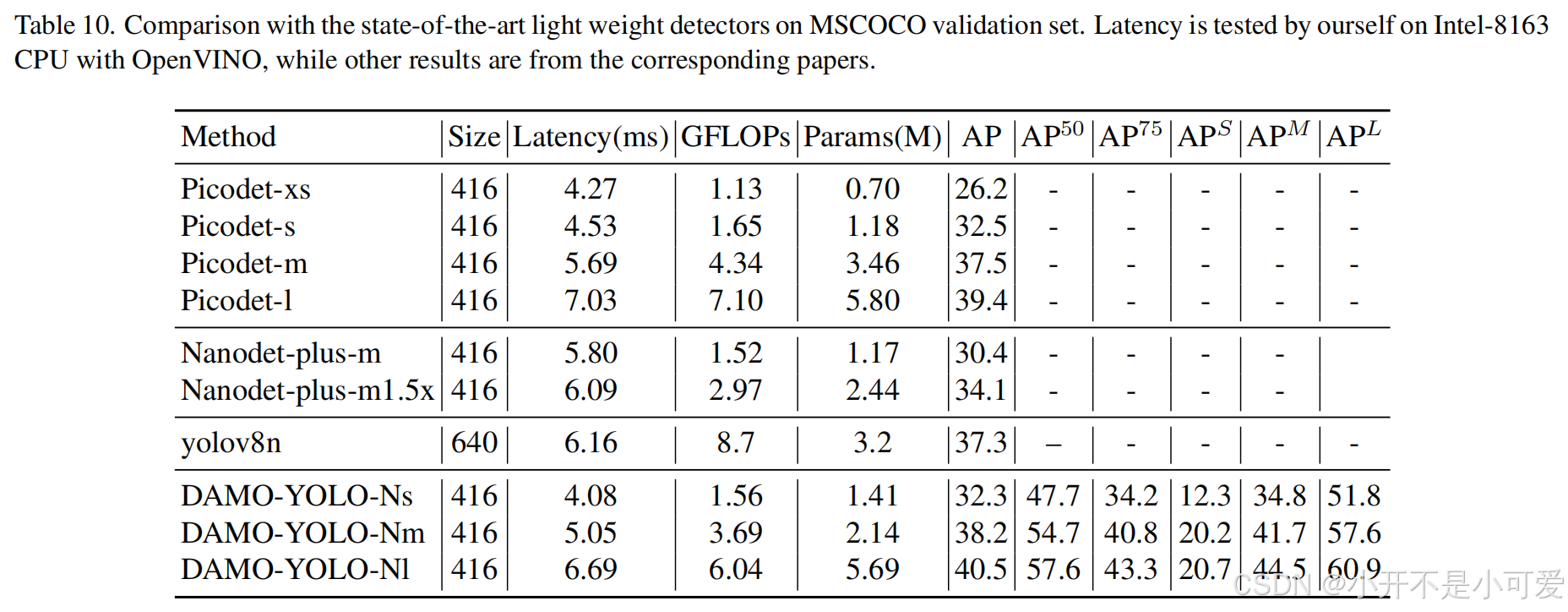
表11. 基于DAMO-YOLO-S预训练的大规模数据集烧蚀研究。我们在没有微调的情况下在COCO上验证了我们的模型(用' - '表示)。对于VisDrone数据集,我们加载了预训练的模型,并对其进行了300次微调。
3. 实现细节
我们的模型用SGD优化器训练了300次。权重衰减和SGD动量分别为5e-4和0.9。初始学习率为0.4,批大小为256,学习率根据余弦调度递减。根据YOLO-Series[9,18,32,34]模型,使用指数移动平均(EMA)和分组权重衰减。为了增强数据的多样性,Mosaic[1,32]和Mixup[41]增强是常见的做法。然而,最近的进展[3,44]表明,适当设计的盒级增强在物体检测中至关重要。受此启发,我们将Mosaic和Mixup用于图像级增强,并在图像级增强后使用SADA[3]的盒级增强以获得更鲁棒的的增强。
4. 与SOTA的比较
DAMO-YOLO推出了一系列通用车型和轻量化车型,满足了通用场景和资源有限的边缘场景。
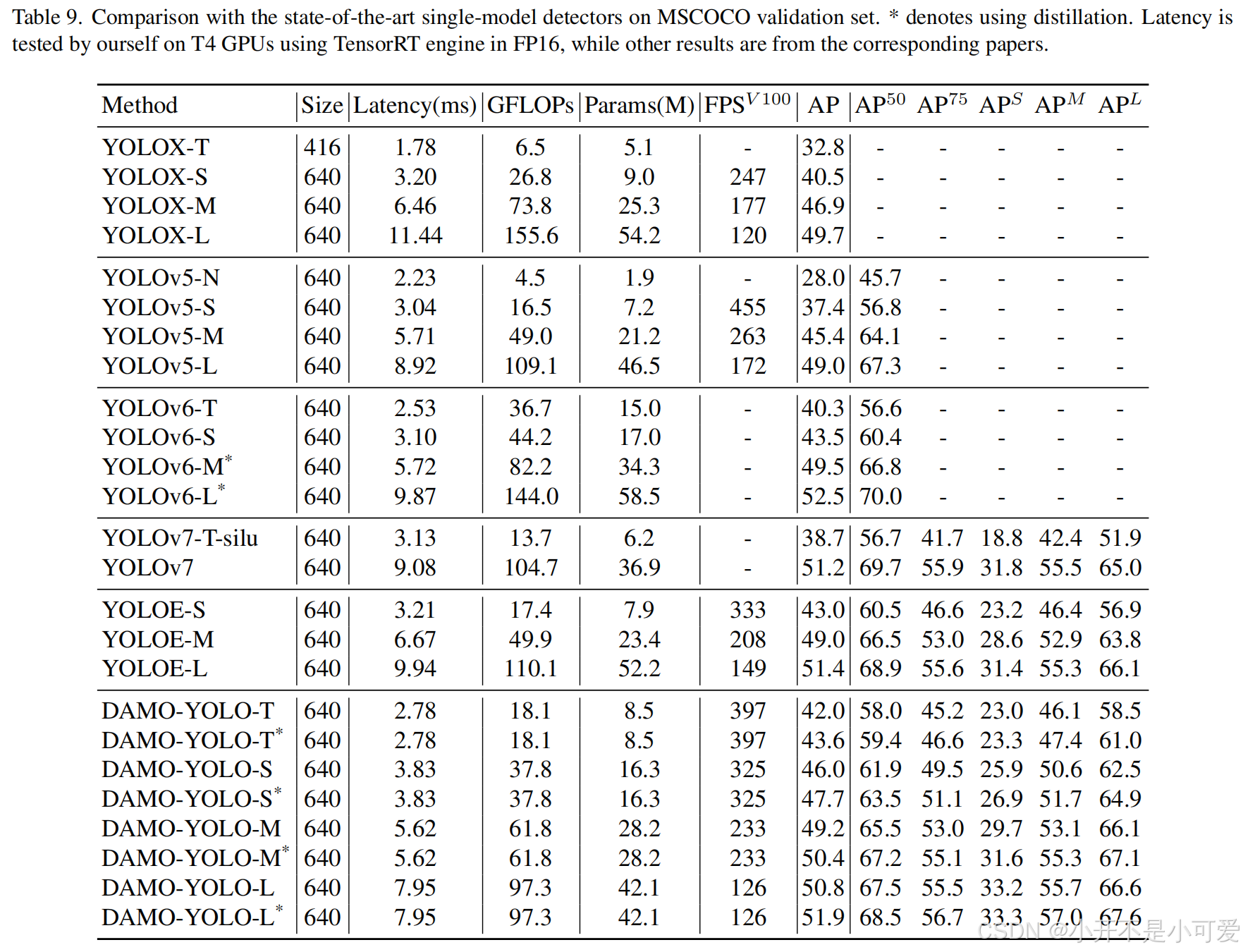
为了评估DAMO-YOLO通用模型与其他最先进模型的性能,我们使用TensorRT-FP16推理引擎在T4-GPU上进行了比较分析。结果如表9所示,表明DAMO-YOLO的通用模型在准确率和速度上都优于其竞争对手。此外,我们提出的蒸馏技术提供了精度的显著提高。
表9。在MSCOCO验证集上与最先进的单模探测器的比较。*表示使用蒸馏。延迟是我们自己在T4 gpu上使用FP16上的TensorRT引擎测试的,其他结果来自相应的论文。
为了评估轻量级模型的性能,我们在使用Openvino作为推理引擎的Intel-8163 CPU上进行了对比分析。如表2所示,DAMO-YOLO的轻量化模型取得了实质性的领先优势,在速度和精度方面都大大超过了竞争对手。
表2。DAMOYOLO框架下不同规模的CSP-Darknet与MAE-NAS骨干网。*表示在X86-CPU上评估的延迟。
5. 结论
本文提出了一种新的物体检测方法DAMO-YOLO,其性能优于YOLO系列中的其他方法。它的优势来自于新技术,包括MAE-NAS主干网、高效的RepGFPN颈、ZeroHead、AlignedOTA标签分配和蒸馏增强。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)