说人话之什么是 RAG(检索增强生成)?
摘要:RAG(检索增强生成)技术解决大模型三大痛点 RAG技术通过动态检索外部知识增强大模型能力,主要解决三大问题:1)知识过时——实时检索最新信息;2)生成幻觉——提供事实依据减少虚构;3)潜在偏见——引入多样化数据源。其工作流程分为数据准备(分块、向量化、存储)和问答处理(查询向量化、相似检索、生成应答)两阶段。RAG无需修改模型参数,通过外挂知识库实现动态知识更新,显著提升回答的时效性和准确
说人话之什么是 RAG(检索增强生成)?
如今的大模型,
上知天文、下晓地理,
文能写诗、武能编程,
俨然科技圈的超级偶像!
可谁能想到,
人前呼风唤雨的技术新贵,
却面临着潜在的"塌房"危机!
🚨 大模型的“塌房危机”
风靡全球的大模型面临着三大问题:过时、幻觉和偏见!

**过时:**大模型的认知边界受限于预训练数据的时间,而训练数据往往存在一定的滞后性。此外,模型训练复杂、成本高昂,难以频繁更新,知识库自然也跟不上外界变化。
**幻觉:**当大模型遇到知识盲区时,会启动一种危险的联想补全机制,基于局部信息拼接出看似合理、实则虚构的内容,这便是所谓的 “模型幻觉”。这种“煞有介事”的错误往往比直接承认未知更具误导性。

**偏见:**在三大问题中,偏见问题最为隐蔽,也最难根除。这些偏见并非AI主动产生,根源在于训练数据本身隐含的各类社会偏见,其在模型学习过程中会被持续放大。
💡科技“顶流”如何自救?
这三大危机就像随时引爆的“黑料”,迫使大模型不得不琢磨自救对策——RAG(Retrieval-Augmented Generation,检索增强生成)。
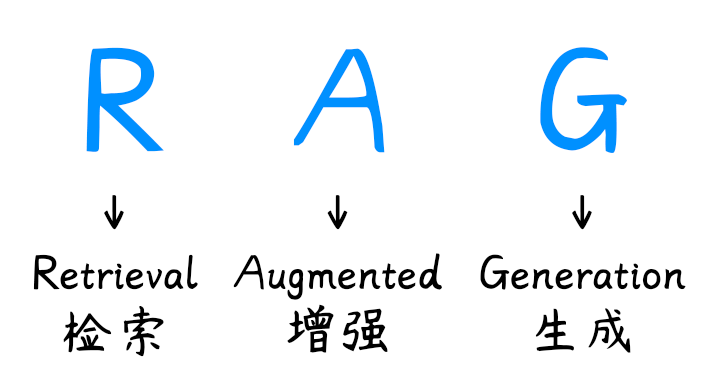
RAG的核心思想是在生成回答时不完全依赖模型中的静态知识,而是通过检索器动态获取外部知识片段,再将其作为上下文输入大模型,从而增强其生成能力。它无需修改模型参数,而是以“外挂”的形式拓宽大模型的知识边界。
知识保鲜期危机?
RAG核心机制在于动态知识注入机制,实时连接外部数据库/API接口等,在生成回答前主动检索最新数据。当传统模型的知识因训练数据滞后而“过期”时,RAG能通过检索机制自动补充最新信息,确保输出内容的时效性和准确性。
爱胡说八道?
RAG 通过检索外部知识,对比多个来源数据,为答案提供事实参考依据,降低模型捏造内容的概率,不过RAG 无法完全杜绝“幻觉”问题。
戴有色眼镜?
RAG通过更广泛、更多样化的外部信息提供更全面的视角,从而减少模型对训练数据中偏见信息的依赖。然而,如果外部信息源存在局限性,偏见问题可能依然存在。要有效应对模型偏见,还需要从训练数据质量和模型设计入手。
🤔RAG的核心流程
顾名思义,RAG(检索增强生成)通过三阶段协同机制实现动态知识整合,其核心流程如下:
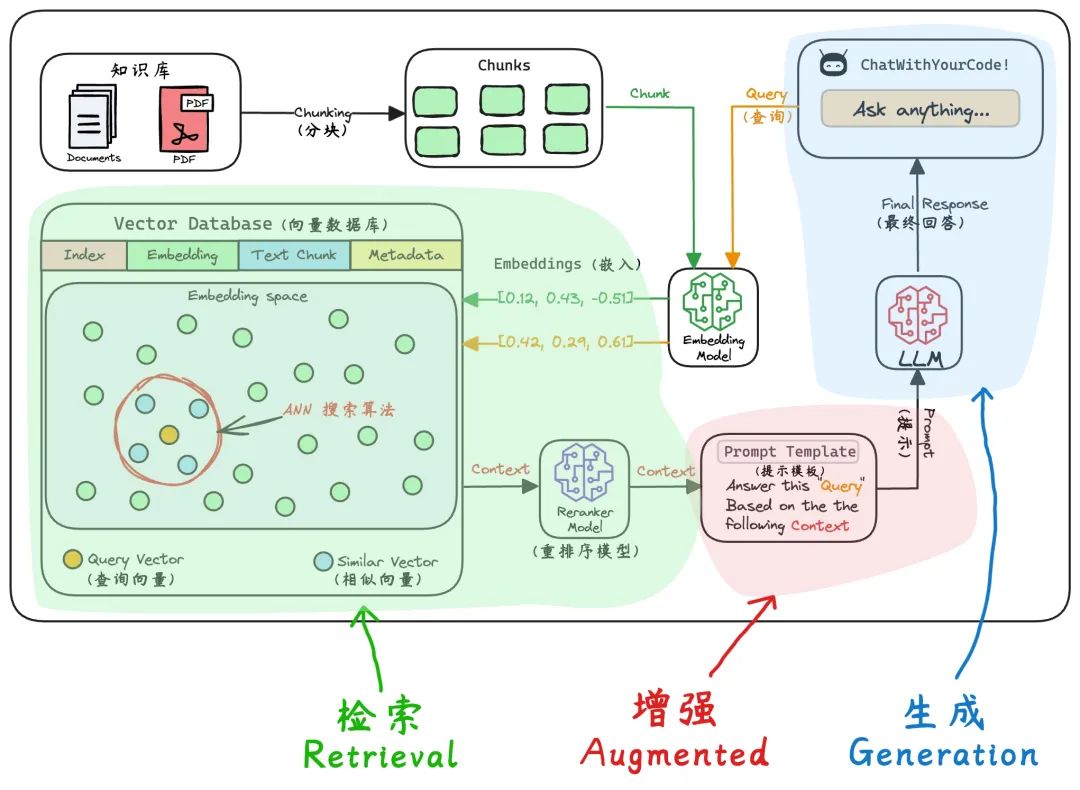
1.检索阶段: 用户输入一个问题或指令(Query),系统中的检索器根据这个输入从外部数据库中检索相关资料(可能是互联网上的公开文档,也可能是用户数据库中的个人数据)。这一阶段的核心目标是从异构数据源中高效定位相关信息片段,为后续生成提供基础。
2. 增强阶段: 将检索到的相关信息有效地整合到用户的原始查询中,形成一个新的、信息更丰富的“提示”(Prompt),提供给生成模型。该阶段的核心目标是构建语义增强的上下文输入。
3. 生成阶段: 大模型基于“提示”生成一个自然、准确的响应。该阶段的核心目标是基于增强后的上下文生成精准响应。
💼RAG具体是如何工作的?
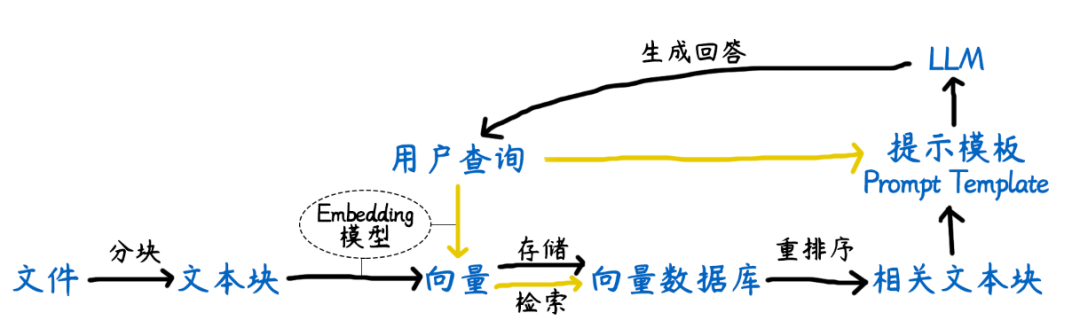
一个完整的RAG工作流程包括两大部分:准备部分(发生在提问前)和回答部分(发生在提问后)。
准备部分(提问前): 外部资料分块➡️将拆分好的文本块通过Embedding模型转换成向量➡️将这些向量存储到向量数据库中。
回答部分(提问后): 用户查询➡️将用户的问题转换成向量➡️从向量库中检索出与用户问题相关的文本块➡️将检索到的文本块重新排序,筛选出相关程度高的块➡️将筛选出来的块与用户的原始查询一起发给LLM➡️LLM生成最终回答。
准备部分(数据提取流程)
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

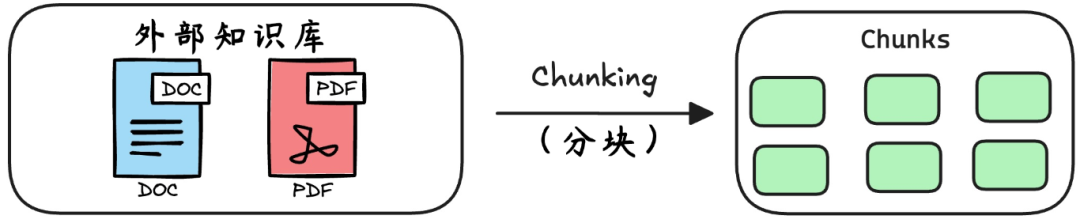
1.分块
第一步是将这些外部资料拆分成chunk(块),比如一份 500 页的产品手册,RAG 会按规则将其拆成小块。分块时会保留上下文连贯性,确保每个块都是完整的 “知识碎片”。
为什么必须分块?
✨输入尺寸限制,模型也有“进食”上限:如果不分块,直接喂一本数万字的文档,模型会 “噎住”(超出输入限制),可能只处理的部分内容,后面的知识全漏了。
✨检索精度需求,避免大海捞针:不分块的话,就像在一整本书里翻找特定段落,没有明确的 “页码” 定位,想找某段内容难上加难。
✨理解效率提升,小块知识更好消化:每个块只包含一个核心知识点,模型处理时不会被其他无关内容干扰。
下面是几个主流的分块策略:
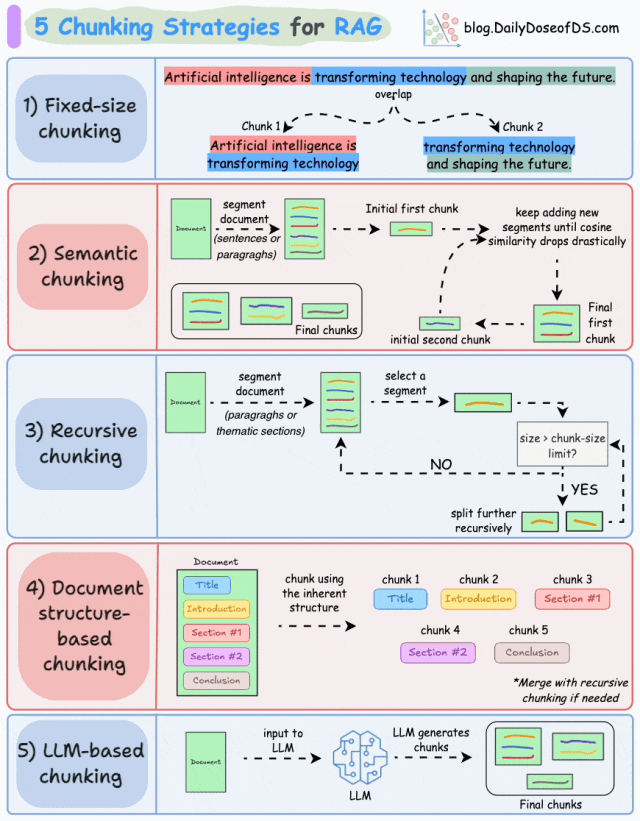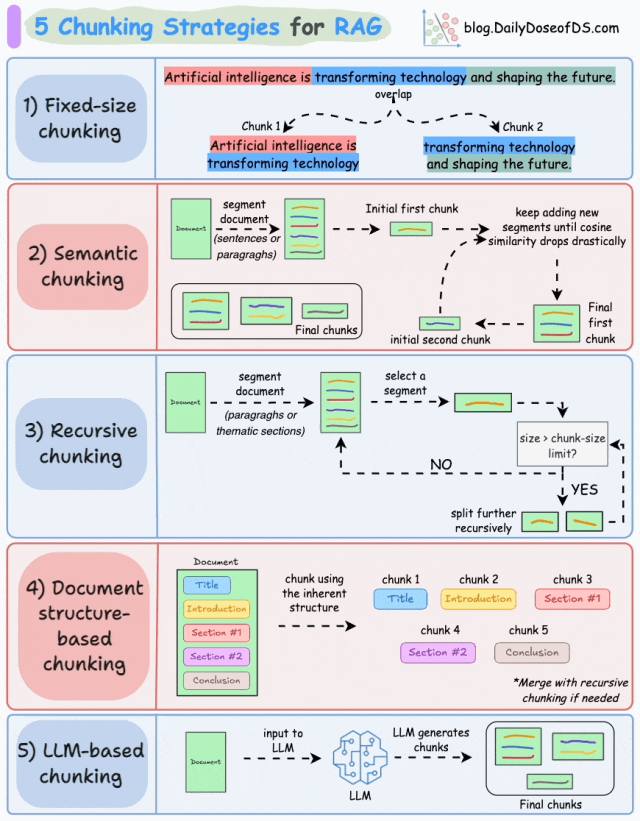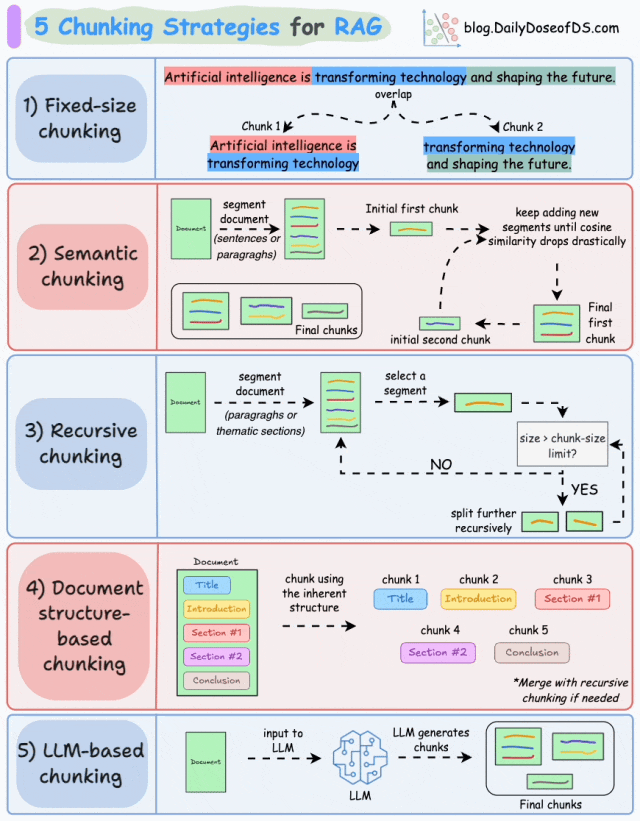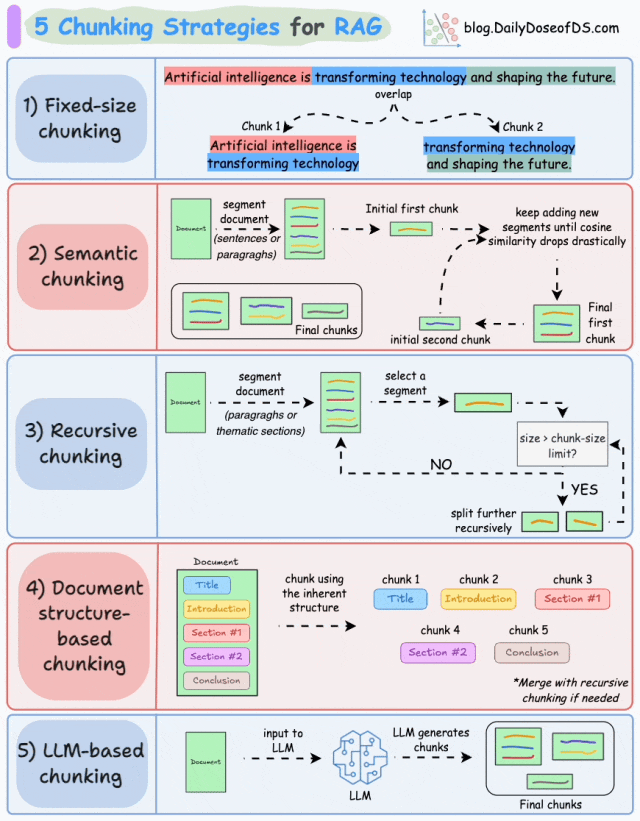
-
固定大小分块(Fixed-size chunking)是一种将文本划分为均匀长度的段的策略, 例如按预定义的字数或token数划分,文档可能会被拆分成每段 200 个单词的块。
-
基于语义的分块(Semantic chunking)是一种按照含义(主题转换、逻辑转折等)对文本进行分块的策略。通过计算相邻文本单元的语义相似度变化,识别“语义断点”。
-
递归分块(Recursive chunking)是根据固有分隔符(如段落、章节等)进行分块。如果每个块的大小超出了预定义的大小,则将其拆分成更小的子块,直到每个子块满足预设的长度或语义完整性要求。
-
基于文档结构的分块(Document structure-based chunking)利用文档的天然格式或逻辑结构进行分块,核心思想是将文档的物理结构(如标题、章节)或逻辑结构(如操作流程中的步骤)作为分块边界,确保拆分后的子块保留完整的语义单元。
-
基于LLM的分块(LLM-based chunking)是指利用LLM的语义理解能力来动态确定文本分块边界,通过模型对文本语义的深层理解实现更精准的分块。
除此之外还有很多其他的切分方式,但最终都需要把文本切分成多份小块。
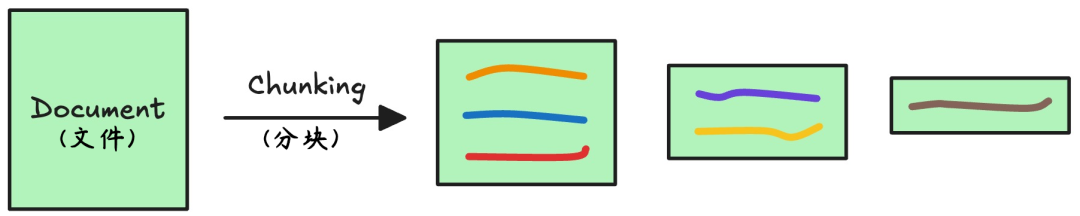
2.文本块向量化
在RAG流程里,把长文本切成小块后,这些文本块对机器来说还是乱码,这时候需要将其转换为机器可理解的格式。
向量化(Embedding)就是将文本或数据转换为向量的过程。模型经过训练后,这些向量可以捕捉到文本的语义信息,使得相似的文本在向量空间中距离较近,这样检索系统可以基于这些向量进行高效的相似度搜索。
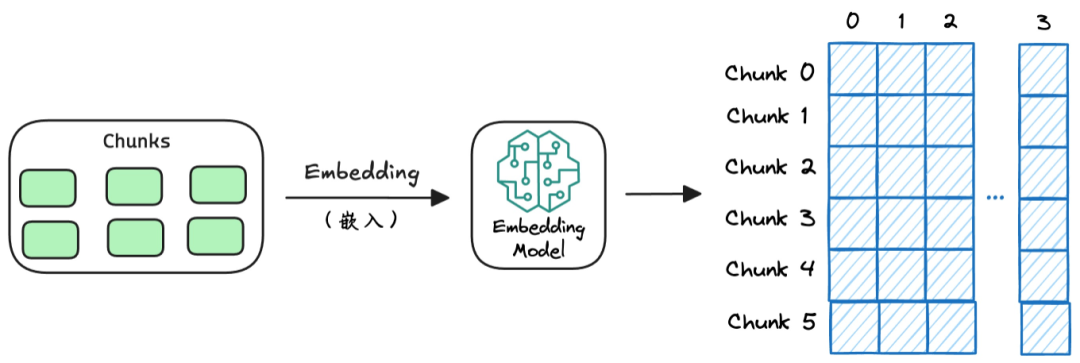
*关于向量化的内容可阅读《说人话之什么是Token?》
3.将向量存储在向量数据库
向量数据库是用于存储和查询向量的数据库。文本块向量化后,就会与原始内容、元数据(如文本块 ID、来源文档、创建时间等)一起被存储到向量数据库中。
假设向量是图书馆里的书,语义信息是每本书的内容,那么向量数据库就是专门为其设计的智能图书馆。
-
传统数据库像老式图书馆,只能按书名(关键词)找书;
-
向量数据库像智能图书馆,能根据书的主题(语义)分类,比如“想找养猫的书”,它会自动把涉及 “猫粮”“猫砂”的书都找出来 ,因为这些词在向量空间里是 “邻居”。
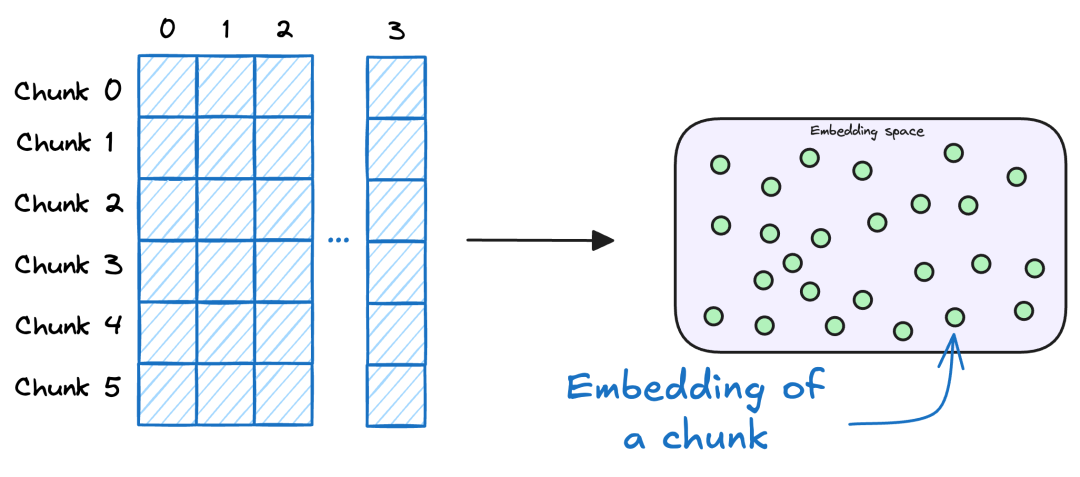
向量数据库充当了 RAG 应用的内存,是存储所有附加知识的地方,通过这些知识,模型可以回答用户的查询。
至此,向量数据库已创建完毕,信息也已添加。
现在,进入模型回答部分。
回答部分(检索与生成流程)
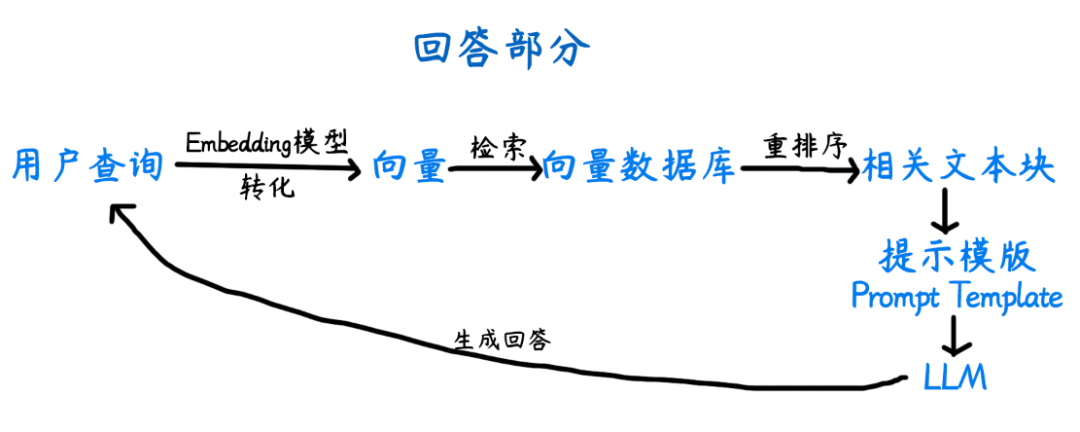
4.用户查询
接下来,用户输入一个查询,比如:“常州能打破0进球魔咒吗?”
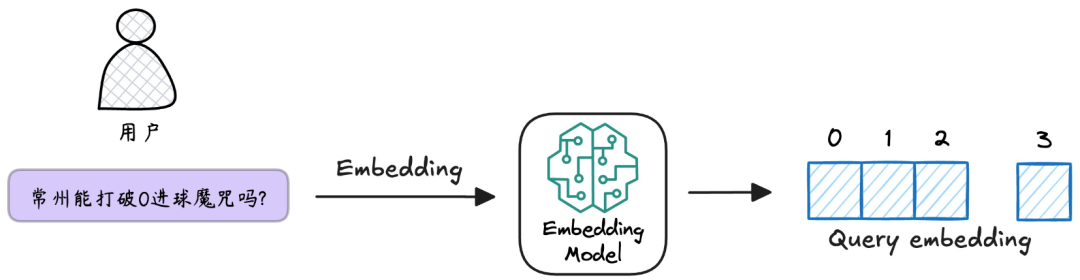
5.将查询向量化
与准备部分中的文本块向量化步骤一样,使用相同的Embedding模型,将用户查询“常州能打破0进球魔咒吗?”转换为向量。
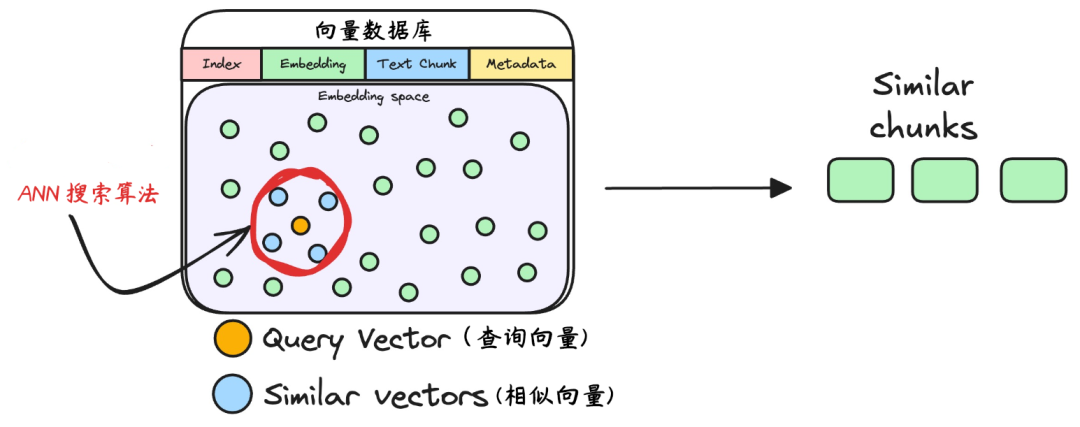
6.检索相似的块
将用户查询转换为向量后,系统需要在向量数据库中快速找到语义最接近的文本块。这个过程本质上是向量相似度检索,用搜索算法检索查询向量与库中所有向量的 “距离”,距离越近,语义越相似。
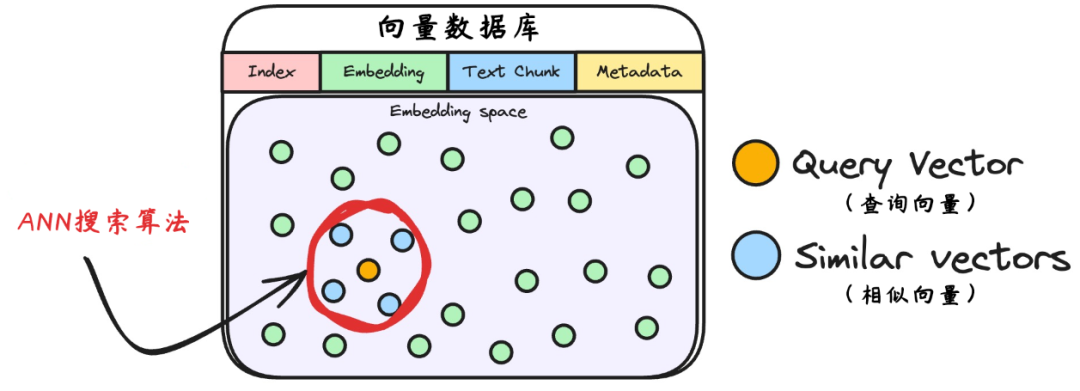
像KNN(K最近邻)等传统的最近邻搜索算法会遍历所有数据点,计算目标向量与库中每个向量的距离,并严格按距离排序,选取最近的 K 个样本。
但向量数据库可能存在百万级甚至上亿向量,若每次都遍历所有向量计算距离,效率极低。如何避免 “暴力比对所有向量” 的低效操作呢?
ANN(近似最近邻)算法采取“抓大放小”策略,牺牲少量精度以换取速度提升。ANN通过 “空间分区 + 快速导航” 机制,将海量向量的搜索范围 “剪枝” 到局部区域,避免全局遍历,降低搜索复杂度。
接下来,向量数据库返回与用户查询相关的文本块,为最终的生成提供基础。
7.重排序
检索阶段就像海选,捞出一堆 “可能相关” 的块,这些块还需要重排序(Re-ranking),以确保最相关、最优质的文档被优先提供给生成模型。该过程依赖编码器模型为检索到的每个块分配相关性分数。
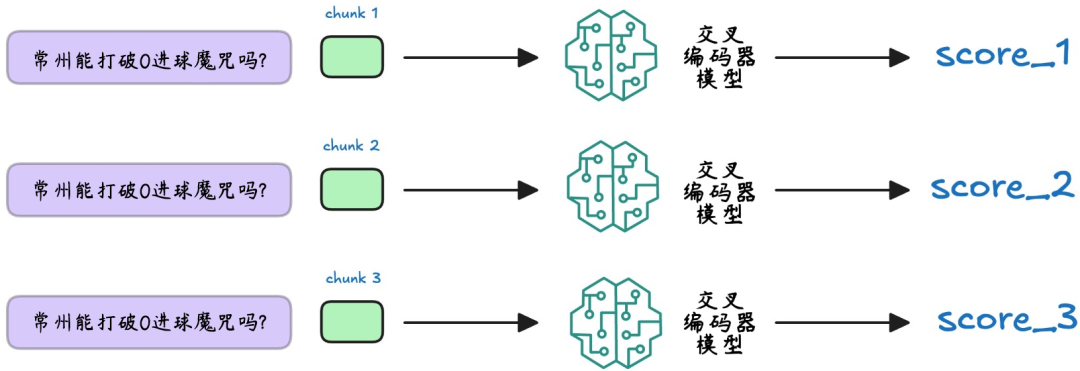
双编码器(Bi-Encoder)和交叉编码器(Cross-Encoder)是两种主要的编码器类型。
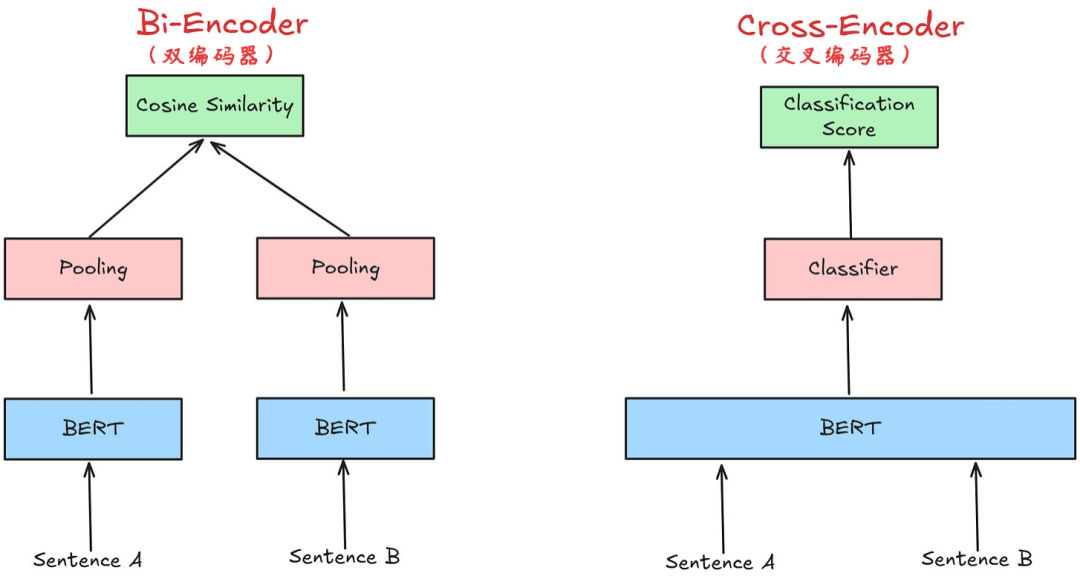
双编码器通过独立的查询编码器和文档编码器,分别将用户查询与文档编码为向量,通过向量相似度计算获取计算其相关性,该方法效率高但仅能捕捉表层语义;交叉编码器将查询和文本块作为整体输入,通过全注意力机制捕捉深层语义交互,直接输出相关性分数。这种方法能捕捉深层语义关联,精度更高但处理速度较慢。
在 RAG 重排序中,交叉编码器通过牺牲部分效率换取语义匹配精度,成为优中选优的核心方案。
8.生成最终响应
当重排序后的高相关文本块准备就绪,LLM 将进入“知识拼图”环节,把用户问题与精选出来的文本块按“提示模板(Prompt Template)”组合,生成融合外部知识的精准回答。
“提示模板”是一个固定格式,把用户问题和精选资料按顺序排列,形成LLM能理解的输入格式。
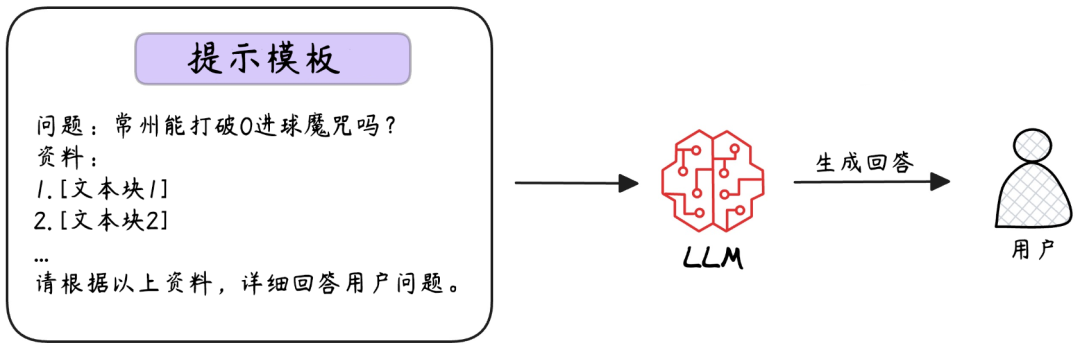
生成最终响应是 RAG 系统的“知识变现”环节,LLM 在此扮演三重角色:
- 信息融合者:将碎片化知识块与问题深度整合,避免照搬资料的生硬感;
- 逻辑编排者:按人类认知习惯重组信息(如时间顺序、重要性排序);
- 表达优化者:将专业术语转化为易懂语言,同时保留关键数据准确性。
从知识分块的 “抽丝剥茧”,到嵌入向量的 “语义编码”,再到检索重排的 “沙里淘金”,最终通过 LLM 完成知识的 “有机生成”。至此,RAG的工作流程就完成了。
真正的模型“顶流”从不依赖 “人设” 行走江湖,得有随时更新、知错就改的真本事,这才是“顶流”保证长红不衰的硬实力。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

{kind=link}
所有评论(0)