WebRTC音频模块详细介绍第一部分-整体介绍
音频模块是WebRTC非常重要的部分,音频模块中的NetEq是WebRTC的三大核心技术(NetEq/GCC/音频3A)之一,我们分四部分介绍该模块,本文是第一部分(整体介绍)。另外三部分分别介绍发送端、接收端、QoS。ADM:Audio Device Module,音频设备模块;APM:Audio Processing Module,音频处理模块;ACM:Audio Control Module
1. 前言
音频模块是WebRTC非常重要的部分,音频模块中的NetEq是WebRTC的三大核心技术(NetEq/GCC/音频3A)之一,我们分七部分介绍该模块,本文是第一部分(整体介绍)。这个专题包括:
- WebRTC音频模块详细介绍第一部分-整体介绍
- WebRTC音频模块详细介绍第二部分-发送端
- WebRTC音频模块详细介绍第三部分-接收端
- WebRTC音频模块详细介绍第四部分-NetEq核心原理
- WebRTC音频模块详细介绍第五部分-NetEq音频决策
- WebRTC音频模块详细介绍第六部分-NetEq数字信号处理
- WebRTC音频模块详细介绍第七部分-体验保障
2. 音频模块整体流程介绍
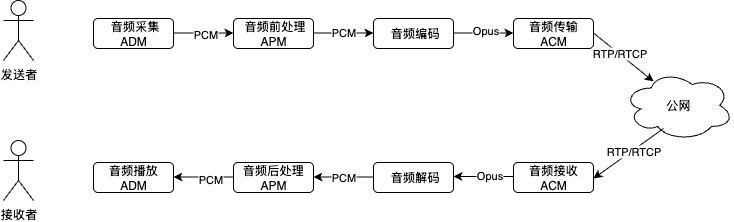
WebRTC音频模块的整体流程如上图所示,包括发送者(生产者)和接收者(消费者)两部分,涉及三个模块:
- ADM:Audio Device Module,音频设备模块;
- APM:Audio Processing Module,音频处理模块;
- ACM:Audio Control Module,音频控制模块。
ADM具体包括:
- 硬件采集:通过系统API(如Windows的WASAPI、Android的AudioRecord)捕获麦克风音频,采样率默认48kHz,位深16bit。
- 格式转换:将原始音频数据转换为统一的PCM格式(16位线性PCM),并重采样到WebRTC支持的采样率(如8kHz、16kHz、32kHz);
APM是WebRTC音频质量的核心,包含以下关键子模块:
- 发送端的子模块:
- 回声消除(AEC):消除扬声器播放的声音被麦克风回采的回声。WebRTC默认使用AEC3,基于自适应滤波和频域LMS算法,动态补偿延迟(最大支持128ms),适用于48kHz采样率。
- 噪声抑制(ANS):过滤背景噪声(如键盘声、空调噪音)。WebRTC基于谱减法或Wiener滤波,提升信噪比(SNR)可达15dB。
- 自动增益控制(AGC):归一化音量,避免音量过载或过低。WebRTC将音量统一至-18dBFS±3dB范围内
- 静音检测(VAD):检测语音活动,静音时段停止发送数据以节省带宽。WebRTC通过能量和频谱特征判断语音是否活跃,用来支持DTX(不连续传输),静音期码率可降至0。
- 接收端的子模块:
- 混音:对解码后的音频数据进行多路混音。
ACM重点和网络打交道,动态适应复杂的网络状况,包括:
- NetEq模块:接收端的网络均衡器,处理抖动、丢包和延迟。通过抖动缓冲(Jitter Buffer)平滑网络抖动,延迟控制在40ms~200ms;通过丢包隐藏(PLC),以插值或预测算法生成缺失的音频数据;通过时间戳调整,同步音频流与播放时钟。
- QoS模块:包括GCC/Pacer/NACK/RED/Opus In-Band FEC。
WebRTC默认采用Opus实现音频的编码和解码,同时支持G.711、G.722。Opus是一款性能优异的开源音频Codec,支持多种类型的采样率、声道、编码周期和码率,具备在音质、时延、码率(带宽成本)、CPU开销诸方面Tradeoff的能力,Opus的灵活性使其能在低延迟实时通信和高保真音乐流之间无缝切换,成为WebRTC的音频核心引擎。
3. WebRTC的音频网络对抗概述
WebRTC的音频网络对抗同时体现在发送端(生产端)和接收端(消费端)上,具体如下:
3.1. 发送端的音频网络对抗
发送端的音频网络对抗由两部分组成,一部分是Opus带来的,另一部分是QoS模块带来的。Opus在音频网络对抗上的具体策略如下:
- 根据不同的采样率、声道数、音质要求设置不同的码率。码率越低,网络适应性越好,弱网和丢包对抗能力越强(码率越低,相同冗余度下冗余数据占用的带宽也越少)。具体公式为:
- 音频原始码率 = 采样率*位深(16-bit)*声道数*压缩率。例如:48kHz采样率+16-bit位深+立体声(2声道)的原始PCM数据为48,000 × 16 × 2= 1,536,000 bps (≈1.5 Mbps)。Opus编码时将此原始数据压缩到目标码率64kbps,此时压缩率为1536/64=24。
- Opus拥有带内FEC,支持CBR/VBR,并支持DTX,具体如下:
- 带内 FEC:OPUS 编码器可以生成带内FEC,当有丢包时,可以通过FEC信息部分恢复丢失的信息。代价是带内FEC会增大音频实际占用的带宽;
- DTX:当要编码的数据长期为空数据时(通常出现在主动静音的情况下),可以生成 DTX 包来降低码率;
- CBR/VBR:Opus支持CBR和VBR两种模式。为了更准确地分配带宽(为音频、视频、冗余包、丢包重传基于权重分配带宽)以及实现上的便利性,WebRTC使用CBR模式,此时音频码率是固定的;
Opus编码作用在信源上,QoS模块作用在物理信道上。根据网络带宽、RTT、丢包率,QoS模块启用不同的策略,设置音频实际发送的网络带宽,具体公式为:
- 音频网络带宽 = Opus带内FEC增加的码率(如有)+音频原始码率 * 冗余度 + 音频原始码率*丢包率。冗余度通过前向纠错机制RED实现,丢包重传则通过后向纠错机制NACK实现。
注意:在实际应用中,重传包可能会丢失,所以丢包重传带来的额外带宽会大于音频原始码率*冗余度。
QoS模块根据BWE给出的带宽评估值乘以一个系数,给出最终的流媒体发送速率,这个过程称为Pacer。Pacer将不均匀的输入码率经过滤波后调整为均匀的输出码率,使得发送到网络中的媒体流的带宽保持相对平稳,从而降低对网络的压力,进而提升通话的流畅度。发送端输入码率的不均匀性由多个因素引入,包括视频码流的变化、FEC&RED冗余度的调整、丢包率的变化以及静音、关闭视频流等业务操作。
Pacer会对音频和视频(如有)做统筹,我们放在单独的章节讲述。
3.2. 接收端的音频网络对抗
接收端的音频网络对抗包括Opus带内FEC的解码(如有)、RED的响应、丢包重传的响应(通过NACK机制)以及NetEq。这4部分我们会有独立的章节讲述。
3.3. 音频网络对抗算法的对比
|
业界常用的音频网络对抗算法的对比 |
|||||
|
物理信道FEC |
Opus带内FEC |
RED |
NACK |
NetEq PLC |
|
|
额外延迟 |
以Group为单位编码冗余帧时引入额外延迟,解码侧也有对应的延迟,整体延迟为单向延迟乘以2 |
编码冗余帧引入额外延迟,解码侧也有对应的延迟,整体延迟为单向延迟乘以2 |
编码冗余帧引入额外延迟,解码侧也有对应的延迟,整体延迟为单向延迟乘以2 |
N倍RTT的传输延迟。N是实际重传次数。 |
不引入延迟 |
|
生效时机 |
前向纠错,编码后、网络发送之前引入 |
前向纠错,在音频编码时引入 |
前向纠错,在网络发送之前引入 |
后向纠错,在接收端引入 |
在接收端生效 |
|
适用范围 |
随机丢包、RTT较大时。丢包率高时通过提升冗余度对抗。 |
丢包率低、非连续丢包时。 |
随机丢包、RTT较大时。丢包率高时通过提升冗余度对抗。 |
突发丢包或持续丢包、RTT较小时。 |
丢包率低时。高丢包下PLC会导致语音信号过度拉升,引起听感上的不适。 |
The End.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)