SPSS数据分析从小白到高手-案例:药物临床效果K均值聚类
药物投入市场前需要进行临床前的研究,该阶段的主要内容为药学、药剂学、药理、毒理学的研究。对于具有选择性药理效应的药物,在进行临床试验前还需要测定药物在动物体内的吸收、分布及消除过程,在经药物管理部门的初步审批后才能进行临床试验,目的在于保证人们用药的安全。
1.案例数据简介
药物投入市场前需要进行临床前的研究,该阶段的主要内容为药学、药剂学、药理、毒理学的研究。对于具有选择性药理效应的药物,在进行临床试验前还需要测定药物在动物体内的吸收、分布及消除过程,在经药物管理部门的初步审批后才能进行临床试验,目的在于保证人们用药的安全。
新药研发是一个耗时、耗资的系统工程,完成前期的基础研究(药理、毒理、药效等动物研究)后开始申请进入人体临床试验阶段。进行代谢相关的药物相互作用研究的重要目的在于探索新药是否有可能对已上市的,并可能在医疗诊治中合用的药物代谢消除产生显著影响。
源数据字段及其字典包括性别:1-F,0-M;血压:2-HIGH、1-LOW、0-NORMAL;类胆固醇含量:1-HIGH、0-NORMAL;药物类型:1-drugA、2-drugB、3-drugC、4-drugX、5-drugY。
在SPSS的变量视图中,建立“Age”、“Sex”、“BP”、“Cholesterol”、“Na”、“K”和“Drug”7个变量,分别表示试用患者的年龄、性别、血压、类胆固醇含量、Na含量、K含量和药物类型,如图7-6所示。
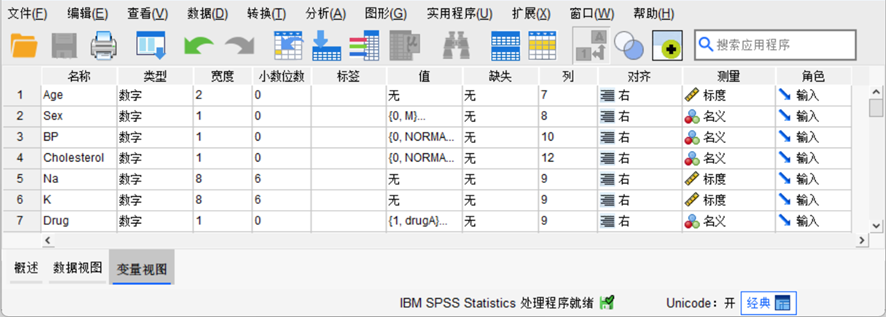
图7-6 数据文件变量视图
在SPSS中,把相关数据输入到各个变量中,输入完毕后数据视图如图7-7所示。
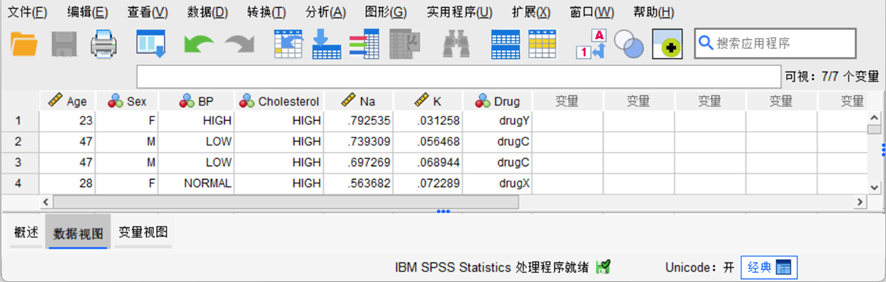
图7-7 数据文件数据视图
2.案例操作步骤
在菜单栏中依次选择【分析】|【分类】|【K-均值聚类】选项,打开“K均值聚类分析”对话框。
从源变量列表中选择“Age”、“BP”、“Cholesterol”、“Na”、“K”和“Drug”变量,单击向右的箭头按钮将它们选入“变量”列表中,“Sex”选入“个案标注依据”列表中。
在“聚类数”输入框中输入聚类的数目,本案例将变量分为5类。
单击“选项”按钮,选择“每个个案的聚类信息”复选框,单击“继续”。
单击“确定”按钮,便可进行快速聚类分析。
3.案例结果分析
单击“确定”按钮后,输出快速聚类分析的结果,如图7-8至图7-11所示。
图7-8给出了每一次迭代的聚类中心内的更改情况。我们可以看出,经过6次迭代,聚类中心达到收敛。
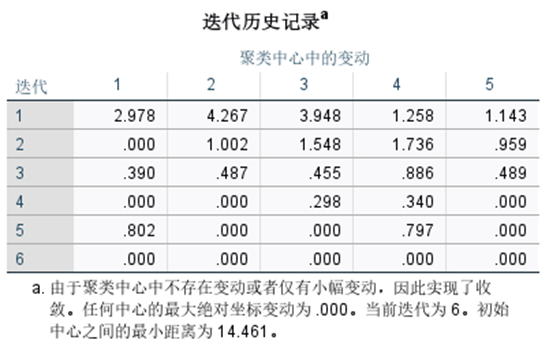
图7-8 迭代历史记录
图7-9和图7-10给出了最终聚类的中心和最终聚类中心间的距离。
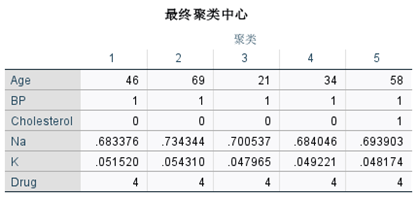
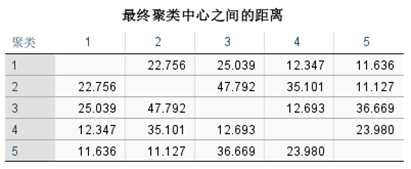
图7-9 最终聚类中心 图7-10 最终聚类中心间的距离
图7-11给出了每一个观测所属的类和每个聚类中的案例数。通过聚类分析我们可以看出,所有的观测按照与聚心的距离被分成了5类。
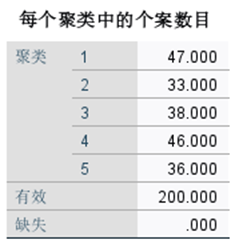
图7-11 聚类成员


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)