ICML 2025 | 标点符号影响LLM记忆能力,微调处理带来显著性能提升
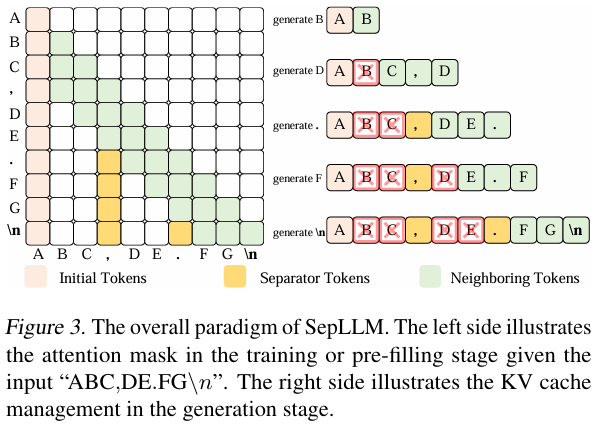
本文旨在解决 Transformer 长序列推理时 KV 缓存随长度二次膨胀的问题。作者发现分隔符 token(如“.”、“,”)在注意力中权重显著高于语义 token,推测其已将所在片段信息压缩于自身。据此提出SepLLM:一种仅保留aaa个)、(全部)与nnn个)KV 的稀疏注意力机制;其余 token 在注意力中被掩码。
一、导读
Transformer 架构在语言建模任务中已展现出卓越性能,但其自注意力模块的计算复杂度随序列长度呈二次增长,严重限制了长序列推理与训练的实用性。现有稀疏注意力或 KV 缓存压缩方法要么引入与预训练权重不兼容的结构修改,要么仅在推理阶段生效,导致训练-推理分布漂移。
本文通过可视化大模型内部注意力分布,发现看似无意义的标点符号(separator tokens)在注意力权重中占据异常高的比例,暗示这些分隔符已将所在片段的全局语义信息压缩至自身。基于此观察,作者提出 SepLLM:一种数据依赖的稀疏注意力框架,仅保留初始 token、邻近 token 以及分隔符的键值(KV)缓存,从而将整段文本“压缩”进单个分隔符。
SepLLM 可作为即插即用模块,无缝嵌入训练、微调或推理阶段,并在 Llama-3-8B 上实现超过 50% KV 缓存压缩率的同时保持与原始模型相当的性能。该工作首次从理论与系统层面证明了“以分隔符为信息瓶颈”的稀疏注意力机制的有效性,填补了训练-推理一致的长文本高效建模空白。
二、论文基本信息

- 论文标题:SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
- 论文链接:https://arxiv.org/abs/2412.12094
- 项目链接:https://sepllm.github.io
三、摘要
本文旨在解决 Transformer 长序列推理时 KV 缓存随长度二次膨胀的问题。作者发现分隔符 token(如“.”、“,”)在注意力中权重显著高于语义 token,推测其已将所在片段信息压缩于自身。据此提出 SepLLM:一种仅保留 initial tokens( a a a 个)、separator tokens(全部)与 neighboring tokens( n n n 个)KV 的稀疏注意力机制;其余 token 在注意力中被掩码。对于流式场景,进一步提出“Tailored Streaming Design”,将 KV 缓存动态划分为初始缓存、分隔符缓存、局部窗口缓存与历史窗口缓存,使得无限长序列的平均 KV 占用收敛至 w + c + a + s 2 < c \frac{w + c + a + s}{2} < c 2w+c+a+s<c。实验表明,在 Llama-3-8B 的 GSM8K-CoT 任务上,SepLLM 在 KV 缓存减少 52.64% 的同时准确率保持 77.18(vanilla 77.79);在 4 M token 流式输入场景下,困惑度显著低于 StreamingLLM,且首次实现了训练-推理一致的压缩。
四、研究背景与相关工作
Transformer 自注意力计算复杂度为 O ( m 2 ) O(m^2) O(m2),其中 m m m 为序列长度。已有两条主流解决路线:
- 线性注意力(Katharopoulos et al., 2020; Schlag et al., 2021)通过核技巧将复杂度降至 O ( m ) O(m) O(m),但需重写注意力算子,无法直接利用预训练权重。
- KV 缓存压缩(Xiao et al., 2024a; Zhu et al., 2024)在推理阶段基于注意力分数或启发式规则丢弃 KV,但训练阶段仍保留全部 KV,导致训练-推理不一致。StreamingLLM(Xiao et al., 2024b)保留 attention sinks 与局部窗口,虽支持无限长输入,但丢弃大量中间 token,性能下降。
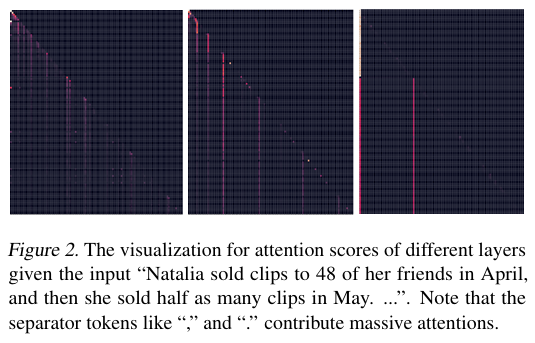
本文通过可视化 Llama-3-8B-Instruct 的注意力图(图 2)发现,逗号、句号等分隔符 token 在多个层/头中获得高达 20% 以上的注意力权重,远高于普通内容词。这一经验现象提示:分隔符已天然作为“信息瓶颈”,可将整段文本压缩进单个 token 表示。以此为核心,SepLLM 不仅在推理阶段稀疏化,更在训练阶段强制模型将片段语义压缩至分隔符,从而首次实现训练-推理一致性压缩。
五、主要贡献与创新
- 现象驱动的新视角:首次系统揭示分隔符 token 在长序列注意力中的关键作用,提出“以分隔符为片段压缩器”的语言建模新范式。
- SepLLM 架构:提出数据依赖的稀疏注意力掩码 M ∈ { 0 , 1 } m × m M \in \{0,1\}^{m \times m} M∈{0,1}m×m,其中
M i , j = 1 ⟺ j ∈ { initial a , separator before i , neighboring n } M_{i,j}=1 \iff j\in\{\text{initial }a,\ \text{separator before }i,\ \text{neighboring }n\} Mi,j=1⟺j∈{initial a, separator before i, neighboring n}
其余位置置 − ∞ -\infty −∞ 经 Softmax 后为零,实现 KV 缓存线性缩减。 - 流式 KV 管理:设计四块缓存(Initial, Separator, Local, Past)及周期性压缩策略,理论证明无限序列的平均 KV 占用上限为 w + c + a + s 2 \frac{w + c + a + s}{2} 2w+c+a+s,确保内存可控。
- 训练-推理一致:提供 training-from-scratch、post-training 两种范式,并基于 FlexAttention 实现硬件高效 Sep-Attention kernel,训练阶段即见 26% 时间加速。
- 理论保证:证明 SepLLM 具备通用近似能力(定理 5.1),对任意连续序列到序列函数 f f f,存在 SepLLM g g g 使得 d p ( f , g ) < ϵ d_p(f,g)<\epsilon dp(f,g)<ϵ。
六、研究方法与原理
6.1 基本公式
对于自注意力层,给定查询 Q ∈ R m × d k Q\in\mathbb{R}^{m\times d_k} Q∈Rm×dk、键 K ∈ R m × d k K\in\mathbb{R}^{m\times d_k} K∈Rm×dk、值 V ∈ R m × d v V\in\mathbb{R}^{m\times d_v} V∈Rm×dv,SepLLM 的稀疏注意力输出为
O = S o f t m a x ( Q K ⊤ d k ⊙ M ) V , O = \mathrm{Softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\odot M\right)V, O=Softmax(dkQK⊤⊙M)V,
其中 ⊙ \odot ⊙ 表示按元素乘, M M M 为上述稀疏掩码。通过仅存储 M i , j = 1 M_{i,j}=1 Mi,j=1 对应的 KV,实现 KV 缓存压缩。
6.2 训练与生成流程
- 训练/预填充阶段:直接对掩码后的 Q K ⊤ QK^\top QK⊤ 执行稀疏矩阵乘法,实现前向与反向传播。
- 生成阶段:将 KV 缓存划分为
- Initial Cache( a a a slots)
- Separator Cache( s s s slots)
- Local Window Cache( w w w slots)
- Past Window Cache(溢出缓存,最终与 Separator Cache 重叠)
当实时占用 Size run = a + s + w + Size past \text{Size}_{\text{run}} = a + s + w + \text{Size}_{\text{past}} Sizerun=a+s+w+Sizepast 达到容量 c c c 时,将 Past 中的 separator KV 迁移至 Separator Cache,其余 KV 丢弃,确保 Size run ≤ c \text{Size}_{\text{run}}\le c Sizerun≤c。
6.3 理论分析
定理 5.1(通用近似):给定 p > 1 , n > 2 p>1,\ n>2 p>1, n>2,对任意 ϵ > 0 \epsilon>0 ϵ>0 与连续函数 f : [ 0 , 1 ] d × n → R d × n f:[0,1]^{d\times n}\to\mathbb{R}^{d\times n} f:[0,1]d×n→Rd×n,存在 SepLLM g ∈ T 2 , 1 , 4 Sep g\in\mathcal{T}_{2,1,4}^{\text{Sep}} g∈T2,1,4Sep 使得
d p ( f , g ) = ( ∫ [ 0 , 1 ] d × n ∥ f ( X ) − g ( X ) ∥ p p d X ) 1 / p < ϵ . d_p(f,g)=\left(\int_{[0,1]^{d\times n}}\|f(X)-g(X)\|_p^p\mathrm{d}X\right)^{1/p}<\epsilon. dp(f,g)=(∫[0,1]d×n∥f(X)−g(X)∥ppdX)1/p<ϵ.
证明基于网格量化、上下文映射与逐层信息传播三阶段构造(见附录 J、K)。
七、实验设计与结果分析
7.1 实验设置
- 模型:Pythia-160M/1.4B/6.9B/12B,Llama-3-8B-Base/Instruct,Falcon-40B
- 数据集:Pile(207 B tokens,训练 from scratch)、GSM8K-CoT、MMLU、PG19、WikiText
- 评测指标:准确率(GSM8K-CoT 8-shot、MMLU 5-shot)、困惑度(PG19, WikiText)、KV 缓存占用比 r.KV(%)、端到端 wall-clock 时间
- 基线:Vanilla full-attention、StreamingLLM、H2O、SnapKV、PyramidKV 等
7.2 关键实验结果
| 场景 | 指标 | Vanilla | StreamingLLM | SepLLM | 备注 |
|---|---|---|---|---|---|
| GSM8K-CoT | 准确率 | 77.79 | 71.42 (n=380) | 77.18 (n=256) | SepLLM KV 47.36% |
| MMLU | 准确率 | 65.72 | 63.39 (n=380) | 64.68 (n=256) | SepLLM KV 44.61% |
| PG19 4M token | ppl | – | 36.1 | 34.5 (s=64) | 同 KV 容量 c=324 |
| 训练 160M | 损失 | 2.60 @143k steps | 2.66 | 2.55 (n=64) | 训练时间 −26% |
| Needle-in-Haystack | 成功率 | – | <50% | >90% | Llama-3-8B 4M ctx |
实验结论:
- 在 KV 缓存减少 50% 左右时,SepLLM 在推理与下游任务上几乎无损;
- 流式场景下,SepLLM 随着序列长度增加,困惑度优势持续扩大;
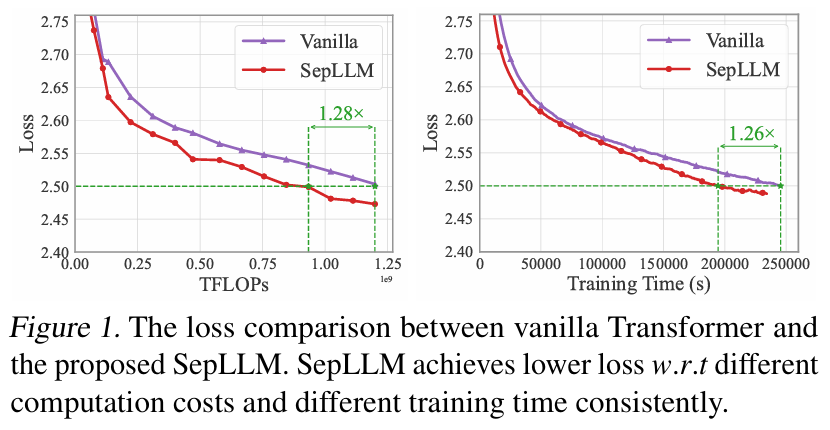
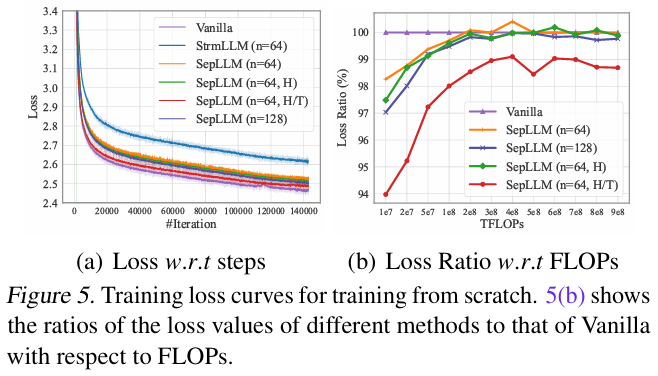
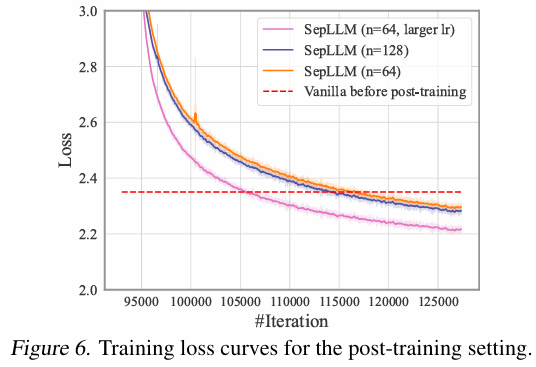
- 训练阶段嵌入 SepLLM 后,收敛速度更快,相同 FLOPs 下损失更低(图 5(b));
- Ablation 显示 separators 是关键:移除后性能显著下降,而仅增加邻近窗口无法弥补。
八、论文结论与启示
本文提出并验证了“分隔符压缩片段信息”的假设,构建了 SepLLM 这一支持训练-推理一致的高效稀疏注意力框架,兼顾理论保证与工程落地。实验表明,SepLLM 在 50% KV 压缩下保持性能,支持 4 M token 流式推理,且训练阶段即可带来 26% 加速。该工作为长文本大模型提供了一种“即插即用”的轻量方案,并启发未来探索更多“语义驱动的稀疏模式”,如句法、篇章结构等。未解决问题包括:
- 如何自适应选择最优分隔符集合;
- 如何与 MoE、量化等压缩技术叠加;
- 多模态场景下分隔符概念的迁移。
九、整体评价与讨论
优点:
- 现象驱动、理论扎实,首次将分隔符作为信息瓶颈系统研究;
- 工程实现完备(Sep-Attention kernel、FlexAttention),支持分布式训练;
- 多场景(training-free, from-scratch, post-training, streaming)验证一致有效。
不足:
- 当前分隔符集合为人工设定,缺乏语言自适应;
- 对中文无空格语言的分隔符定义未深入讨论;
- 未与 Flash-Decoding、PagedAttention 等最新推理库深度融合。
改进建议:
- 引入可学习的“伪分隔符” token,通过端到端训练自动发现最优压缩点;
- 在多语文本、代码、数学公式中验证分隔符概念的普适性;
- 公开更详细的 CUDA kernel benchmark 与 Triton 实现,促进社区复用。
关注下方《AI前沿速递》🚀🚀🚀
各种重磅干货,第一时间送达
码字不易,欢迎大家点赞评论收藏

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)