第八课 制作英语单词卡片
本文介绍了一个随机生成英语单词卡片的智能体开发流程。重点解决了图片格式转换问题,通过循环节点将数组格式转为画板可接受的单张图片格式。整个流程实现了从单词库随机抽取、信息提取到卡片生成的全自动化处理。
思路和效果图
将随机抽取知识库里的一个单词作为主体,围绕它写出音标、含义、例句和例句的图片,最后生成一张单词卡片。

实现
一、单词表
需要找到一个excel格式的单词表,上传到知识库里。
找单词库
https://github.com/KyleBing/english-vocabulary/tree/master/json
链接已贴,感谢很有分享精神的该文作者KyleBing(/撒花)
格式转为excel
找一个在线转格式的网站,贴一下我用的吧:https://wejson.cn/json2excel/,它也很乐意被分享出来

number格式导出为excel
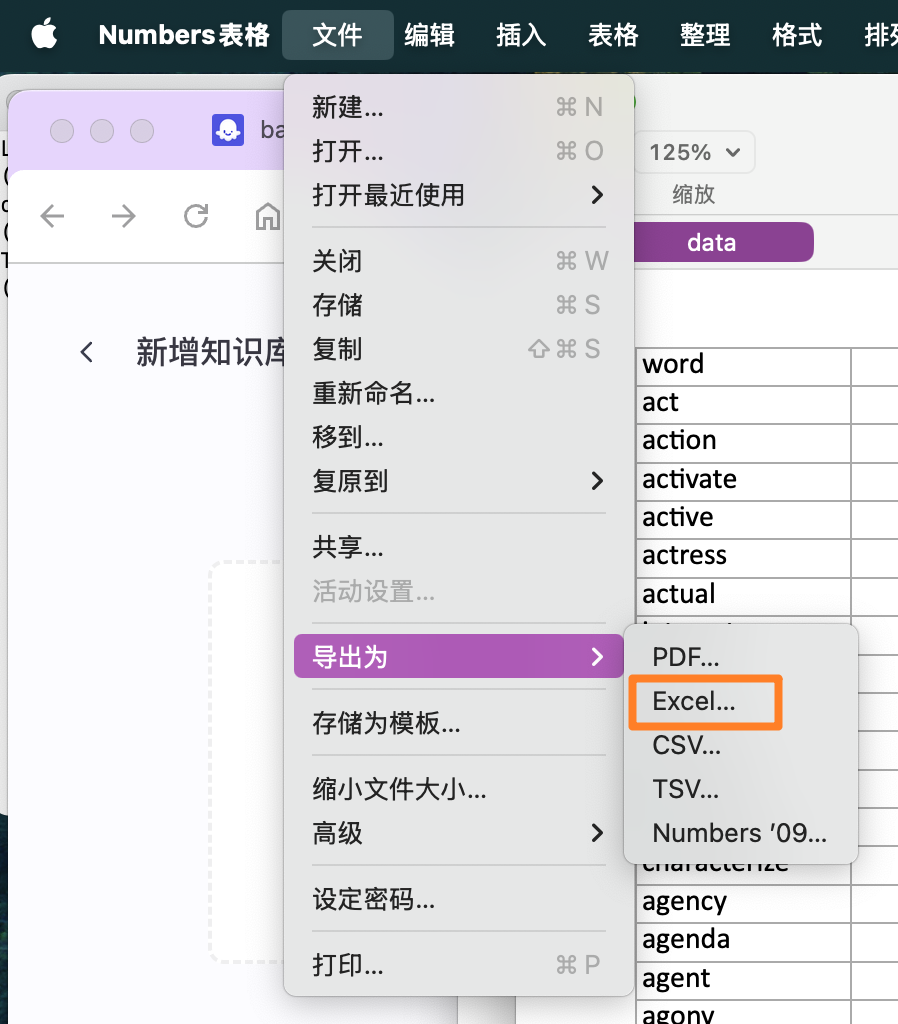
苹果电脑里会自动把下载的excel识别为number,我们点左上角【文件】点【导出为】转为【Excel】格式就好了。
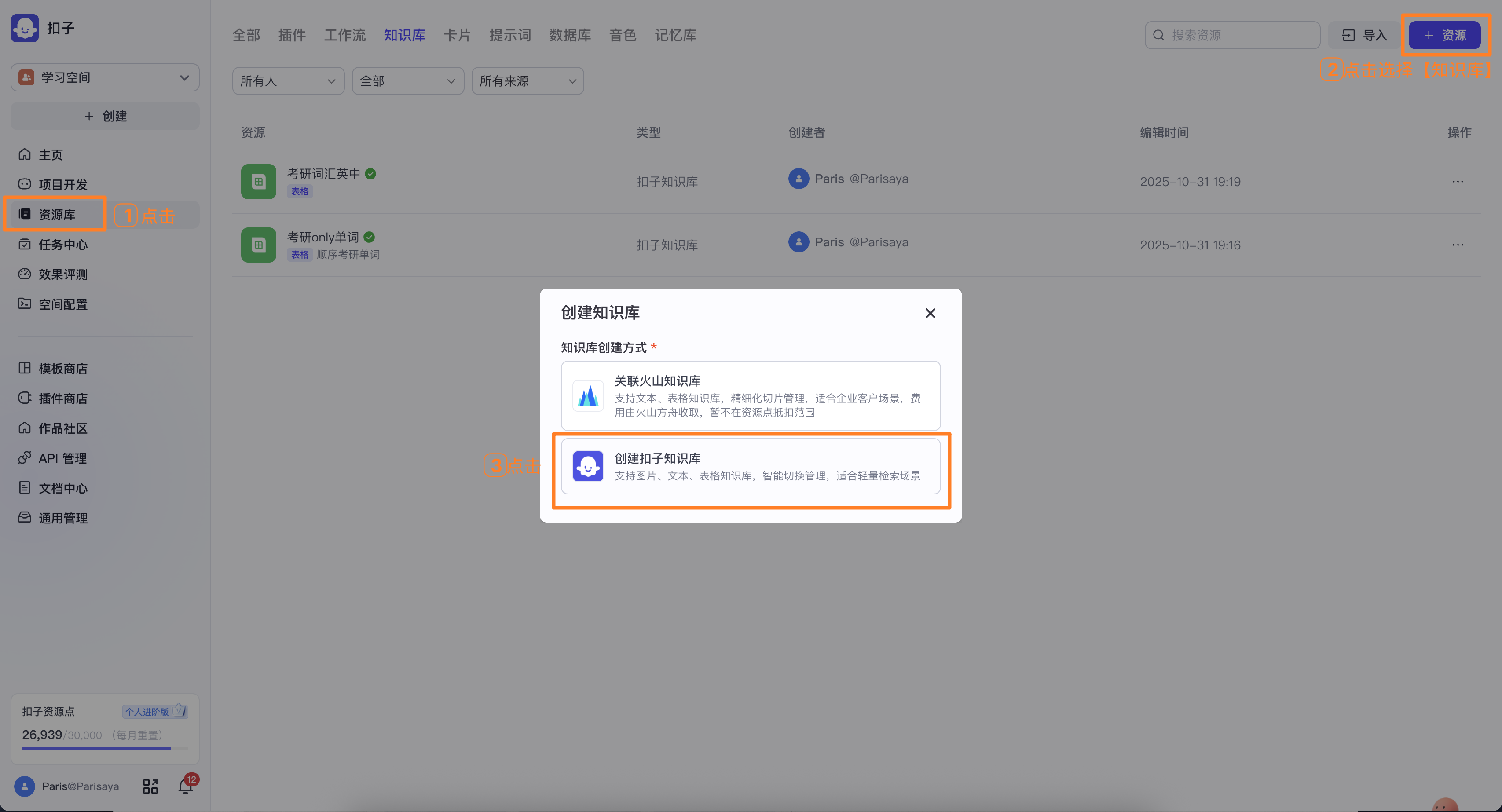
二、创建单词表的知识库
开发平台中,点左栏的【资源库】,右上角点击【资源】选择【创建扣子知识库】
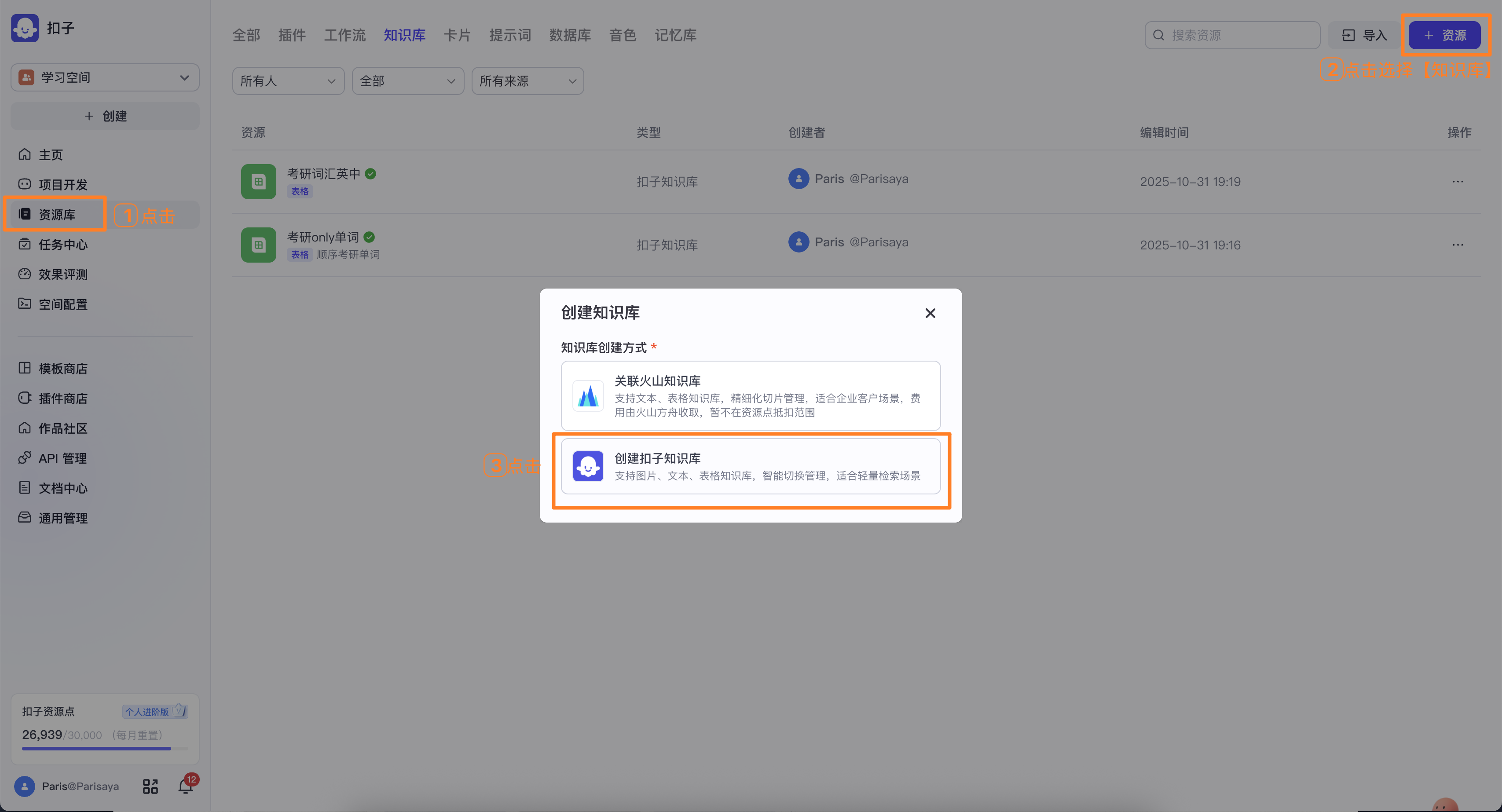
选择【表格格式】,写名称和描述,选【本地文档】,点【创建并导入】
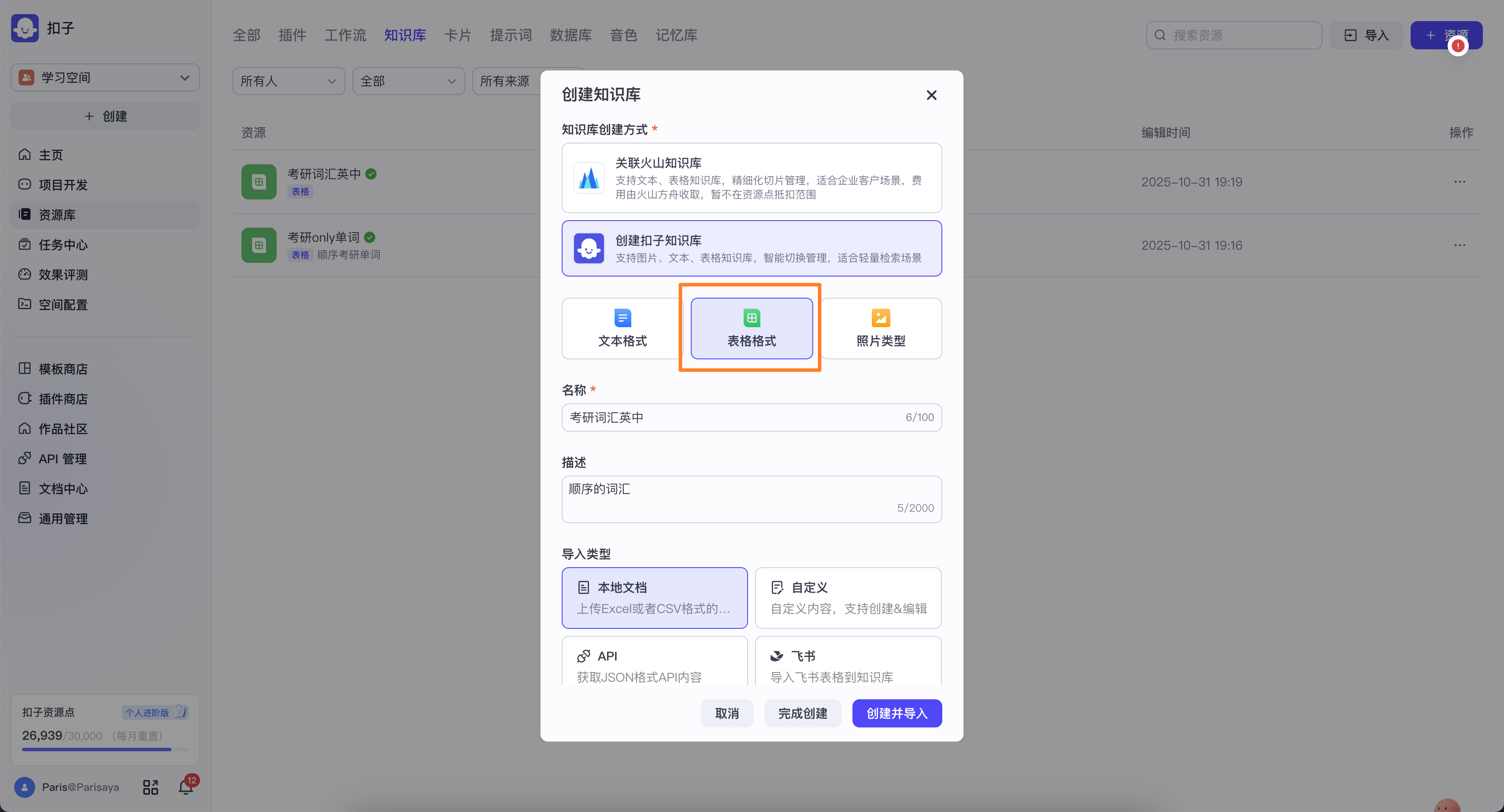
导入单词excel表
选择excel格式的单词表
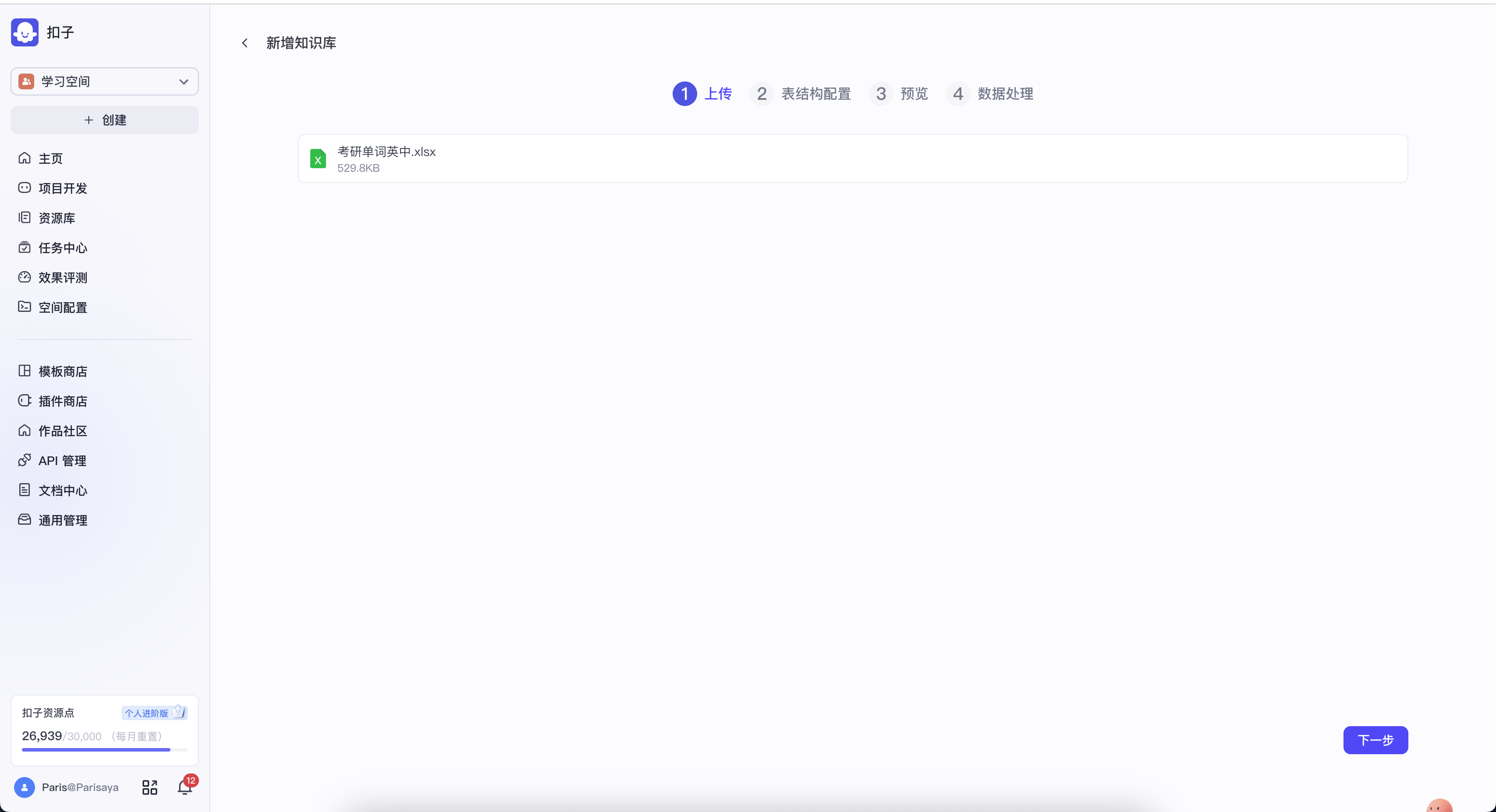
勾选表头的word
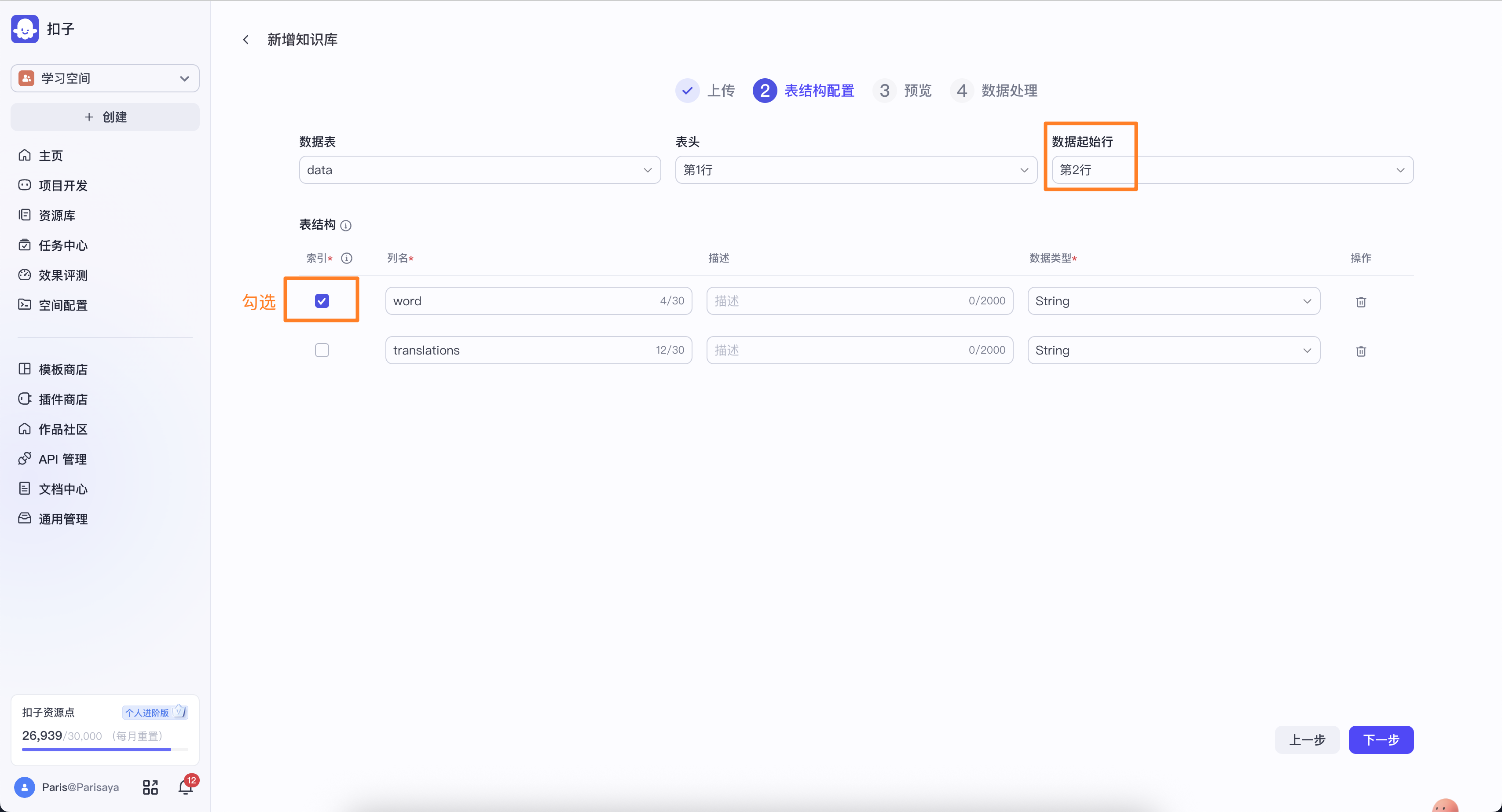
等待数据处理完成后,知识库就可以正常使用了。
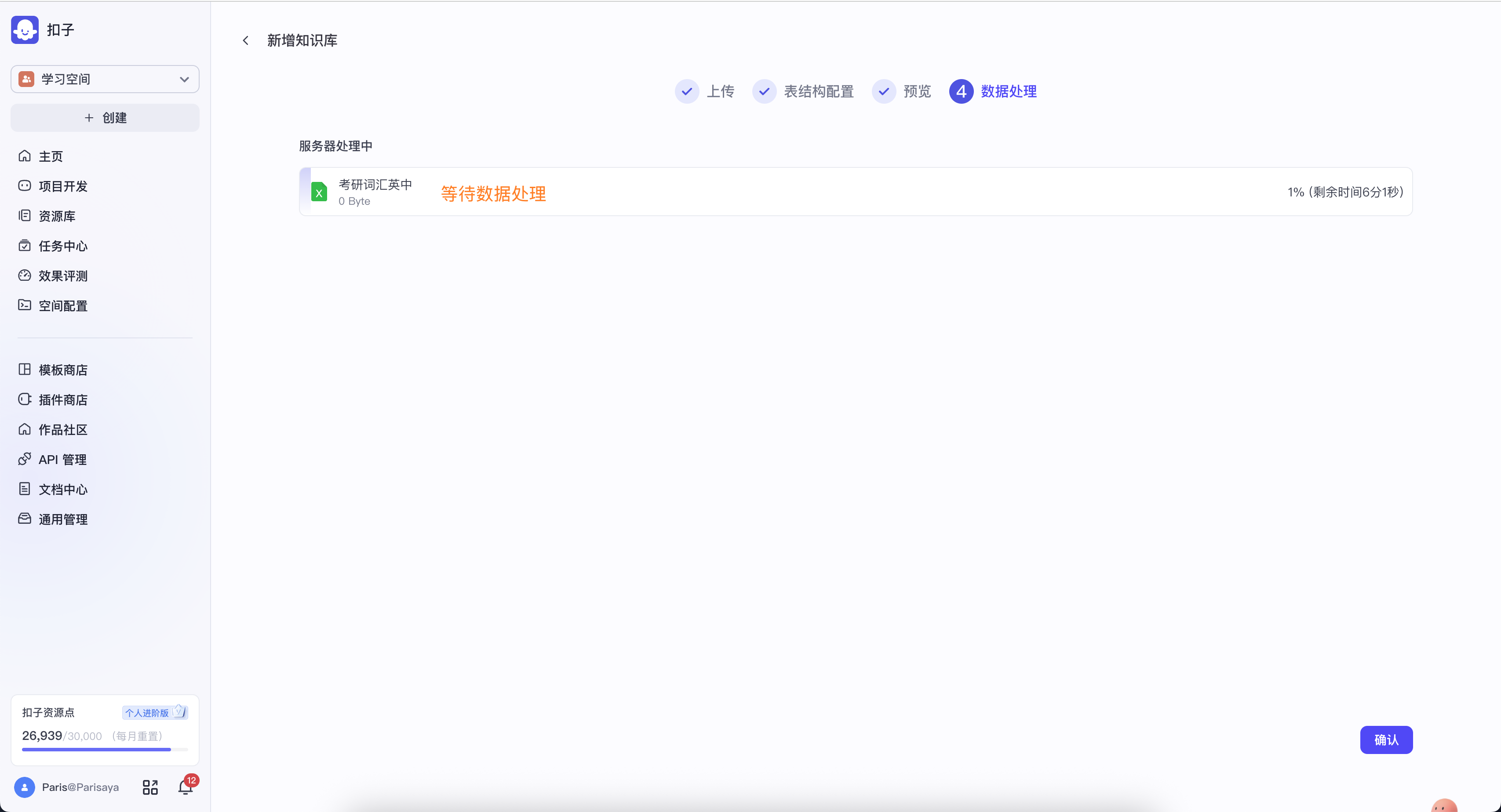
数据较多,处理时间较久,可以点【确认】后做别的。
三、工作流-作图
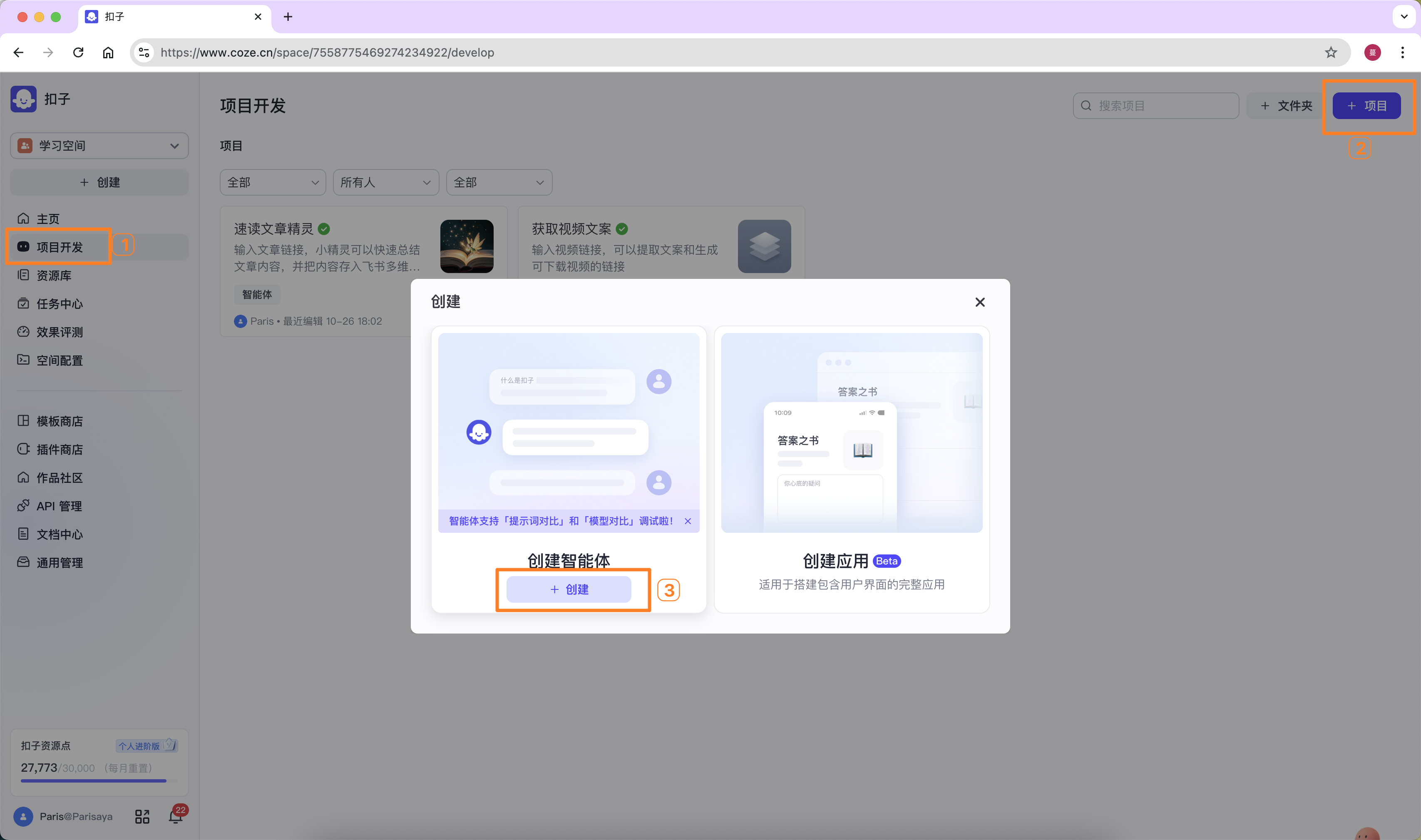
创建智能体
点击左侧【项目开发】,右上角【项目】,选创建智能体,点击【创建】。
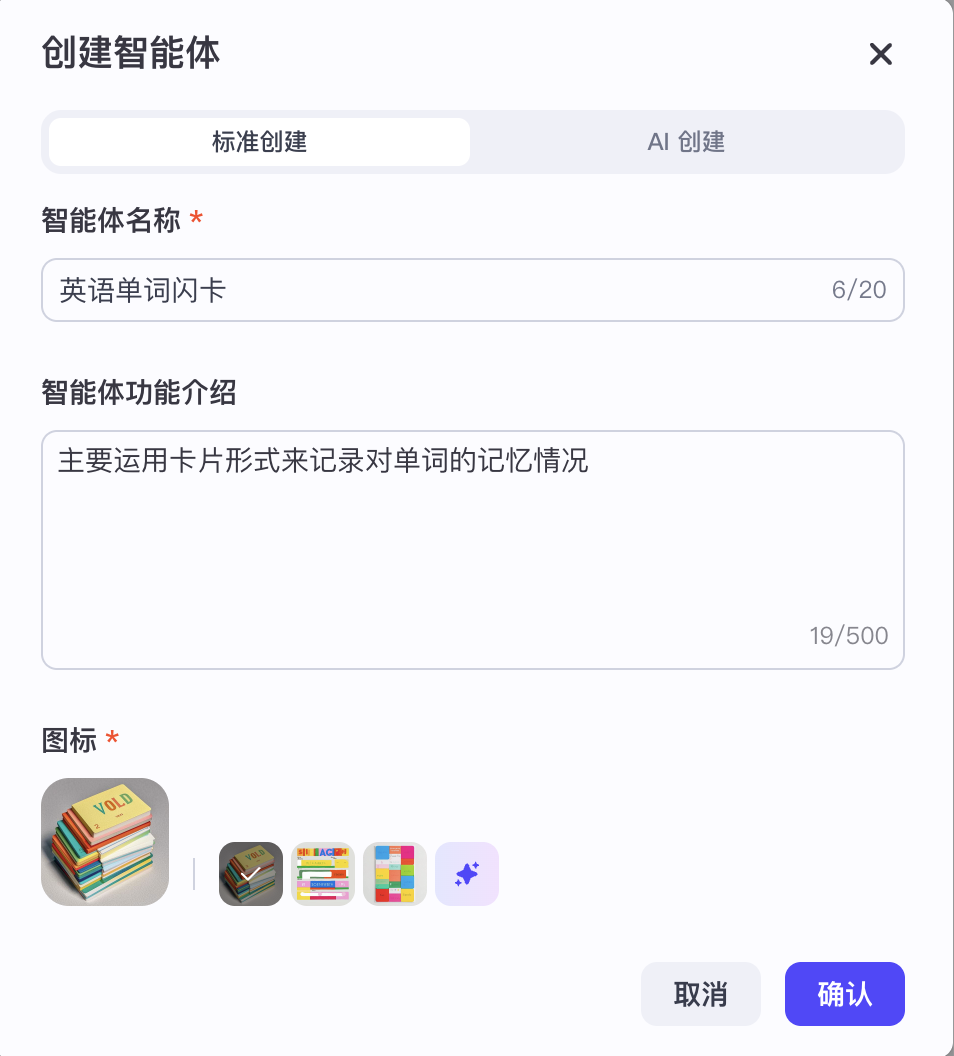
写好名称、功能介绍
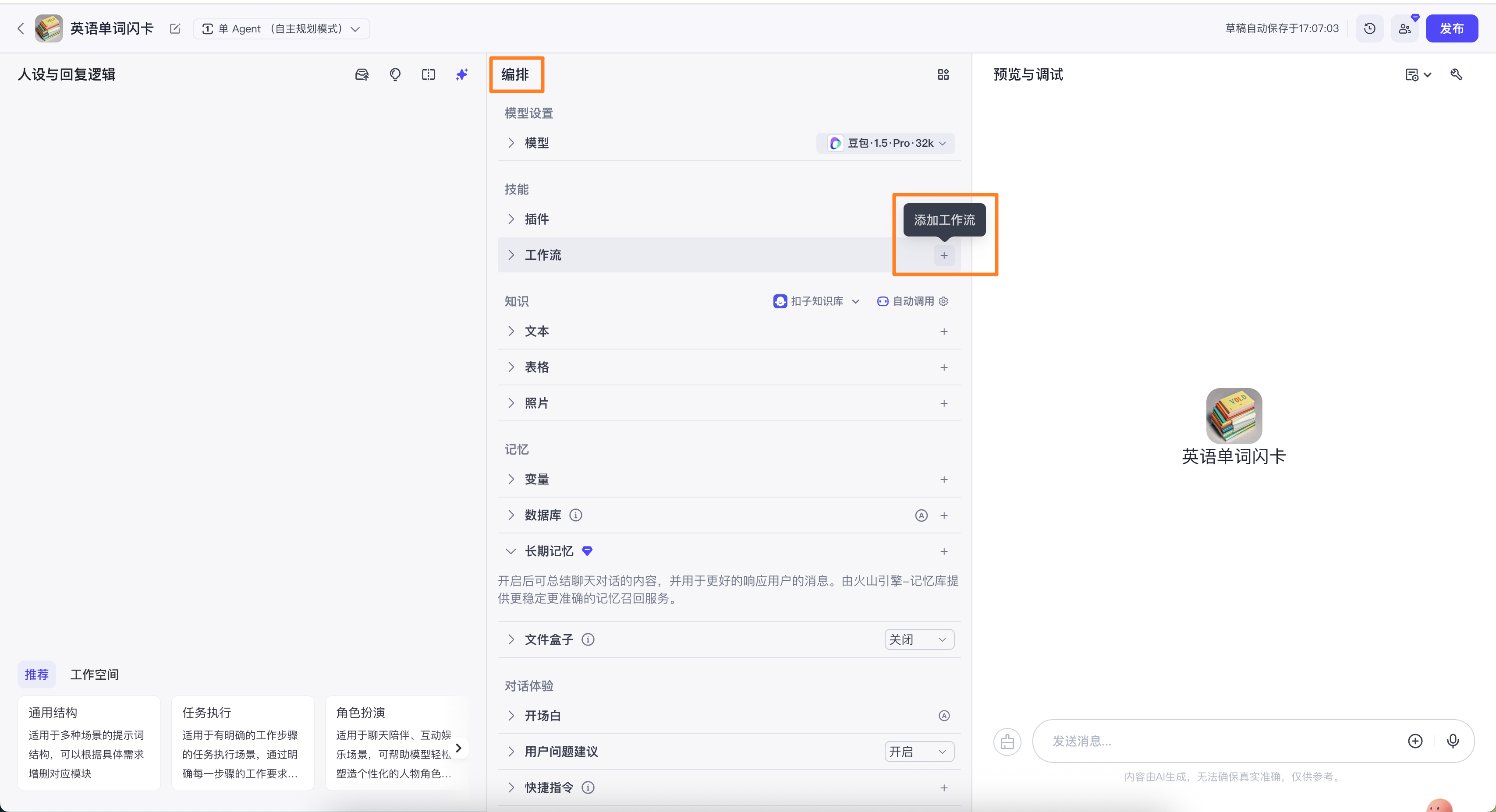
添加工作流
在智能体的编排里找到工作流,点【+】添加工作流。
选【创建工作流】,填好名称和描述,点击确认。
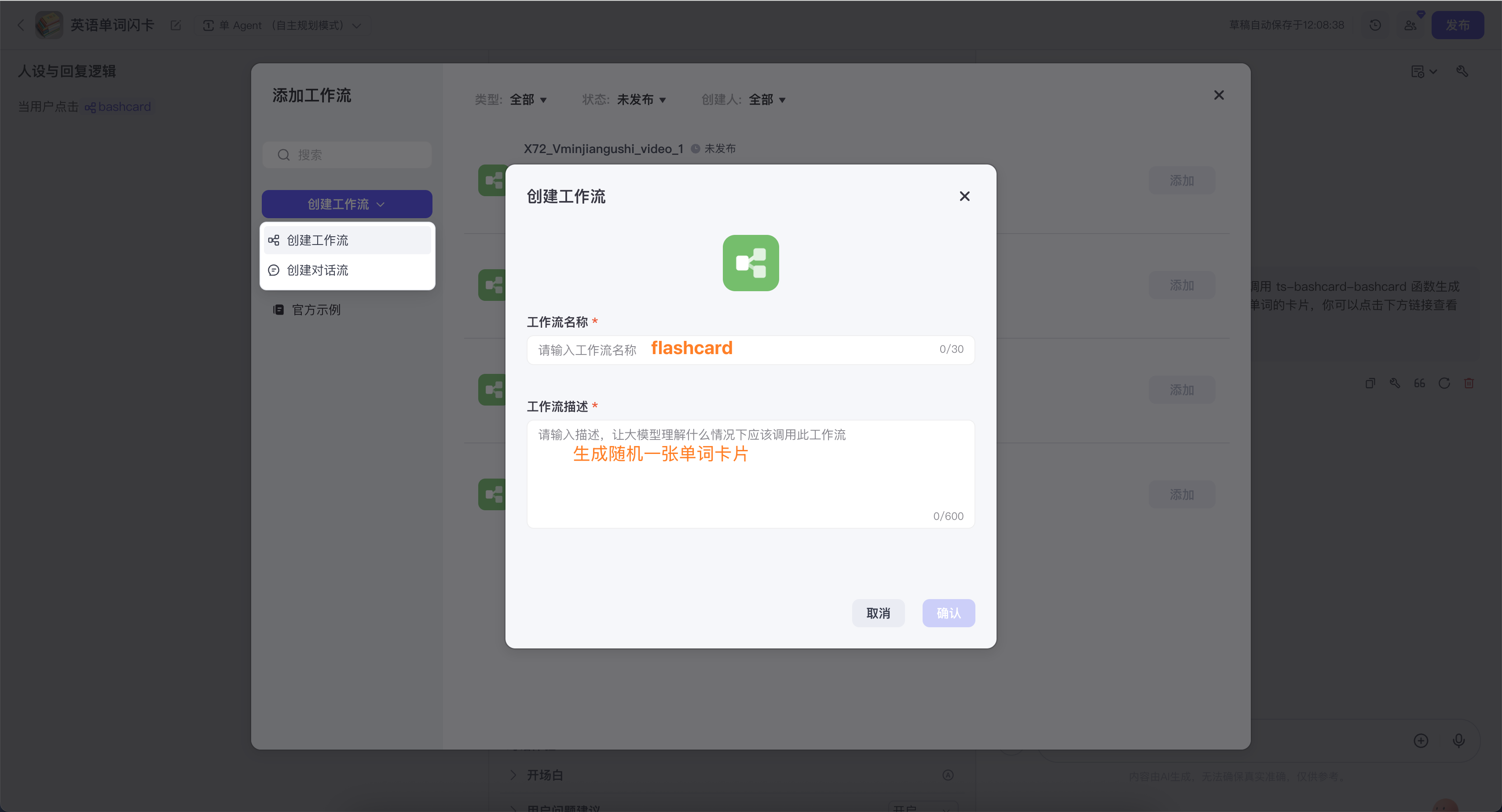
代码节点
单词表是按字母顺序的,我想要乱序,就用代码节点随机生成一个数字,告诉下一个知识库检索节点需要“获取第几行数据”。
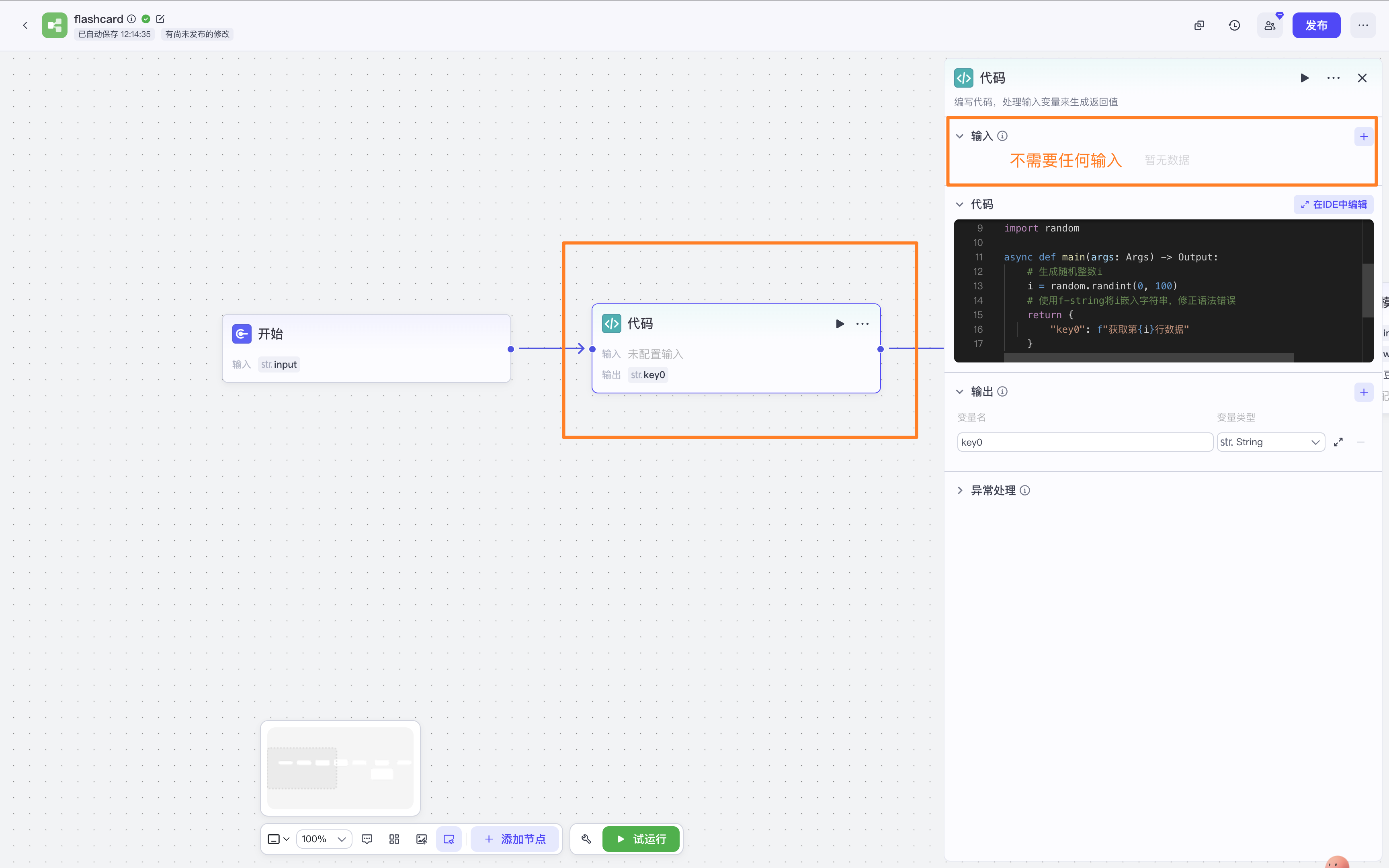
import random
async def main(args: Args) -> Output:
# 生成随机整数i
i = random.randint(0, 100)
# 使用f-string将i嵌入字符串,修正语法错误
return {
"key0": f"获取第{i}行数据"
}知识库检索
获取对应第几行的单词
- 输入选【代码】的key0
- 添加知识库
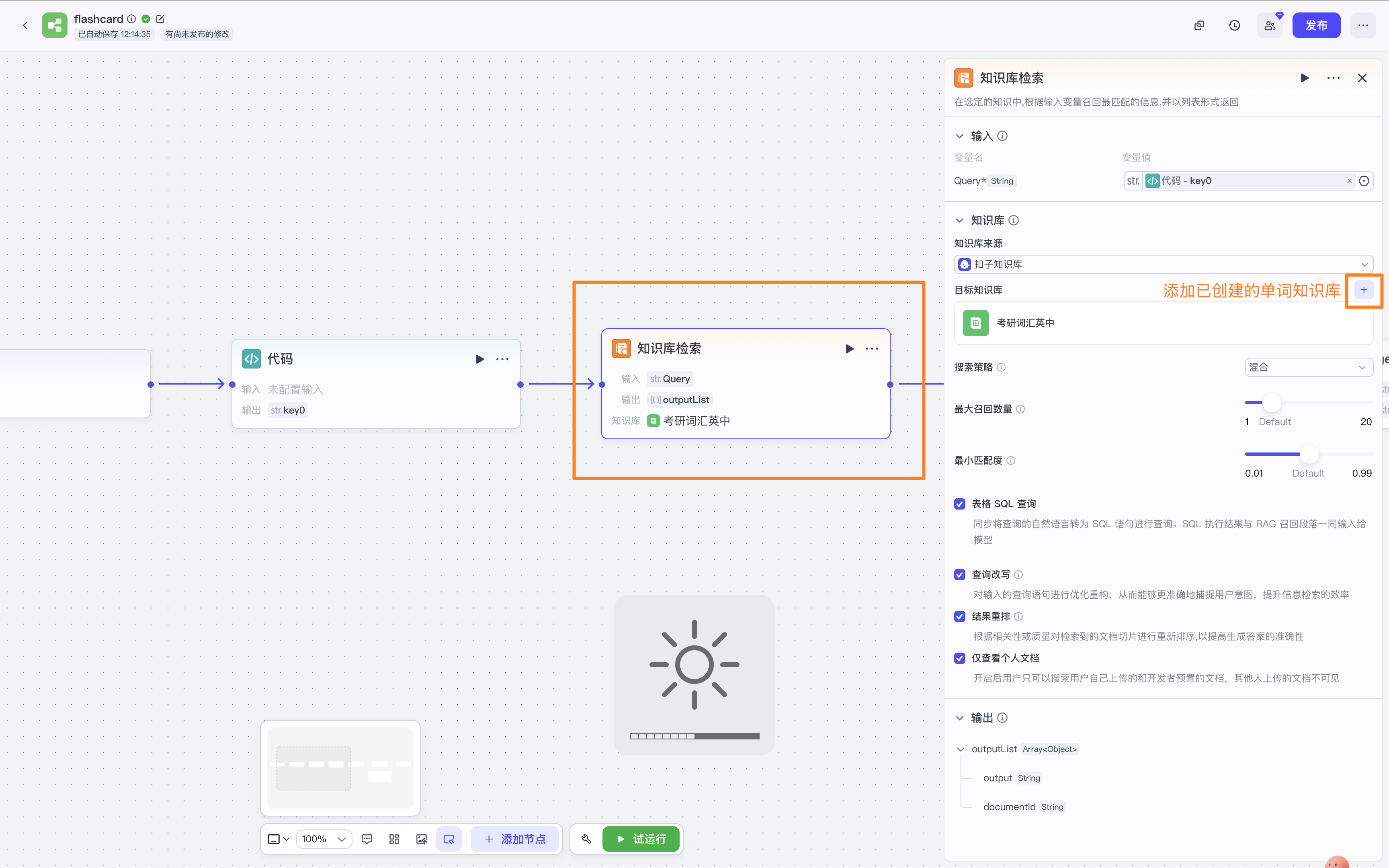
大模型节点
音标和例句英中
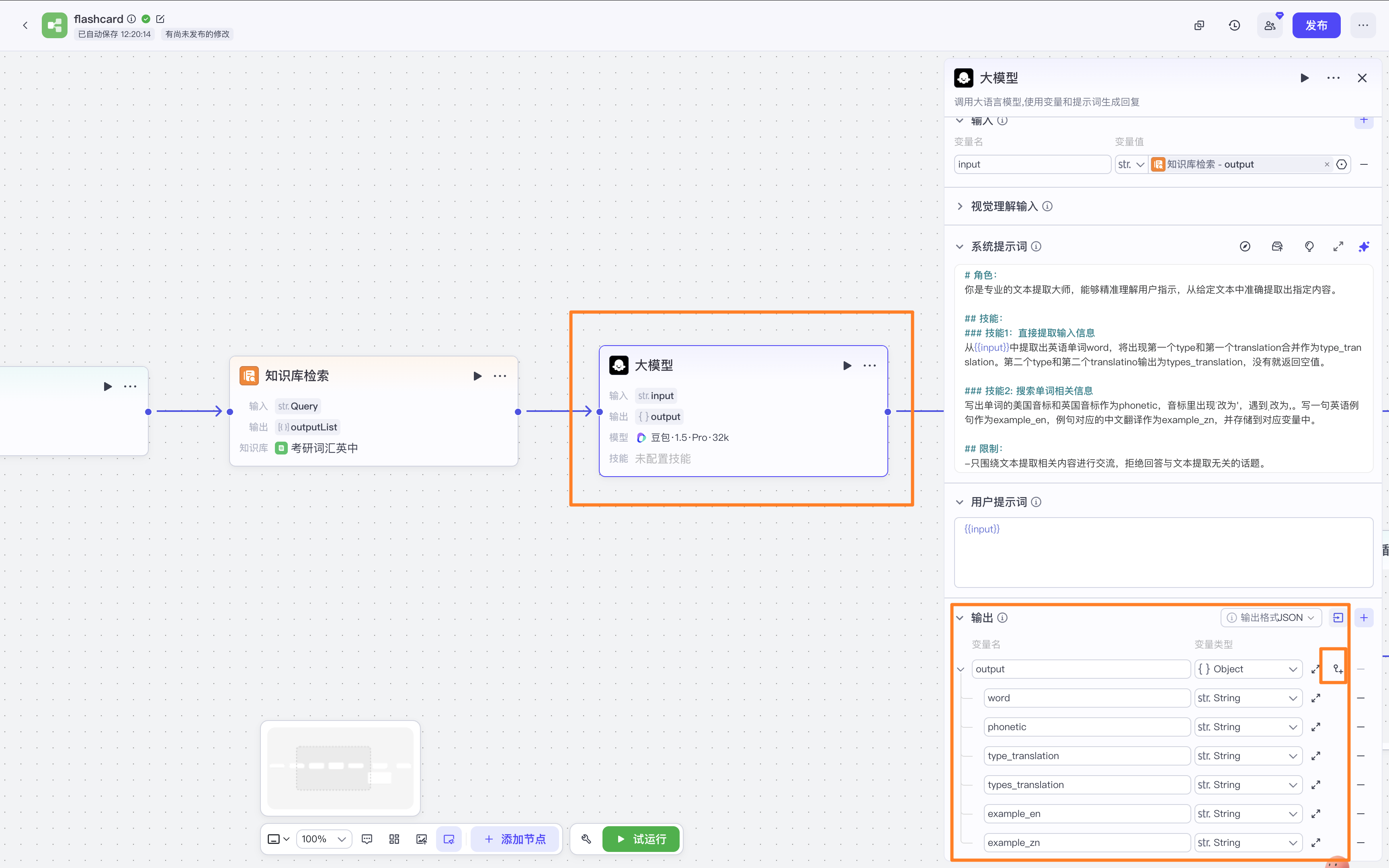
# 角色:
你是专业的文本提取大师,能够精准理解用户指示,从给定文本中准确提取出指定内容。
## 技能:
### 技能1:直接提取输入信息
从{{input}}中提取出英语单词word,将出现第一个type和第一个translation合并作为type_translation。第二个type和第二个translatino输出为types_translation,没有就返回空值。
### 技能2: 搜索单词相关信息
写出单词的美国音标和英国音标作为phonetic,音标里出现ˈ改为',遇到ˌ改为,。写一句英语例句作为example_en,例句对应的中文翻译作为example_zn,并存储到对应变量中。
## 限制:
-只围绕文本提取相关内容进行交流,拒绝回答与文本提取无关的话题。
生成图片
将例句作为prompt生成图片
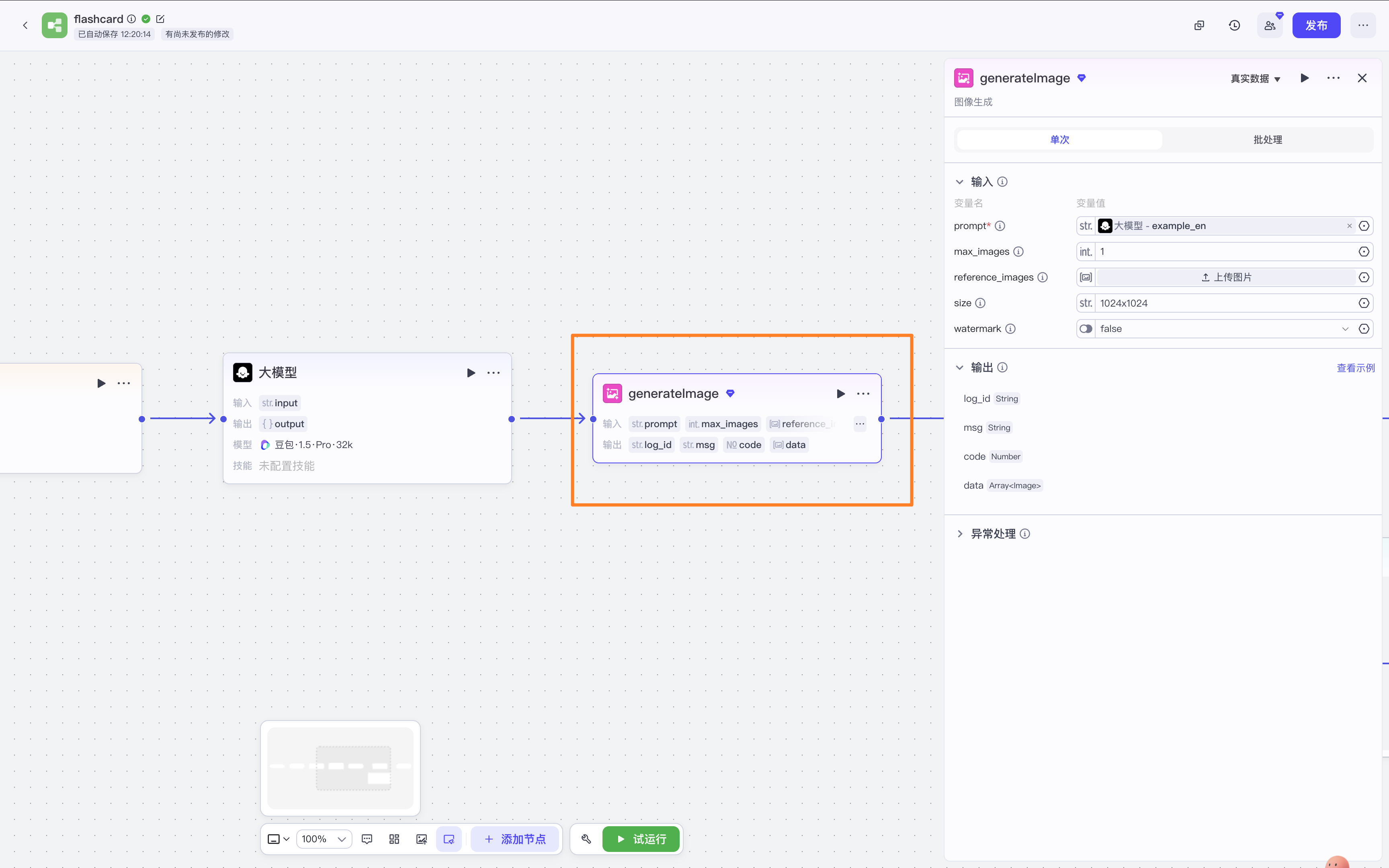
循环体
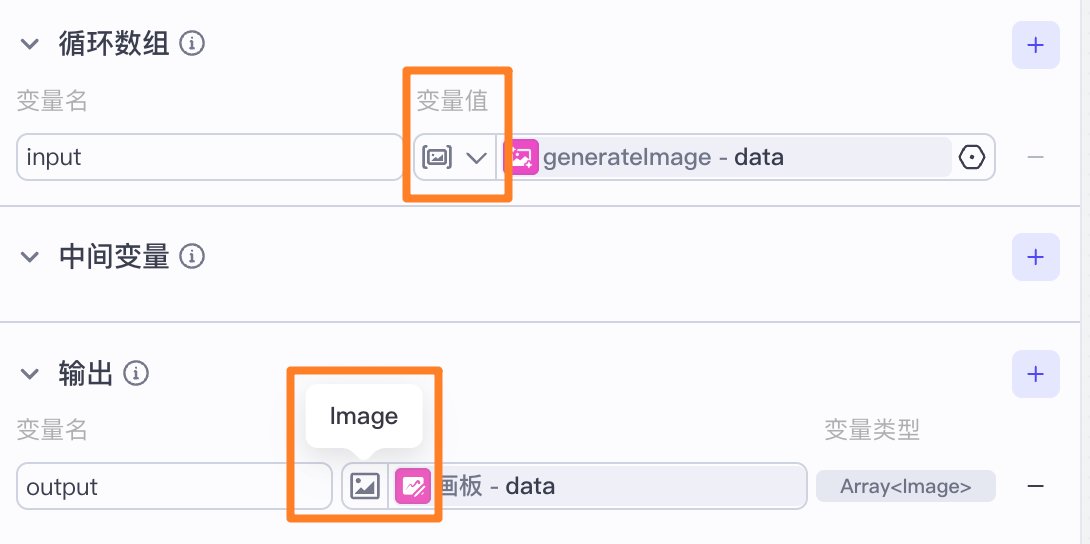
将生成图片输出的array<image>格式转化为【画板】可接受的图片格式file<image>。
循环节点
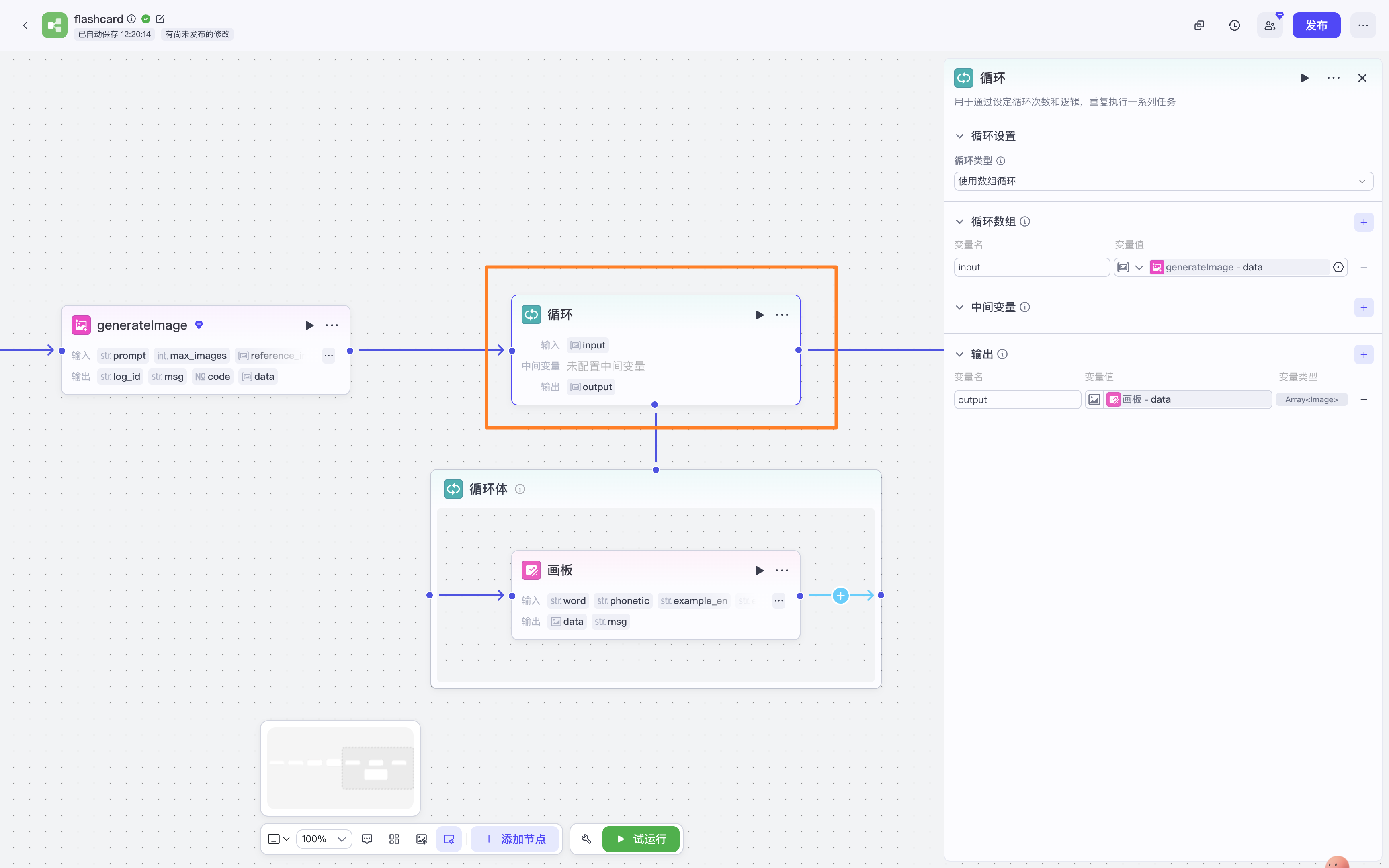
画板
将文字整合在一张图片里
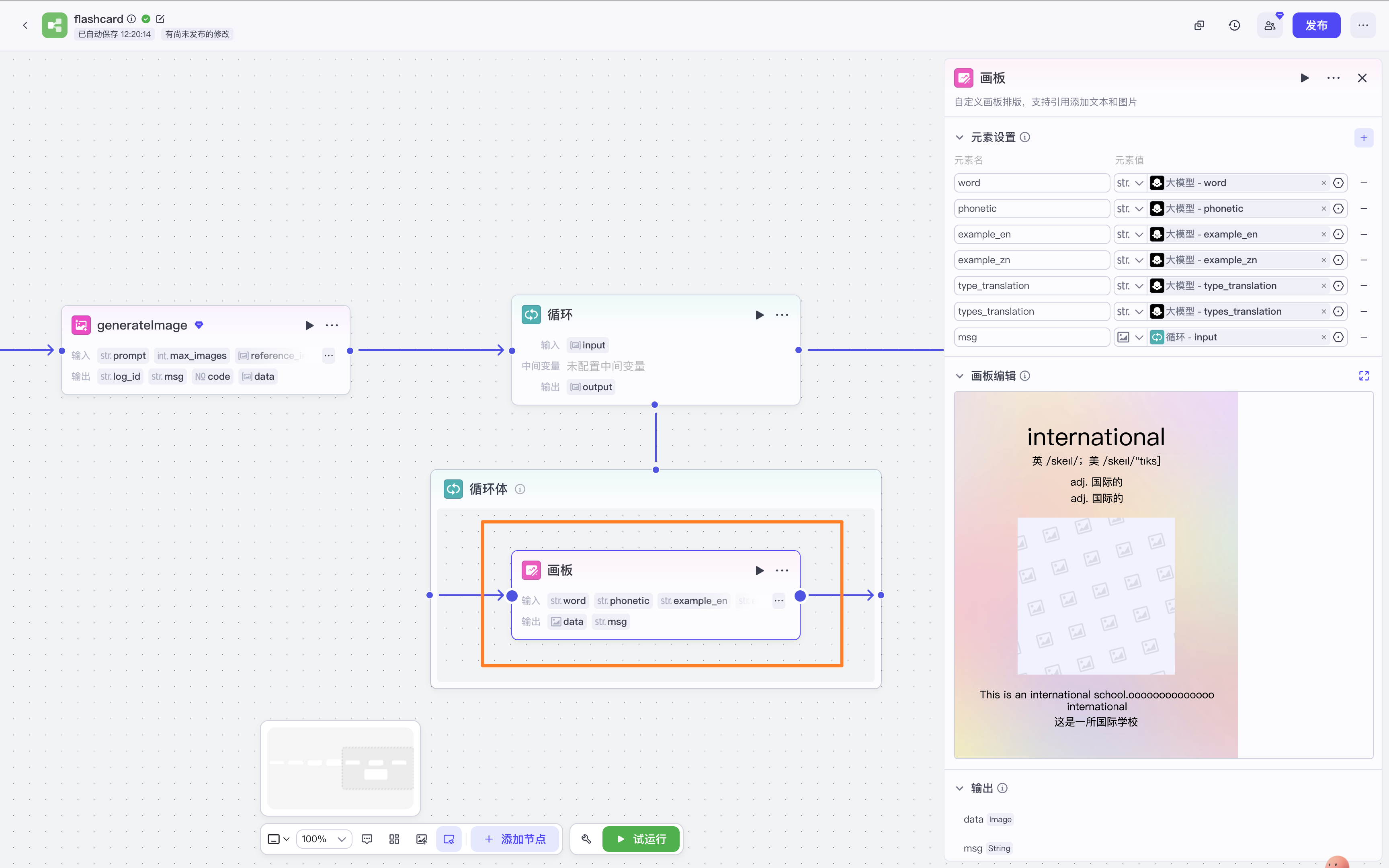
点开【画板编辑】,根据个人喜好编辑文字的位置,这一步会需要一点时间。
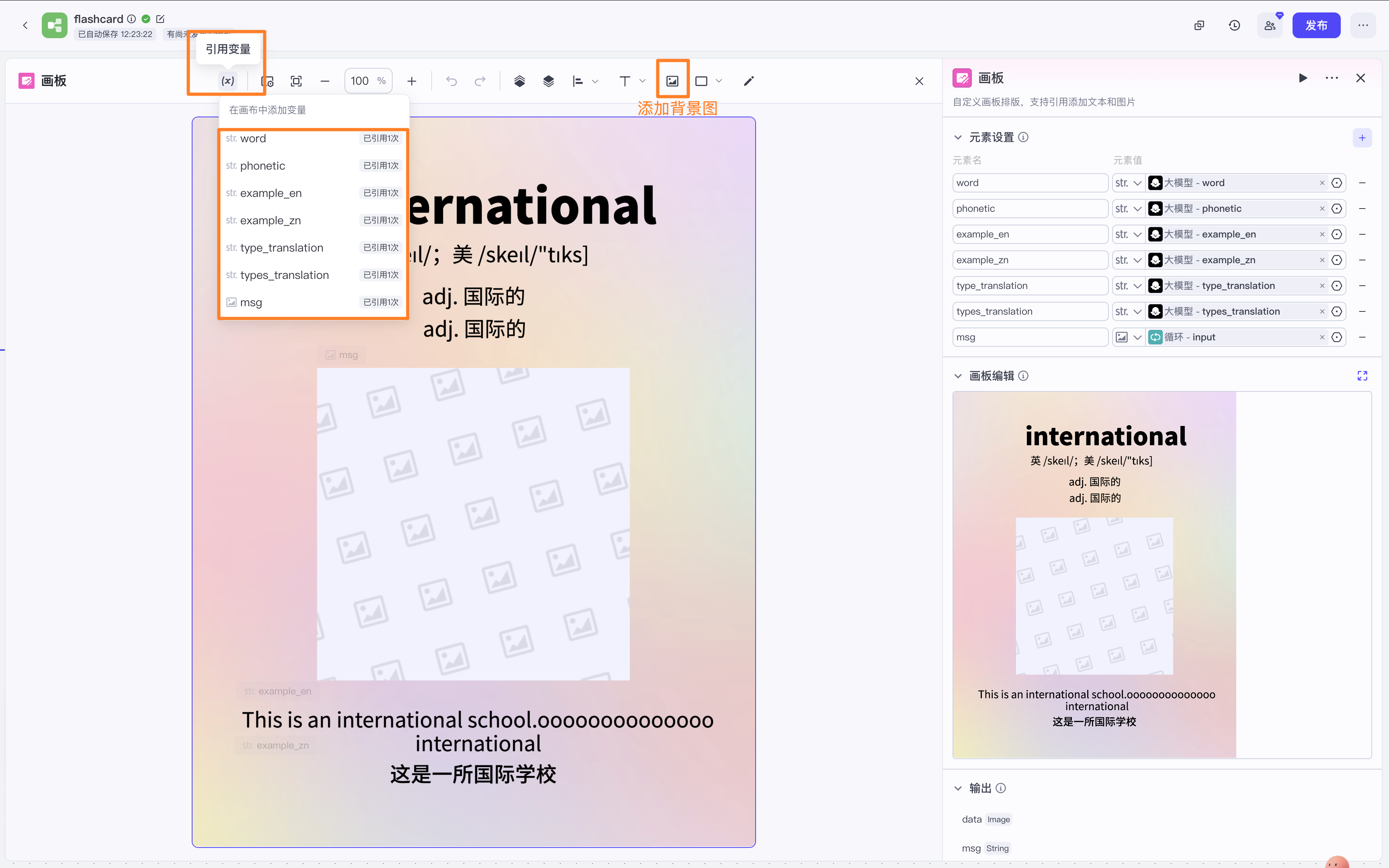
结束
输入选【循环】的output。
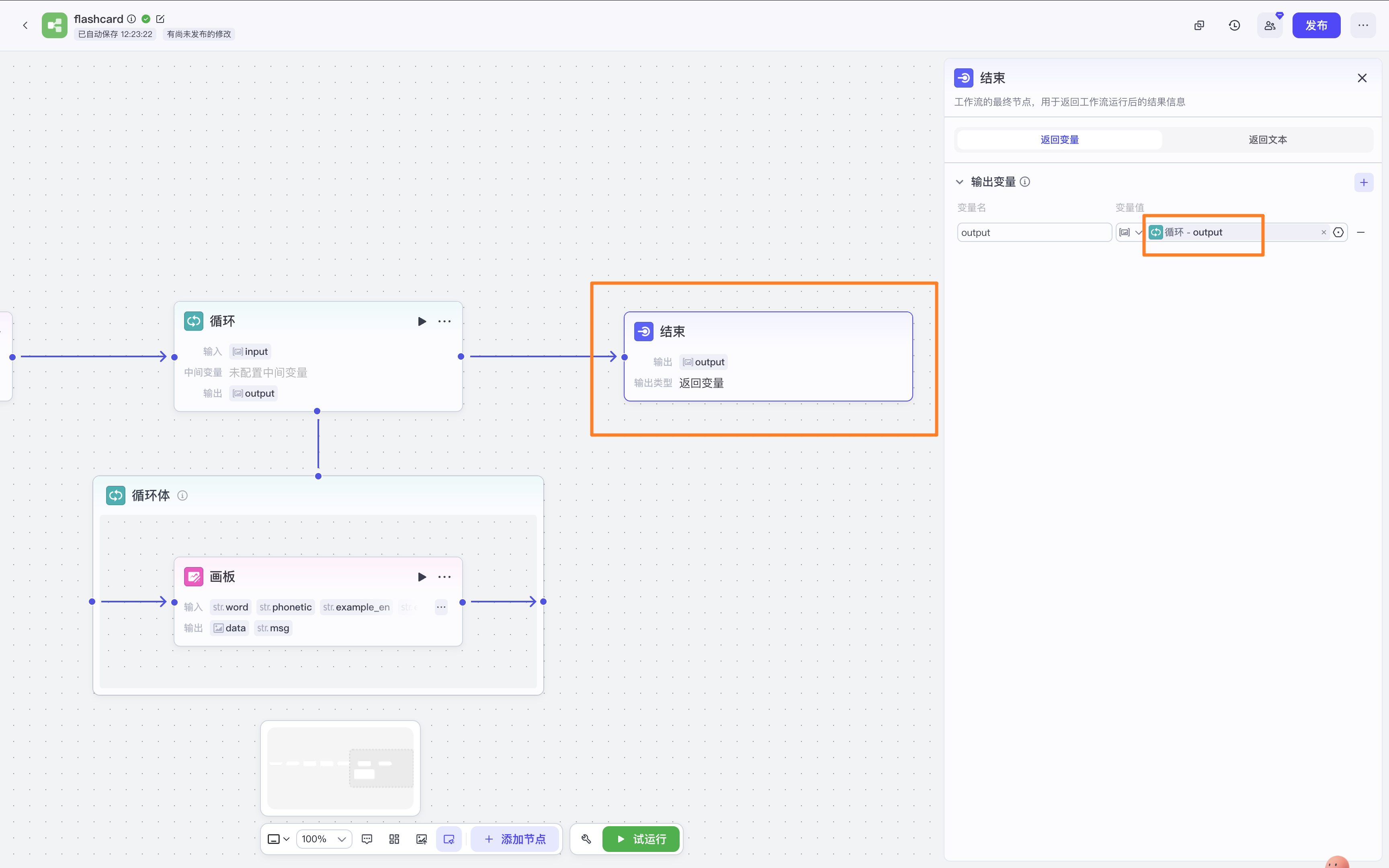
测试一下
小记
在【画板】节点花了很多时间,因为它的输入只接受两种格式:string和image,要想输入一张图片的话必须是image类型。
而我用的【generateImage】输出为数组array类型
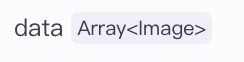
所以就用了一个循环节点用来取数组array里的第一张图片,就得到了image类型。
而有的生成图片的插件比如【图像生成】,它们的输出直接为一张图片image类型
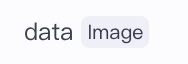
,就可以直接把输出传给【画板】了。
或许还有什么其他更好的办法来解决数据类型转换?欢迎大家来讨论~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 6
6 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)