基于LLM专家混合路由的交易框架QuantML
然而,传统的MoE模型存在明显瓶颈。其次,现有流水线大多是单模态的,仅仅依赖数值型数据,完全忽略了新闻等文本信息,而这些文本信息本可以为专家选择提供宝贵的上下文,从而提升决策质量。给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!通过这种策略,路
摘要
近期的深度学习与大型语言模型(LLM)的飞速发展,为在股票投资领域部署专家混合(Mixture-of-Experts, MoE)机制创造了条件。尽管现有的MoE模型在交易表现上已展现出潜力,但它们通常是单模态的,忽略了文本数据等其他模态中蕴含的丰富信息。此外,传统的基于神经网络的静态路由选择机制,由于未能充分考虑上下文和现实世界的复杂情况,导致专家选择未能达到最优状态。
为了突破这些局限,本文提出了一种名为LLMOE的创新框架。该框架的核心变革在于,用LLM替代了MoE架构中传统的神经网络路由器。通过利用LLM强大的世界知识和推理能力,新路由器能够依据历史价格数据和相关股票新闻来动态选择最合适的专家模型。这种方法不仅提升了选择的有效性,也增强了决策过程的可解释性。在真实世界的多模态股票数据集上进行的实验表明,LLMOE的性能显著优于当前最先进的MoE模型及其他深度神经网络方法。同时,LLMOE的灵活架构使其能轻松适应各类下游任务。
引言
传统的量化交易方法主要依赖统计分析或预测模型。然而,这些方法在面对金融市场的高度复杂性和波动性时,往往难以适应,无法有效处理未曾见过的数据模式和动态变化的数据分布。作为应对方案,深度学习方法凭借其卓越的特征学习能力和对市场的深刻表征能力,已成为量化交易领域一个极具前景的选择。但即便如此,基于深度学习的算法通常依赖单一预测器,这导致其性能不稳定,且对市场波动极为敏感。
为解决单一预测器的不稳定性,专家混合(MoE)方法应运而生。MoE通过利用多个各有所长的“专家”模型协同工作,实现了更优的性能和更强的泛化能力。交易算法中的MoE机制,好比一个真实的交易室,由多位专家协作应对特定的市场挑战。
然而,传统的MoE模型存在明显瓶颈。首先,其路由器通常被设计为静态的神经网络,在多变的金融环境中缺乏灵活性,并且在训练数据有限时容易出现模型崩溃。其次,现有流水线大多是单模态的,仅仅依赖数值型数据,完全忽略了新闻等文本信息,而这些文本信息本可以为专家选择提供宝贵的上下文,从而提升决策质量。
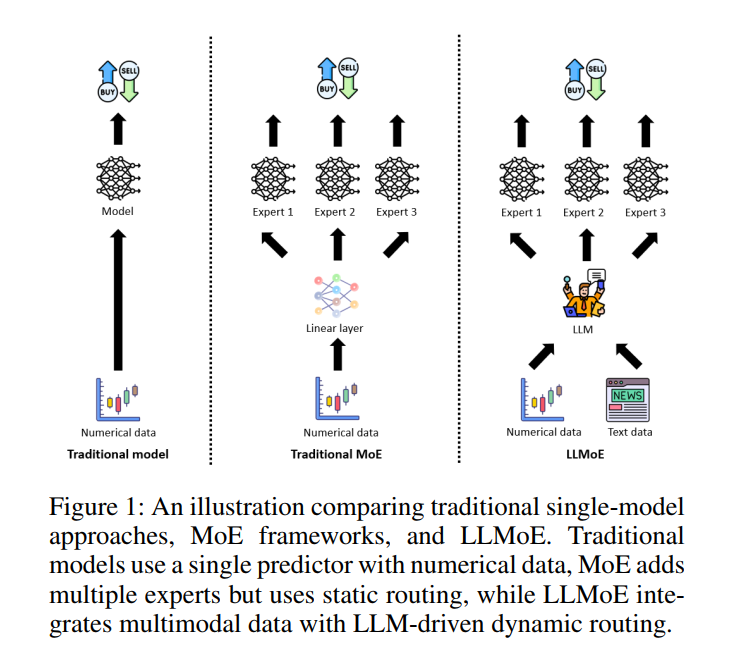
为了填补这些空白,本文提出了LLMOE框架,该框架将MoE与先进的语言模型相结合作为路由器。如图1所示,LLMOE与传统模型的区别在于:
-
传统模型:使用单一预测器处理数值数据。
-
传统MoE模型:引入了多个专家,但路由器是静态的,且仅处理数值数据。
-
LLMOE模型:集成LLM作为动态路由器,能够同时处理数值和文本等多模态数据,实现更智能的专家分配。
在LLMOE框架中,LLM路由器首先处理历史股价和新闻标题,形成对当前市场状况的全面理解。随后,路由器基于这些综合信息,动态地为股票走势预测任务选择最合适的专家模型。最终,基于所选专家的预测结果,采用一种“全入全出”(All-in All-out)的策略生成交易决策。实验证明,LLMOE能有效结合数值和文本数据,优化专家选择过程,并在金融市场应用中取得卓越表现。
问题定义与方法论(详述)
问题定义
本研究的核心任务可以被精确地表述为:给定一个由连续五个交易日的描述性表征构成的滚动时间窗口:
其中,每一个都是一个描述性字符串,它融合了当天的数值特征(如股价指标)与对应的新闻标题,旨在全面地封装当日的市场状况。
模型的目标是基于这个时间窗口的信息,预测下一交易日()的股票价格变动 。此外,研究的另一个目标是根据预测结果 ,开发出一套有效的交易策略,该策略能够统一整合量化数据与定性的上下文信息,以实现更高质量的决策。
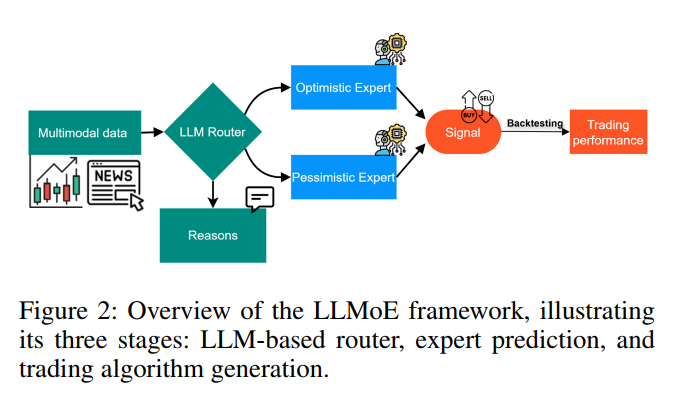
LLMOE:基于LLM路由器的专家混合方法
为了解决上述问题,我们提出了LLMOE框架,它创新性地利用LLM的强大能力在MoE架构中担当路由器角色,从而通过处理多模态数据实现更高效的专家选择。
如图2所示,LLMOE框架的运作流程包含三个核心阶段:LLM路由器、专家预测和交易算法生成。
第一阶段:基于LLM的路由器 (LLM-Based Router)此阶段是LLMOE框架的基石。路由器采用一个大型语言模型(具体为Llama3.2 ),负责处理和整合历史股价等数值数据与相关的新闻资讯等文本数据。LLM凭借其先进的自然语言理解能力,能够深度解读和情境化这些多模态输入,从而形成对当前市场环境的综合性判断。
为了进一步优化专家的选择过程,框架根据不同的市场情境对专家进行分类,例如,划分为“乐观专家”(Optimistic Expert)和“悲观专家”(Pessimistic Expert)。LLM路由器首先对输入的5天滚动数据进行分析,并将其分类为“乐观”或“悲观”。随后,被标记为“乐观”的数据实例将用于训练乐观专家,而被标记为“悲观”的数据则用于训练悲观专家。
这种基于上下文的动态选择机制,确保了每个市场实例都能被分配给最擅长处理该类情境的专家模型。通过这种策略,路由器基于对给定实例的深刻理解,做出了信息更充分的决策,显著改善了整个专家选择流程的质量和效率。
路由器的具体输出包括两个部分:
-
分类(Classification):路由器评估滚动窗口数据后,会给出一个明确的标签——“乐观”或“悲观”,以反映其对市场情绪的预测。
-
推理(Reasoning):为了提升模型的可解释性,路由器还会生成一段自然语言形式的解释(),阐述其做出特定分类的背后原因和考量因素。这段推理过程增强了模型的透明度,但不会直接影响后续专家模型的预测计算。
第二阶段:专家模型预测 (Expert Prediction)此阶段聚焦于由专家模型生成的具体预测。无论是乐观专家还是悲观专家,它们都共享一个统一的架构,即前馈神经网络(Feedforward Neural Networks, FNNs)。这些专家模型接收由LLM路由器筛选和分配的数据,专门分析数值型输入(如价格指标)来应对特定的市场场景。
每个专家模型的输入层处理 个通过特征工程得到的数值特征。这些特征同样以5天的滚动窗口结构组织:其中,每个 代表11个每日数值属性,包括价格指标和滚动偏差等。这种输入结构确保模型能同时捕捉到市场的短期波动和长期趋势。
这些专家模型经过优化,旨在实现高准确率和高效率,从而提升预测的精确度和决策质量,最终在回测中取得稳定且强大的性能表现。
第三阶段:交易算法生成 (Trading Algorithm Generation)在最后阶段,被选中的专家模型的预测结果将被用来生成具体的交易策略。本研究采用了一种简单而强大的“全入全出”(All-in All-out)策略。
具体操作为:
-
当专家预测未来价格将上涨(乐观信号)时,策略会将所有可用现金全部买入目标股票。
-
当专家预测未来价格将下跌(悲观信号)时,策略会将持有的所有该股票头寸全部卖出。
该策略的目标是通过基于专家模型的输出动态调整投资仓位,从而实现回报的最大化。
实验
实验设置
为全面评估LLMOE框架的性能,实验设计涵盖了数据集、特征工程、基准模型和评估指标等多个方面。
1. 数据集 (Datasets)实验选用了两个美国市场的多模态数据集,时间跨度为十年(2006-2016),每个数据集均包含股票价格数据和对应的新闻标题。
-
MSFT (微软) 数据集:共包含2,503个交易日的数据。该数据集的特点是存在大量新闻缺失日(1,176天无新闻),这对模型处理不完整多模态数据的能力构成了严峻考验。
-
AAPL (苹果) 数据集:共包含2,482个交易日的数据,其中仅有194天缺少新闻记录。这个更完整的数据集与MSFT形成互补,用于展示LLMOE在不同数据完整度下的适应性。
数据集的划分标准统一:前80%的交易日(2006年12月7日至2014年12月2日)作为训练集,后20%(2014年12月3日至2016年11月29日)作为测试集。
2. 特征工程 (Features)为了有效捕捉市场动态,研究人员设计了一套包含11个数值属性的特征集。这些特征分为三类:
-
价格比率 (Price Ratios):量化开盘价、最高价和最低价相对于收盘价的比率。
-
日度价格变化 (Daily Price Changes):捕捉收盘价和调整后收盘价的每日百分比变化。
-
滚动偏差 (Rolling Deviations):计算调整后收盘价与其n日移动平均线(MA)的偏差,其中 的取值为 {5, 10, 15, 20, 25, 30}。这类特征旨在捕捉不同时间跨度下的市场趋势和偏离度。例如, 反映了股价与其20日均线的偏离程度,为洞察中期市场动向提供了依据。
3. 基准模型 (Baseline Models)为了验证LLMOE的有效性,研究中将其与多个主流基准模型进行了对比。这些模型包括:
-
LightGBM (LGB) :一种梯度提升决策树模型,广泛用于处理结构化数据,性能强大。
-
多层感知机 (Multi-Layer Perceptron, MLP) :一种全连接的神经网络,作为处理表格化金融特征的深度学习基准。
-
长短期记忆网络 (Long Short-Term Memory, LSTM) :一种循环神经网络(RNN),擅长捕捉序列数据(如股价)中的时间依赖性。
-
动态神经网络集成 (Dynamic Neural Network Ensemble, DNNE) :一种集成模型,通过在自助采样(bootstrap samples)数据上训练多个神经网络来提升预测的多样性和鲁棒性。
-
传统专家混合模型 (MoE) :采用静态路由机制的传统MoE模型,分别评估了包含2个专家和10个专家的版本。它们作为直接对比,用以突显LLMOE动态路由的优势。
4. 评估指标 (Evaluation Metrics)为了从收益和风险两个维度全面评估模型的交易表现,实验采用了七个金融领域常用的评估指标 :
-
总回报率 (Total Return, TR) :衡量整个测试期间投资组合价值的百分比变化。
-
年化波动率 (Annualized Volatility, VOL) :衡量投资组合风险的指标,代表日度回报率的标准差的年化值。
-
夏普比率 (Sharpe Ratio, SR) :评估投资组合的风险调整后回报,数值越高代表单位风险下获得的回报越高。
-
索提诺比率 (Sortino Ratio, SoR) :夏普比率的变体,仅关注下行风险(负向波动),更符合风险规避者的偏好。
-
最大回撤 (Maximum Drawdown, MDD) :衡量投资组合在测试期间从峰值到谷底的最大跌幅,是衡量下行风险的关键指标。
-
卡玛比率 (Calmar Ratio, CR) :通过总回报率与最大回撤的比值来衡量风险调整后回报。
-
下行标准差 (Downside Deviation, DD) :专门计算负回报的标准差,重点衡量资产表现不佳时期的风险。
5. 专家模型架构细节无论是乐观专家还是悲观专家,其内部的FNN架构均保持一致。该架构包含:
-
三个隐藏层:
-
第一层:128个神经元,使用ReLU激活函数。
-
第二层:64个神经元,使用ReLU激活函数,并附加0.3的Dropout率以防止过拟合。
-
第三层:32个神经元,使用ReLU激活函数,并附加0.2的Dropout率。
-
-
一个输出层:
-
包含一个单独的神经元,使用Sigmoid激活函数。它输出一个二进制分类结果(0或1),代表对次日股价走势(下跌或上涨)的预测,直接用于生成交易策略。
-
实验结果与分析
路由器的类人推理能力
LLMOE框架中的LLM路由器展现出了令人印象深刻的类人推理能力,因为它能够有机地结合数值数据和文本信息进行综合判断。论文中给出了一个具体的例子:在某个交易实例中,尽管新闻标题强调了“对苹果公司增长的担忧”,但LLM路由器同时识别出“价格和成交量在持续增长”这一积极的数值信号。最终,路由器权衡了这两种相互矛盾的信号——即文本上的悲观情绪与数值上的乐观趋势——并给出了“审慎乐观”的判断。这种推理过程充分展示了路由器生成平衡且情境感知能力强的预测的能力。
LLMOE的卓越性能
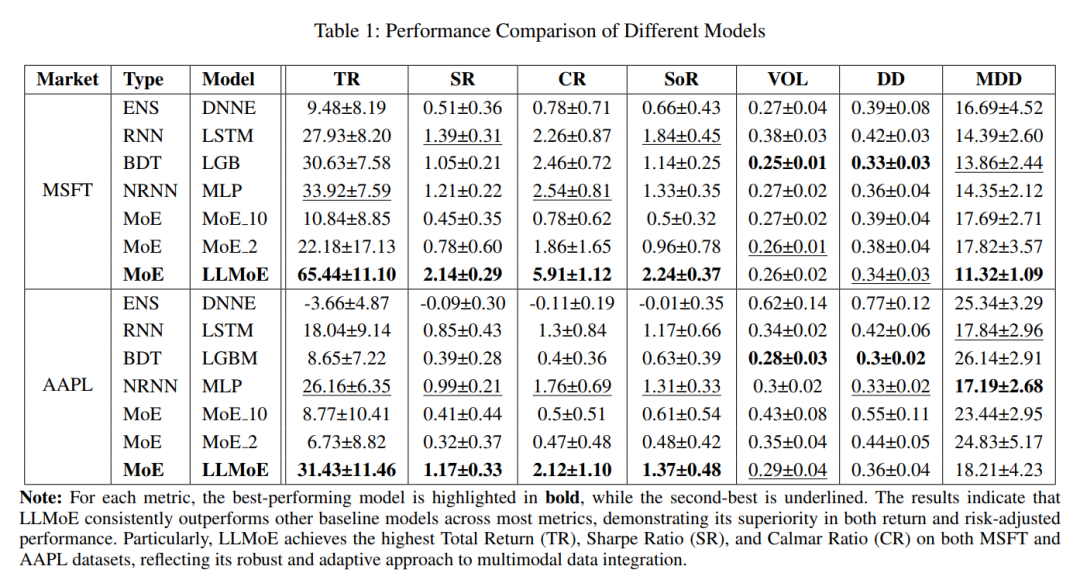
如表1所示,LLMOE模型在多个关键性能指标上显著超越了所有基准模型,包括总回报率(TR)、夏普比率(SR)和卡玛比率(CR)。这充分证明了使用LLM作为路由器来整合数值与文本数据的高效性和准确性。
以MSFT数据集为例 :
-
LLMOE的总回报率(TR)达到了65.44,而表现次之的MLP模型仅为33.92。
-
LLMOE的夏普比率(SR)为2.14,远高于第二名LSTM的1.39,表明其风险调整后收益极佳。
-
在风险控制方面,LLMOE的最大回撤(MDD)为**11.32%**,是所有模型中最低的,显示出优越的风险管理能力。
在AAPL数据集上,LLMOE同样表现最佳,TR达到31.43,SR为1.17,再次验证了其强大的性能和跨资产的鲁棒性。
与传统2-Expert MoE的比较
LLMOE相较于传统的2-Expert MoE模型,展现出了压倒性的优势,其根本原因在于LLM作为智能路由器的引入。传统的MoE模型依赖于静态的路由机制,无法根据实时变化的市场信息动态分配任务。而LLMOE则能动态整合多模态数据,从而实现专家资源的更有效分配。
这种动态分配机制带来了显著的性能提升,尤其是在风险调整后回报指标上,如夏普比率(SR)和卡玛比率(CR)。同时,LLMOE也实现了更好的风险管理,其最大回撤(MDD)远低于传统的MoE模型。这证明了LLM驱动的动态路由机制在适应市场变化和提升投资效率方面的巨大价值。
结论
本文提出并验证了一种名为LLMOE的创新框架,该框架将一个预训练的大型语言模型(LLM)作为路由器集成到专家混合(MoE)架构中。通过动态地结合数值化的股票特征与文本化的新闻数据,LLMOE成功地在量化分析与定性分析之间架起了一座桥梁,实现了对金融市场更准确且更具可解释性的预测。
这种动态且具备情境感知能力的路由机制,克服了传统MoE系统静态、死板的局限性,极大地增强了模型对高波动性金融市场的适应能力。实验结果强有力地证明了LLMOE的卓越性能,其在夏普比率和总回报率等关键的风险调整后回报指标上取得了超过25% 的性能提升。这一成果不仅标志着LLMOE成为了一种顶尖的智能交易工具,也为未来量化交易策略的研发开辟了新的方向。
如何学习AI大模型 ?
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
(👆👆👆安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
(👆👆👆安全链接,放心点击)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献185条内容
已为社区贡献185条内容

所有评论(0)