RAG from scratch: Part 9 (Query Translation -- HyDE) by LangChain
以之前视频使用的notebook为例,针对已编入索引的关于代理的博客文章,定义提示“写一篇xxx来回答给定的问题”,用于生成假设文档。
RAG from scratch: Part 9 (Query Translation – HyDE) by LangChain
查询翻译 — 基于提示的文档嵌入(HyDE,Hypothetical Document Embeddings 的缩写 ) (Query Translation – HyDE)
HyDE (Hypothetical Document Embeddings)是一种改进检索的方法,它生成可用于回答用户输入问题的假设文档。
我们讨论的技术名为HyDE(Hypothetical Document Embeddings) ,即基于提示的文档嵌入技术。它是一种利用简单想法的有趣方法。
一、查询翻译与RAG Flow关系
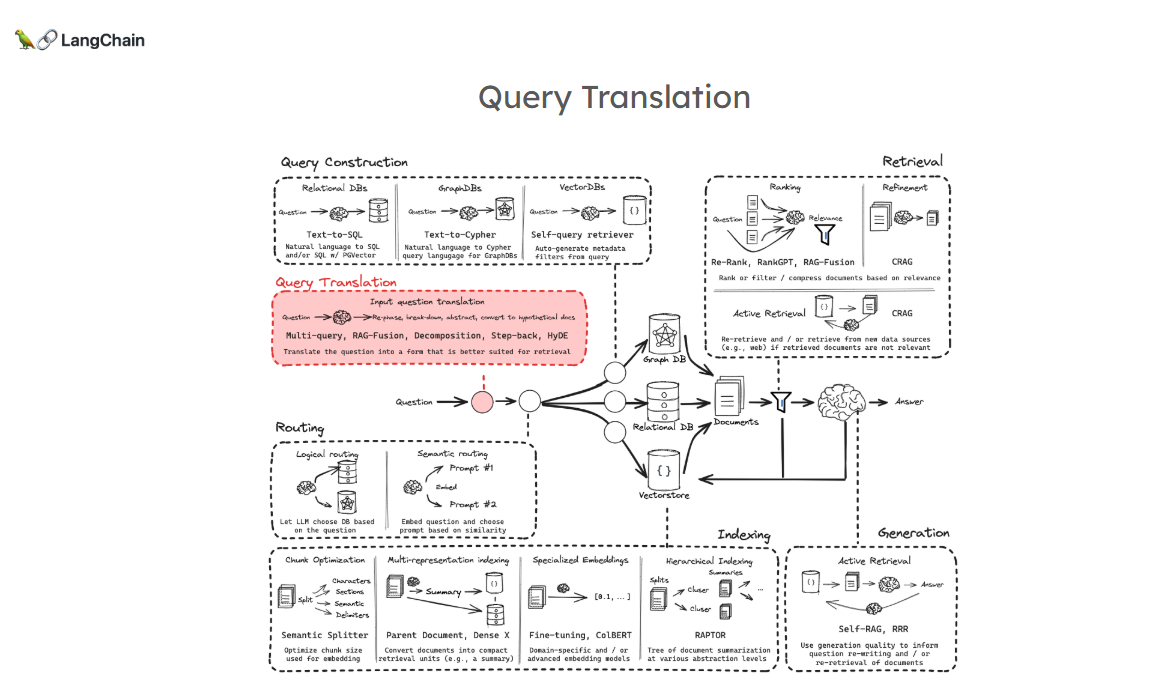
1. 位置
查询翻译处于整个RAG(Retrieval Augmented Generation,检索增强生成)flow的前端。
2. 目标
接受输入问题并进行特殊“翻译”(并非常规语言翻译,而是对问题处理转换),以此改善检索效果。
二、HyDE技术原理
论文:Precise Zero-Shot Dense Retrieval without Relevance Labels
在基本RAG Flow中,问题和文档都会被嵌入,然后计算二者嵌入的相似性。但问题和文档是截然不同的文本对象:文档可能是从密集出版物等来源提取的大块内容,而问题简短且可能因用户表达不当而存在缺陷。
HyDE的核心直觉是通过生成假设文档,将问题映射到文档空间。在某些情况下,假设文档比原始稀疏的输入问题更接近实际想要检索的文档,能更好地理解高维嵌入空间,进而将原始问题转化为更利于检索的形式。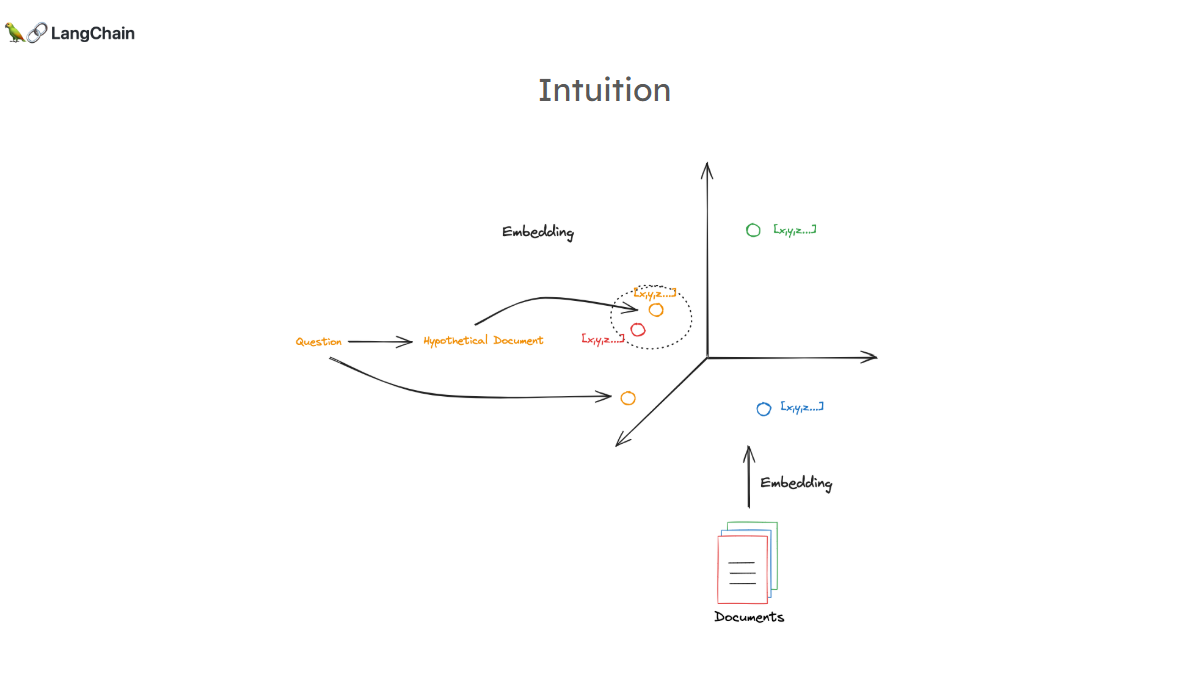
三、HyDE技术代码代码实现步骤

1. 定义提示
以之前视频使用的notebook为例,针对已编入索引的关于代理的博客文章,定义提示“写一篇xxx来回答给定的问题”,用于生成假设文档。
2. 生成假设文档
将上述提示通过特定流程,传输至OpenAI ChatGPT,再借助字符处理工具,生成与问题相关的假设文档部分。
这部分内容源于语言模型(LLM)的嵌入式世界知识,是生成假设文档的合理途径。
3. 导入检索器
把生成的假设文档导入检索器,基于假设文档的嵌入,从索引中获取与之相关的文档,得到一些相关检索块。
4. 构建并运行RAG prompt
获取检索文档和原始问题,将它们导入RAG prompt(检索增强生成提示),运行之前设定好的rag chain(检索增强生成链),最终得出答案。
四、HyDE技术效果及优势
1. 效果评估
在特定索引情况下,输入问题或许足以检索到相关文档,如根据之前例子,部分相同文档能从原始问题检索出来,但并非所有情况都如此。不过,人们反馈在某些领域使用HyDE表现良好。
2. 灵活性和优势
可根据感兴趣的领域自由调整文档生成提示,灵活性强,是一种能克服检索方面一些挑战的有效方法,值得尝试应用 。
五、视频原文
第一页:我们实际上在讨论一种名为HYDE的技术
第二页:查询翻译在某种程度上处于整个RAG flow的前端,目标是接受输入问题并以某种方式进行翻译,从而改善检索。
第三页:HyDE是一种有趣的方法,它利用了一个非常简单的想法,基本的RAG Flow接受一个问题并将其嵌入,它接受一个文档并将其嵌入,然后查找嵌入文档和嵌入问题之间的相似性,但问题和文档是非常不同的文本对象,因此文档可以是从密集出版物或其他来源中提取的非常大的块,而问题则很短,可能被用户误用,
第三页:HyDE背后的直觉是使用假设文档或通过生成假设文档将问题映射到文档空间中,这是基本的直觉,这里直观地展示的想法是,原则上在某些情况下,假设文档更接近您实际想要检索的文档。比稀疏原始输入问题本身更了解高维嵌入空间,所以这只是将原始问题转换成更适合检索的假设文档的一种方式,
第四页:所以让我们实际进行代码演练以了解其工作原理。它实际上非常容易实现,这真的很好,所以首先,我们从一个提示开始,我们使用与之前视频相同的笔记本,我们有一篇关于代理的博客文章已经编入索引,所以我们要做的是定义一个提示来生成假设文档,在这种情况下,我们会说写一篇论文通过Mage来回答给定的问题,所以让我们运行它,看看会发生什么,我们将提示通过pipline传输到打开AI Chatgpt,然后使用字符出啊opa parer,所以这是一个与我们的问题相关的假设文档部分,好的,这当然是从LM的嵌入式世界知识衍生出来的,你知道这是一个生成假设文档的合理的地方,现在,让我们看一下这个假设文档,基本上,我们将它导入检索器,这意味着我们将从索引中获取与这个已嵌入的假设文档相关的文档,您可以看到,我们得到了一些与这个假设文档相关的检索块,这就是我们所做的一切,然后让我们采取最后一步,我们将获取我们定义的检索文档,我们的问题我们将把它导入这个RAG prompt,然后我们将在这里运行我们之前见过的rag chain,然后我们得到答案,就是这样,我们可以去lsmith,我们可以实际看看发生了什么。嗯,例如,这是我们的最终rag propmt:根据此上下文回答以下问题,这是我们传入的检索文档,这样部分就很简单了,我们也可以查看,嗯,好的,这是我们的检索,好的,现在这实际上是我们在这里生成的假设文档,嗯,好的,这是我们的假设文档,我们运行了聊天开放AI,我们生成了这段假设文档,然后我们在这里运行了检索,所以这基本上展示了假设文档的生成,然后是检索,嗯,这里再次展示了我们传入的段落,然后这里是我们从检索器中检索到的与段落内容相关的文档,因此,在这个特定的索引情况下,输入问题可能足以检索这些文档,事实上,根据之前的例子,我知道其中一些相同的文档确实是从原始问题中检索出来的,但在其他情况下可能并非如此,所以人们报告说,使用HyDE在某些领域表现良好,真正方便的是,你可以使用这个文档生成提示,你可以根据你感兴趣的领域任意调整它,所以它绝对值得尝试,这是一种需要的方法,可以克服检索方面的一些挑战,非常感谢。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)